基于脈沖神經網絡與移動GPU計算的圖像分類算法研究與實現*
2020-03-26 10:56:00徐頻捷王誨喆
計算機工程與科學 2020年3期
關鍵詞:模型
徐頻捷,王誨喆,李 策,唐 丹,趙 地
(1.中國科學院計算技術研究所,北京 100190;2.中國科學院大學,北京 100049; 3.中國礦業大學(北京) 機電與信息工程學院,北京 100083)
1 引言
神經科學希望能從生理學角度解釋生物的神智活動,但是神經系統的生理學機制過于復雜,僅人腦就有超過一千億的神經元,每個神經元又和上萬個神經元構建聯系,哪怕科技發展到今天該領域也沒有取得突破性的進展。隨著計算機科學的發展,人類所掌控的算力越來越強,在摩爾定律的加持下,利用計算機模擬人腦成為了可能,類腦計算應運而生。而以圖像分類為代表的機器視覺作為類腦計算的重要任務之一,逐漸引起計算機科學家的重視。
Maass博士[1]稱脈沖神經網絡為第3代神經網絡,與傳統的人工神經網絡不同,脈沖神經網絡由精確的脈沖點火序列驅動,使用更具有生物可解釋性的神經元模型和突觸可塑性算法。漏極點火模型LIF(Leaky Integrate and Fire model)是由Lapicque[2]提出的,這種神經元模型最簡單,但不夠精確。隨著生物學的發展,Hodgkin等[3]提出了霍奇金赫胥黎HH(Hodgkin Huxley)模型,HH模型高度仿生,精確地仿真了人腦神經元活動時的理化特性,但在模型仿真時需要求解大量的微分方程,需要付出較大的計算代價。為了找到一種既有更高的生物可解釋性,又只需要較低算力代價的模型,Izhikevich[4]提出了Izhikevich模型,該模型介于LIF模型和HH模型之間,在算力代價大大降低的前提下,保證了較高的生物可信度。
脈沖神經網絡的學習方法分為基于梯度下降、基于Widrow-Hoff規則、基于感知機規則3大類。其中基于梯度下降的方法以Bohte等[5]的基于梯度下降的脈沖反向傳播SpikeProp(Spike Back Propagation)算法為代表;Mckennoch等[6]提出了帶動量的反向傳播算法作為改進;為了加快訓練速度,Silva等[7]提出了快速梯度下降算法。在基于Widrow-Hoff規則的學習方法中,脈沖時序依賴可塑性STDP(Spike Timing Dependent-Plasticity)[8]算法最為常用;Ponulak等[9]的遠程監督學習ReSuMe(Remote Supervised Method)方法通過計算期望輸出和實際輸出的差值體現神經元的突觸可塑性;Chronotron[10]中的I-learning機制,通過神經元之間的帶權值電流調整突觸權值。而基于感知機規則的學習方法較為少見,以Xu等[11]提出的基于感知機規則的脈沖序列學習方法PBSNLR(Perceptron Based Spiking Neuron Learning Rule)為主。
