一種空氣污染物濃度預測深度學習平臺
2020-04-09 06:21:18盧淑怡張旱文高浩然
上海師范大學學報·自然科學版 2020年1期
盧淑怡,張 波*,張旱文,俞 豪,高浩然,劉 波
(1.上海師范大學信息與機電工程學院,上海201418;2.上海超算科技有限公司,上海201203)
0 引 言
隨著深度學習技術的興起,空氣污染預測成為信息科學和環境科學的交叉融合課題.國內外各研究學者通過大量的傳統數值分析和機器學習手段等方法已取得了一定的成果.雷源等[1]為對流層內的多種氣體污染物的時空分布及演變過程進行預測,建立了對流層高分辨率化學預報模型;朱亞杰等[2]通過建立貝葉斯時空模型對京津翼區域進行空氣污染預測,考慮了PM2.5污染物的時間變異和空間分布特性,進行預測的過程中還引入氣象數據作為協變量;尹琪等[3]通過支持向量機(SVM)結合改進的粒子群(IPSO)算法和遺傳算法(GA),使用參數尋優的方法建立新模型,從而對空氣質量指數做預測;陳偉等[4]使用支持向量機(SVM)結合小波分解建立了城市大氣污染物濃度預測模型,通過對于小波分解重構,得到由分解序列合成的最終預測結果.
深度學習作為人工智能前沿技術,國內外在研究污染物濃度的序列建模和變化趨勢預測方面已獲得很多良好的效果.尹文君等[5]針對當前熱點的環境問題,提出基于深度學習的大數據空氣污染預報,通過模擬人腦的神經連接結構[6],實現大數據集成,有效克服現有方法的缺陷,提高預報性能,在應用層面上更加靈活和可操作.
盡管空氣污染預測在深度學習領域取得了較大的發展,但仍存在不足.例如:1)當下的預測方法僅提供了較為優質的模型,無法直觀地展現預測結果,不同的模型也無法在一個平臺上統一應用;2)各個模型的集成度較差,對于跨專業領域的應用存在困難.因此,本文作者提出一種基于深度學習的空氣污染物濃度預測平臺,利用網絡爬蟲技術獲取眾多的污染物數據,考慮到傳統數值分析和機器學習手段的局限性[7],采用長短期記憶(LSTM)網絡模型的深度學習[8]框架進行空氣污染物濃度的預測,充分結合氣象數據對污染物濃度預測的影響,將基于深度學習的空氣污染預測技術設計為一個交互式平臺,提出了一種具有3個層次的深度學習交互式平臺架構.該平臺可通過對用戶的個性化模型參數進行設置,具有靈活、可擴展等優點.
1 總體技術框架
平臺一共有3個層次組成,分別為:數據采集層、模型層以及可視化界面層.由數據采集層自動更新氣象數據和空氣污染數據,數據經清洗和篩選后上傳至模型層,經過LSTM 網絡模型,將產生的預測結果上傳至可視化界面,并展示給用戶,如圖1所示.
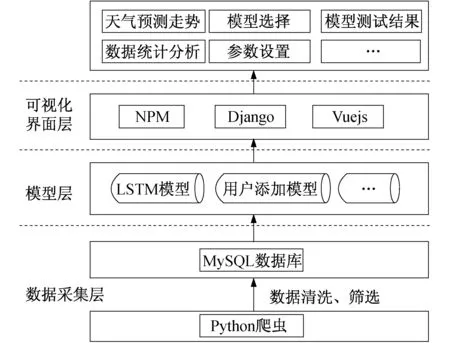
圖1 總體技術框架圖
1.1 數據采集層
數據采集層主要負責采集空氣污染的數值數據.該層接收來自網絡爬蟲采集到的數據.數據內容包括:時間、監測站、濕度、降雨量、風向、風速、溫度、PM2.5值、PM10值、SO2、NO2、CO 及O3的13 個數據項.整合成為以小時為時間跨度單位,整體長度為2015—2018年的實時數據,接著對其進行數據清洗及篩選,最后上傳至模型層進行訓練.
