基于CPU+GPU 異構(gòu)計算編程研究
2020-03-26 09:34:30邱浩淼
科學技術(shù)創(chuàng)新 2020年1期
關(guān)鍵詞:程序
邱浩淼
(汕頭市超聲儀器研究所有限公司,廣東 汕頭515000)
1 CPU+GPU 異構(gòu)編程方式
1.1 CPU+GPU 異構(gòu)計算系統(tǒng)
CPU+GPU 異構(gòu)計算系統(tǒng)是一種新型的計算系統(tǒng),對傳統(tǒng)計算機系統(tǒng)進行了設計與改善,計算任務由加速部件GPU 與CPU 共同完成。這種異構(gòu)方式具有顯著的運用優(yōu)勢,增強了GPU 的運算能力,例如對追求浮點運算性能的結(jié)構(gòu)中具有非常遠超CPU 浮點運算能力的GPU。同時GPU 在具有傳統(tǒng)圖像處理能力的同時也具有一定的計算能力。隨著目前技術(shù)的的不斷發(fā)展,GPU 運用過程中在、編程模型、如硬件結(jié)構(gòu)等層面上存在則問題也得到了不同程度的改善。隨著目前計算機系統(tǒng)的逐漸完善,在其功能與擴展性等層面上也出現(xiàn)了一些問題,GPU 加速部件的運用能夠?qū)Υ擞行Ы鉀Q[1]。
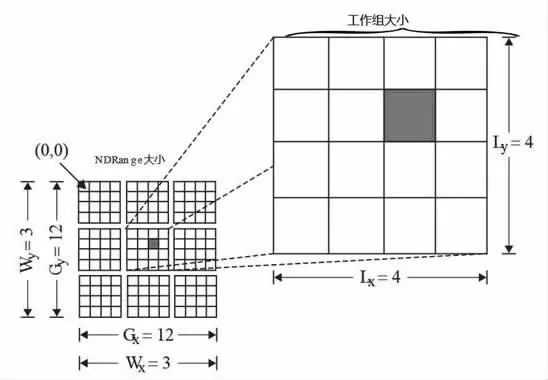
圖1 GPU 計算模型
1.2 CPU+GPU 異構(gòu)在計算系統(tǒng)編程上的困境
CPU+GPU 異構(gòu)計算在目前多項領(lǐng)域中均得到快速發(fā)展,但是由于技術(shù)以及實際運用等多種層面的制約,在具體的計算過程中依然存在著一些不足之處。程序開發(fā)難度較大。 GPU的設計初衷是處于圖形,因此將其進行通用計算層面上存在一定的限制,硬件建設性不足,重點表現(xiàn)為雙精度性能有限,數(shù)據(jù)校驗機制建設不足,數(shù)據(jù)傳輸有限。目前國內(nèi)在GPU 軟件開發(fā)編程模型與方式依然發(fā)展不夠成熟,設備架構(gòu)(CUDA)技術(shù)的開發(fā)具有重要意義,但是在運用過程中需要考慮到CPU 模式中長久存在的X86 編程習慣。目前針對異構(gòu)計算中標準開放計算語言(OpenCL)的運用時間較短,尚沒有形成統(tǒng)一開放的運用體系[2]。
2 目前采用的程序開發(fā)方式
2.1 底層圖形API 的開發(fā)方式
這一開發(fā)方式運用較早,在目前CPU+GPU 異構(gòu)計算方式中依然適用,運用過程中要求對GPU 硬件底層圖形API 做到靈活運用,將其中的程序與圖形處理進行一一對應。在編程處理過程中一般采用開發(fā)圖形庫著色語言(GLSL)等方式。GPU 產(chǎn)品在早期開發(fā)過程中包括頂點處理、片段處理等圖形渲染過程,GPU 可編程能力較為有限。目前已經(jīng)出現(xiàn)并運用了素級可編程性,在一般代數(shù)問題的求解過程中可以采用像素程序解決,能夠?qū)τ邢薏罘址匠探M求解(PDEs)進行有效解決。底層圖形API的運用為程序員進行技術(shù)處理與解決提供了新的方式與途徑。目前主要采用DirectX、OpenGL 的開發(fā)圖形語言[3]。
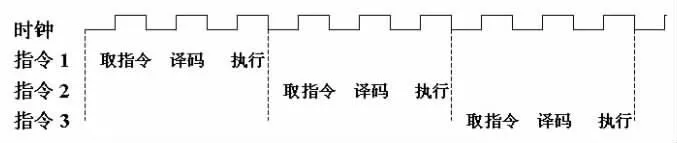
圖2 CPU 指令執(zhí)行流程
2.2 采用低層次抽象的輕量級編程工具
CUDA 的運用有效彌補了傳統(tǒng)方式中需要圖形API 來實現(xiàn)GPU 的訪問的不足,是一種能夠直接訪問硬件的軟硬件體系,建立的圖形處理器(GPGPU),能夠進行通用目的的計算,是C語言中的編程語言,開發(fā)了大量高性能的開發(fā)語言。能夠在實現(xiàn)GPU 計算能力的同時建立一種密集數(shù)據(jù)計算方式。OpenCL能夠運用在Cell 類型架構(gòu)、GPU、CPU、DSP 等并行處理器之中,是一種基于通用計算方式開發(fā)的運用體系。能夠編程GPU、CPU及其他其他分離的計算設備組成的異構(gòu)群。OpenCL 運用過程中可以不把算法映射到底層圖形API 之中,在開發(fā)過程中同時包含了API 庫、開發(fā)語言以運行系統(tǒng)。
