采用分段主成分和PPI的高光譜影像分類
2020-04-01 01:01:06梁遠玲簡季
遙感信息 2020年1期
關鍵詞:分類
梁遠玲,簡季
(成都理工大學 地球科學學院,成都 610059)
0 引言
高光譜遙感波段多、光譜分辨率高,能夠提供豐富的地物波普信息,區分地物的細微差異,較多光譜遙感更適宜地物的精細分類研究[1-2]。目前高光譜遙感技術已應用于地質勘探、精準農業、環境監控、目標識別等多個領域,其中一項廣泛的應用是利用高光譜影像實現地物分類[3-4]。然而高光譜影像的高維度,波段之間相關性高、數據冗余,混合像元等問題決定了傳統的多光譜分類方法往往不適用于高光譜影像[5]。高光譜圖像降維、端元提取及分類方法的選擇都是高光譜分類研究的關鍵環節,現國內外已對這些問題有了深入研究。
降維即從眾多波段中提取出地物光譜差異明顯的特征波段,去除無用的噪聲波段,可減少數據運算量,降低后續分類器的構建難度,最大化利用高光譜數據精細光譜分辨率的優勢[6]。降維方法可分為監督、半監督和無監督3種類型[7]。線性判別分析(linear discriminant analysis,LDA)是一種典型的有監督降維方法,但LDA最多降將維數降到K-1,當訓練樣本數小于樣本維數時,LDA效果較差。無監督的降維方法如主成分變換(principal component analysis,PCA)對簡單的線性分布數據處理十分有效,PCA是通過某種算子,將高維度的數據變換到低維度的空間里,且對降低的維數沒有限制,對于本文的小樣本分類也是適用的[8-10]。PCA變換適用于相關性較強的波段,且易忽略某些局部重要的波段[11]。有研究表明用SPCA處理高光譜影像,分段后的波段在局部子塊的相關性大大提高,更有利于進行主成分變換,同時可有效避免全局變換忽略某些局部重要波段的情況[12-13]。劉瑤等[14]在大豆品種識別研究中將整個高光譜波段分解為3個子分段,分別在每個子分段上做PCA,得出在第二分段進行PCA變換來無損識別大豆品種是可行的,且識別精度優于全波段PCA變換。對降維的結果進行端元提取,較為成熟的端元提取方法是基于最小噪聲分離(minimum noise fraction,MNF)的結果進行PPI處理[15]。黃晨等[16]對比了基于MNF和SPCA 2種變換做PPI端元提取效果,發現在地物破碎區域使用SPCA較MNF降維方法更有效果,能找出信號較弱的端元數量,從而能夠發現MNF降維不能提取到的端元。這一研究充分印證了SPCA降維與PPI端元提取二者結合運用于高光譜影像分類識別的可行性。以研究區的典型地物端元建立波普庫進行分類,各種分類算法的機制不同,對地物的識別精度各異,MDC和BE簡單有效,在監督分類中應用廣泛。
有研究用MDC方法做土地覆蓋分類,得到的分類結果精度高,改變距離規則可形成加權最小距離和自適應最小距離的分類方法,與假設檢驗結合提高基于像素的分類精度,融入基于對象的原理分類精度優于基于像元的方法[17-20]。周利鵬等[21]基于PPI提取端元之后,采用BE從高光譜影像成功識別樹種。用hamming距離作為差異測度可形成多門限的二進制編碼方法,更加精確地描述地物的光譜特征,實現地物的精細分類[22]。此外針對空間紋理特征,借助BE對圖像的紋理特征進行二進制編碼,可實現對遙感場景分類并識別圖像的紋理特征[23]。BE與支持向量機(support vector machine,SVM)分類方法結合,形成基于最優支持向量機和改進的二進制編碼蟻群優化算法,應用于遙感圖像分類能夠在效率和分類精度之間保持良好的平衡,總體分類結果的精度可適用于實際需求[24]。針對高光譜影像多波段和混合像元的問題,本文先基于SPCA降維和PPI法提取端元,再用MDC和BE 2種分類方法實驗,并對2種分類結果的優劣勢進行了分析。
1 研究方法
1.1 數據
研究區地處福建省泉州市德化縣葛鎮以東和楊梅鄉以北的交界處位置,中心地理坐標為118°16′41.8″E、25°50′49.91″N,面積約為1.9 km2,屬于亞熱帶季風氣候區,年平均氣溫18 ℃,無霜期255天,年降雨量大約為1 200 mm。葛坑是德化重要的礦區之一,蘊藏著豐富的礦藏資源,境內的湖頭村是德化的煤炭基地和水泥原料基地;楊梅鄉有豐富的煤、鐵、錳、大理石等礦產資源待開發。區內西南部為采礦區和農田,地形平坦,以及部分居民區也聚集此,區域內其余多為植被叢林覆蓋的淺丘,平均海拔約為300 m。境內自然景觀以亞熱帶常綠闊葉林為主,土壤類型多為南方地區典型的紅壤。
本研究分類的數據為CASI高光譜影像,共72個波段,覆蓋的波譜范圍為可見光(367~760 nm)到近紅外(760~1 045 nm),空間分辨率1 m,波譜分辨率為9.5 nm。研究區地物主要有植被、道路、不同建造材料的房屋、農田、湖泊及陰影。大氣校正是把像元的輻射亮度值轉換為反射率值,分類之前先進行大氣校正以獲得地物真實表觀反射率,提高分類的準確性。該傳感器數據產品中包含了一些輔助數據,可作為FLAASH大氣校正工具的輸入參數,大氣校正后高光譜影像如圖1所示。