針對大量氣象數據的收集、獲取及篩選處理,數據采集層利用網絡爬蟲程序,從2345天氣網站對上海市近3 年及實時數據進行采集.網絡爬蟲程序通過統一資源定位符(URL)地址和超文本傳輸協議(HTTP),模擬客戶端向訪問的網站發送請求,封裝必要的參數信息,自動獲取網站內容信息并解析數據,如圖2所示.

圖2 網絡爬蟲工作流程圖
1.2 模型層
模型層作為該平臺架構的核心,集成了多種深度學習的神經網絡模型.用戶可根據不同的需求選擇相應的網絡模型,設置自定義參數進行訓練.1.2.1 LSTM模型介紹
1)遺忘門層.遺忘門層決定細胞狀態中信息的保留和丟棄.
2)輸入門層.輸入門層判斷細胞狀態中信息是否需要更新.
3)更新門層.更新門層負責更新細胞狀態.
4)輸出層.輸出層負責確定輸出的內容.采用LSTM 網絡模型的記憶門和遺忘門機制,記憶門決定保留過往有用的信息,遺忘門用于過濾掉無用的信息,從而突出重點屬性,降低非相關屬性的影響,對PM2.5空氣污染物進行回歸預測.
1.2.2 基于LSTM網絡模型的空氣污染物濃度預測
在模型層設計一個符合空氣污染物濃度預測的LSTM 網絡模型,LSTM 網絡模型和數據集的相關參數可由用戶自行設定.該模型主要包括3個部分:輸入層、隱藏層、輸出層.
1)輸入層接收數據采集層處理的數據,再將數據進行歸一化處理,形成符合網絡輸入格式的規范數據.
減譯法是指在不影響原文思想和內容的情況下,把重復多余的文字省去,或在不影響譯語讀者理解的情況下,用更加簡明的語言形式代替原文繁瑣語言的一種翻譯方法,比如:
2)隱藏層包括LSTM 網絡模型和全連接層.依據不同粒度的時間窗口,對模型進行分析,綜合驗證時間長度依賴所取得的最佳窗口值.調節LSTM 網絡模型隱藏層中各處理器之間的傳播機制,優化處理器內部的參數設置,實現對時間序列預測的優化.通過網絡訓練,LSTM 網絡模型將分析所得的污染物特征傳給全連接層,全連接層將該特征轉譯為預測的污染物數值.
3)輸出層輸出下一時段PM2.5的預測值,同時記錄訓練過程當中的均方誤差、損失函數等相關系數.
1.3 可視化界面層
用戶在可視化界面輸入相關參數,LSTM 網絡模型接受參數后開始訓練,數據經訓練之后,以圖表的形式,將預測到的PM2.5空氣污染物及其他相關數據呈現給用戶.除此之外,模型訓練過程中的均方誤差、損失值和數據集的特征分布也會以圖表的形式展現給用戶,方便用戶評估模型性能,觀察數據集分布特征.
2 仿真實驗驗證
本平臺以MySQL為數據庫,Vue.js文件為前端,融合了數據源處理、深度學習模型、數據可視化等技術,并具有可擴展性,兼容多類人工智能模型,如圖3所示.
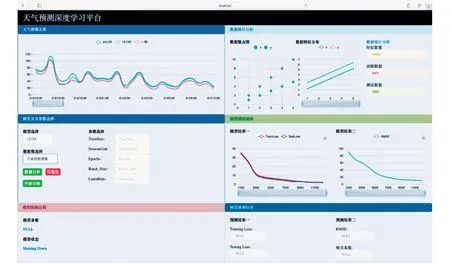
圖3 空氣污染物濃度預測平臺界面
本平臺主要由6個模塊組成:
1)天氣預測走勢.通過將數據庫中已經擁有的天氣數據輸入LSTM 網絡模型進行訓練,對未來的PM2.5情況進行預測.以折線圖的形式展示24 h,72 h 和一周這3 個不同時間跨度的PM2.5污染物質量濃度,如圖4所示.
