基于用戶行為的新聞推薦算法的研究*
2020-03-26 10:56:04李誠誠
計(jì)算機(jī)工程與科學(xué) 2020年3期
關(guān)鍵詞:用戶
李 增,劉 羽,李誠誠
(桂林理工大學(xué)信息科學(xué)與工程學(xué)院,廣西 桂林 541006)
1 引言
智能化交互式的網(wǎng)絡(luò)平臺(tái),使得每個(gè)人都可以是信息的上傳者和接收者。信息量的爆炸式增加導(dǎo)致信息量過載和人們需求量的嚴(yán)重不平衡[1]。因此,如何從大量的信息中找出用戶想要的信息并推薦給用戶變得尤為重要。
智能新聞推薦系統(tǒng)的出現(xiàn)進(jìn)一步迎合了用戶的需求,該系統(tǒng)不僅能幫助用戶發(fā)現(xiàn)有價(jià)值的新聞,還可以將新聞發(fā)送給對(duì)其感興趣的用戶。在國內(nèi),個(gè)性化新聞推薦系統(tǒng)也在飛速發(fā)展。2003年,Baidu推出了比較成熟的新聞推薦系統(tǒng),使之成為了當(dāng)時(shí)最成功的中文新聞推薦系統(tǒng)[2]。2008年,非負(fù)矩陣分解為推薦系統(tǒng)的設(shè)計(jì)提供了新的策略和方法[3]。2015年,研究者將隱馬爾科夫模型運(yùn)用于推薦系統(tǒng)的研究中,在傳統(tǒng)的協(xié)作型過濾算法的基礎(chǔ)上加入隱馬爾科夫模型,其推薦效果得到意想不到的提高[4]。在個(gè)性化推薦系統(tǒng)中,應(yīng)用最為廣泛的是協(xié)同過濾算法[5],根據(jù)其選取的鄰域不同,分為基于用戶的協(xié)同過濾算法和基于內(nèi)容的協(xié)同過濾算法。2種算法都存在各自的問題。對(duì)于基于用戶的協(xié)同過濾算法,其算法本身更容易忽略掉新聞的本身特性,如時(shí)效性,這就會(huì)導(dǎo)致推薦的新聞時(shí)效性不好,降低了用戶的實(shí)際接受率;基于內(nèi)容的協(xié)同過濾算法往往會(huì)忽略用戶的特性,如喜好度,這就會(huì)導(dǎo)致同一種相似的新聞大量出現(xiàn)在推薦列表中,無法達(dá)到拓寬視野的效果[6,7]。
在新聞系統(tǒng)中,用戶的所有行為都會(huì)以日志的形式保存下來。日志是記錄系統(tǒng)事件的文件集合,在新聞瀏覽過程中,用戶的點(diǎn)擊瀏覽、閱讀時(shí)長、分享、評(píng)論等操作會(huì)以日志的形式記錄下來,用戶瀏覽新聞的先后順序也會(huì)以日志的形式記錄下來。這些日志是分析用戶行為的重要依據(jù)。在前人的理論研究基礎(chǔ)上[8],用戶瀏覽新聞的行為更符合馬爾科夫過程,即下一個(gè)決策僅僅取決于當(dāng)前的狀態(tài),跟以前的狀態(tài)并無關(guān)系。因此,本文對(duì)馬爾科夫算法進(jìn)行深入研究,將其應(yīng)用于新聞推薦系統(tǒng)中。
2 用戶行為日志分析和隱馬爾科夫模型
2.1 用戶行為日志分析
用戶行為日志來自于字節(jié)跳動(dòng)公司內(nèi)部開發(fā)使用的新聞?lì)^條用戶日志,其中有10 000個(gè)用戶,523 145條記錄,出于隱私考慮對(duì)用戶的記錄做了特殊處理。圖1給出了部分用戶的行為日志。