雖然在傳統人工神經網絡上有關于低功耗算法的嘗試[12],但是過擬合、缺少生物可解釋性等問題仍然存在。為了克服人工神經網絡的缺點,大量基于脈沖神經的視覺模擬算法被提出。Beyeler等[13]通過脈沖神經網絡實現了生物視網膜的視覺選擇機制,并實現了視頻數據的特征提取;潘婷[14]提出了單層脈沖神經網絡圖像分類算法,并提出了一種改進的突觸時序依賴可塑性算法;Diehl等[15]提出了一種基于液態機的圖像分類算法,該算法模擬了人腦視覺神經元的連接方式,并通過自適應的脈沖點火閾值方法提高網絡性能。
2 脈沖卷積神經網絡
2.1 脈沖神經網絡的生物學原理
2個神經元之間通過一種叫突觸的結構連接。突觸間隙既保證了細胞之間不會走得太近,又保證了細胞之間的正常通信。當來自突觸前神經元的動作電位達到軸突末端的時候,動作電位并不會直接引起突觸后膜電勢的變化,而是通過傳遞一種叫做神經遞質的化學物質改變突觸內外膜電勢,形成電勢差。隨著動作電位的到達,突觸小泡釋放神經遞質,神經遞質穿過突觸間隙到達突觸后膜,并被突觸后膜上的受體接收。隨著受體和神經遞質結合,引起通道蛋白打開,神經元和外界發生鈉離子和鉀離子交換,并引起突觸后膜的電勢發生變化。當突觸后膜電勢累加達到某1個閾值時,神經元激活并發出1個脈沖,隨后突觸后神經元會進入一段時間的不應期。脈沖會引起1個新的動作電位的產生,并通過軸突傳導,引起下1次突觸小泡的釋放。
2.2 脈沖神經元模型
綜合考慮算力和生物可解釋性的需求,為了將脈沖神經網絡部署在Jetson TK1開發板上,本文選用LIF神經元模型。
LIF神經元可以由如圖1所示的電路圖模擬。當電流流入細胞體(RC電路)時,突觸后膜電勢為ε(t),電流部分被電阻R消耗,部分給電容器C充電,如式(1)所示。
(1)
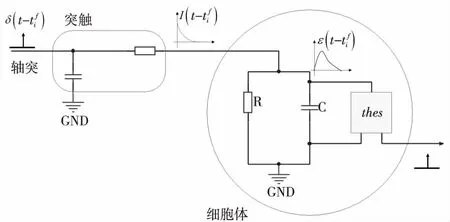
Figure 1 LIF neural model圖1 LIF神經元模型
令時間常數τm=RC,就可以將式(1)變形為更常見的形式:
(2)

(3)
2.3 突觸可塑性算法
