巖土工程地質結構特點及勘察數據處理系統設計應用
2020-03-29 04:03:48李小明
中國金屬通報 2020年18期
李小明
(九江地質工程勘察院,江西 九江 332000)
我國的地質問題一直是學界研究的重點,因其具備復雜多變的地貌、發展迥異的各地地質環境,在這一環境下進行垃圾填埋、跨地區調水、建設樓房等,對于巖土工程地質結構的工程師來說,都是極大的挑戰。巖土工程的產生源于土木工程的實際需要,它將地質學和力學兩大學科進行結合,對工程師的技術要求較高,具有很強的學術性和實用性。
巖土工程地質的側重點在于解決生產和建設活動中出現的巖土技術問題,在工程的開發和運營過程中要求工程師做到實時監督工程目標,對地質條件進行勘察,需要工程師對整個工程的建設、開發及后續的運行管理等方面的安全問題負責[1]。因此,巖土工程地質結構就具備了重視觀察、重視實際應用的特性。在工程正式開始前,巖土工程地質的工程師需要通過勘察地質、地形、地貌,并整合勘察數據,判斷地下的地質結構全貌,預測在施工過程中會遇到哪些問題,對斷層、深溝、地下巖石的種類都要做出科學的預判,同時,通過勘察數據,幫助施工團隊打造施工方案,做到綜合運用物探、洞探等工程技術手段,明確地質結構的優勢方向。設計勘察數據處理系統,對巖土工程地質的開發和研究有極大幫助。
1 巖土工程地質結構特點
巖土工程地質結構具有復雜多變的特點,因此在巖土工程開發過程中使用勘察工具,經常會勘察出大量數據資料與信息。巖土工程工作的推進,離不開對這些勘察數據進行分析和處理。如果不對勘察數據進行分析,就無法深入了解到地質內部的結構,也無法對其作出有效的判斷,進而會影響到整個工程的開展。工程概況、預施工地地質情況、勘探設備狀況、現場模擬測試、室內模擬實驗等幾個方面,組成了巖土工程地質數據勘察[2]。在完成數據勘察后,需要整理信息,整合全部數據,做出工程實施報告,通過巖土工程技術及時向施工單位做出反饋,并輔助其進行相關方面的整改。
因此,使用勘察數據是巖土工程地質的硬性需求。而在巖土工程地質的開采設備和勘察設備都更新換代的同時,勘察數據的采集、整理和處理仍存在處理方法落后、效率差等問題。這是因為巖土工程地質結構的數據勘察處理辦法,存在分析速度較慢的問題,無法適應新時代的新需求。
2 系統硬件設計
2.1 選擇能夠搭載虛擬服務器的CPU
設計勘察數據處理系統,需要硬件設備的支持和網絡環境的搭建。從投資、使用度等方面考慮,選用普通的P Ⅱ300 計算機就可以滿足系統搭建的需求,同時需要用到的設備還有:能夠搭載虛擬服務器的CPU。
虛擬服務器的使用方法為通過整合線下的物理存儲服務器,將服務器中數據進行采集和分析對比,利用虛擬化技術,將多臺設備通過資源分配方法,整合到一臺配置較高的虛擬服務器中,通過數據資源共享模式,將多區域的物理服務器轉化為虛擬服務器的運作能源[3]。如圖1 所示。
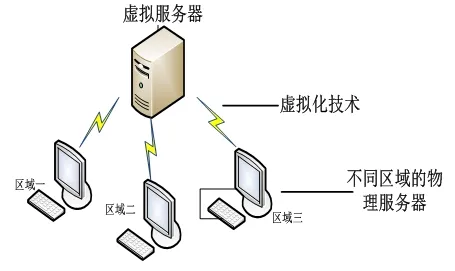
圖1 虛擬服務器運行方法
如圖所示,物理服務器的數據運算功能通過虛擬化技術匯總到虛擬服務器中,而虛擬服務器的虛擬機在VMware VirtualCenter 平臺進行運行。主板的CPU 性能決定了虛擬服務器的運算能力,虛擬機的運行效率受CPU 主頻參數影響。CPU 主頻的參數影響著整個服務器的工作效率。CPU 的運算能力越強,意味著它的主頻越高。因此在勘察數據處理系統的設計中,必須保證搭載虛擬服務器的CPU 內核有足夠大的空間進行運算。所以需要使用能夠滿足需求的大內存CPU。
CPU 的選擇方法如下:假設搭載的服務器應對CPU 的最大使用率為6023,那么在整合物理服務器過程中,需要使用的虛擬機的CPU 運算能力至少為1.2GHZx5 %=6GHZ,那么在選用CPU 時,應當選用定值不低于主頻為6GHZ(即運算能力為1x2x6=12GHZ)的雙核CPU。
通過合理運算,選取更適合本次系統設計的CPU 完成虛擬系統服務器的搭建,為本次勘察數據處理系統設計提供良好的硬件支持。
2.2 固態硬盤設計
在設計巖土工程勘察數據處理系統的過程中,因為巖土工程勘察數據通常具有保密性質,因此需要對存儲數據使用的固態硬盤進行保密化處理。
對硬盤進行保密化處理設計,主要集中在對硬盤用戶的身份驗證環節進行設計,因為使用者的身份信息是公開的,而用戶身份則會受到固態硬盤內部的用戶表和權限表的檢測。可以使用yubikey5 系列的USB 安全密鑰加固硬盤數據,安全密鑰能夠生成板載RSA1024 位和2084 位安全密碼,同時具備雙因素身份認證令牌,能夠有效降低固態硬盤的使用風險。
3 系統軟件設計
3.1 相似勘察數據計算模型設計
將從巖土工程地質結構勘察中得到的數據,使用字母符號或者數字符號來代替相關數據的實際名稱。將這些數據進行定性,并使用代碼的方式將其標識,對數據的規范化有一定的幫助,同時也能縮短數據整理時間,對規范行業起到一定的示范作用,也有助于提升后期在系統中查詢、搜索的工作效率[3]。比如不同地層在數據庫中就可以使用代碼來表示,代碼的設置見表1。