Figure 1 Original user log圖1 原始用戶日志記錄
如圖1所示,用戶原始日志為我們提供了大量的信息,如IP可以提供上網(wǎng)地域,瀏覽時(shí)長可以提供用戶的喜好,最重要的是日志中的網(wǎng)址,這個(gè)網(wǎng)址記錄了用戶是從哪個(gè)新聞頁面跳轉(zhuǎn)到此新聞來的。這條記錄在用戶的瀏覽過程中可以形成一個(gè)閱讀鏈,這個(gè)閱讀鏈跟馬爾科夫鏈(Markov Chain)有相似之處。因此,用馬爾科夫鏈模擬用戶的瀏覽過程,更接近用戶的實(shí)際瀏覽行為。
2.2 馬爾科夫模型
馬爾科夫鏈,又稱為離散時(shí)間馬爾科夫鏈DTMC(Discrete-Time Markov Chain),其含義為狀態(tài)空間從一個(gè)狀態(tài)到另一個(gè)狀態(tài)的過程,該過程“無記憶”,即下一狀態(tài)的概率分布只能由當(dāng)前狀態(tài)決定[9,10]。
用形式化的語言描述,即當(dāng)?shù)仁絻蛇叺臈l件概率都有意義時(shí):
P(Xn+m=j|Xn=in,Xn-1=in-1,…,X1=i1)=
P(Xn+m=j|Xn=i1)
(1)
其中,in為從狀態(tài)i經(jīng)過n次轉(zhuǎn)移變?yōu)闋顟B(tài)j。當(dāng)m=1時(shí),等式成立,則隨機(jī)變量序列X=(X1,X2,…,Xn)是1個(gè)馬爾科夫鏈。其中Xi為閱讀新聞X1的狀態(tài),狀態(tài)集合為馬爾科夫鏈的狀態(tài)空間(State Space)。該鏈最大的特點(diǎn)是無后效性,即事物將來的狀態(tài)僅與現(xiàn)有的狀態(tài)有關(guān),跟以前的狀態(tài)沒有關(guān)系。這在新聞推薦的預(yù)測(cè)中,更加符合人們平時(shí)閱讀新聞的習(xí)慣。
從用戶的瀏覽日志分析可以直觀地看出用戶所瀏覽的新聞內(nèi)容,這里用其行為和內(nèi)容進(jìn)行建模,如圖2所示。其中,B1,B2,B3,B4是用戶的行為操作,即點(diǎn)擊某一類新聞網(wǎng)頁,該行為是不可見的,因此被稱為隱馬爾科夫鏈。X1,X2,X3,X4是用戶瀏覽的該類的新聞內(nèi)容。通過日志可以很容易發(fā)現(xiàn)X1,X2,X3,X4,……這樣的序列,而如何去求解下一個(gè)行為的概率是實(shí)現(xiàn)該推薦算法的核心。
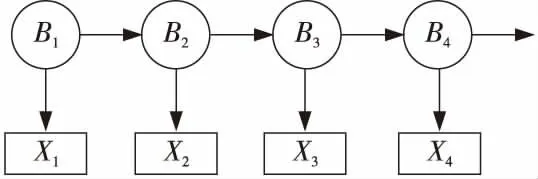
Figure 2 Markov chain model圖2 馬爾科夫鏈模型
算法模型如式(2)所示:
P(Bn)=
P(B1→B2)·P(X1)·
P(B1→B2)·P(X2)·
…·
P(Bn-1→Bn)·P(Xn)
(2)
其中,P(Bn-1→Bn)為行為的轉(zhuǎn)換概率,Bn為用戶瀏覽行為,而P(Xn)為用戶瀏覽Xn所屬某類新聞下某一新聞的概率。為了方便計(jì)算以獲得最大的概率,本文采用參數(shù)n=3計(jì)算。
2.3 相關(guān)推薦算法
協(xié)同過濾算法根據(jù)相似用戶瀏覽的新聞進(jìn)行打分,形成評(píng)分矩陣。本文采用改進(jìn)的余弦公式計(jì)算新聞Ni和Nj的相似度:
(3)