為了實現低功耗網絡,回避有監督學習必須的大量數據標注和復雜的學習方法,本文選用基于無監督的STDP算法。STDP是Hebbian學習[16]的一種重要形式,在該算法中突觸前神經元和突觸后神經元脈沖時間的精確計時將影響突觸權重的變化[6]。SDTP遵循以下規則:如果突觸前神經元的脈沖比突觸后神經元的脈沖先到達,那么將產生長時間的興奮刺激LTP(Long-Term Potentiation),同時2個神經元之間的突觸權值將增大;如果突觸前神經元的脈沖比突觸后神經元的脈沖后到達,那么將產生長時間的抑制LTD(Long-Term Depression),同時2個神經元之間的突觸權值將減小。突觸權值的更新策略由式(4)描述:
(4)
其中,tpost為突觸后神經元的脈沖產生時間,tpre為突觸前神經元的脈沖產生時間;A+是可塑性增強學習率,A-是可塑性減弱學習率;τ+和τ-是時間衰減指數。
3 CUDA改進的脈沖神經網絡
3.1 脈沖卷積
脈沖卷積操作對象是表示點火時間序列的脈沖信號。1個典型的脈沖卷積運算可以由式(5)描述:
(5)
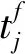
(6)
3.2 脈沖池化
對于脈沖池化,可以由式(7)描述:
(7)
其中各個參數的含義與脈沖卷積中的一樣,值得注意的是,wij是突觸前神經元j和突觸后神經元i之間的突觸權重,這里的權重來自于池化模板,且權值根據模板的類型(最大、平均、隨機)是固定的,不需要通過學習算法更新。
3.3 脈沖卷積神經網絡
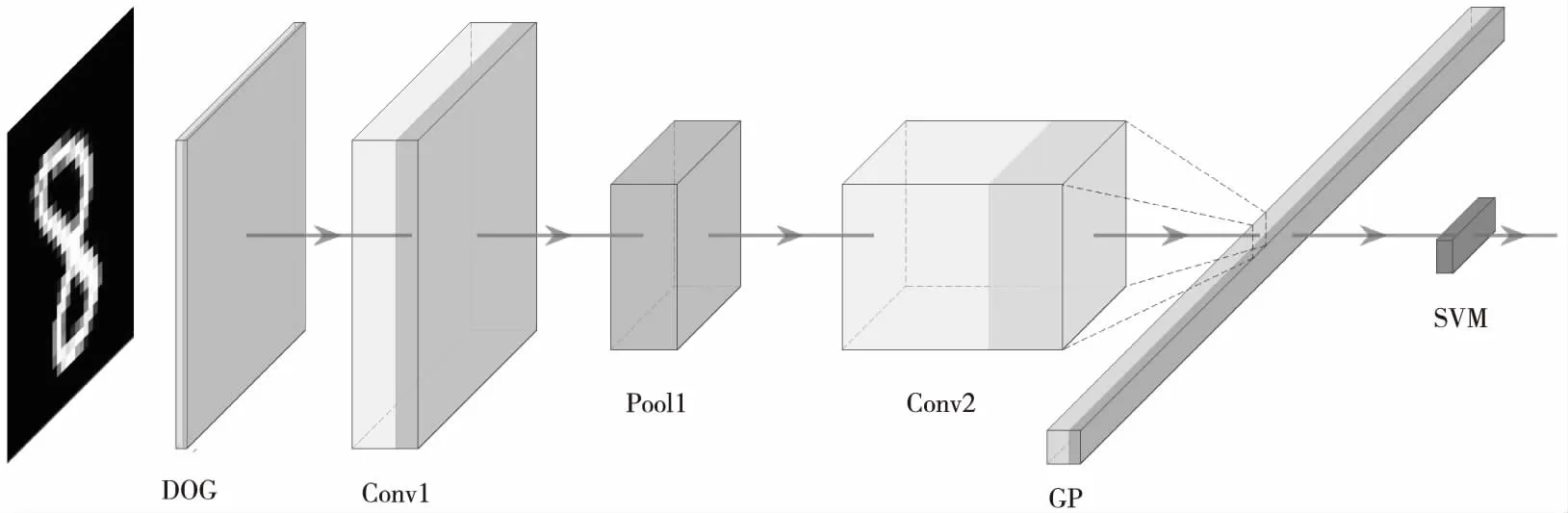
Figure 2 Structure of spiking convolutional neural network圖2 脈沖卷積神經網絡結構圖
在生物學研究中發現,人的視覺系統通過簡單視覺細胞(S cell)和復雜視覺細胞(C cell)來提取視覺特征。簡單視覺細胞主要用于提取特征信息,能夠最大限度地響應來自感受野的視覺邊緣信息;而復雜細胞有更大的接受域,使網絡獲得了抗變形的能力,使得視覺系統對于某些確定位置的刺激具有局部不變性。通過復雜視覺細胞和簡單視覺細胞的層疊組合,既能夠控制網絡連接的規模,又能約束特征子模式的響應級別。為了構建1個有效的視覺分類系統,本文用脈沖池化層模擬人視覺系統的復雜視覺細胞,用脈沖卷積層模擬簡單視覺細胞,通過堆疊類似于傳統人工神經網絡的池化卷積模塊,構建深度脈沖卷積神經網絡模型。如圖2所示是1個典型的脈沖卷積神經網絡結構圖,圖2中模塊從左往右依次為脈沖高斯差分神經元組(DOG)、脈沖卷積神經元組1(Conv1)、脈沖池化神經元組1(Pool1)、脈沖卷積神經元組2(Conv2)、全局最大池化(GP),最后通過支持向量機(SVM)完成分類。
