基于VGG-NET的特征融合面部表情識別*
2020-03-26 11:07:48李校林鈕海濤
計算機工程與科學 2020年3期
李校林,鈕海濤
(1.重慶郵電大學通信與信息工程學院,重慶400065;2.重慶郵電大學通信新技術應用研究中心,重慶400065; 3.重慶信科設計有限公司,重慶 401121)
1 引言
面部表情是人們傳達情感和意圖的自然而直接的手段,一個人的面部表情會無意識地流露出許多情感信息,如何讓智能機器正確分析人類所表達的情感和情緒已成為人機交互領域中的研究熱點,廣泛應用于醫療檢測、謊言檢測和多媒體等領域。隨著研究的深入,面部表情識別中的表情被分為7類[1,2],包括快樂、驚訝、悲傷、憤怒、恐懼、厭惡和中性表情。當前面部表情識別的主要任務是特征提取和分類,傳統的特征提取方法難以在不同的膚色、年齡、性別和光照條件等復雜條件下選擇特征提取。近年來,面部表情特征提取方法層出不窮,有采用基于面部子空間的特征提取方法(比如主成分分析PCA(Principle Component Analysis)[3]、線性判別分析法[4,5]等提取面部細節局部特征的方法)、基于空頻變換的傅里葉變換法[6]、基于直方圖的局部二值模式LBP(Local Binary Patterns)特征提取法[7,8]和基于頻率域的Gabor小波特征提取法[9]等。Gabor小波通過圖像紋理表示特征信息,但Gabor變換效率低下;LBP特征,即局部二值模式特征,是通過對圖像紋理灰度進行分析得到的分類能力良好的LBP特征,這類特征具有灰度不變性和旋轉不變性,但在表情的表達上容易產生較高的維數,影響識別速度。以上特征提取方法都需要人工干預,且面部靜態圖像存在受光照變換、不同的頭部姿態以及面部阻擋等干擾問題。
深度學習技術的持續發展讓人們看到了深度學習在圖像領域的巨大潛力,對于面部表情識別的研究也逐漸從傳統手工設計特征的方式轉到以深度學習技術為基礎的研究,使面部表情識別技術取得了突破性進展。李勇等人[10]通過改進LeNet-5網絡架構,將網絡中提取到的低層次特征和高層次特征相結合作為分類器的輸入,在JAFFE表情數據庫上實現了94.37%的識別率;Chang等人[11]構建了一種有效的卷積神經網絡提取輸入圖像的特征,使用復雜性感知分類算法將數據集劃分為簡單分類樣本子空間和復雜分類樣本子空間,降低了面部表情識別因環境因素而導致的復雜性;Georgescu等人[12]將卷積神經網絡學習的自動特征和由視覺詞袋模型計算的手工特征相融合,使用支持向量機作為分類器預測類標簽;Chen等人[13]提出一種強面部特征提取方法,提取表情表達峰值與中性面部表情幀中的差值表情幀特征,保留從中性面到表情面的過渡中改變的面部部分,在表情數據集上取得了較好的識別效果。
盡管已經有許多特征提取方法,但仍然存在一些問題,例如提取的特征單一化,特征受光照變化影響等。局部二值模式(LBP)側重于圖像局部紋理特征,由于其良好的旋轉不變性和光照不敏感性,被廣泛用于表情識別。本文提出了一種基于改進的卷積神經網絡結合CNN(Convolutional Neural Networks)特征和LBP特征的面部表情識別方法,根據面部局部和整體信息的組合可以有效地描述面部的表情特征。所提出的方法結合2種類型的特征以獲得更高的識別精度,并解決了對光照的魯棒性問題。本文的主要工作如下所示:
(1)利用多任務卷積神經網絡MTCNN(Multi-Task Convolutional Neural Network)算法定位面部圖像關鍵點,對圖像進行預處理。利用多尺度多關鍵點采樣方法提取LBP紋理特征,并通過PCA進行特征降維。
(2)設計了一種基于VGGNet的改進卷積神經網絡。從卷積層獲得的特征以加權方式與LBP紋理特征合并,作為最終表情分類特征。
(3)與現有的面部表情識別方法相比,在CK+和JAFFE表情數據集上進行實驗。結果表明,本文方法提高了面部表情識別的準確性,驗證了其有效性。
2 基本理論
2.1 LBP算子
局部二值模式LBP算子是用于描述圖像局部紋理特征的算子,對紋理細節特征提取能力顯著。通過比較圖像的中心像素值與周圍8個像素的值大小得到LBP值,圖像的局部紋理特征便用此值來描述。傳統的LBP算子如下所示:
(1)
其中,(x,y)是中心像素點的位置,P為采樣點個數,gp是鄰域像素點的像素值,gc是中心像素點的像素值。S(x)是一個符號函數,表示鄰域像素點的二進制值:

(2)
從式(1)和式(2)中提取的二進制代碼被轉換為十進制數,以便形成LBP圖像。傳統LBP算子不能滿足不同尺寸的紋理特征,并且不具有旋轉不變性。Ojala等人[7]提出了具有旋轉不變性的 LBP 算子,并將其定義為:
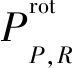
i=0,1,…,P-1}
(3)
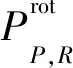
U(LBPP,R)=|S(gp-1-gc)-S(g0-gc)|+
(4)
(5)
其中,U(LBPP,R)表示0到1或1到0變化的次數,gc是矩形塊中心像素的灰度值,g0,…,gP-1為中心像素鄰域的P個灰度值,R為圓形鄰域的半徑。

Figure 1 VGG-16 network structure 圖1 VGG-16網絡結構
2.2 卷積神經網絡
卷積神經網絡CNN是一種特殊的專門用作處理具有類似網格結構數據的人工神經網絡,網絡前部是多個卷積和池化層的組合,最后連接多個全連接層與一個分類器作為輸出,現已成為圖像分析領域中的研究熱點。與傳統神經網絡不同的是,卷積神經網絡不需要網絡中每個神經元與前一層的所有神經元都進行連接,其優勢在于通過局部感知和權值共享可以減少網絡參數。在圖像特征中,每個神經元感知圖像的局部信息,利用局部信息組合成圖像整體信息,減少網絡需要學習的參數數目;權值共享通過不同的濾波器(這種濾波器又稱為卷積核)來提取圖像中不同位置的不同特征的激活值。權值實際上是不同神經元之間的連接參數,權值共享的目的就是讓若干個連接參數相同,再通過多個卷積核來提取圖像特征,得到特征值。采樣層又叫池化層,是對輸入的圖像的局部區域進行壓縮,在降低維度的同時起到防止過擬合的作用,一般常見的采樣方法為最大值(或均值)池化。牛津大學提出的VGGNet[14]網絡結構,在分類任務中功能強大,也正因如此,VGGNet網絡仍然被用作提取圖像特征。
VGG-16由13層卷積層(conv)、3層全連接層(FC)以及Softmax輸出層構成,如圖1所示。所有隱層的激活單元都采用ReLU函數;使用3*3大小的卷積核來擴大通道數,以提取更復雜和更具有表達力的特征,通過零填充保證輸出數據體的維度與輸入相同。層與層之間使用大小為2*2,步長為2的最大池化方式進行采樣,以捕獲到更細微的信息,卷積核的數量隨著卷積層數量的增加而增加,卷積層深度依次為64→128→256→512→512。
