基于卷積神經網絡的隧道掌子面圖像質量評價方法研究
2020-04-11 07:23:50鮮晴羽仇文革王泓穎許煒萍孫克國
鐵道科學與工程學報 2020年3期
鮮晴羽,仇文革,王泓穎,許煒萍,孫克國
基于卷積神經網絡的隧道掌子面圖像質量評價方法研究
鮮晴羽,仇文革,王泓穎,許煒萍,孫克國
(西南交通大學 交通隧道工程教育部重點實驗室,四川 成都 610000)
鑒于隧道掌子面圖像的多樣性和復雜性,提出一種基于深度卷積神經網絡(Convolutional Neural Network,CNN)的圖像質量評價方法,以篩選出滿足工程需求的掌子面圖像。基于多條隧道創建掌子面圖像數據集,采用Keras深度學習框架,應用多種主流的CNN進行對比試驗,并結合傳統的圖像評價指標,分別從清晰度、分類和相似度3個方面對掌子面圖像質量進行評價。其中基于DenseNet169的多分類模型可達到88.7%的準確率。研究結果表明:跟傳統的圖像處理技術相比,深度學習方法在隧道掌子面圖像識別上具有精度高、效率高的顯著優勢。該方法可為實現隧道掌子面的自動素描提供技術支持,具有良好的工程應用前景。
隧道;圖像質量評價;卷積神經網絡;掌子面;深度學習

隧道建設受控于工程地質條件,準確地掌握掌子面地質條件對安全、快速的隧道建設至關重要。掌子面是工程地質條件最準確和直觀的反映,地質工程師須進行實時、快速的地質素描。基于獲取的掌子面節理信息、巖體完整程度和地下水發育狀態等,結合相關規范進行地質編錄、圍巖分級,從而指導支護選型和實現信息化施工。但人工地質素描存在強度大、效率低、危險系數高、數據共享率低等問題。在此背景下,掌子面自動素描技術應運而生:通過對隧道掌子面照相,采用圖像處理技術,自動提取掌子面節理等信息,據此定量計算巖體完整程度,以便圍巖分級。該技術有益于降低地質工程師的工作強度、保障人身安全,大幅推動隧道信息化和智能化施工進程。獲取質量合格的掌子面圖像是掌子面自動素描技術的基本前提。然而受施工環境、現場設備和技術人員拍照技術水平的限制,拍攝的掌子面圖像時常“不合格”,出現諸如模糊、光線太暗、明暗不均、有遮擋、沒有拍全等情況。同一個掌子面的多張圖像質量往往參差不齊,此時須甄別出合格的圖像,并進行實時反饋,篩選出真實反映當前掌子面情況的圖像。隧道掌子面圖像具有多樣性和復雜性的特點,傳統處理技術在圖像質量判別上的表現差強人意。近年來,深度學習的快速發展給計算機視覺領域提供了一條全新的思路:采用深度學習技術進行圖像識別,從而評價圖像質量的好壞,彌補了傳統技術的不足,使掌子面自動素描成為可能。深度學習在計算機視覺、語音識別和自然語言處理等方面已取得重大突破。卷積神經網絡是一種常見的深度學習架構,廣泛應用于圖像分類、檢測和分割等方面。