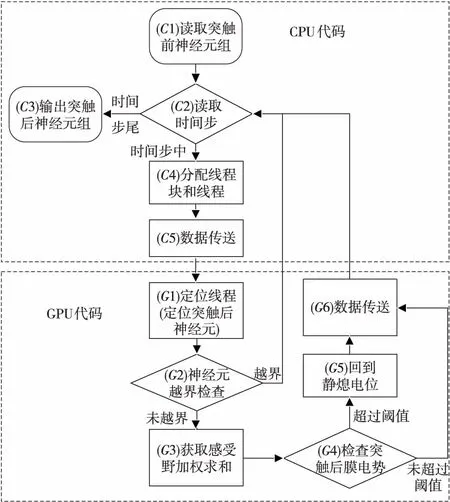
Figure 3 Flow chart of CUDA improved spiking convolution algorithm圖3 CUDA改進的脈沖卷積算法流程圖
3.4 CUDA改進的脈沖卷積
為了充分利用Jetson TK1開發板支持CUDA編程的優勢,本文提出并實現了CUDA改進的脈沖卷積神經網絡,算法流程圖如圖3所示,該實現分為CPU和GPU 2個部分。
CPU代碼部分主要完成時間步的遍歷。輸入神經元組的維度是H×W×C×T,分別表示輸入神經元組的長、寬、通道數和時間步。在CPU代碼部分,如圖3的C1(簡稱C1,下同)所示,代碼將讀取來自神經網絡上1層的輸出。在C2中,實現對時間步的循環遍歷,當輸出達到時間步尾時脈沖卷積結束(C3),否則對該時間步的特征進行卷積。在C4完成線程和線程塊的分配。在C5處交互CPU與GPU之間的數據,CPU內存和GPU顯存的存儲形式差別很大,需要額外定義GPU上的顯存變量,再將CPU上的內存變量轉化成GPU顯存變量。
GPU代碼部分主要完成突觸后膜電勢加權求和以及脈沖序列的生成,該部分由多個GPU線程并行完成,因此只需要關注單個線程中的操作。在G1中定位當前線程的位置,即定位當前線程對應的突觸后神經元。在G2完成C4處分配的冗余線程的越界檢查,越界線程沒有對應的突觸后神經元,因此不應參加卷積計算。在G3處,每個突觸后神經元唯一對應1個感受野,感受野的大小和卷積核尺寸相同,對感受野上的脈沖做加權求和形成突觸后膜電勢增量,并累加到突觸后膜電勢上。在G4中,由于突觸后膜電勢在時間步上的累加效應,當突出后膜電勢累加并超過閾值時就會在當前時間步產生1個脈沖,同時突觸后膜電勢回到靜息電位(G5),如果未達到閾值,則電勢會被保留到下1個時間步。當GPU上的卷積操作結束時,將更新后的脈沖序列和突觸后膜電勢送回CPU內存。
4 實驗結果及分析
本文選用Jetson TK1作為開發環境,這是一款被廣泛使用的高性能嵌入式開發板,基于NVIDIA的Tegra?K1 SoC架構。雖然是1個小型嵌入式設備,但擁有基于ARM架構的Cortex-A15 CPU,4核主頻2.3 GHz;以及NVIDIA的Kepler GK20a架構GPU,擁有192個CUDA核心,每秒浮點運算次數高達326 GFLOPS。由于Jetson TK1低功耗、高性能的特點,現在正被廣泛應用于智能家居[18]、監控安防[19]、車載設備[20]等眾多領域。