其中,Ru表示用戶u對(duì)瀏覽的新聞給出的評(píng)分平均值,Ru,i為用戶u對(duì)新聞Ni的評(píng)分。在相似用戶中,統(tǒng)計(jì)瀏覽量最高的前50條新聞,根據(jù)評(píng)分矩陣計(jì)算出評(píng)分最高的新聞加入推薦名單中。
由于新聞平臺(tái)上的相似內(nèi)容太多,推薦算法計(jì)算復(fù)雜度大,因此采用K-means(K均值)聚類優(yōu)化。K-means聚類在本文中主要有2個(gè)用處:(1)新聞聚類。把相似的新聞聚類成1個(gè)組,選取其中2個(gè)作為該類新聞的推薦,能夠減少相似新聞的推薦。(2)決定用戶的喜好。如果1個(gè)用戶瀏覽某一類新聞過多,可以推測(cè)該用戶對(duì)這類新聞的興趣比較大。假設(shè)矩陣M為用戶的偏好矩陣,矩陣中行表示用戶,列表示新聞,每個(gè)元素表示用戶對(duì)新聞的偏好度,由此可以構(gòu)建如下矩陣:
(4)
其中,m,n分別代表用戶數(shù)量和新聞數(shù)量,每1行表示1個(gè)用戶對(duì)所有新聞的偏好程度,而每1列表示所有用戶對(duì)1個(gè)新聞的偏好程度。對(duì)于某一新聞的喜好程度,很大程度上取決用戶的瀏覽時(shí)長,而瀏覽時(shí)長由用戶的日志提供,因此用戶的偏好度可由式(5)求得:
(5)
其中,btsij表示用戶i對(duì)新聞j的瀏覽時(shí)長,btsik表示用戶i對(duì)新聞k的瀏覽時(shí)長。
Top-N算法可以根據(jù)關(guān)鍵詞對(duì)新聞進(jìn)行排序,同時(shí)可以篩選出與關(guān)鍵詞相關(guān)性強(qiáng)的新聞,也可以對(duì)關(guān)鍵詞匹配高的關(guān)鍵詞進(jìn)行調(diào)整。通過Top-N算法推薦熱點(diǎn)新聞可以有效解決用戶的冷啟動(dòng)問題,從而提高算法的準(zhǔn)確度。
如果為每個(gè)用戶都建立1個(gè)馬爾科夫鏈,其計(jì)算量巨大。為了減少馬爾科夫鏈的計(jì)算量,使其更好地應(yīng)用于新聞推薦算法中,需要對(duì)用戶進(jìn)行相似度計(jì)算。相似用戶的計(jì)算應(yīng)以瀏覽新聞的相似度為基礎(chǔ),本文通過設(shè)置新聞的相似度閾值來計(jì)算相似用戶。
本文采用Jaccard相似系數(shù)進(jìn)行用戶相似度計(jì)算,如式(6)所示:
(6)
式(6)只能獲取2個(gè)用戶閱讀新聞的相似度,因此更符合本文要求。將用戶A和用戶B瀏覽的新聞集合UserAnews和UserBnews相交,產(chǎn)生共同的新聞集合,再將用戶A和用戶B瀏覽的新聞集合相并,得出2個(gè)用戶的新聞總集。用共同的新聞數(shù)除以新聞總數(shù),其結(jié)果即是兩者的相似度。本文設(shè)置1個(gè)閾值,即若User_similar>50,就認(rèn)為用戶A和用戶B為相似用戶。
3 基于隱馬爾科夫模型的混合算法設(shè)計(jì)與實(shí)現(xiàn)
3.1 隱馬爾科夫算法狀態(tài)轉(zhuǎn)換
通過協(xié)同過濾算法可以很容易地計(jì)算出用戶瀏覽每一類新聞的概率P(B)。而在每類新聞中所投票選舉出來的新聞?dòng)挚梢宰鳛橄乱淮胃黝愋侣劦目蛇x新聞集,如果每類新聞的前5條作為候選,那么點(diǎn)擊這5條新聞的概率就是1/5。
