
基于分組SIFT 的圖像復制粘貼篡改快速檢測算法
2020-04-06 08:24:58肖斌景如霞畢秀麗馬建峰
通信學報 2020年3期
肖斌,景如霞,畢秀麗,馬建峰
(1.重慶郵電大學圖像認知重點實驗室,重慶 400065;2.西安電子科技大學網絡與信息安全學院,陜西 西安 710071)
1 引言
隨著互聯網技術的快速發展,人們從網絡上獲取信息變得極其容易。同時,人們借助強大的圖像編輯軟件,可以輕松地篡改數字圖像的內容。如果大量篡改圖像在互聯網上廣泛傳播,將會導致諸多不良影響。因此,判定一幅圖像是否為真實圖像變得尤其重要。現有的數字圖像篡改方法主要包括重采樣、復制粘貼、剪切以及刪除對象。其中,復制粘貼篡改是指復制原始圖像的一個區域或者多個區域并粘貼到同一幅圖像的某個區域,以達到掩蓋或增加圖像內容的目的。一個復制粘貼篡改的例子如圖1 所示,圖1(a)為篡改圖像,圖1(b)指示了篡改圖像中的篡改區域。本文旨在研究圖像的復制粘貼篡改問題,提出快速、有效、準確的圖像復制粘貼篡改檢測算法。

圖1 復制粘貼篡改圖像及其真實篡改區域
多年來,圖像篡改問題引起了研究人員的廣泛關注,他們發現大多數圖像進行篡改操作后會導致某些固有的圖像統計數據失真,因此可以通過分析這些統計數據來識別圖像是否被篡改。現有篡改檢測方法的基本操作流程可分為預處理、特征提取、特征匹配、后處理。預處理操作將輸入圖像轉換到灰度空間或者其他彩色空間(如HSB、YCbCr 等);特征提取操作從不同的圖像區域(如重疊規則塊、非重疊不規則塊、高熵區域等)提取特征,所提取特征的描述能力和抗攻擊能力直接影響最終檢測效果,是復制粘貼篡改檢測方法的關鍵階段;特征匹配操作通過提取的特征進行匹配篩選,根據匹配特征的位置確定篡改區域;后處理操作從匹配的信息中過濾掉異常值,然后對剩余信息進行處理,得到最終檢測結果。通常,根據提取特征區域的類型,可以將復制粘貼篡改檢測方法分為3類,分別為基于圖像塊的檢測方法、基于特征點的檢測方法、基于分割的檢測方法。
基于圖像塊的檢測方法首先把圖像分成重疊的規則塊,利用各種變換提取每個塊的特征;然后利用塊的特征向量實現塊匹配。已有的基于圖像塊的檢測方法如表1 所示,主要采用的特征提取方法包括離散余弦變換(DCT,discrete cosine transform)[1]、奇異值分解(SVD,signal value decomposition)[2]、主成分分析(PCA,principle component analysis)和離散小波變換(DWT,discrete wavelet transform)[3]、方向梯度直方圖(HOG,histogram of orientation gradient)[4]、Krawtchouk 矩陣(Krawtchouk moment)[5]、Zernike 矩陣(Zernike moment)[6-7]、極性復數指數變換矩陣和YCbCr 顏色空間(polar complex exponential transform moment and YCbCr color)[8]、極性復數變換矩陣(polar complex transform moment)[9]、一維描述符(1-D descriptors)[10]、一致性敏感哈希(coherency sensitive hashing)[11]、空間和顏色模型(spatial and color rich model)[12]等。為了提升檢測算法的抗攻擊能力,文獻[6]算法利用Zernike 矩陣和局部敏感哈希進行塊匹配來定位篡改區域;文獻[10]算法將重疊的像素塊映射到對數極坐標,在極坐標空間生成一維描述符。為了降低算法的時間復雜度,文獻[11]算法應用增強一致性敏感哈希算法來建立特征對應關系,通過迭代細化特征對應關系最終定位篡改區域。由于采用重疊塊,基于塊檢測的檢測方法具有很好的檢測效果,但由于需要匹配篩選的塊特征數量很大,因此此類檢測方法的計算時間復雜度都比較高。