對于圖像分類問題,合理提取圖像特征是決定分類正確與否的關鍵。傳統的圖像處理技術通常是采用人為設計手工提取圖像特征,準確率和效率均較為低下。卷積神經網絡可以從訓練數據中學習到更高層次、更加抽象的特征,在圖像分類中表現超強,遠勝傳統方法。層出不窮的CNN模型不斷刷新記錄,也展示著該領域的研究熱度,具有代表性的如AlexNet[1],VGG[2],ResNet[3],Xception[4]和DenseNet[5]等。圖像質量評價分為有參考和無參考2種模式,本文屬于后者。在無參考圖像質量評價中,圖像的清晰度是衡量圖像質量優劣的重要指標。徐貴力等[6]提出了一種基于圖像邊緣灰度變化率的算法用以評價圖像的清晰度。李郁峰等[7]提出了灰度方差乘積法,該方法計算性能較好,但其靈敏度在焦點附近不高。Horita 等[8]在WANG等[9]的研究基礎上針對JPEG壓縮圖片定義了全新的質量指標。李祚林等[10]基于面向無參考圖像質量評價,介紹了多種具有代表性的清晰度評價算法,并將對它們各種性能進行了對比和分析。圖像相似度算法的關鍵在于提取具有高穩定性、高匹配度的局部特征。傳統算法中,尺度不變特征(SIFT)算法[11]由加拿大英屬哥倫比亞大學的David Lowe教授于1999年首次提出并于2004年總結完善,常應用于特征提取和匹配算法。吳偉交[12]基于SIFT特征點進行了圖像匹配試驗,取得了較好的結果。圖像哈希算法[13]也稱為圖像感知哈希或魯棒哈希,在圖像認證和識別領域應用廣泛。劉兆慶等[14]則提出了一種基于SIFT的圖像哈希算法。近年來隨著深度學習技術的發展,基于CNN的相似度算法在人臉識別等方面引起諸多研究者的關注[15?17]。CNN在圖像識別領域應用廣泛,但是在特定場景下的研究尚為欠缺,隧道掌子面處的環境復雜,尤以光線差、空氣污濁為代表。本文針對隧道掌子面圖像,對當下幾種主流的CNN網絡模型展開了對比研究,以選取合適的圖像分類模型,并結合清晰度和相似度算法,提出了一種基于卷積神經網絡的掌子面圖像質量評價方法,從而為掌子面的自動素描提供技術支持。
1 掌子面圖像質量評價算法
1.1 總體思路
圖像質量評價方法依次包括清晰度判定、圖像分類和相似度判定3個方面。首先對掌子面圖像進行清晰度判定,再將篩選出來的清晰圖像進行分類,最后通過相似度判別降低重復率。其中,清晰度判定是基礎,圖像分類是核心,相似度判別是進一步保障。具體算法和流程如圖1所示。
1.2 圖像清晰度算法
對于無參考模式的隧道掌子面圖像,通過多種清晰度算法的對比分析,從而確定科學的清晰度算法。基于 Python實現Brenner梯度函數、Tenengrad梯度函數和Laplacian梯度函數等6種算法。

