生成式對抗網(wǎng)絡(luò)在超分辨率圖像重建中的應(yīng)用*
2020-04-15 09:45:44汪鑫耘
計(jì)算機(jī)與生活 2020年4期
關(guān)鍵詞:實(shí)驗(yàn)
汪鑫耘,李 丹
安徽工業(yè)大學(xué) 電氣與信息工程學(xué)院,安徽 馬鞍山 243032
1 引言
超分辨率技術(shù)可以重建低分辨率的圖像以獲得更多細(xì)節(jié)信息,也可以應(yīng)用于低分辨率視頻重建以獲得更好的視覺效果,在實(shí)際應(yīng)用中不可或缺,如高分辨率的醫(yī)學(xué)圖像有利于配合醫(yī)生做出正確的判斷,高分辨率可以更好協(xié)助警方破案等,此外高分辨率的圖像還可以做數(shù)據(jù)增強(qiáng)來提高智能算法的性能。目前主要有重建、插值、學(xué)習(xí)三種方法被用于圖像超分辨率研究,基于重建方法是建立觀測模型之后再逆向求解,最終實(shí)現(xiàn)重組,該方法的問題在于它是一個(gè)不可逆問題且重組結(jié)果不唯一[1]。插值是直接利用圖像的先驗(yàn)信息,再通過建立數(shù)學(xué)模型輸出高分辨率圖像。經(jīng)典的方法有最近鄰插值、雙線性插值、雙三次插值等[2-4],但只對少部分圖像重建效果明顯。隨著所需圖像放大倍率的增加,重建和插值的方法效果都不理想。近年來隨著深度學(xué)習(xí)的迅猛發(fā)展,深度學(xué)習(xí)中的各類智能算法及卷積神經(jīng)網(wǎng)絡(luò)模型被廣泛應(yīng)用到了圖像超分辨率重組中。Dong 等人[5]提出SRCNN(super-resolution using convolutional neural network)的方法,將卷積神經(jīng)網(wǎng)絡(luò)引入到超分辨率重建問題中,但是研究人員發(fā)現(xiàn)SRCNN 很難訓(xùn)練,它對超參數(shù)的變化非常敏感。Yang 等人[6]提出DEGREE(deep edge guided recurrent residual)來指導(dǎo)反饋殘差網(wǎng)絡(luò),初步解決了SRCNN 沒有完全開發(fā)圖像的先驗(yàn)信息和SRCNN 存在丟失細(xì)節(jié)信息的現(xiàn)象等問題。他們大都以均方誤差(mean squared error,MSE)為最小化的目標(biāo)函數(shù),這樣雖然可以取得較高的PSNR(peak signal to noise ratio),但是當(dāng)超分辨率重建倍數(shù)較高,如四倍、八倍時(shí),重建得到的圖像會(huì)非常模糊,丟失大量細(xì)節(jié)。2016 年,Ledig 等人[7]提出了SRGAN(super-resolution using a generative adversarial network),利用對抗式生成網(wǎng)絡(luò)[8]來進(jìn)行超分辨率重建的方法,但使用SRGAN 生成的高分辨率圖像相對原圖比較模糊。2018 年,Wang 等人[9]提出了ESRGAN(enhanced super-resolution generative adversarial networks),使用殘差密集塊RDB(residual dense block)作為生成網(wǎng)絡(luò)的主體,超分辨率重建雖然獲得了較明顯的效果,但其生成的圖像存在過多的偽細(xì)節(jié)。