表1 基于圖像塊檢測方法的特征提取方法、匹配方法
基于特征點的檢測方法通過提取圖像的局部角點或者極值點作為特征向量進行匹配,定位篡改區域。已有的基于特征點的檢測方法如表2 所示,主要采用的特征提取方法包括加速穩健特征(SURF,speeded up robust feature)[13]、基于多支持區域的梯度直方圖(MROCH,multi-support-region order based gradient histogram)[14]、二進制穩健性不變可擴展關鍵點(BRISK,binary robust invariant scalable keypoint)[15]、雙閾值 SIFT 描述符(dual-threshold SIFT descriptor)[16]、Harris 角點(Harris corner point)[17]、SIFT 描述符和Zernike 矩陣(SIFT descriptor and Zernike moment)[18]、尺度不變特征變換(SIFT,scale-invariant feature transform)[19-21]。由于提取的特征點數量比重疊塊數量少,因此該類方法的特征匹配和后處理的計算時間復雜度比基于塊的檢測方法低。同時,由于特征點具有很好的抗變換能力,因此該方法穩健性強。但是,如果篡改圖像對比度較低或者以有損格式保存,提取特征點的數量會急劇降低,導致檢測效果不佳。

表2 基于特征點檢測方法的特征提取方法、匹配方法
為了解決上述2 類方法存在的問題,研究者們提出了基于分割的檢測方法[22-25]。已有的基于分割的檢測方法如表3 所示,該類方法先將輸入圖像分組為超像素,然后從超像素中提取特征點進行匹配。在大多數情況下,不規則且不重疊的圖像塊不僅能比常規塊更好地定位篡改區域,還能降低計算時間復雜度。然而,基于分割的檢測算法依賴于初始分割設置,即超像素的初始大小。

表3 基于分割檢測方法的特征提取方法、匹配方法
綜上所述,以上3 類檢測方法主要解決的問題集中于保持檢測效果和減少計算時間復雜度。本文研究發現,3 類檢測方法的特征匹配方法大都是窮舉搜索匹配。窮舉搜索匹配雖然效果好,但是會大大增加計算時間復雜度。因此,本文提出了基于SIFT 分組的圖像復制粘貼篡改快速檢測算法。該算法采用類間匹配的思想,即通過計算結構張量屬性對超像素進行分類,相同類的超像素進行塊內SIFT特征點匹配。通過類間匹配思想快速準確定位篡改區域,同時保證較好的穩健性。
2 基于分組SIFT 的檢測算法
基于分組SIFT 的圖像復制粘貼篡改快速檢測算法流程如圖2 所示,包含4 個步驟,分別為塊劃分、塊特征提取、塊分類、塊類間匹配。
步驟 1應用簡單線性迭代聚類(SLIC,simple linear iterative clustering)算法對輸入圖像進行塊劃分。
基于圖像塊的檢測算法都是預先定義塊的大小,然后將輸入圖像劃分為重疊且規則的塊,最后通過匹配塊來定位篡改區域。定位的篡改區域由規則塊組成,準確度不高。同時,當待檢測圖像增大時,重疊塊數量增加,塊特征的匹配計算時間復雜度也會隨之上升。因此,本文采用SLIC[22]將輸入圖像分為不重疊且不規則的圖像塊。SLIC 算法采用k-means 聚類生成超像素,主要包含2 個步驟:初始化聚類中心、迭代尋找最佳的聚類中心。
步驟2從圖像塊中提取SIFT 特征點作為塊特征。
特征點提取方法SIFT[15,26]和SURF(speeded up robust features)[27]已廣泛應用于計算機視覺領域,SIFT和SURF特征點已被廣泛證明對于常見的圖像處理操作(如旋轉、縮放等)具有穩健性。因此,SIFT和SURF常用作現有基于特征點的復制粘貼篡改檢測方法中的特征點提取方法。Christlein 等[28]研究表明,SIFT 具有更穩定和更好的性能。所以本文方法選擇SIFT 作為特征點提取方法。
步驟3利用結構張量劃分圖像塊的類別。
結構張量[29-32]描述了一個點的指定鄰域中的梯度方向,以及這些方向相關的程度。在圖像處理中,結構張量是由偏導數表示的矩陣,用來表示邊緣信息并描述局部模式。圖像I 的結構張量S 通常被定義為I 的一階偏導數的局部協方差矩陣。I 是根據先前估計的梯度?I =[IxIy]構建的,其中Ix=I ? Dx,Iy=I ? Dy,Ix和Iy分別表示x 方向和y 方向的梯度,?表示卷積,Dx和Dy是卷積核。I 使用高斯卷積核來估算離散域中偏導數。然后通過梯度外積的空間平滑來計算結構張量S 。