在實(shí)際中,每個(gè)用戶閱讀的新聞數(shù)量有限,這就導(dǎo)致了隱馬爾科夫鏈的長度不一。根據(jù)以上模型,本文采用用戶最近的3條瀏覽記錄作為模型的參數(shù)n,推算出下一次最大概率要瀏覽的新聞。
根據(jù)最后3次的操作B1,B2,B3,求解B4作為預(yù)測(cè)用戶的點(diǎn)擊動(dòng)作,其狀態(tài)轉(zhuǎn)換過程為:
P(B1)=P(Xi),i=1,2,3
(7)
式(7)表示在B1動(dòng)作下,用戶點(diǎn)擊新聞瀏覽的概率可以是P(Xi),i=1,2,3。
P(B2)=P(B1→B2)=
(8)
式(8)是B1→B2狀態(tài)的轉(zhuǎn)換過程,其中Yi表示第2類新聞下的內(nèi)容,而P(Yi)是Yi在所屬新聞?lì)愡x出來的概率,max(·)表示取矩陣中的最大元素值。因此,得出B2可能出現(xiàn)的概率。同理B2→B3的狀態(tài)類似,因此可以得到B4存在的概率。
P(B3→B4)=
(9)
其中,Ci表示在B3狀態(tài)下瀏覽的該新聞?lì)愊碌钠渌侣劇(C1)表示C1新聞出現(xiàn)的概率。選取式(8)得到的概率矩陣中前幾個(gè)最大概率的新聞作為推薦名單。
3.2 隱馬爾科夫算法的實(shí)現(xiàn)
本文采用隱馬爾科夫算法為主要算法,輔以協(xié)同過濾算法和Top-N算法進(jìn)行混合推薦。協(xié)同過濾算法能夠快速對(duì)新聞進(jìn)行評(píng)分,而Top-N算法能快速選取最優(yōu)的新聞,加入到隱馬爾科夫算法的候選名單中。因此,輔以這2種算法比傳統(tǒng)的排序查找能更快得到候選新聞集合。用韋恩圖表示如圖3所示。
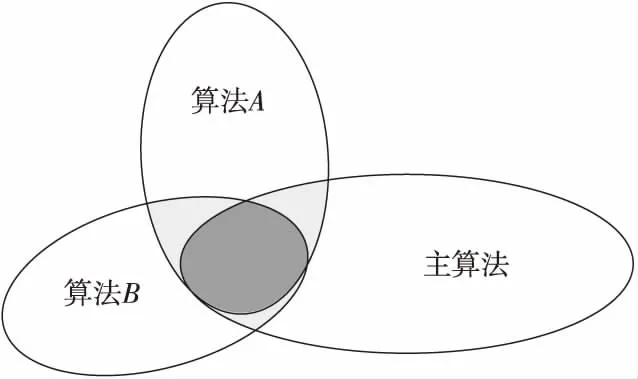
Figure 3 Wayne diagram of result set 圖3 結(jié)果集韋恩圖
算法A為基于內(nèi)容的協(xié)同過濾算法,算法B為Top-N算法,A、B算法重疊的部分表示2個(gè)算法得出來的新聞推薦列表,用來做隱馬爾科夫算法的候選新聞集合,最終得到新聞推薦列表。這樣在減少了主算法計(jì)算量的同時(shí),提高了其推薦的準(zhǔn)確度。
上述組合算法的流程圖如圖4所示。

Figure 4 Flow chart of algorithm 圖4 算法流程圖
隱馬爾科夫算法步驟如下所示:
步驟1根據(jù)新聞數(shù)據(jù)集和用戶行為日志,分別計(jì)算相似新聞和相似用戶,將相似新聞放入同一個(gè)集合,相似用戶放入同一個(gè)集合。
步驟2通過協(xié)同過濾算法得出推薦名單;同時(shí)以并行模式用Top-N算法計(jì)算各相似新聞集合中點(diǎn)擊量最高的前3條新聞,作為隱馬爾科夫計(jì)算狀態(tài)。
步驟3計(jì)算2個(gè)推薦名單的并集和交集。
步驟4根據(jù)馬爾科夫算法從相似用戶集合中隨機(jī)選擇一位用戶,計(jì)算該用戶最近3次瀏覽的新聞ID,統(tǒng)計(jì)這3條新聞所有的瀏覽用戶的下一條新聞,生成馬爾科夫鏈。