圖1 隧道掌子面圖像質量評價算法
對于二分類問題(本文指掌子面圖像清晰或模糊),根據混淆矩陣(Confusion Matrix),分類器預測結果分為4種情況:真正例(TP)、假正例(FP)、真反例(TN)及假反例(FN)。準確率(Accuracy)是指分類正確的樣本個數占總樣本個數的比例,表達式如下:

查準率(Precision)是指分類正確的正樣本個數占分類器判定為正樣本的樣本個數的比例,表達式如下:
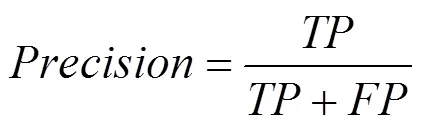
查全率(Recall)是指分類正確的正樣本個數占真正的正樣本個數的比例,表達式如下:

1值是查準率和召回率的調和平均值,表達式如下:
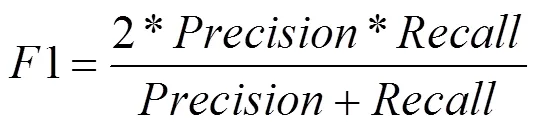
準確率是分類中最簡單和直觀的評價指標,但當不同類別下的樣本比例十分不均衡時,占比大的那類易主導準確率。P-R曲線刻畫的是查準率和查全率之間的關系,對比不同分類器即6種算法所對應的P-R曲線,選擇性能較優的那一個。再通過計算查準率和查全率的調和平均1值尋找該分類器較優的閾值。
1.3 圖像分類算法
1.3.1 隧道掌子面數據集的建立
通過采集多條隧道不同里程和不同地質條件下的掌子面照片,經過人工清洗和標注,生成一個符合深度學習多分類模型訓練的數據集。考慮到施工現場諸多干擾因素(人、機、光線等)和拍攝條件限制,結合拍攝呈現出來內容和特征,掌子面圖像可分和不合格2類。其中,合格細分為3類:明顯輪廓線、模糊輪廓線和臺階;不合格細分為7類:局部帶拱、局部不帶拱、有人/人影遮擋、有機械/機影遮擋、有巖渣遮擋、光線不好和有集中光源。每種分類對應的標簽及備注見表1。建立的數據集包含 4 014 張圖像,其中3 607 張作為訓練集,407張作為驗證集,劃分比例為9:1,具體的數據集分布見表2。10類掌子面圖像的典型代表如圖2所示。

表1 數據標注
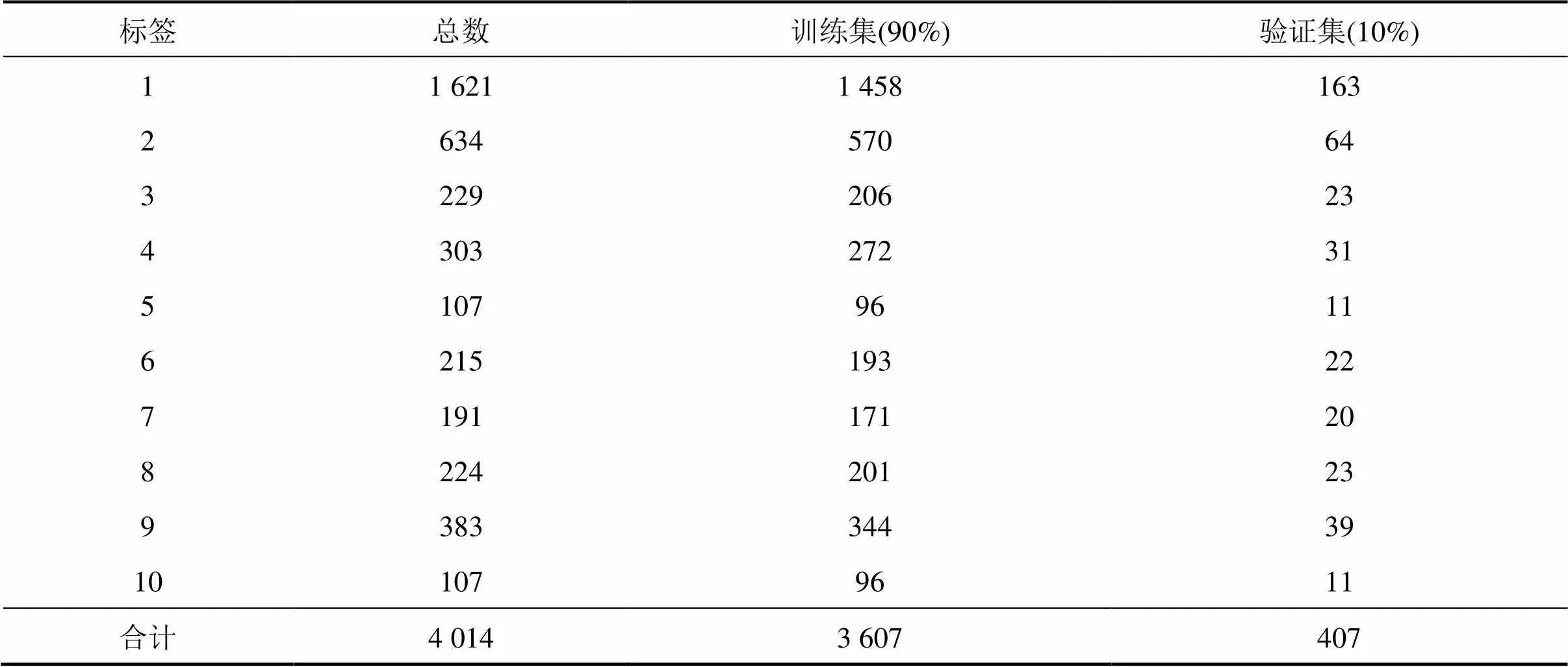
表2 數據集分布
1.3.2 網絡結構
作為深度學習的代表算法之一,CNN是一類包含卷積結構的深度前饋神經網絡,通常由輸入層、隱含層和輸出層3部分組成。