圖2 基于分組SIFT 的復制粘貼篡改快速檢測算法流程

其中,結構張量S 與輸入圖像I 具有相同的尺寸,即相同數量的線和列。S 是結構張量 S(z)在位置z的對稱半正定矩陣的矩陣值。在每個位置z,S(z)的特征值分解為2 個非負特征值 λ1(z)和 λ2(z),顯示局部圖像邊緣的強度,即方向變化的強度;以及2 個對應的特征向量e1(z)=[e1x(z)e1y(z)]和e2(z)=[e2x(z)e2y(z)],e1(z)和 e2(z)正交且平行于局部邊緣。根據與 λ1(z)相關聯的特征向量 e1(z)計算局部方向趨勢 O(z),其范圍在之間。

本文利用結構張量計算每個塊中每類像素所占比例,根據比例判定圖像塊是平坦塊、邊緣塊還是角點塊。假設p1、p2、p3分別表示某個塊中平坦像素、邊緣像素、角點像素的個數,則有

其中,pi表示某一個塊中某類像素的總數,i=1,2,3;per(pi)表示不同類別像素在每個塊中所占的比例。某圖像塊內不同類像素所占的比例根據式(5)判別得到其類別。

其中,q=1表示平坦塊;q=0表示邊緣塊;q=-1表示角點塊;ε1和ε2為平坦像素和邊緣像素的比例閾值,即塊分類閾值,兩者的具體取值將在3.3 節中介紹。
步驟4采用類間匹配的思想進行匹配。
根據步驟3 所得的分類塊,在每類中進行SIFT特征點匹配。采用歐幾里得距離進行相似性度量。在這些塊中,當2 個特征點描述符的歐幾里得距離滿足式(6)時,特征點 fa(xa,ya)與 fb(xb,yb)匹配。

其中,d(fa,fb)和 d(fa,fi)分別如式(7)和式(8)所示。

其中,i 表示第i 個特征點,n 表示相應的類別塊中特征點的數量,threshold 表示特征點匹配閾值。threshold 越大,匹配精度越高,錯誤匹配的概率也越高。本文根據大量實驗,設定特征點匹配閾值為3.5。
3 實驗結果與分析
本節對所提檢測算法進行驗證和分析,并將其與現有復制粘貼篡改檢測算法進行比較。所有實驗都是在Intel(R)Core(TM)i5-4590 CPU @3.30 Hz的PC(Matlab 2018a,Win7)平臺上進行的。為了確保實驗的可行性,利用實驗數據庫來自公共數據集。
3.1 數據集
實驗數據集由人物、風景、動物等圖像組成,其篡改區域的類型主要為平滑區域和粗糙區域。數據集由612 幅圖像組成,其中原始圖像36 幅,篡改+攻擊圖像576 幅。數據集的攻擊類型包括旋轉、尺度縮放。本文將實驗所使用的數據集命名為CMFD,其構成如表4 所示。

表4 數據集CMFD
3.2 評價參數
本文實驗部分所參考的評價參數為準確率(Precision)、召回率(Recall)以及F 值。評價參數計算方式如下。

其中,TP表示檢測結果中正確檢測為篡改區域的像素總量,FP表示檢測結果中錯誤檢測為篡改區域的像素總量,FN表示檢測結果中未被檢測出的篡改像素總量。實驗部分出現的Precision、Recall、F 都是所使用數據集檢測結果的平均值。
3.3 參數設置
本文所提算法中,塊分類閾值會影響圖像塊的分類,進而影響塊類間匹配,最終影響檢測時間復雜度以及檢測效果。因此,為精確地對圖像塊進行分類,并減少塊匹配的錯誤概率及時間復雜度,本文通過實驗對比分析來確定塊分類閾值,在保證算法檢測效果的同時使算法具有較低時間復雜度。實驗分別對塊分類閾值的取值選擇做了各種組合,檢測結果分別如表5 和表6 所示,其中Time_1 和Time_2 分別表示檢測圖像大小為1 024 像素×768 像素(低分辨率)和3 000 像素×2 000 像素(高分辨率)的平均運行時間,Precision、Recall、F 分別表示檢測結果的準確率、召回率和F 值。從表5 和表6 可以看出,當取不同的值時,算法的性能表現不一致。當檢測低分辨率圖像時,檢測時間復雜度差異較小,但是檢測準確率和召回率差異較大,其原因是閾值取值不當,在對圖像塊分類時,造成圖像塊分類出現錯誤,使圖像塊匹配不當。當檢測高分辨率圖像像素時,不同的塊分類閾值對檢測的準確率和召回率影響較小,但是對于檢測時間復雜度影響較大,其原因是在對塊分類時,難以精準地把圖像塊分為3 類,而是錯誤地將圖像塊分為了2 類或者一類,未達到分類的效果,進而采用類間匹配的方法出現失效的情況,導致匹配階段時間復雜度上升。由于低分辨率圖像總的圖像塊比較少,即使圖像塊的類別較少,在采用類間匹配時,對時間復雜度影響較小。根據實驗結果分析可得,當閾值為ε1=0.9,ε2=0.3時,算法可以獲得最優的檢測效果,同時具有較低的時間復雜度。