圖1 大氣校正結果
1.2 分段主成分分析
PCA是一種全局變換,它適用于波段相關性很強數據,若對CASI高光譜影像的72個波段做PCA處理,全局大范圍波段的平均相關性就會減弱,某些局部比較重要的波段可能在波段選擇中被漏掉,主成分變換的效果也會越差。
相關性矩陣圖(圖2(a))是由72×72個像元構成的灰度圖,(i,j)位置像元的DN值代表i波段關于j波段的相關性。相關性矩陣圖中3波段、33波段附近存在明顯的十字絲,以十字絲為分段依據,將72個波段其分為3個波段子空間,分段信息如表1所示:1~3波段為第一波段子集,4~33波段為第二波段子集,34~72波段為第三波段子集。每個波段子集的平均相關性(圖2(b))較全波段的平均相關性高很多,高度相關的波段會有信息冗余,PCA對相關性強的波段變換效果較好,故在3個子空間分別做PCA變換。

圖2 相關性矩陣信息

表1 分段信息
1.3 PPI端元提取
PPI的獲取端元主要是應用凸面幾何學思想,在波段數為N的高光譜數據,可以看成是N維的特征向量,構成一個N維特征空間,形成N+1個頂點的凸面體。所有的像元呈閃點分布于此空間,端元分布凸面體的頂點處,而混合像元位于凸面體的內部,是頂點純凈像元的線性組合[25]。PPI算法的示意圖如圖3所示,在特征空間內將所有像元向量投影到隨機單位向量上,投影在單位向量兩端的像元為純凈像元(端元),將投影在端點位置像元記錄下來,次數越多越純凈。

圖3 PPI端元提取示意圖[25]
1.4 MDC和BE
MDC用訓練樣本數據計算出每一類的均值向量和標準差向量,以均值向量作為該類在特征空間中的中心位置,計算圖像中每個像元xi到各類中心的距離D,到哪一類中心的距離最小,該像元就歸入到哪一類[26]。距離準則常采用歐式距離(式(1)),也可用馬氏距離、計程距離、折線距離等。
(1)
式中:N為波段數;xi為像元在第i個波段的像元值;Mij為第j類在第i個波段的均值。
BE分類是基于光譜形狀特征來描述地物的反射光譜并建立二進制編碼特征,通過光譜匹配識別來對地物分類。其算法為:低于波譜平均值的編碼為0,高于波譜平均值的編碼為1(式(2))[27]。N個譜段的多光譜則形成N個比特位的二進制編碼。

(2)
式中:y(i,j,n)為波段圖像的灰度;m(i,j)為均值圖像的灰度;n和n′為波段序號,n=1,…,N-1,n′=n+1,…,N;i,j為多光譜圖像中像元的行列號。
2 結果
2.1 分段主成分結果
在3個波段子集分別進行主成分變換得到累計貢獻率(表2),它反映了變換后特征信息量大小。根據信息量在第一波段子集中選取前兩個波段,第二個波段子集中選取前五個波段,第三個波段子集中選取第一個波段,這8個波段子集(圖4)基本涵蓋了原始波段的所有信息。對8張單波段的影像柵格處理進行波段合成得到1張8個波段的彩色影像,原始的72個波段影像降維后信息集中到了8個波段,達到了特征提取和去噪的目的。

