文本情緒原因檢測研究綜述
2020-04-01 18:12:34陳珊珊姚攀
現代計算機 2020年6期
陳珊珊,姚攀
(四川大學計算機學院,成都610065)
0 引言
當今是一個信息豐富,網絡發達的社會,互聯網為人們的工作生活帶來極大便利,人們利用社交媒體了解時事、分享經歷、表達情緒,網絡空間中出現了大量包含情緒的文本數據,例如產品評論或者對熱點事件的討論等。從海量文本中識別和理解情緒成為自然語言處理領域中重要的研究方向之一。早期,對情緒分析的研究大多數集中在情緒分類、情緒識別等任務[1]。但是,在實際生活中,企業組織或服務人員有時更關心文本中表達某種情緒背后的原因。他們可以根據消費者產生情感的原因,有效地提高產品的性能或服務質量。例如,某顧客發布一條評論,“旅店的無線網絡極其差勁,嚴重影響我工作,太讓人生氣了,下次不會再來了。”酒店經理更想知道顧客為什么不喜歡他們的酒店,而不是簡單的情緒分類。在確定情緒產生的原因后,他們可以改善無線網絡環境,吸引更多的客人,這顯然比單純了解顧客是否滿意更加具有實踐上的指導意義,所以對文本情緒原因檢測的研究具有重大的商業應用價值。相比與一般情緒分類任務,情緒原因檢測需要更深層次的理解情緒與情緒原因間的關系,具有更高的難度。
本文結構分為三個部分,第一節介紹文本情緒原因檢測的任務描述和主要方法;第二節介紹相關語料資源的基本情況;第三節總結和展望。
1 文本情緒原因檢測研究現狀
1.1 任務描述
情緒原因檢測任務是指識別文本中觸發某一情緒的原因[1],具體做法是將文本分割為多個子句,在已知情緒表達的情況下,識別文本中的子句是否包含情緒原因。如例句1,已知“傷心”的情緒,識別目標是原因所在子句“卻被告知丈夫殉職的噩耗”。

1.2 規則方法
文獻[1]首次提出情緒原因檢測任務,基于Sinica語料庫構建了一個較小的情緒原因數據集[1],通過觀察、分析數據集,總結出與文本情緒原因有關的常見使役動詞、原因連詞、感知動詞、連詞、其他線索詞等,歸納了七組語言學線索,并構建相應的規則系統。隨著社交媒體的發展,情緒原因檢測在微博文本中有了較大的需求。由于微博文本語言表達口語化和生活化,多為短句,并含有較多表情符號,與普通新聞文本存在差異,解決新聞文本的規則并不適用于微博本文,文獻[2]在文獻[1]提出的規則基礎上,針對微博文本的特點重新定義了適用于微博文本的規則。文獻[3]提出從情緒原因到情緒表達可以看作一個認知的過程],研究產生情緒的常識知識有助于情緒原因檢測,文中搜集了情緒原因詞對,構建情緒——情緒原因常識知識庫,并利用其他情緒表達知識庫對其進行擴展,用基于規則的方法實現情緒原因檢測。實驗顯示常識庫可以作為基于規則模型的情緒原因檢測方法的有效補充,提高情緒原因檢測的效果。
1.3 機器學習方法
基于規則的方法不能覆蓋所有語言規則,存在規則繁多、覆蓋率低的缺點;針對不同風格的文本,需要重新構建相應規則。與傳統的基于規則方法相比,基于統計機器學習的方法不需要更新大量的規則,所以研究人員選擇機器學習的方法來解決文本情緒原因檢測問題。
基于機器學習的方法又可以分為分類方法和序列標注方法。采用分類的方法,文獻[4]將情緒原因檢測任務看作多標簽分類問題,并泛化文獻[1]提出的規則,設計了基于語言學規則的特征和情緒原因檢測的通用特征。文獻[5]將情緒原因檢測看作二分類問題,將人工構建的規則,候選原因子句與情緒表達的位置關系,情緒原因的詞性標注作為特征編碼候選原因子句,用SVM對子句進行分類。文獻[6]利用卷積核的學習方法訓練多核分類器,用于識別情緒原因事件,文中定義了一個7元組描述情緒原因事件,使用語法結構來獲取情緒原因的結構特征和詞匯特征。
分類模型將文本中每個子句單獨對待,無法捕捉子句標簽之間的關系。文獻[7]將情緒原因檢測任務看作序列標注問題,文中分析了詞性特征,情緒表達與情緒原因之間的相對距離特征,語言學規則特征,采用條件隨機場算法(CRF)對特征序列進行學習和標注。序列標注模型可以克服分類模型無法利用文本子句間關系的缺點,同時模型融入詞法、相對距離和語法規則等特征,提高模型識別效果。
1.4 神經網絡方法
情緒表達與情緒原因的關系通常是語義相關的,基于規則和機器學習的方法都只是在對于情緒原因子句上的特征進行分析和提取,少有考慮到情緒表達子句與原因子句間的語義關系。由于神經網絡模型自動學習特征的優勢,越來越多的研究人員使用神經網絡模型來解決情緒原因檢測問題。
(1)考慮情緒表達子句與原因子句間的關系