3 融合特征提取設計
本文提出了一種LBP特征和CNN特征相融合的表情識別方法,使網絡能夠學習更多具有區分性的特征,從而有效地對結果進行分類,提高識別準確性。第1類特征是LBP特征,第2類特征來自改進的卷積神經網絡卷積層特征,使用自適應加權函數將它們組合以得到用于分類的特征。具體的方法框架如圖2所示。
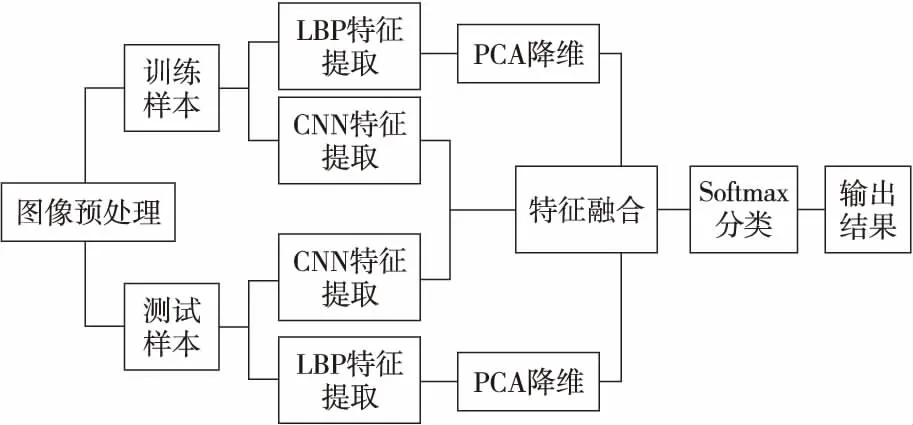
Figure 2 Framework of the proposed method圖2 本文方法框架
3.1 LBP特征提取
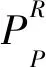

Figure 3 LBP operators of different scales圖3 不同尺度的LBP算子圖
在進行表情識別之前,需要通過面部檢測處理來分離面部和非面部。我們使用MTCNN[15]算法對數據集中的面部表情圖像進行面部檢測和特征點定位。將面部表情關鍵點如左/右眼、鼻子、左/右嘴角作為采樣區域并做仿射變換,校正面部,將面部區域圖像縮放為3個不同的尺度,包括75*75,120*120,224*224像素大小。固定采樣窗口的大小,即P=8,R=1。如圖4所示。通過在單個關鍵點周圍進行多尺度的采樣來獲取不同尺度上的局部特征,增加LBP特征的維數,并且不同的尺度使得提取到的特征既包含細節部分又擁有相對整體結構的信息,增強了特征的表達能力。考慮到數據的主要信息都集中在主成分上,因此采用無監督的主成分分析PCA方法對高維LBP特征進行降維,在降低信息的冗余度和噪聲的同時盡量減小信息損失。PCA 降維處理的具體過程如下所示:
(1)設有M個面部訓練樣本,構成特征矩陣X,其中每個樣本所對應的特征向量為xi,記為X=[x1,x2,…,xM]。則平均向量表示為:
(6)
(2)根據式(7)和式(8)將特征矩陣均值化,計算協方差矩陣P。將特征值從大到小排序取對應前k個特征向量構成矩陣U=[μ1,μ2,…,μk],其中U為經均值化后μi所組成的特征向量矩陣。經過X的k階降維轉換,得到低維空間的特征矩陣Y=X*U
(7)
(8)
由于是選取了5個關鍵點,采樣的區域大小為4*4,使用了旋轉不變的等價LBP模式將P固定為8,則 LBP模式數量為9種,再經過3次不同尺度的縮放,最終得到的LBP特征維數為2 160維(5*16*9*3)。即1個關鍵點區域包含432(16*9*3)維的特征向量,經過PCA方法降維后,每一個關鍵點區域包含60維,最終得到300(5*60)維的特征向量。通過上述步驟得到的圖像特征維數與深度卷積提取的特征維數接近。
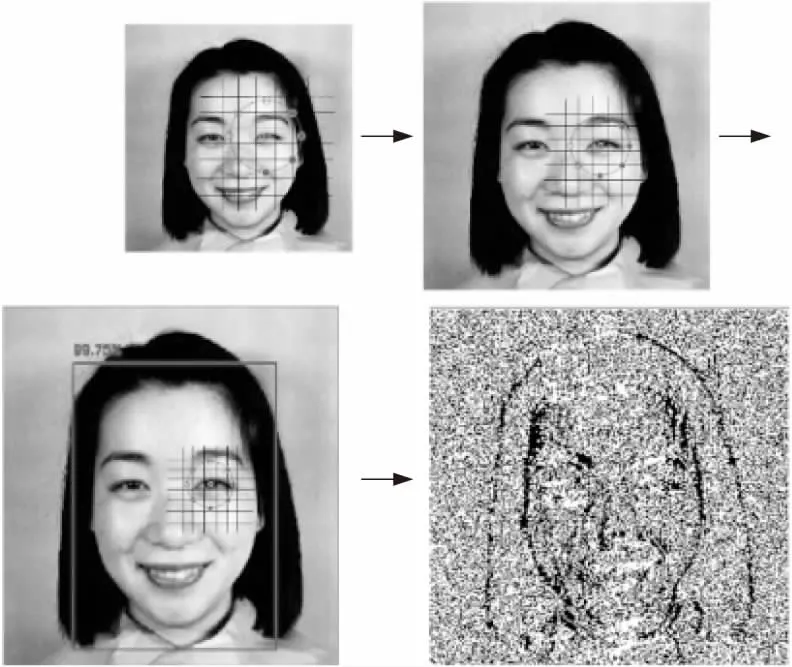
Figure 4 Face detection and multi-scale sampling LBP image圖4 面部檢測及多尺度采樣LBP圖像
3.2 改進的卷積神經網絡特征提取