為了獲取更好的超分辨率重建效果,本文設(shè)計(jì)了PESRGAN(permeability enhanced super-resolution generative adversarial networks)超分辨率重建方法,可以重建四倍下采樣圖像,PESRGAN 基于SRGAN算法框架,在ESRGAN 的基礎(chǔ)上,對激活函數(shù)、基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu)和損失函數(shù)進(jìn)行優(yōu)化,以改進(jìn)超分辨率重建算法。
2 方法與理論
2.1 模型建立
設(shè)計(jì)的PESRGAN 算法采用對抗式生成網(wǎng)絡(luò),包含生成網(wǎng)絡(luò)和判別網(wǎng)絡(luò),其整體結(jié)構(gòu)如圖1 所示。生成網(wǎng)絡(luò)的輸入是低分辨率圖像,經(jīng)過卷積后,輸入殘差密集塊,再通過采樣層和若干卷積層,最后輸出高分辨率圖像;同時(shí)將生成的圖像作為負(fù)樣本輸入判別網(wǎng)絡(luò),判別網(wǎng)絡(luò)的正樣本是非生成的高分辨率圖像,判別網(wǎng)絡(luò)使用經(jīng)典的VGG19 網(wǎng)絡(luò)[10],輸出為判別高分辨率圖像的真假結(jié)果。
2.2 激活函數(shù)
在深度學(xué)習(xí)中常使用ReLU 作為激活函數(shù)可以加速卷積的計(jì)算[11],但是當(dāng)一個(gè)非常大的梯度流過ReLU 神經(jīng)元時(shí),可能會(huì)打亂數(shù)據(jù)分布,導(dǎo)致某些神經(jīng)元不激活任何數(shù)據(jù)而發(fā)生關(guān)閉現(xiàn)象,改進(jìn)的LeakyReLU 可以避免這種情況,LeakyReLU 函數(shù)公式如式(1),其中x是輸入,y是輸出,leaky 為(0,1)的系數(shù)。
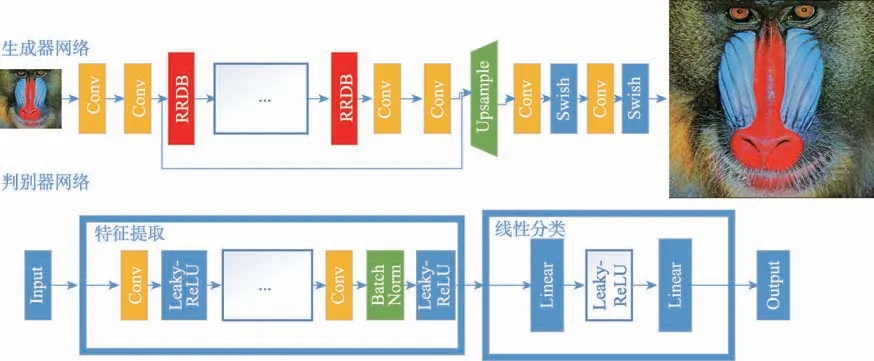
Fig.1 Generator network and discriminator network architecture圖1 生成器網(wǎng)絡(luò)和判別器網(wǎng)絡(luò)結(jié)構(gòu)
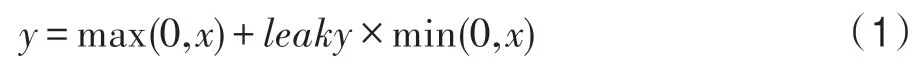
此外本文還使用了Swish 激活函數(shù)[12],Swish 是Google 在2017 年提出的一種新的激活函數(shù),其原始公式如式(2),其中x是輸入,y是輸出。

Swish 激活函數(shù)擁有不飽和、非單調(diào)性等特點(diǎn),Google 在論文中的多項(xiàng)測試表明Swish 激活函數(shù)的性能非常好,在不同的數(shù)據(jù)集上都表現(xiàn)出了優(yōu)于當(dāng)前其他激活函數(shù)的性能。
2.3 生成器模型
PESRGAN 在ESRGAN 的生成器模型結(jié)構(gòu)基礎(chǔ)上進(jìn)行修改,使用殘差密集塊RDB 中的殘差作為基本的網(wǎng)絡(luò)構(gòu)建單元,每3 個(gè)RDB 構(gòu)成1 個(gè)RRDB(residual in residual dense block),RDB 和RRDB 基本結(jié)構(gòu)如圖2 所示。圖像經(jīng)過兩層卷積并使用Swish 函數(shù),后經(jīng)過26 個(gè)RRDB 結(jié)構(gòu),在RDB 結(jié)構(gòu)中使用1×1和3×3 的卷積層,減少參數(shù)量的同時(shí)加深了網(wǎng)絡(luò)。此外RDB 中使用Leaky ReLU 激活函數(shù),加速收斂,這樣更有利于深度網(wǎng)絡(luò)的訓(xùn)練,有效地避免了梯度消失,然后圖像通過殘差密集塊后連續(xù)兩次使用Upsample 方法進(jìn)行上采樣,最后經(jīng)過兩個(gè)卷積層并使用Swish 激活函數(shù)后將圖像還原。