圖2 1~10類掌子面圖像
1) 輸入層是模型的入口,在計算機視覺領域,通常一個樣本對應一個三維數據,即平面上的二維像素點(0~255)和RGB三通道。
2) 隱含層包含卷積層、池化層及全連接層,其中,卷積層和池化層是CNN特有結構, 基本順序一般為:輸入?卷積層?池化層?全連接層?輸出。卷積層中常用的非線性激活函數有:Sigmoid函數、雙曲正切函數、ReLu函數及其變體Leaky ReLu函數等。其中,ReLu函數具有收斂速度快、梯度求解簡單等特點,在CNN中應用廣泛,表達式如下:
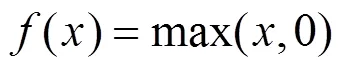
3) CNN輸出層的結構和工作原理與傳統的前饋神經網絡中相同,其上一層通常為全連接層,這里便不再贅述。對于圖像多分類問題,輸出層一般采用歸一化指數函數(Softmax Function)作為分類器輸出分類結果,表達式如下:
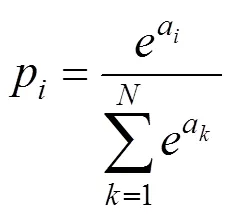

Softmax將多個神經元的輸出,映射到(0,1)區間內,可理解為概率值,所有概率值之和為1,最大概率值對應的分類即為正解,從而實現多分類。Softmax層的交叉熵損失函數表達式如下:

式中:y表示該樣本對應第類的真值。
將10類圖像和對應標簽作為輸入數據對網絡進行訓練,采用梯度下降法不斷優化損失函數,表達式如下:

式中:θ表示網絡中的權重參數;()為待優化的損失函數。
1.3.3 模型訓練與測試
使用Keras深度學習框架進行模型的訓練與測試,模型訓練采用基于ImageNet數據集的預訓練模型進行遷移學習。初始學習率設置為 0.001,并使用學習率衰減策略,即每一輪進行一次衰減,衰減率為0.8。圖片批數量為4,訓練100次全數據,圖片進入網絡前統一縮放至 299×299 像素大小。
模型訓練對輸入圖像應用了多種預處理方案:旋轉、平移、錯切變換、放大、改變顏色和水平翻轉。通過這些圖像預處理手段,在一定程度上實現了數據集的擴充,能更好地提升模型的準確率。測試時,輸入新圖像,利用訓練完成的模型可直接給出圖像分類結果。分類模型框架如圖3所示。
圖3 分類模型框架
DenseNet網絡借鑒ResNet網絡中“抄近路”思想,在不同層之間建立了全新的連接關系(通道上的疊加),如圖4所示。
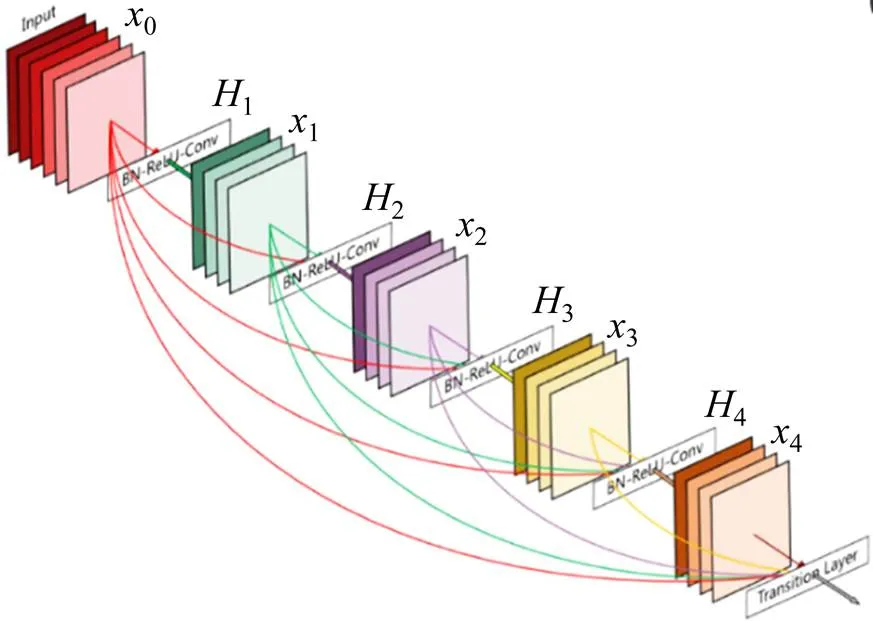
圖4 Dense Block結構示意圖
將DenseNet169,Xception,ResNet50以及VGG16模型分別應用于掌子面圖像分類中,基于Keras(用Python 編寫的高級神經網絡API,以 TensorFlow或 Theano 作為后端運行)實現,模型訓練工作在GPU(1050 Ti)上完成。
1.3.4 可視化分析
深度學習因其內部算法不可見被人們稱為“黑盒子”,但是CNN能夠實現可視化。ZFNet[18]為CNN可視化的開山之作,其通過對AlexNet進行可視化,并根據可視化結果進行優化研發而成。利用反卷積實現可視化,可深入了解識別圖像的過程:CNN是從底層到高層,從抽象到具體來學習特征的,同時該可視化為我們改進網絡結構提供了可能。
可視化主要有4種模式:1) 卷積核輸出的可視化;2) 卷積核的可視化;3) 類激活圖可視化; 4) 特征可視化。本文采用第3種可視化模式,通過熱度圖,了解對圖像分類起關鍵作用的具體部位,同時可以定位圖像中物體的具體位置,以對分類結果進行輔助驗證。
1.4 圖像相似度算法
將第2步分類中訓練好的CNN模型作為特征提取器以獲取圖像特征,生成唯一特征向量,將待判別圖像與數據庫里既有圖像進行對比,根據特征向量計算相似度,選擇合適閾值,滿足閾值要求的圖片即為相似圖片。常用的相似度指標有:余弦相似度、歐式距離和漢明距離等。在文本、圖像和視頻等領域,研究對象的特征維度往往很高,余弦相似度在高維情況下仍然保持:相同時為1,正交時為0,相反時為?1,這體現了方向上的相似性。受拍攝角度、距離、光線等的影響,同一個掌子面拍攝的照片可能在亮度、尺寸、長寬比等方面存在波動,計算圖像特征在方向上的差異相較于計算數值上的差異更能反映真實情況,故這里采用余弦相似度作為相似度指標,表達式如下:


其中:A,B分別代表特征向量,的各分量。
給出的相似性范圍是從?1到1,?1意味著2個向量的方向截然相反,1表示它們的方向完全相同的,0通常表示它們是相對獨立的,而在?1,0或0,1之間的值則表示不同程度的相似性或相異性。本文研究的相似度判別是指:將新輸入的掌子面圖片和數據庫里既有的圖像進行對比,若判定相似,則說明該掌子面的圖像已存在從而駁回,否則,則將其視為新的掌子面圖像而接收。
2 試驗結果與分析
2.1 圖像清晰度試驗
經過大量試驗,Laplacian算法的計算速度、區分度以及在P-R曲線上的表現,都較其他算法有明顯優勢,且與人眼判定基本相符。其梯度函數采用Laplacian算子提取梯度值,因此基于Laplacian梯度函數的圖像清晰度可定義如下:

式中:是給定的邊緣檢測閾值;(,)是像素點(,)處Laplacian算子的卷積。
這里展示3組測試數據在6種清晰度算法下各自的得分。為方便對比,每組中的4張圖像均采集于同一或相鄰掌子面,它們處于不同的清晰級別,且根據人眼判定從模糊到清晰依次排列,以第一組為例,清晰度排序:1?1<1?2<1?3<1?4,其它組同理,具體如表3所示。圖5展示了第2組測試圖像。分析數據得出,6種算法對每組圖像的評分和人眼判定順序基本一致,評分越高,圖像越清晰。

表3 清晰度評分

(a) 2-1模糊(6.0);(b) 2-2模糊(15.0);(c) 2-3模糊(19.0);(d) 2-4清晰(21.1)
結合相關文獻,Laplacian算法的初始化閾值為10,上限為30,以1為步長遞增,試驗結果表明,當閾值取21時,1值可取到最大,此時準確率也達到98%,故設定閾值為21。得分小于21,則判定模糊,大于21,則判定清晰。實際運用中,大部分圖像在清晰度的表現上基本合格,此階段過濾掉的圖像較少,但此步驟仍然不可或缺。
2.2 圖像分類試驗
構建的模型中最后1層使用的是Softmax分類器,預測時,對提取的深層卷積特征進行分類,輸出為每一類的概率值(見式(6)),取概率最大值為預測結果,和真實標簽比較,統計結果得到在驗證集上的準確率.分別訓練了4個模型(DenseNet169,Xception,ResNet50和VGG16),經過大量的調參訓練,結果如表4所示,保存的模型為訓練過程中驗證集損失最小時的模型,準確率即為此時該模型在驗證集上的準確率。以DenseNet169為例,圖6展示了DenseNet169模型在100輪的訓練過程中準確率(見式(1))和損失函數(見式(7))的變化曲線。

表4 不同模型的訓練結果

(a) 模型準確率;(b) 模型損失量
綜合考慮模型的準確率和在GPU上的實測時間,選定DenseNet169模型作為掌子面圖像分類網絡。部分預測結果如圖7所示。
圖中展示了概率前3的預測結果及其對應的概率值,結果基本和人眼判定相符。實際上,分類正誤取決于數據集的“好壞”,數據集越大、標注越客觀、分布越均衡,越易得到好的訓練結果。

圖7 DenseNet169部分預測結果

(a) 原圖;(b) 熱度圖;(c) 疊加圖
以DenseNet169為例,從測試集中選取4張掌子面圖像進行基于Keras的CNN類激活圖可視化,將熱度圖疊加到原圖像,獲得對圖像分類起到關鍵作用的部分,即熱度圖中的高亮部分,與實際情況相符,也驗證了本文方法的正確性。如圖8所示。
2.3 圖像相似度試驗
由于該階段樣本數量較少,試驗中采用了K折交叉驗證(=10)以得到可靠穩定的模型,相似度閾值初始化為0.800,上限為0.999,以0.001為步長遞增,分別計算10次試驗中準確率取得最大值時對應的閾值,再將10次結果求平均,得到最終的閾值,根據試驗結果設定閾值為0.955。
通過清晰度判定和圖像分類后,系統可篩選出基本合格的掌子面圖像。在圖像相似度測試階段,余弦相似度大于0.955,則判定攝于同一個掌子面,否則,則判定攝于不同掌子面。限于篇幅,僅展示一組測試圖像,具體如圖9所示。

(a) 原圖;(b) 1相同(0.967 7);(c) 2相同(0.958 6);(d) 3不同(0.940 4);(e) 4不同(0.931 6)
3 工程應用
以成都天府國際機場高速公路龍泉山隧道為例,其“兩進兩出”龍泉山,設計采用了全國首創的“雙向四洞十車道”。4座隧道的長度約4 651 m,車道布置為2+3+3+2,以實行客貨分流。
通過人工拍攝采集了龍泉山隧道10個里程處的掌子面圖像300張,每個掌子面均對應在不同距離、角度、光照等因素影響下的30張圖像,部分圖像展示如圖10所示。