在VGG-16網絡中,由于連續多次使用了小卷積核并且每一層的卷積核呈翻倍式增長,使得相應的輸出特征映射的數量變得更多,占用了更多的存儲空間。通過對原模型VGG-16進行實驗發現,在第1個全連接層上會產生非常大的參數量,使得計算量巨大,消耗了更多的計算資源。此外,由于數據集的規模制約,中小規模的數據樣本在深度網絡上表現并不好,最后的實驗結果遠遠低于預期,我們分析認為部分原因是數據規模較小產生的過擬合問題,導致模型泛化能力不足,并未能體現出深度網絡VGG-16原有的優秀性能,而通過不同方式減少神經網絡深度來減少參數量,在一定程度上是有助于防止過擬合的。受GoogleNet[16]和AlexNet[17]的啟發,在高維特征圖上使用大的卷積核直接降維,并沒有產生過多的計算,且連續的大卷積核代替小卷積核能降低模型的復雜度,進一步壓縮參數數量;減少部分全連接層并不會影響特征層的表達,反而降低了參數量。因此,本文對VGG-16結構進行以下改進:(1)在初始層的較大特征圖上使用5*5卷積核,在后3層堆疊的卷積層上依舊使用3*3卷積核,有效地降低特征圖占用的空間并保持模型的特征提取能力;(2)將第1層全連接層刪去,直接與第2層全連接層相連,其次將剩余2個全連接層中的神經元的數量降為1 024和256,減少參數數量的同時可以促使最后一層卷積層得到的特征更具區分性,有助于提升融合效果。將改進后的網絡命名為NEW-VGG,如圖5所示。網絡的輸入數據維度為224*224*3。在網絡中使用ReLU作為激活函數,并使用Dropout來解決過擬合問題。選取Softmax作為分類器用于分類任務,以估計M類中每個類標簽的概率。通常,卷積神經網絡需要在卷積層之后連接低維全連接層作為新特征層以減小特征尺寸,并且由卷積層獲得的特征通常包含豐富的圖像細節信息。因此,采用卷積層部分獲得的特征作為待融合的特征。
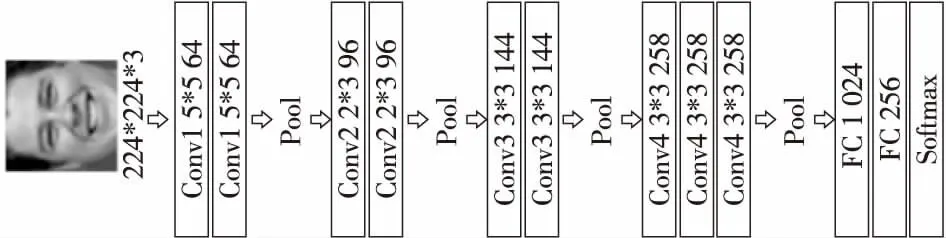
Figure 5 Improved convolutional neural network NEW-VGG圖5 改進的卷積神經網絡NEW-VGG
3.3 特征融合
本文采用特征向量拼接方法融合上述2種類型的特征。考慮到2個特征向量的不同尺寸將導致不同的特征點比,本文使用加權函數來融合2個向量,以生成新特征。具體的特征融合方法如下所示:
(1)LBP 特征和CNN 特征融合。
將n維LBP 特征向量記為VLj,VLj=(VL1,VL2,…,VLn);m維CNN特征向量記為VCj,VCj=(VC1,VC2,…,VCm)。新的融合特征向量Vfc=(VN1,VN2,…,VNN),VNi表示第i(i=1,…,6,代表6種基本表情)個類別,記為:
Vfc=αVCj+(1-α)VLj
(9)
其中,α是0~1的實數值,α和1-α分別對應于2種類型的特征的組合權重。假設有N個圖像樣本,每個樣本的維度大小為D,基于表情識別共有6類。Softmax函數用于融合特征向量中估計6類中每個類標簽的概率,如式(10)和式(11)所示:
(10)
(11)
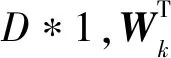
(12)
根據式(10)~式(12)計算損失函數,使用基于隨機梯度下降優化方法的反向傳播來最小化式(13):
(13)
(2)對融合特征進行降維處理。
2種特征的融合是局部特征與全局特征的信息互補,因此存在著大量的冗余信息,這就導致融合后的新特征VNi維數很高。故本文在進行特征融合時,將網絡模型最后一個全連接層的神經元數目設為256,相當于通過神經網絡模型對拼接的2種特征進行降維操作,去掉冗余信息,從而產生新的有用信息。