文獻[8]從問答系統的角度來解決文本情緒原因檢測問題,研究結合注意力機制的記憶網絡[8],建模文本中情緒表達與情緒原因之間的相關關系。將文本分成多個子句,模型接受候選情緒原因子句和情緒表達關鍵詞兩個輸入,通過注意力機制建模兩個輸入的關系,以此判斷候選情緒原因子句是否為情緒原因子句。該方法為后續的研究者提供新的研究思路與方向。文獻[9]提出將情緒表達關鍵詞作為查詢輸入,這一做法忽略了情緒表達關鍵詞的上下文所包含的信息。例如例句2,其中情緒表達關鍵詞為“沮喪”,情緒原因子句為子句④“馬刺隊的鄧肯也宣布退役”:
例句2:
①在2016年,
②湖人隊的科比宣布退役,
③同一年,
④馬刺隊的鄧肯也宣布退役。
⑤ 馬刺隊的隊員和鄧肯的粉絲都感到十分沮喪。
若將“沮喪”作為查詢輸入,文本中每個子句作為被查詢內容,那么子句②與子句④都是將是滿足查詢輸入的答案。然而,顯然子句②雖然滿足“沮喪”,但它卻并不是正確的查詢結果。針對該問題,文獻[9]提出應當將情緒表達關鍵詞所在子句中的其他詞的語義也納入考慮,即將整個情緒表達子句作為查詢輸入。在此例子中查詢輸入就由“沮喪”變為了整個子句⑤。考慮了情緒表達關鍵詞的上下文后,對情緒原因檢測的識別效果有了進一步提升。
(2)考慮文檔中各子句間的關系
文獻[10]提出了使用整個文本和情緒表達作為輸入,考慮文本中各個候選原因子句間的語義影響,使用注意力機制在詞語級、短語級層次上對候選原因子句與情緒表達間的對應關系建模,再在句子級融合子句間的上下文信息,通過這種多層級網絡模型來確定情緒原因子句。情緒原因檢測任務除了考慮情緒表達與情緒原因的關系之外,子句與情緒表達的相對位置關系和子句間的標簽關系[11]也是有助于情緒原因檢測的重要特征。在只考慮情緒表達子句與原因子句間的關系的建模方式中,將文本分成多個子句分別與情緒表達所在子句配對,這種建模方式可能導致一個文檔中沒有子句被預測為原因子句,或者太多子句被預測為原因子句。為了解決該問題,文獻[11]將情緒原因檢測任務轉化為重新排序后的子句預測問題,將原始文本中的子句按照距離情緒表達子句的相對距離,按其絕對值大小升序排序,預測每個子句是否為情緒原因子句,將子句的預測結果作為特征,用于預測下一個子句是否為情緒原因子句。文獻[12]提出一種RNN-Trans?former層級網絡,對整篇文檔采用Transformer編碼子句的方法進行情緒原因檢測,使用Transformer的編碼方式能充分利用整篇文檔的信息,更有效的編碼子句間的相互作用關系。實驗結果證明了使用Transformer對多個子句的編碼效果使用RNN編碼子句間關系的效果更好[12]。
2 語料資源
目前,仍然缺少情緒原因檢測的中文微博數據集。對于中文微博的情緒原因檢測,大都是研究人員各自構建數據集。文獻[6]針對表述規范的文本,公開了基于新聞文本構建的情緒原因檢測數據集,彌補了之前沒有公開數據集的空白,進而推進了情緒原因檢測任務的發展。目前,該數據集已經成為情緒原因檢測任務的基準數據集。該數據集包含了喜(Happi?ness)、悲(Sadness)、懼(Fear)、怒(Anger)、惡(Disgust)、驚(Surprise)六種情緒[6];包含2105篇文檔,11799個子句,其中包括2167個情緒原因子句,情緒原因數量的分布情況如表1;原因子句與情緒表達子句的距離分布如表2,“0”表示原因子句與情緒表達在同一子句,“-”表示原因子句在情緒表達子句左邊,“+”表示原因子句在情緒表達子句右邊,經過分析可發現大部分情緒原因子句在情緒表達子句的前一個子句或者同一子句。
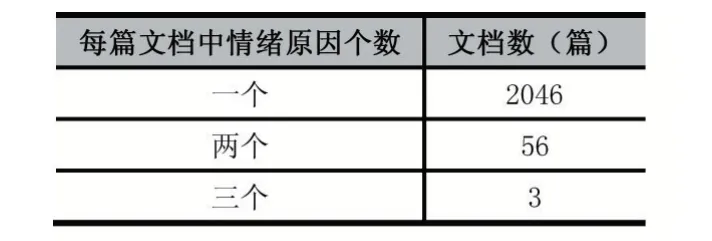
表1 情緒原因數量的分布情況
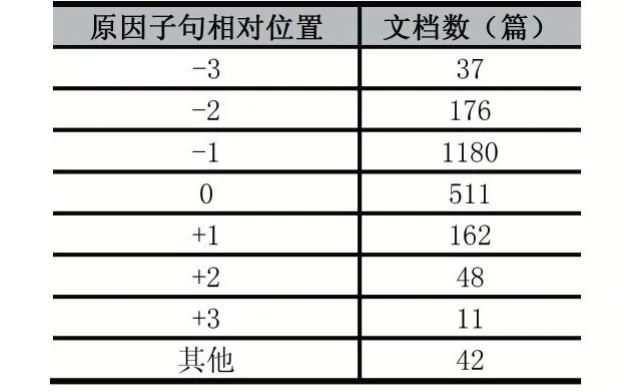
表2原因子句與情緒表達子句的距離分布情況
3 結語
本文對情緒原因檢測的研究進展進行了介紹,簡單介紹了文本情緒原因檢測任務和相關數據集的基本情況,重點介紹了解決情緒原因檢測問題的三大主要方法,分析了這幾類方法的改進思想。情緒原因檢測任務將有助于情緒的識別,問答系統的發展,增強人機交互體驗,具有較高的研究價值和應用價值。情緒原因檢測是情緒分析領域一個新的研究方向,在實驗效果上仍然有很大的提升空間。目前仍存在缺少公開中文微博數據集以及已公開數據量較少的問題,這給該任務提出新的挑戰,需要進一步探索新的解決方法。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
小學教學參考(2015年20期)2016-01-15 08:44:38