輸入網絡的手寫數字圖像維度是28×28×1,網絡整體分為基本神經元組和特殊神經元組,其中基本神經元組為前4組,特殊神經元組為后2組,各神經元組具體參數如表1所示。在整個網絡中,只有2個脈沖卷積神經元組是需要通過學習更新權重的。特征的提取和分類是完全分開的,使用脈沖時序依賴可塑性算法更新參數,本文對第1個卷積層和第2個卷積層各做50 000次權重更新。
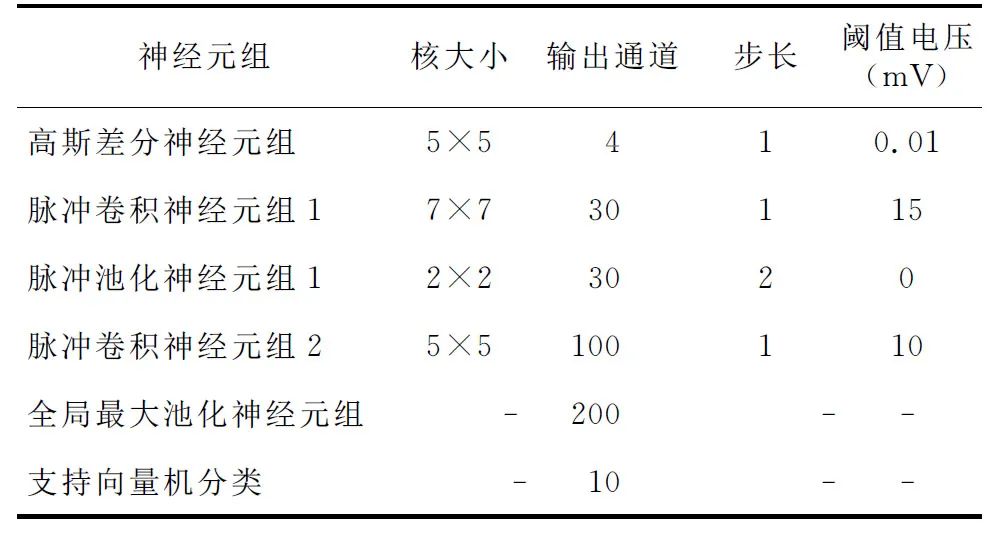
Table 1 Parameters of each neuron group表1 各神經元組參數
脈沖神經網絡通過精確的脈沖點火序列驅動,可以可視化各層輸出的脈沖序列。以輸入手寫數字“6”為例,可以得到如圖4所示的脈沖點火序列,這些圖將三維神經元組的長、寬、通道3個維度合并平攤成1個維度作為y軸,將脈沖點火時間作為x軸。
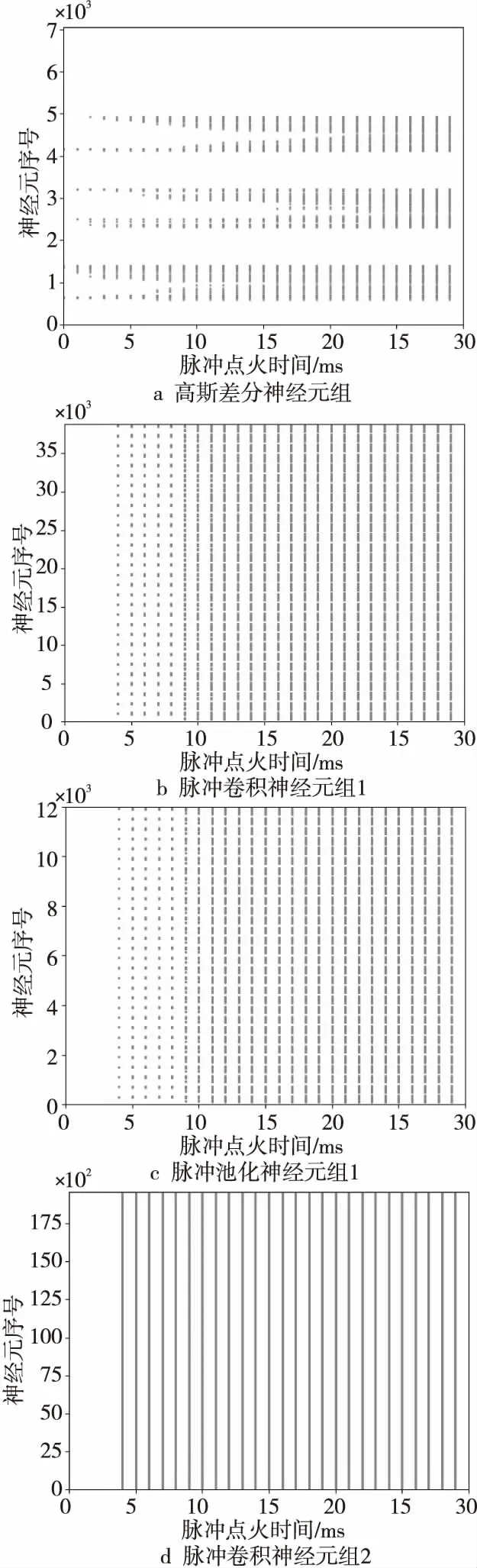
Figure 4 Spatiotemporal relationship of spiking sequences produced by neural group圖4 各神經元組產生脈沖的時空關系圖
首先,本文將分析CUDA改進的脈沖卷積神經網絡在Jetson TK1開發板上的表現,將分類準確率、網絡單次運行耗時和圖像分類幀率作為評價指標。網絡單次運行耗時把網絡的運行分為配置狀態、初始化狀態以及運行狀態3個部分;而圖像處理幀率分析實驗則是建立在網絡已經完成初始化基礎上,只關注在運行狀態1 s能夠處理多少幅圖像(FPS)。本文使用MNIST數據集,該數據集包含60 000幅大小為28×28的手寫數字灰度圖像,取其中50 000幅作為訓練集訓練網絡,取其中10 000幅作為測試集測試算法性能。
首先分析網絡單次運行耗時,Jetson TK1開發板在CPU狀態、GPU狀態以及PC機上CPU狀態下進行對比,實驗結果如圖5所示。網絡配置狀態(Config State)主要讀取網絡結構和各種超參數,這個狀態用時是最少的,在各平臺上該步驟用時都保持在0.01 s之內;其次是初始化狀態(Setup State),初始化狀態主要構建網絡結構,申請CPU內存以及GPU顯存;最后是運行狀態(Run State),運行狀態將完成脈沖神經網絡的仿真。可以看出,在Jetson TK1上,GPU模式下CUDA改進的脈沖神經網絡相比于CPU模式提升較大,GPU模式下的運行時間為3.87 s,而CPU模式下用時9.53 s。