表2 各波段子集主成分累計貢獻率

圖4 各波段子集部分影像
2.2 PPI結果
PPI的結果為灰度圖(圖5(a)),DN值大于0均為純凈像元,且值越大,純度越高。對SPCA降維去噪后的影像做PPI處理,以PPI結果為基礎選取感興趣區域,獲得了2 896個純凈像元。在N維可視化空間提取端元的波譜曲線制作為光譜庫文件(圖(b)),作為分類的訓練樣本。
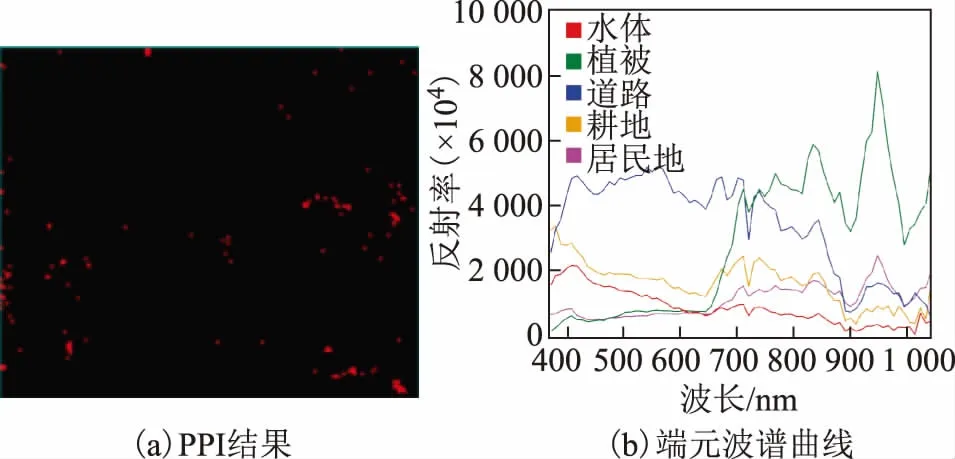
圖5 PPI結果及端元波譜曲線
2.3 分類結果
2種方法的分類結果如圖6所示,從視覺效果看來,MDC方法對道路和居民地分類效果更好,道路信息幾乎完全提取出來。而BE對植被分類效果好,不受植被陰影的干擾,也不會存在植被稀疏有林地與耕地混淆的情況,且能分出水體,很好地將湖泊與周圍植被區分開。總體而言,道路和居民地更適合最小距離的分類方法,而植被、耕地和水體則更適合二進制編碼方法分類。