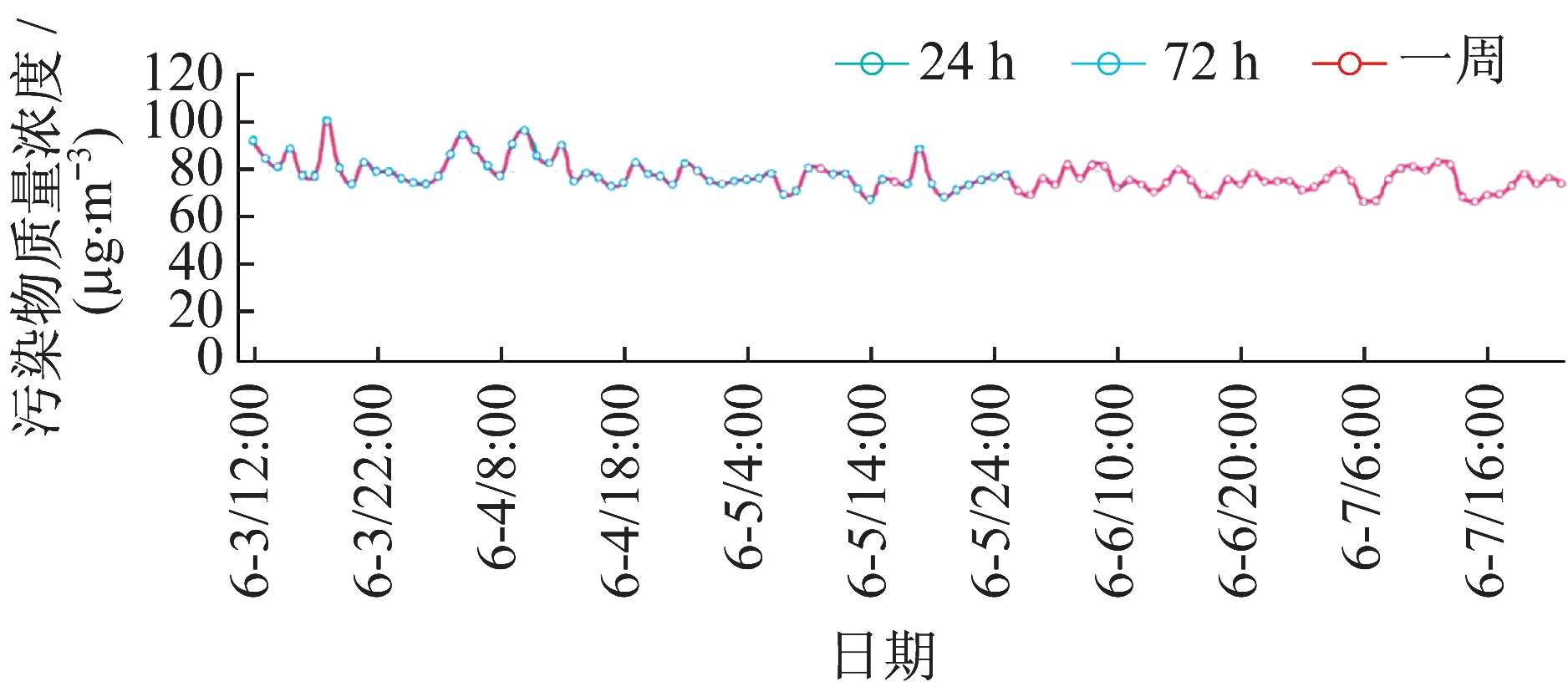
圖4 天氣預測走勢圖
2)數據統計分析.結合歷史污染物質量濃度數據,對CO,PM10,PM2.5等污染物進行統計分析,生成數據散點圖(圖5)和數據特征分布圖(圖6).