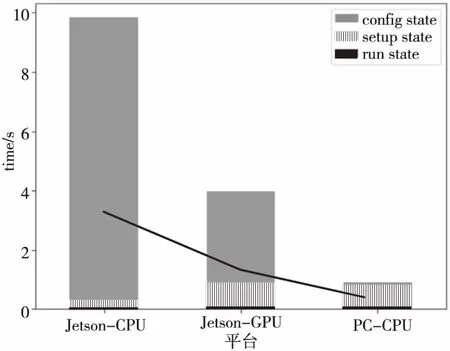
Figure 5 Time consuming comparison of spiking neural network of different states on different plaforms圖5 脈沖神經網絡在不同平臺上各階段耗時比較
接下來做幀率分析,同樣選取來自MNIST數據集中的圖像,由于幀率分析時需要1次性處理多幅圖像,這將反復執行運行狀態的代碼,而配置和初始化狀態只需執行1次。為了節省開發板資源,本文將網絡的訓練階段放到PC機上執行,然后將訓練的權重保存在開發板上,這樣開發板上的脈沖卷積神經網絡只需要專注于圖像分類的前向傳播工作,而可以忽略費時費力的網絡訓練工作。
從表2可以看出,將網絡改變成CUDA版本并部署在Jetson TK1開發板上時檢測準確率達到了98%,檢測幀率達到了0.34,相比于基于CPU的原始算法,CUDA改進的脈沖神經網絡在保證準確率不變的情況下幀率增加3倍。與基于單層脈沖神經網絡[14]的算法比較,本文算法由于增加了網絡的層數,使用了CUDA改進,在準確率和幀率上均有所提升。
5 結束語
本文提出了一種脈沖卷積神經網絡,先使用脈沖高斯差分層提取輸入脈沖的時空特征,再通過堆疊脈沖卷積層和脈沖池化層提取脈沖序列的高層特征,使用基于無監督學習的脈沖時序依賴可塑性算法訓練網絡權重,最后由支持向量機分類特征。實驗表明,該方法在MNIST數據集上有較好的分類準確率。
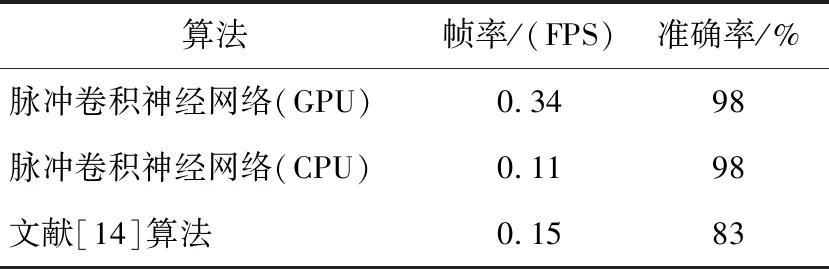
Table 2 Performance comparison among our algorithm and other algorithms on MNIST data set in Jetson TK1 environment 表2 在Jetson TK1環境中本文算法與其他算法在MNIST數據集上的性能比較
在所提的脈沖卷積神經網絡基礎上,本文提出了一種CUDA改進的脈沖卷積神經網絡模型,并將該模型成功部署在了Jetson TK1開發板上,實現了在移動GPU上的基于脈沖神經網絡的圖像處理以及圖像分類算法,并與傳統單層脈沖神經網絡的性能進行了對比。總體來說,本文提出的基于脈沖神經網絡與移動GPU計算的圖像分類算法有較強的生物可解釋性、較高的魯棒性和較快的運算速度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