融合后的特征具有更強的可區分性,可進一步提升特征對光照的魯棒性,帶來更好的識別效果。將融合特征輸入到NEW-VGG模型的Softmax層中,可得到最終的分類識別結果。詳細的融合步驟如下所示:
(1)對面部圖像進行預處理。
(2)提取LBP特征。利用式(3)~式(5)在訓練樣本和測試樣本上分別提取具有光不敏感性的 LBP特征,并采用 PCA 進行降維。
(3)對NEW-VGG網絡模型參數進行初始化設置并提取CNN特征。
(4)融合2種類型特征。根據式(9)將CNN卷積層特征和 LBP 特征在 CNN 的第1層全連接層進行融合并降維。
(5)將已處理的特征導入Softmax層,以獲得最終的分類結果。
(6)參數調整。根據式(9)調整特征向量參數。根據CNN網絡調整權重參數,直到式(13)收斂到較小的值,調整完畢。
4 實驗設計與結果分析
4.1 實驗的準備工作
為了證明本文提出的特征融合的表情識別方法的有效性,本文設置了3組實驗。實驗數據來源于開源的JAFFE(the JApanese Female Facial Expression database)[18]和CK+(the extended Cohn-Kanade dataset)[19]表情數據集。CK+數據集用于訓練好的網絡模型性能測試。JAFFE數據集包含213幅圖像,是10位日本女模特的7種面部表情(6種基本表情+1種中性表情)。CK+數據集包含123位受試者的593個圖像序列,每個序列都在此數據集以中性表達式開頭并繼續達到表情頂峰,最后一幅表情都有動作單位的標簽,共含6個基本面部表情。由于CK+數據集沒有中性表情,故在實驗過程中選取6種基本表情。考慮到數據有限以及VGG-NET網絡的參數數量,本文將每種表情的標簽圖像進行一系列翻轉、平移、旋轉操作使表情樣本數據增加130倍,最后使用10折交叉驗證進行評估,其結果可直接反映網絡訓練情況和模型設計質量。2個數據集的示例集合如圖6所示。

Figure 6 Examples of facial expression in JAFFE and CK+圖6 JAFFE和CK+中的面部表情示例
4.2 環境配置和初始化設置
本文實驗環境:臺式電腦1臺,CPU為Intel(R) Core(TM)i5,8 GB內存。GPU為GTX 1060。開發環境為基于Python語言的TensorFlow框架。在訓練過程中,所有學習率設置為0.1,batchsize大小為1 000,動量為0.9,權重衰減為0.000 5,迭代次數設置為100,最大限制次數為10 000。使用隨機梯度下降優化方法訓練網絡。
4.3 實驗結果與分析
(1)參數α的影響分析。
為了探索參數α在融合特征中的作用,在JAFFE和CK+數據集上進行實驗,以找到適合數據集的α值。我們將α的值從0逐漸增加到1,其中α=0表示融合特征中僅包含LBP特征,α=1表示融合特征中僅包含CNN特征。實驗結果如圖7所示。從圖7中可以看出,隨著α值的增加,訓練模型的識別率在一定范圍內逐漸增大,當權重α= 0.6時,CK+數據集上的識別準確度達到最大值,而JAFFE數據集上的準確度則在α=0.7時達到最大。后續α再變大時,2個數據集上的準確度都呈減小的趨勢。這是由于當CNN特征增加時,融合特征中局部特征的比例減小,融合特征對光照的魯棒性降低,因為當面角變化很小時,光照的影響更明顯,為了減弱光照影響,本文更傾向加大融合特征中LBP特征的比重。鑒于此,最終取2個數據集上的平均準確度最大時的α值(即α固定為0.6)用于特征融合中。