步驟5若新聞存在于并集中,則將該新聞加入新的推薦名單中,若不在,則舍棄。將新生成的推薦名單和交集上的新聞合并,得出最后的推薦名單,根據(jù)馬爾科夫鏈,選舉出票數(shù)最高的前30條新聞,推送給用戶。
其隱馬爾科夫算法的偽代碼如下所示:
begin:
initializeβ,T,t∈T,aij,bjk,可見序列VT;
fort←t-1;
untilt=1;
returnP(VT)←βi(0)//已知的初始狀態(tài)
end
其中,T為通過協(xié)同過濾和Top-N算法得出的推薦名單集合。VT表示可見序列集合,可見序列為用戶行為序列,即用戶瀏覽新聞序列。for循環(huán)中執(zhí)行的是計(jì)算狀態(tài)t-1到狀態(tài)t的概率。βi(0)為第i個(gè)用戶的初始化狀態(tài),aij表示第i個(gè)用戶在該狀態(tài)下瀏覽的新聞,bjk表示該新聞?lì)惖钠渌侣劇?/p>
4 實(shí)驗(yàn)和結(jié)果分析
本文選取的硬件實(shí)驗(yàn)平臺(tái)為若干型號(hào)相同的電腦,操作系統(tǒng)是Linux CentOS 6.5,Spark版本是2.2.0,處理器是Intel I7四核處理器(Quad core processor),8 GB運(yùn)行內(nèi)存,1 TB硬盤。
本文主要實(shí)現(xiàn)基于Spark的隱馬爾科夫算法在推薦算法中的應(yīng)用,通過輔以基于內(nèi)容的協(xié)同過濾算法和Top-N算法,使其準(zhǔn)確度更好。本文通過2個(gè)實(shí)驗(yàn)來驗(yàn)證其混合算法的優(yōu)越性。
在推薦效果測(cè)評(píng)中,準(zhǔn)確率和召回率是常用的測(cè)試指標(biāo),本文采用該指標(biāo)對(duì)算法進(jìn)行測(cè)評(píng)的時(shí)候需要對(duì)新聞進(jìn)行劃分。
本文采用準(zhǔn)確率和召回率來評(píng)價(jià)實(shí)驗(yàn)的結(jié)果:
(10)
(11)
其中,NRS,NRN分別表示感興趣的新聞推薦的條數(shù)和未推薦的條數(shù)。NIS,NIN分別表示不感興趣的新聞推薦的條數(shù)和未推薦的條數(shù)。NS,NN分別表示推薦的新聞總條數(shù)和未推薦的新聞總條數(shù)。
不同數(shù)據(jù)量下的準(zhǔn)確率和召回率如圖5所示。
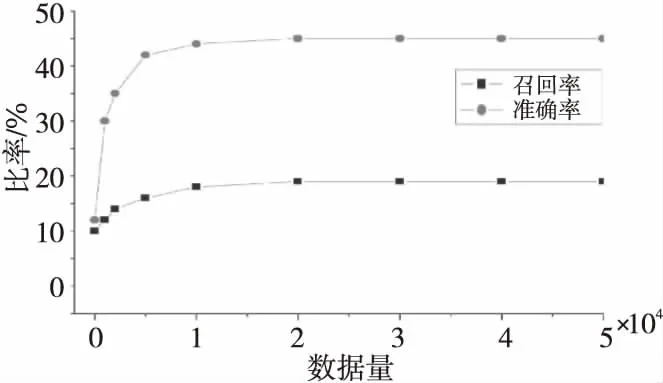
Figure 5 Accuracy and recall under different data volumes圖5 不同數(shù)據(jù)量下的準(zhǔn)確率和召回率
通過圖5可以看出,算法的性能與數(shù)據(jù)的復(fù)雜度有關(guān)系,隨著數(shù)據(jù)量的增加,新聞集中會(huì)有越來越多的“過期”新聞,對(duì)于馬爾科夫算法來說,算法的性能隨著推薦數(shù)量的增加而提高。當(dāng)數(shù)據(jù)量在10 000以上時(shí),其準(zhǔn)確率穩(wěn)定在45%,而召回率穩(wěn)定在19%。即超過一定的閾值時(shí),該算法的性能既不會(huì)提高也不會(huì)降低。
通過對(duì)不同的算法的實(shí)驗(yàn),得出在同樣的數(shù)據(jù)下,不同算法的準(zhǔn)確率和召回率,其結(jié)果如圖6所示。