2.3 建立高層次抽象函數(shù)庫與模板庫
CUDA 快速傅里葉變換(CUFFT)運用中設計了與標準C 語言程序庫(FFTW)相近的接口,通過GPU 建立了一個函數(shù)庫,能夠?qū)崿F(xiàn)傅里葉變換。對FFTW 操作方式中數(shù)據(jù)存儲內(nèi)存之中進行了有效互補,CUDA 離散傅里葉變換(CUFFT)在存儲方式中具有顯存特征,在數(shù)據(jù)交換中要求在內(nèi)存與顯存之間進行交換。CUDA 線性代數(shù)基礎子程序庫(CUBLAS)運用中能夠進行簡單的矩陣計算,具有和BLAST 差不多的接口,屬于基本的矩陣與向量的運算庫。運用中可以將其運用到線性代數(shù)程序包(LAPACK)等復雜函數(shù)包之中。CUBLAS 也為顯存的存儲方式,要求完成封裝之后才能替代線性代數(shù)子程序(BLAST)函數(shù)。
可以采用高層次抽象編譯器的處理方式,運用復雜的代碼分析技術(shù)、指示語句、語言運行時系統(tǒng)、算法模板等自動生成GPU 內(nèi)核程序。例如PGI x86+GPU 編譯器,設計了一種新指示語句(PRAGMAS),目前得到了一定運用。
3 目前編程方法的運用
目前很多開發(fā)者是從底層圖形API 方法程序逐漸開發(fā)設計而言,在遺留代碼的處理過程中依然可以運用底層圖形API 處理方法,可以不用太大修改原來的運用程序。但是在具體的運用過程中存在著一些局限性。在運用過程中要求程序員編寫構(gòu)造圖形素元,并分配紋理存儲。因此要求程序員在開發(fā)設計過程中詳細掌握GPU 硬件特點、限制因素以及圖形API 的運用方式。同時在設計算法的表達上可以采用三角形、紋理等方式。這種方式在推行過程中在GPU 產(chǎn)品運行代碼執(zhí)行效率難以達到理想效果,與新程序相比運用優(yōu)勢不明顯。
針對這一方式,在處理過程中可以采用OpenCL、CUDA 等較低層次的編程工具,此時只有少量程序段會影響性能,只需將這些代碼自己編寫即可。運用過程中為了獲得良好的效果,要求積極優(yōu)化GPU 具體數(shù)據(jù)結(jié)構(gòu),但是對開發(fā)者提出了較高的要求,要求其掌握一門新的編程語言。
執(zhí)行標準函數(shù)應用程序運用過程中,為了提升了其運行效率,可以采用GPU 加速版本的標準函數(shù)庫的處理方式,運行中要求降低GPU 和主機之間的通訊。但是在實際運用中,函數(shù)庫的靈活性較為有限,有可能出現(xiàn)多余的存儲器訪問。
針對需要專業(yè)領(lǐng)域算法應用程序,開發(fā)者難以自己編寫程序,而標準函數(shù)庫中又難以找到對應程序的情況,可以采用編譯器來解決。這一方式目前運用時間較短,存在著一定的局限性。Portland Group 運用中難以在嵌套循環(huán)結(jié)構(gòu)與底層流處理器之間建立良好的映射關(guān)系,需要用戶自己做較大量的工作,內(nèi)核程序并行化復雜度,沒有得到很好地隱藏。
結(jié)束語
CPU+GPU 異構(gòu)計算模式在目前計算機領(lǐng)域中運用較為廣泛,在程序開發(fā)方面存在著一定的局限性,目前GPU 產(chǎn)品的硬件架構(gòu)設計中正在積極向著程序設計層面演變,工業(yè)界與學術(shù)界目前正在對此積極研發(fā),CPU+GPU 的異構(gòu)計算系統(tǒng)設計正在逐步完善。
猜你喜歡
電腦愛好者(2020年6期)2020-05-26 09:27:33
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環(huán)球時報(2017-03-30)2017-03-30 06:44:45
信息安全與通信保密(2016年3期)2016-08-23 01:23:56
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:34
山西省政法管理干部學院學報(2016年2期)2016-07-31 18:19:25
中國衛(wèi)生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