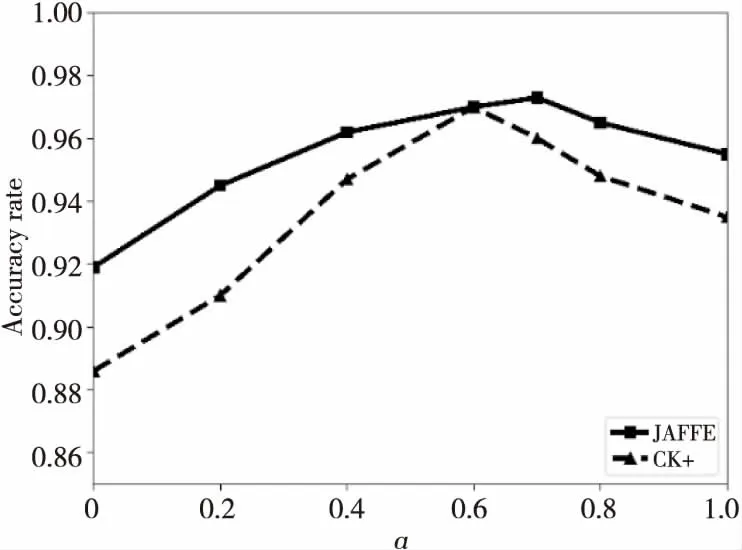
Figure 7 Evaluation of fusion weight α on different datasets圖7 不同數據集上的融合權重α的評估
(2)網絡模型的性能比較分析。
為了驗證不同尺度數據集對NEW-VGG網絡模型性能的影響,將2個增強數據集混合為1個數據集,命名為Data1數據集,共有104 780幅圖像,其中80 000幅用于訓練,其余用于測試,特征融合的權重α為0.6。將Data1分為100個批次,用Softmax訓練該網絡模型并進行反復迭代訓練以減小損失值。經過反復實驗發現,在初始設置20個epochs時,模型的損失值較大。上調epochs值到80之后,其損失值穩定在0.018,并且測試集上的性能也達到最高的99.15%。當設置更大的epochs迭代更多次時,平均識別準確度不再提高。我們認為NEW-VGG網絡在反復迭代中學習了一些高頻特征,這些高頻特征對模型提升并無幫助,還會造成過擬合的狀態,影響最終的分類任務,因此,該網絡的性能沒有進一步提高。如圖8所示。
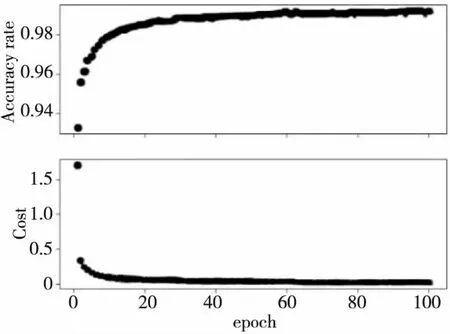
Figure 8 Training performance curve of NEW-VGG network model 圖8 NEW-VGG網絡模型訓練性能曲線
最后,在Data1上分析了GoogleNet、VGG-16和NEW-VGG網絡模型的性能。如圖9所示,隨著訓練數據集大小的增加,3種網絡的性能逐漸提高。當數據集大小達到近80 000時,NEW-VGG網絡的準確度高于其他2個網絡的準確度。同時發現,NEW-VGG網絡架構在訓練和測試速度方面明顯快于其他2個網絡結構,證明了NEW-VGG網絡可以很好地處理更多數據,也證明了改善網絡會影響面部表情識別的準確度。
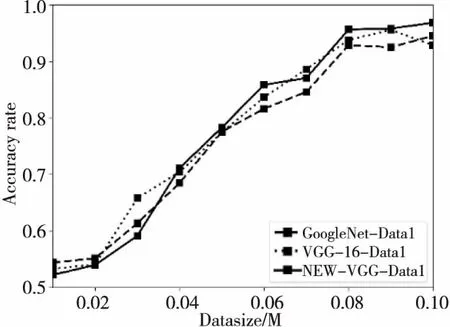
Figure 9 Recognition accuracy on different scale datasets圖9 不同規模數據集上的識別準確度
(3)不同網絡結構和特征維數比較分析。
為了驗證不同網絡結構與不同特征維數對識別效果的影響,本節使用VGG-16網絡結構以及NEW-VGG網絡結構在Data1數據集上進行實驗,分別選取不同維數的特征用于對比識別準確度,結果如表1 所示。
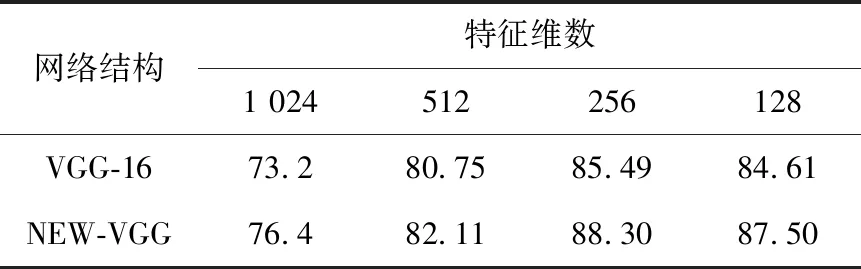
Table 1 Influence of different dimensions on recognition results表1 不同特征維數對識別效果的影響 %
實驗結果表明,隨著特征維數的減小,2種網絡識別精度并沒有隨之增加,反而是在128維時略微降低,說明特征維度在256時就足以表征Data1數據集,這256維特征包含了數據集里絕大部分的有效信息量。圖10是2種網絡結構各卷積層特征的對比圖。NEW-VGG在淺層網絡所提取到的紋理、細節特征要比VGG-16提取到的更豐富,尤其是一些關鍵特征,如眼睛特征信息等。而在更深層的網絡中,NEW-VGG提取了更多的輪廓、形狀等特征,特別是在最后一層卷積層得到的抽象特征,相對而言,這些特征更具有代表性。并且NEW-VGG網絡沒有因為簡化結構使提取特征的能力下降,綜上所述,本文采用256維的特征維度。