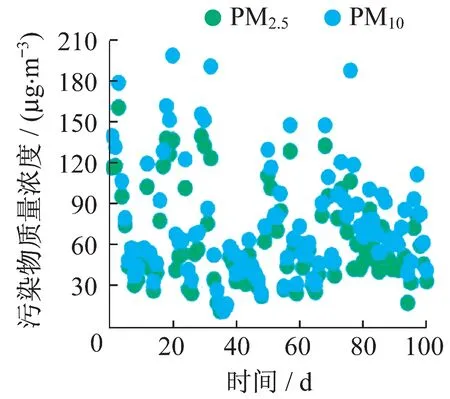
圖5 數據散點圖
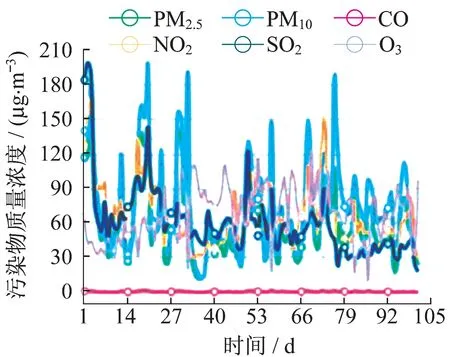
圖6 數據統計分析圖
其中,數據散點圖展示了PM10,PM2.5兩種污染物的數值情況,根據散點圖的聚集程度,用戶可判斷一段時間內的空氣質量情況.
數據特征分布圖則顯示了CO,NO2等六類污染物數據,用戶可選擇自己所需要查看的污染物種類.通過折線圖的方式,用戶可以清晰地了解一段時間內污染物的變化情況.
3)模型及其參數選擇.選擇數據集與相應的訓練模型,并為訓練模型設置相應的參數.該板塊具備兼容性和可擴展性,用戶可自行添加其他模型進行訓練,也可添加不同的數據,根據用戶的不同需求進行預測,如圖7 所示.其中,TrainSize 代表訓練集的大小,NeuronUnit 代表輸出維度,Epochs 代表訓練輪數,Batch_Size代表批處理的大小,LearnRate代表學習率.

圖7 模型參數選擇圖
4)模型測試結果.生成模型損失值和模型周期的函數關系圖,并生成預測的天氣數據和時間的關系圖.
模型損失函數變化曲線圖(圖8)展現了現有模型與理想回歸模型的差距,其變化規律與數值給用戶直觀地展現了模型的收斂過程與最終性能.
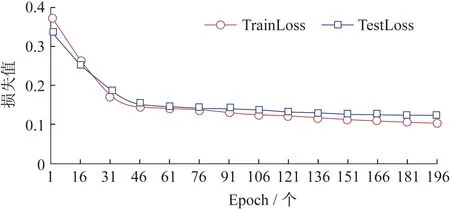
圖8 模型損失函數變化曲線圖
模型預測結果圖(圖9)則展示了用戶自定義模型對污染物濃度預測的準確度,通過觀測值和預測值曲線的重合性,用戶可判斷未來污染物數值(即天氣預測走勢圖)的準確性.
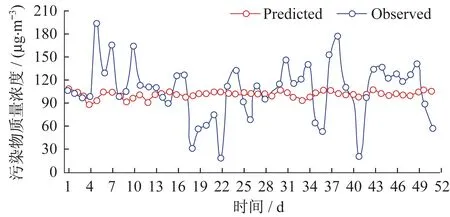
圖9 模型預測結果圖
5)模型訓練過程.模型訓練過程顯示模型訓練時候的參數與訓練的狀態:Shutting Down(關閉)、Training(訓練中)、Finished(完成).
6)模型預測結果.計算最后模型的損失值,并計算模型預測相應的誤差,生成對模型的性能評估指標.
采用經典的數據切分方式,即80%的數據作為訓練集,20%的數據作為測試集.用戶通過輸入神經元個數(NeuronUnit)、訓練輪數(Epochs)、一次訓練所選取的樣本數(Batch_Size)、學習率(LearnRate)4個參數進行訓練,得到相應的預測結果,如表1 所示.實驗證明,隨著神經元個數及訓練輪數,預測值基本可以逐步擬合測試值.

表1 實驗結果
3 結 論
采用LSTM 網絡模型深度學習框架進行空氣污染物濃度的預測,同時提出了基于深度學習的三層架構預測平臺,給深度學習的可視化技術提供了一種新的方法.該平臺分為數據采集層、模型層和可視化界面層三個層次,集成了多種深度學習模型,可以直觀地展示數據,并具備兼容性和可擴展性,用戶可以在平臺上自定義不同的數據集、深度學習模型以及訓練參數.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