圖10 龍泉山隧道掌子面圖像
經過人工標記,將該300張圖像輸入本文研發的掌子面圖像質量評價方法體系中,依次通過清晰度判定、圖像分類和相似度判別,測試結果如下:
首先通過清晰度判定模塊,基于閾值21,篩選出了7張模糊圖像,該階段的準確率、查準率、查全率和1值分別為94.0%,94.8%,98.9%和96.8%,基本滿足工程要求。將剩下293張滿足清晰度要求的圖像傳入下一模塊即圖像分類。
在圖像分類階段,評價方法篩選出92張不合格的圖像,其中大多存在沒拍全、有人影遮擋、有巖渣遮擋和有集中光源的情況,該階段的準確率為86.3%,接近模型在驗證集上的準確率,說明該模型的泛化能力較好。
最后將剩余的201張掌子面圖像進行相似度判別,基于閾值0.955,該階段的準確率穩定在92%左右,基本符合預期。
通過以上工作完成對掌子面圖像的質量評價,篩選出滿足工程需求的掌子面圖像,部分如圖11所示。可以看出,經本文方法挑選出來的掌子面圖像具備清晰高、完整度好、光線均勻和遮擋物較少等特點,為下一步掌子面節理識別與自動素描提供優秀素材。與傳統人工地質素描相比,節省了人力物力,降低了人員要求和施工風險,且耗時更短:以一次性對同一掌子面拍攝10張圖像為例,傳入本文提出的評價體系中,歷經清晰度判定?圖像分類?相似度判別3個階段,基于GPU計算總耗時可控制在毫秒級。此外,借助人工智能和大數據技術,實現了數據共享,推動隧道施工信息化和智能化進程。