Figure 10 Features contrast of different convolutional layers of VGG-16 and NEW-VGG圖10 VGG-16和NEW-VGG不同各層卷積特征圖對比
(4) CK+和JAFFE數據集上的準確度分析。
本節將2個增強數據集各自進行10等分,取其中9組作為訓練集,剩余1組作為測試集,進行10折交叉驗證,通過這10組平均混淆矩陣得到最終的混淆矩陣。將10組數據做3種處理:一種是只將單一特征Basic_LBP(即傳統LBP)用于網絡訓練并進行分類得到最終結果,另一種只取來自于NEW-VGG網絡的特征并進行分類得到最終結果,最后一種是將Basic_LBP特征與CNN卷積層特征融合用于網絡訓練并進行分類得到最終結果。兩者實驗結果如表2~表4所示。
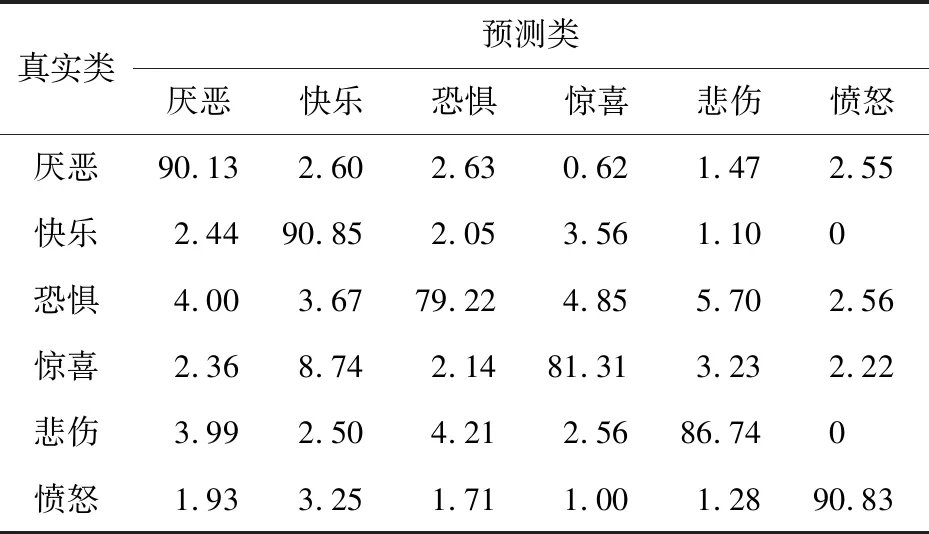
Table 2 Confusion matrix based on Basic_LBP feature (CK+)表2 基于Basic_LBP特征的混淆矩陣(CK+數據集) %
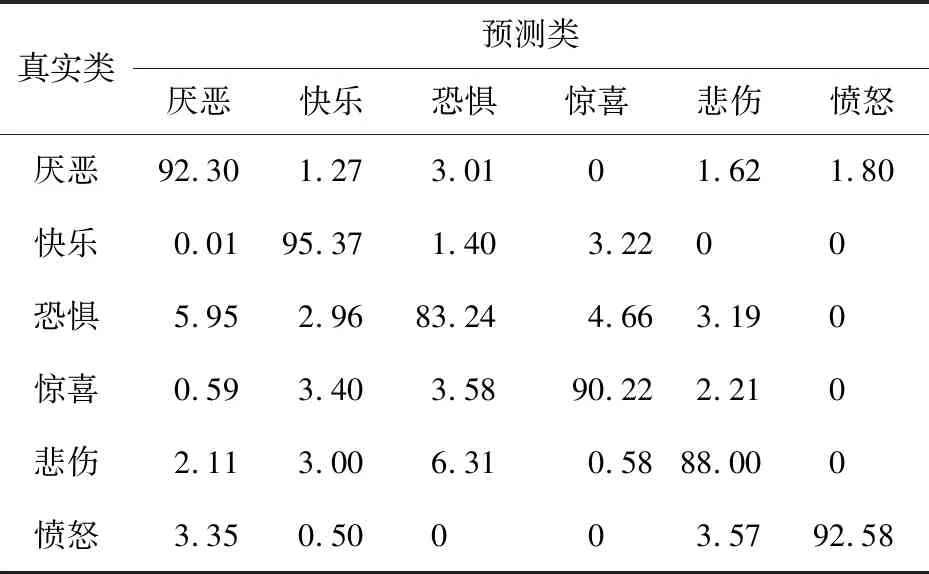
Table 3 Confusion matrix based on NEW-VGG CNN feature(CK+)表3 基于NEW-VGG的CNN特征的混淆矩陣(CK+數據集) %
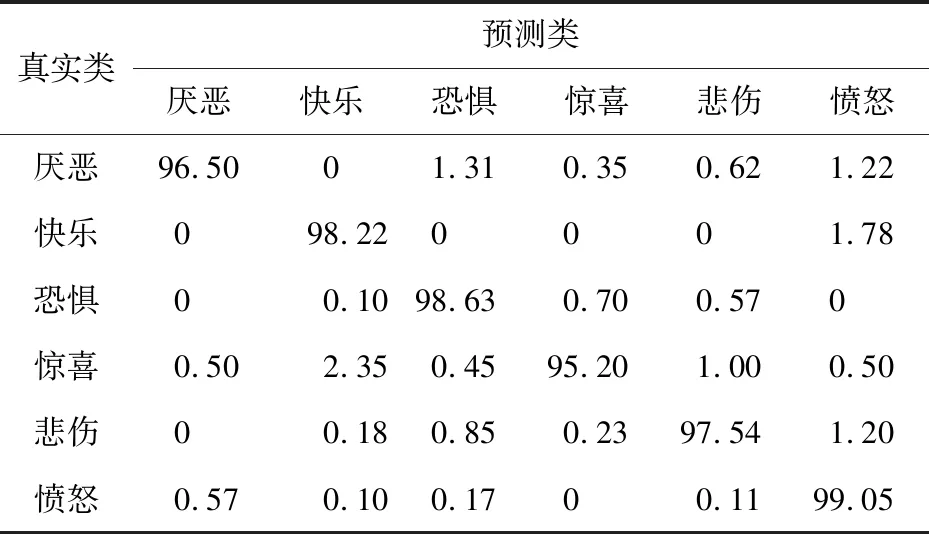
Table 4 Confusion matrix based on NEW-VGG fusion feature (CK+)表4 基于NEW-VGG的融合特征的混淆矩陣(CK+數據集) %
表2和表3是在CK+數據集上使用Basic_LBP特征和基于NEW-VGG的CNN特征計算出的混淆矩陣,表4是使用基于NEW-VGG的融合特征方法計算出的混淆矩陣。可以看出,網絡在僅有LBP特征下時,最高的識別準確度來自于表達“快樂”的表情,達到了90.85%,最低的識別準確度來自于表達“恐懼”的表情,只有79.22%。平均準確度為86.51%。觀察上述2表可知,“驚喜”的表情容易被錯誤預測為“快樂”的表情,“恐懼”的表情容易被錯誤預測為“驚喜”和“悲傷”的表情。這是因為在這幾種面部表情中,有些面部圖像中嘴巴呈閉攏狀,有些面部圖像中眼睛呈現驚恐狀,使更注重提取局部細節的LBP特征增加了錯誤概率,難以進行正確的特征分類。此外,表3中的實驗結果整體好于表2中的實驗結果,但是仍在“恐懼”與“悲傷”表情的識別上存在特征區分不明顯情況。而基于融合特征的識別方法,表情的平均識別精度為97.50%,最高的可識別表情是“憤怒”表情,達到了99.05%,增幅最大的是“恐懼”表情,增幅為19.41%。