表1 不同地層的數據代碼
由表1 可知,統計數據的對象主要是指不同位置的地層名稱,每一層地質結構都代表了不同的土質特性和積層強度,通過數字代碼將地層剖面直觀化展示。使用規范化數據統計方式,能夠更快捷地完成對相似數據區分的計算。對相似數據進行區分,需要對數據集分類后進行計算。計算方法如下:
用T 來代表地質勘察數據來源中一個數據節點,稱它其中的連續子序列為satisfy,而T 中所有來源為n 的satisfy 集合定義為S(T,n),假設兩個地質勘察數據Q4-1(數據A)和Q4-2(數據B)的相似程度定義為:
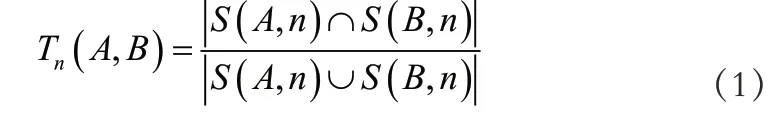
用D 代指數據間的關聯性,則關聯性可定義為:
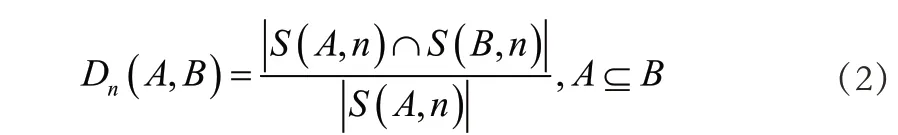
通過上述定義公式,可以看出數據的相似程度計算取決于n的取值,即數據的來源,通過數據的上傳渠道和所在區域,通過計算,能夠對數據A 與數據B 的相似程度進行區分。構建區分數據相似度的計算模型。
3.2 設置功能模塊
為給巖土工程地質勘察數據處理系統提供數據支持,為此建立了數據庫。數據庫的建立流程見圖2。

圖2 數據庫建立流程
如圖3 所示,建立數據庫,首先要對數據進行分析和整理,然后分析數據的功能和數據庫的具體使用目的,最后完成數據庫的建立。巖土工程地質勘察經過整理,已按照地質、地層等特征進行整理和匯總,初步建立了數據庫構架。
巖土工程地質勘察數據處理系統依托數據庫的數據支持,可以開始對數據進行分析和處理。完成對數據的采集和整理后,利用大數據技術,構建多個數據模塊。分成子系統和母系統,在將各個模塊進行分類的同時,發掘這些數據和信息之間的時間、空間關聯,并進行連接;通過不同模塊的組成,完成勘察數據處理系統的設計。利用代碼,設置數據處理系統中的基本功能。使用系統硬件,完成整個地質勘察數據處理系統的搭建。
4 實驗論證分析
4.1 實驗準備
使用的CPU 為Intel core i5,CPU 內核/線程為10/20,時鐘速度5.2GHZ,使用CPU 搭載虛擬服務器A1,三臺不同區域的物理服務器代號為B1、B2、B3 作為環境支持,完成實驗測試環境搭建。傳統設計下的數據處理系統同樣會參與實驗,進行比較。
4.2 實驗過程及結果
實驗目的是驗證勘察數據處理系統的處理速度,是否能夠滿足巖土工程地質開發的相關工作。將本文設計的系統與其他兩種傳統數據處理系統的搜索結果進行比較。首先將5GB 大小的原始勘察數據加入系統中,進行數據處理。隨后依次向系統中導入原始勘察數據,數據大小為10GB、15GB、20GB、25GB、30GB,記錄每次處理數據的速度。為保證實驗的準確性,在數據處理完成后,清除系統的后臺數據,重新導入不同規模的勘察數據進行實驗。實驗結果取三次實驗的平均值。結果如下:

圖3 不同系統處理數據時長
由圖3 可以看出,本文設計的勘察數據處理系統,在處理大量數據時,處理時間明顯少于傳統設計下的勘察數據處理系統。可見本文設計的地質勘察數據處理系統,在巖土工程地質開發過程中,有較高的實用性。
5 結束語
結合巖土工程地質結構特點,完成勘察數據處理這一設計要求。本文的地質勘察數據處理系統能夠有效運用到實際的巖土工程工作中,而存在的不足之處,將在日后通過對算法、巖土工程相關知識的進一步學習來彌補,使勘察數據處理系統能夠更好地為巖土工程服務。
猜你喜歡
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
財經(2017年2期)2017-03-10 14:35:35
太空探索(2016年6期)2016-07-10 12:09:06
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
筑路機械與施工機械化(2015年11期)2015-07-01 16:28:43
筑路機械與施工機械化(2015年8期)2015-01-11 09:24:54