圖11 龍泉山隧道合格掌子面圖像
4 結論
1) 提出一種基于深度卷積神經網絡的隧道掌子面圖像質量評價方法:從清晰度、分類和相似度3個方面依次對掌子面圖像質量進行評價,過濾掉不合格的圖像,最后成功篩選出能滿足要求的掌子面圖像。具有耗時短、反饋及時的優點,是隧道掌子面自動素描技術里最基礎且不可或缺的一步,具備較高的工程應用價值。
2) 基于DenseNet169網絡的分類模型與掌子面圖像數據集的適應性最好,準確率可達88.7%。
3) 以Laplacian梯度函數為指標的清晰度判定和基于CNN圖像特征提取以余弦相似度為指標的相似度判定,可用于隧道掌子面照片質量評價體系,且效果優良。
受時間、人力和物力所限,數據集的數量和質量尚存較大的提升空間,將來應注重數據集的擴充,改善人工標注,解決分布不平衡問題,完善和健全數據集。此外,探究不同的深度學習框架對訓練結果的影響以尋找最優方案、進一步調整和改進CNN網絡結構也可作為未來的研究方向。
[1] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[2] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, America, 2016: 770?778.
[3] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, America, 2017: 1251?1258.
[4] Szegedy C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston America, 2015: 1?9.
[5] HUANG G, LIU Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, America, S 2017: 4700?4708.
[6] 徐貴力, 劉小霞, 田裕鵬, 等. 一種圖像清晰度評價方法[J]. 紅外與激光工程, 2009, 38(1): 180?184. XU Guili, LIU Xiaoxia, TIAN Yupeng, et al.Image clarity-evaluation-function method[J].Infrared and Laser Engineering, 2009, 38(1): 180?184.
[7] 李郁峰, 陳念年, 張佳成. 一種快速高靈敏度聚焦評價函數[J]. 計算機應用研究, 2010, 27(4): 1534?1536. LI Yufeng, CHEN Niannian, ZHANG Jiacheng.Fast and high sensitivity focusing evaluation function[J].Application Research of Computers, 2010, 27(4): 1534? 1536.
[8] Horita Y, Arata S, Murai T. No-reference image quality assessment for JPEG/JPEG2000 coding[C]// 2004 12th European Signal Processing Conference. IEEE, 2004: 1301?1304.
[9] WANG Z, Sheikh H R, Bovik A C. No-reference perceptual quality assessment of JPEG compressed images[C]// Proceedings of the International Conference on Image Processing. IEEE, 2002, 1: I-I.
[10] 李祚林, 李曉輝, 馬靈玲, 等. 面向無參考圖像的清晰度評價方法研究[J]. 遙感技術與應用, 2011, 26(2): 239?246. LI Zuolin, LI Xiaohui, MA Lingling, et al.Research on clarity assessment method for no-reference images[J]. Remote Sensing Technology and Application, 2011, 26(2): 239?246.
[11] Lowe D G. Distinctive image features from scale- invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91?110.
[12] 吳偉交. 基于SIFT特征點的圖像匹配算法[D].武漢:華中科技大學, 2013. WU Weijiao. Image matching algorithm based on SIFT feature points[D]. Wuhan:Huazhong University of Science and Technology, 2013.
[13] Swaminathan A, MAO Y, WU M. Robust and secure image hashing[J]. IEEE Transactions on Information Forensics and Security, 2006, 1(2): 215?230.
[14] 劉兆慶, 李瓊, 劉景瑞, 等. 一種基于SIFT的圖像哈希算法[J]. 儀器儀表學報, 2011, 32(9): 2024?2028. LIU Zhaoqing, LI Qiong, LIU Jingrui, et al.An image hashing algorithm based on SIFT[J]. Chinese Journal of Scientific Instrument, 2011, 32(9): 2024?2028.
[15] Chopra S, Hadsell R, LeCun Y. Learning a similarity metric discriminatively, with application to face verification[C]// CVPR (1), 2005: 539?546.
[16] Zagoruyko S, Komodakis N. Learning to compare image patches via convolutional neural networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 4353?4361.
[17] Bell S, Bala K. Learning visual similarity for product design with convolutional neural networks[J]. ACM Transactions on Graphics, 2015, 34(4): 98: 1?98: 10.
[18] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]// European Conference on Computer Vision. Springer, Cham, 2014: 818?833.
Research on image quality assessment method of tunnel face based on convolutional neural network
XIAN Qingyu, QIU Wenge, WANG Hongying, XU Weiping, SUN Keguo
(Key Laboratory of Transportation Tunnel Engineering, Ministry of Education, Southwest Jiaotong University, Chengdu 610000, China)
In view of the diversity and complexity of tunnel face images, an image quality assessment method based on deep convolution neural network was proposed to select tunnel face images to meet engineering needs. A tunnel face image dataset based on several tunnels was created. The Keras deep learning framework was adopted. Various mainstream convolutional neural networks (CNN) were applied to carry out comparative experiments. Combining with traditional image evaluation indexes, the tunnel face image quality was evaluated from three aspects: clarity, classification and similarity. The multi-classification model based on DenseNet169 achieved 88.7% accuracy. The results show that, compared with the traditional image processing technologies, the deep learning method has the remarkable advantages of high accuracy and high efficiency in tunnel face image recognition. This method can provide technical support for realizing automatic sketch of tunnel face, and it has a good prospect in engineering application.
tunnel; image quality assessment; convolutional neural network; tunnel face; deep learning
U45
A
1672 ? 7029(2020)03 ? 0563 ? 10
10.19713/j.cnki.43?1423/u.T20190586
2019?06?29
國家自然科學基金資助項目(51678495,51578463)
許煒萍(1981?),女,山東德州人,副教授,從事地下工程施工過程力學與動力學效應研究;E?mail:xwp1981@126.com
(編輯 涂鵬)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