表5和表6是在JAFFE數據集上使用Basic_LBP特征和基于NEW-VGG的CNN特征計算出的混淆矩陣,表7是使用基于NEW-VGG的融合特征方法計算出的混淆矩陣。基于Basic_LBP特征的方法獲得了89.00%的平均識別準確度,“驚喜”表情的識別準確度最高(92.00%)。與Basic_LBP特征方法相比,CNN特征方法的平均識別準確度只增長了3.11%,“驚喜”與“憤怒”表情的準確度反而有所下降。反觀使用融合特征的混淆矩陣,采用融合特征的識別準確度高于采用單一特征的準確度,準確度最高的仍是“驚喜”表情,達到99.85%,“恐懼”表情的識別度最低,只有95.00%,平均識別準確度達到97.62%,這個結果高于在CK+數據庫上實驗結果。這是因為CK+數據庫中的表情圖像有光照條件影響且表情姿勢更加難以捕獲。
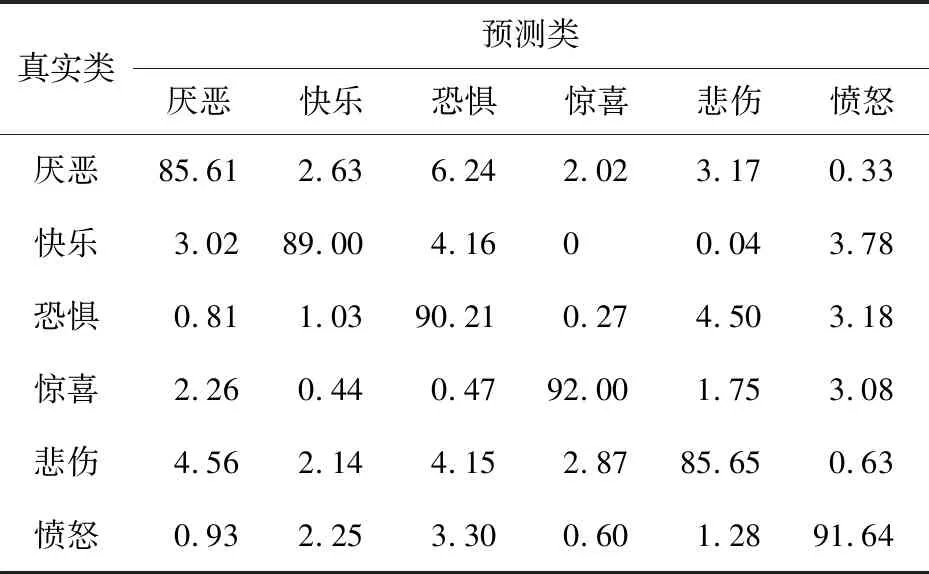
Table 5 Confusion matrix based on Basic_LBP feature (JAFFE)表5 基于Basic_LBP特征的混淆矩陣(JAFFE數據集) %
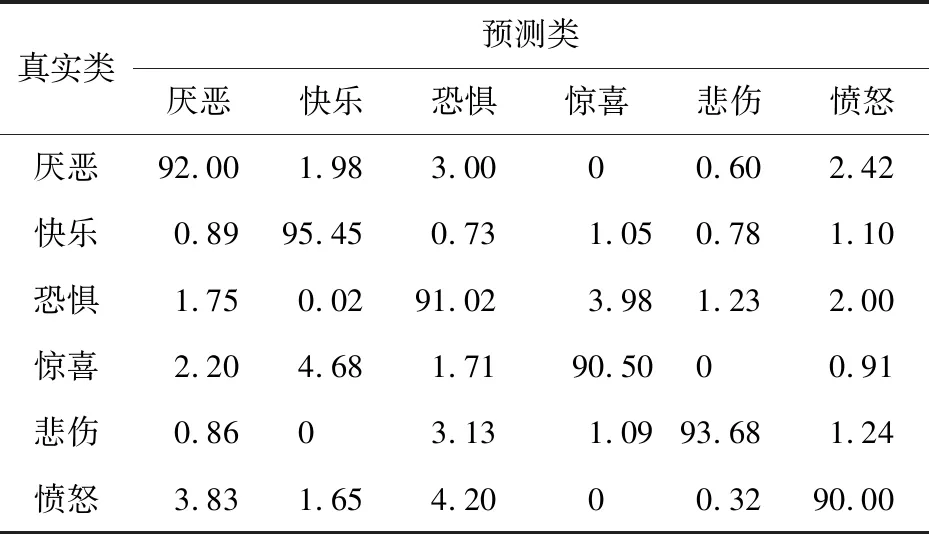
Table 6 Confusion matrix based on NEW-VGG CNN features (JAFFE)表6 基于NEW-VGG的CNN特征的混淆矩陣(JAFFE數據集) %

Table 7 Confusion matrix based on NEW-VGG fusion features (JAFFE)表7 基于NEW-VGG的融合特征的混淆矩陣(JAFFE數據集) %
本文還比較了在本文方法和其他現有方法2個數據集上的準確度,結果如表8所示。
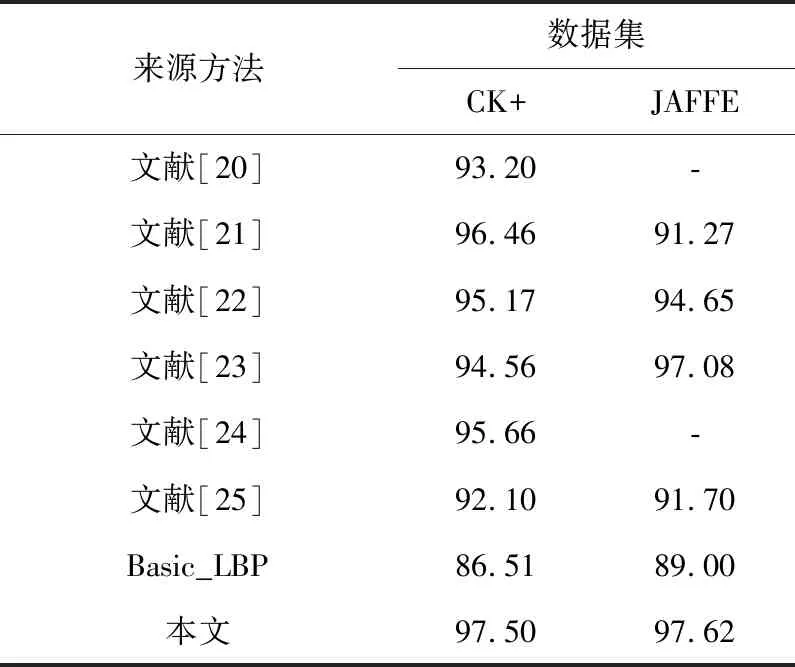
Table 8 Accuracy comparison among the proposed method and the existing methods表8 本文方法與現有方法準確度對比 %
實驗對比結果表明,本文提出的特征融合方法在NEW-VGG網絡的幫助下具有更好的表情分類能力,一定程度上提高了表情識別率。與沒有進行CNN特征融合的Basic_LBP單一特征在CK+與JAFFE驗證集上的準確度相比,其準確度分別由86.51%,89.00%達到了97.50%,97.62%。優于其他大多數方法,說明本文所提出的特征融合方法在識別不同數據集中的6個基本表情時的性能良好,有較好的泛化能力,不僅在光照變化的CK+數據集上帶來性能提升,也可增強對其他變化因素的魯棒性。
5 結束語
本文提出了一種基于NEW-VGG網絡的CNN特征和LBP特征相融合的表情識別方法。一種類型特征取自LBP特征,其使用旋轉不變的等價LBP模式,另一種特征取自卷積神經網絡的卷積層,通過權重α融合2種特征,以便更充分地利用局部特征與全局特征信息。通過不同規模的數據集驗證了改進的NEW-VGG網絡的有效性,2個基準數據集上的實驗驗證了本文方法在識別6個基本表情方面的有效性,實現了更準確、更有效的面部表情識別,尤其是可以準確地識別“快樂”和“憤怒”,還可進一步采取微調策略來修正諸如“驚喜”和“恐懼”等錯誤分類情況。此外,與其他現有方法相比,本文方法在CK+和JAFFE數據集上分別達到了97.50%和97.62%的平均準確度。然而,與Li等人[26]提出的方法相比,本文的網絡僅使用最基本的損失函數Softmax進行分類驗證,還沒有深入探討損失函數對表情識別準確度的影響,這是未來將要開始探索和研究的內容。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