表5 ε1=0.9,ε2變化時的復制粘貼篡改檢測結果Precision、Recall、F 和運行時間

表6 ε2=0.3,ε1變化時的復制粘貼篡改檢測結果Precision、Recall、F 和運行時間
3.4 評價實驗及對比分析
隨機選取本文算法的6 組檢測結果作為示例,如圖3 所示。其中,圖3(a1)~圖3(a6)表示篡改圖像,圖3(b1)~圖3(b6)表示真實篡改區域,圖3(c1)~圖3(c6)表示本文算法的檢測結果。圖3 的示例是復制粘貼篡改的理想情況,在這種情況下,只將圖像的一部分復制粘貼到同一圖像中而不對圖像進行任何攻擊。
本節選取了文獻[6,10-12,21-22]算法作為對比算法,進一步驗證本文算法的有效性。表7 中展示了不同算法檢測結果的Precision、Recall、F值和運行時間。由表7 可知,本文算法的時間復雜度高于文獻[11]算法,低于其他對比算法;雖然文獻[11]算法的時間復雜度低,但其F 值低于本文算法。由于對圖像塊進行分類,在匹配階段采用類間匹配會在一定程度上減少檢測時間復雜度,但是隨著圖像大小逐漸增大,圖像塊的數量也隨之增加,進而時間復雜度也會隨之上升。從表7 中可以看出,本文算法的Precision 高于其他算法,但是Recall 和F 并不理想,說明有漏檢的篡改區域。其原因是圖像塊分類不夠精準,導致塊匹配過程中圖像塊沒有完全被正確匹配。以上情況說明選擇最佳的固定閾值時,雖然檢測效果比較好,但是如果能根據每幅圖像自身的規律自適應地計算分類閾值,從而對圖像塊進行分類,檢測效果會有明顯提升,這也是未來需要展開的工作。

圖3 本文算法檢測結果

表7 不同算法檢測結果Precision、Recall、F 和運行時間
本節測試了本文算法和對比算法在不同類型、不同程度攻擊下的檢測效果,結果如圖4 所示。圖4(a)和圖4(d)表示各算法在不同攻擊下檢測結果的Precision,圖4(b)和圖4(e)表示各算法在不同攻擊下檢測結果的Recall,圖4(c)和圖4(f)表示各算法在不同攻擊下檢測結果的F。從圖4 可以看出,在旋轉和尺度攻擊下,本文算法都展示了較好、較穩定的檢測結果。
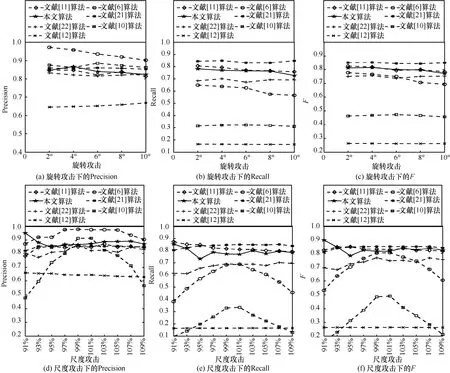
圖4 不同算法的檢測效果
4 結束語
現有的復制粘貼篡改檢測算法的匹配階段大多采用窮舉搜索,導致檢測過程的計算復雜度較高。針對這一問題,本文提出了一種基于SIFT 分組的圖像復制粘貼篡改檢測算法,將圖像塊進行分類,對相同類的圖像塊進行SIFT 特征點匹配。實驗結果表明,本文算法檢測效果較好,時間復雜度大多優于其他幾種對比算法。但本文算法也存在不足之處,算法對塊進行分類時采用固定閾值,當篡改區域與周圍區域的對比度非常相近時,采用固定閾值會降低算法的檢測準確度。在未來的工作中,將繼續研究自適應方法對圖像塊進行分類,進一步提升算法的效果。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