Figure 6 Accuracy and recall comparison of each algorithm 圖6 各個(gè)算法準(zhǔn)確率和召回率對(duì)比
通過圖6可知,在同樣的數(shù)據(jù)下,通過余弦相似度計(jì)算方法的協(xié)同過濾算法的準(zhǔn)確率為28%,基于Person的協(xié)同過濾算法的準(zhǔn)確率在33%左右,基于內(nèi)容的推薦算法的準(zhǔn)確率為38%,而基于馬爾科夫算法的準(zhǔn)確率達(dá)到了45%,這說明本文的基于馬爾科夫算法在新聞推薦系統(tǒng)中的應(yīng)用明顯優(yōu)于其他推薦算法,且召回率和準(zhǔn)確率有明顯的提高。
實(shí)驗(yàn)顯示,以馬爾科夫?yàn)橹魉惴ɑ旌匣趦?nèi)容的協(xié)同過濾算法和Top-N算法,在新聞推薦中其準(zhǔn)確率明顯比傳統(tǒng)的算法要高。
通過對(duì)比基于內(nèi)容的協(xié)同過濾算法在相同的數(shù)據(jù)中的運(yùn)行時(shí)間,來進(jìn)行其運(yùn)行效率的驗(yàn)證。實(shí)驗(yàn)結(jié)果如圖7所示。
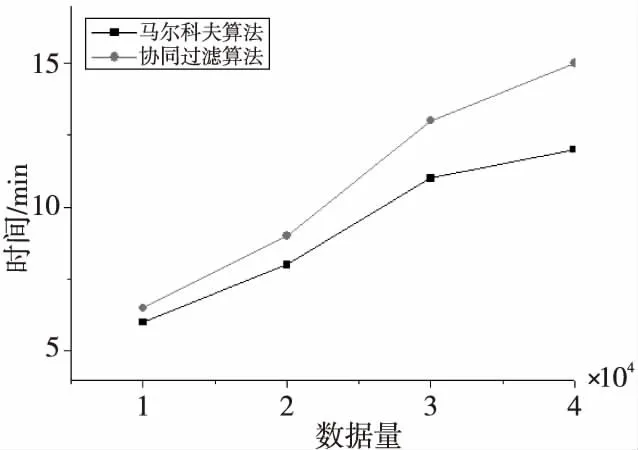
Figure 7 Comparison of running time of algorithms圖7 算法運(yùn)行時(shí)間對(duì)比
通過圖7可以看出,在相同的運(yùn)行環(huán)境和相同的運(yùn)算數(shù)據(jù)下,以馬爾科夫算法為主算法的混合推薦算法的運(yùn)行時(shí)間相對(duì)少于基于內(nèi)容的協(xié)同過濾算法的,也就是馬爾科夫算法的運(yùn)行效率要好于協(xié)同過濾算法。但是,由于混合算法的輸入輸出延誤,導(dǎo)致其效果并不是太明顯。
5 結(jié)束語
從人們?yōu)g覽新聞的行為出發(fā),分析其瀏覽新聞的無目的性更接近于馬爾科夫鏈。因此,將馬爾科夫算法應(yīng)用于新聞推薦系統(tǒng),通過大量的實(shí)驗(yàn)數(shù)據(jù)對(duì)比表明,該算法在推薦過程中比傳統(tǒng)的推薦算法更有效,其準(zhǔn)確率和運(yùn)行效率更好。但是,該推薦算法具有一定的局限性,即計(jì)算復(fù)雜度由所選的行為參數(shù)形成的矩陣所決定,若行為參數(shù)過大,數(shù)據(jù)量隨之增加,其計(jì)算復(fù)雜度也會(huì)相應(yīng)提高,從而影響推薦效率。因此,在后續(xù)研究中,會(huì)進(jìn)一步優(yōu)化算法效率和行為參數(shù)的選擇,提高推薦的準(zhǔn)確度。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業(yè)黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛(wèi)星與網(wǎng)絡(luò)(2016年12期)2016-02-05 09:23:23
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