圖6 分類結果
3 討論
在高光譜影像上選擇感興趣區域,每種地物類型隨機選擇50個樣本點,用正確分類點與總的樣本點的比值作為分類精度評價指標。對2種方法的分類結果建立混淆矩陣進行精度評估,對結果進行分析列出主要錯分類型(表3)。結果顯示,MDC分類的總體精度為69.71%,植被的分類精度為82.35%,主要是由于部分植被稀疏區域被錯分為耕地,從而耕地分類精度也會受損;道路的分類精度達98.08%,可以看到幾乎所有道路都被提取出來;居民地的精度為25.43%,有一部分房屋屋頂可能為水泥或混凝土,故易錯分為道路。BE分類的總體精度為70.88%,植被和耕地精度均較高,分別為94.12%、98.08%;但道路的精度下降到63.46%,只提取到部分主干道路;居民地建筑物的精度很不可觀,有一部分錯分為道路,有一部分受房屋和植被陰影的影響,誤分為水體;水體的分類精度高達98.11%,能看到圖中的湖泊分割效果與實際情況有高度的一致性。
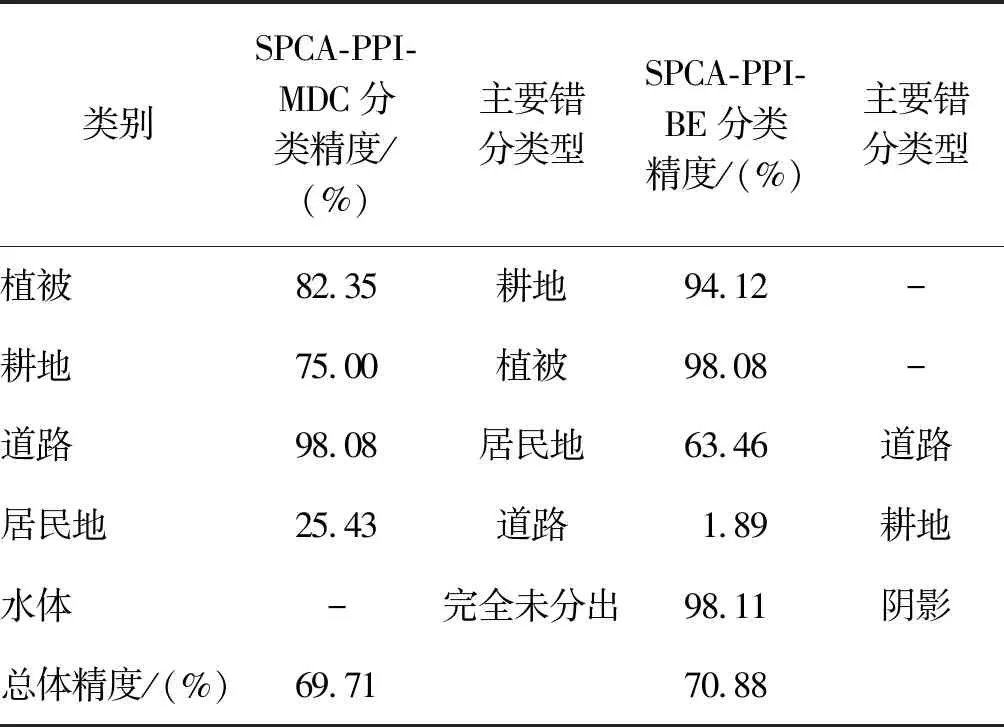
表3 不同地物類型分類結果精度評價
MDC能夠很好地分出道路,但是對于植被和耕地易混淆,主要是由于一些耕地和一些植被稀疏的有林地混在一起,植被稀疏的地方一部分劃分為了植被,一部分劃分到了耕地。MDC最大的缺點是不能分出水體,將湖泊區域全部劃分到了植被。
BE能很好將湖泊劃分為水體,但也存在一些問題,如對陰影和水的分類錯誤,水體混雜了一部分植被和道路陰影。BE對植被的辨識敏感,使有林地不會誤分為耕地,植被陰影和植被不會分為不同類。但是其對道路的劃分不那么理想,當然有的道路可能本來是泥路,造成其與耕地劃分為一類。
4 結束語
本文以CASI高光譜影像作為數據源,采用分段主成分變換進行特征提取,以相關性矩陣為依據,劃分出3個相關性更大的波段子集分別進行主成分變換。在每個波段子集選擇出信息量較大的波段,第一波段子集選用前2個波段,第二波段子集選用前5個波段,第三波段子集選用第1個波段,對8張單波段影像的波段合成處理,從而避免了全波段做主成分變換時可能忽略重要局部信息的情況,很好地實現了對高光譜影像的降維去噪,運用分段主成分變換做特征提取是可取的。
對波段合成后的影像采用PPI做端元提取,將提取的端元作為訓練樣本,采用最小距離法和二進制編碼2種方法進行監督分類。2種方法的整體分類精度均在70%左右,但是單一地物的分類精度卻有很大的差異,這主要是2種分類算法的機制原理有所不同。2種方法各有所長,道路和居民地采用最小距離的分類方法精度更高,而植被、耕地和水體采用二進制編碼的分類方法精度更高。二者均存在不足,特別是居民區錯分為道路的情況。猜想主要是由于居民區可能存在大量的水泥屋頂的房屋,與道路的光譜特征相似,造成了居民區建筑物錯誤劃分為道路,此外房屋的陰影也是造成居民地錯誤分類的一個重要原因。
目前我們只有研究區的原始高光譜影像,完全依靠圖像數據本身對影像進行分類。許多研究已經證明了高質量的分類結果是通過將數據與不同的特征融合在一起來獲得而不是只使用一種數據類型,如借助機載雷達數據建立數字表面模型來區分有高度差的植被和耕地、道路和水泥建筑。在未來的研究中,我們將專注于減少對其他物體的錯誤分類,如陰影和水、建筑物和道路、耕地和植被,同時可嘗試借助一些輔助數據來實現更高精度的分類,減少易混淆地物的錯誤分類,期望實現不同種類的地物完全分開。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