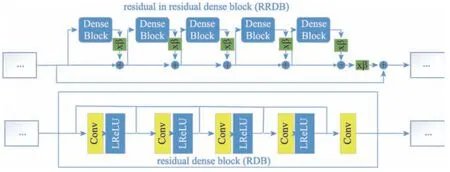
Fig.2 Basic structure of RDB and RRDB圖2 RDB 和RRDB 基本結(jié)構(gòu)
2.4 判別器模型
PESRGAN 使用典型網(wǎng)絡(luò)VGG19 對判別器進(jìn)行訓(xùn)練,將高分辨率圖像輸入VGG19 網(wǎng)絡(luò)之前,對圖像進(jìn)行隨機(jī)旋轉(zhuǎn)、裁剪以增強(qiáng)判別器模型的穩(wěn)定性。最后輸出結(jié)果為二分類,即判別輸入的高分辨率圖像是原始圖像還是生成器生成的圖像。
生成器盡力生成看似真實(shí)的圖像,判別器盡力區(qū)分生成和真實(shí)的圖像,經(jīng)過訓(xùn)練,生成網(wǎng)絡(luò)和判別網(wǎng)絡(luò)形成一個(gè)對抗的過程,最后生成網(wǎng)絡(luò)會(huì)生成非常近似真實(shí)的高分辨率圖像。
2.5 損失函數(shù)
2.5.1 判別器損失函數(shù)
2018 年Jolicoeur-Martineau[13]提出訓(xùn)練生成器時(shí),不僅應(yīng)該提高偽數(shù)據(jù)是真實(shí)數(shù)據(jù)的概率,還應(yīng)該降低實(shí)際數(shù)據(jù)是真實(shí)數(shù)據(jù)的概率。判別器的損失函數(shù)如式(3):
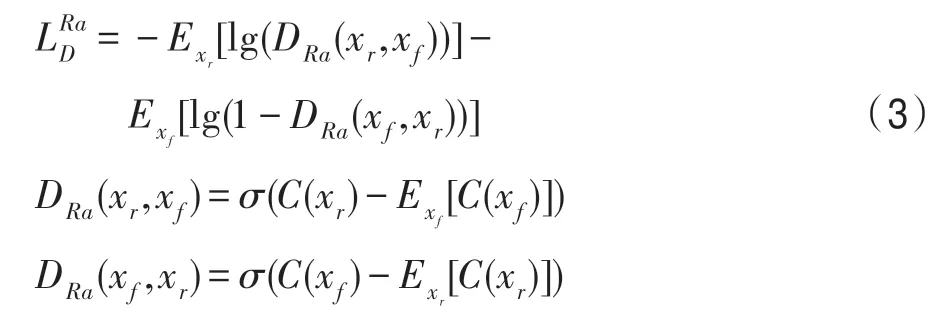
2.5.2 生成器模型損失函數(shù)
基于Bruna 等人[14]和Gatys 等人[15]感知特征相似性的想法,Johnson等人[16]提出感知損失,并在SRGAN中進(jìn)行擴(kuò)展。知覺的損失先前是在預(yù)先訓(xùn)練的深網(wǎng)絡(luò)的激活層上定義的,即兩個(gè)激活功能之間的距離最小化。特征提取同樣使用VGG19 網(wǎng)絡(luò),提取con3-4、conv5-4 雙層特征損失進(jìn)行計(jì)算。
此外,PESRGAN 引入滲透指數(shù)PI(permeability index),即原圖與生成圖像的拉普拉斯算子的方差之比,滲透指數(shù)越大,代表圖像清晰度越高,細(xì)節(jié)越多,采用滲透指數(shù)作為權(quán)值,有利于生成器模型生成更加清晰的圖像。但如果PI 值太大會(huì)產(chǎn)生過多的偽細(xì)節(jié)。PI公式如式(4):
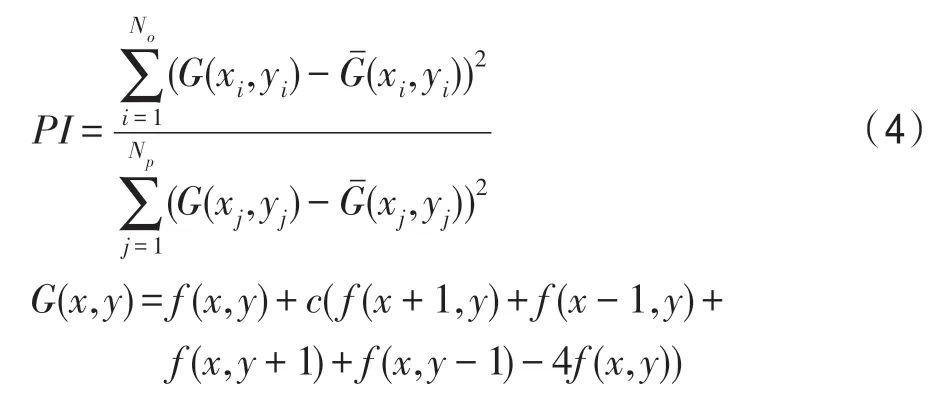
PESRGAN 結(jié)合相對判別器理論對損失函數(shù)重新定義,使用激活層前的特征原因在于:被激活的特征是非常稀疏的,如baboon 的激活神經(jīng)元的百分率在VGG19-54 層后僅為11.17%[9],表示高級特征稀疏激活提供的弱監(jiān)督會(huì)使得性能變差,且使用激活后的特征也會(huì)使得圖像的亮度和真實(shí)圖像不一樣;融合兩層特征優(yōu)點(diǎn)在于雙層特征可以更好地明確損失收斂的方向。生成器模型損失函數(shù)定義如式(5):
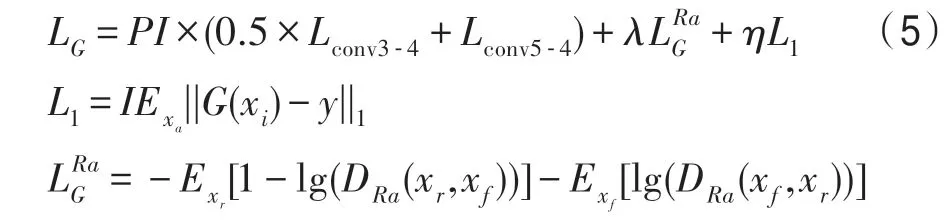
其中,LG為生成器總生成損失,L1是評估圖像G(xi)和真實(shí)圖像y之間的1-范數(shù)距離內(nèi)容損失,λ和η是平衡不同損失項(xiàng)的系數(shù),為相對生成器的損失,PI為滲透指數(shù)參數(shù)。
2.6 評價(jià)函數(shù)
為驗(yàn)證所提算法的效果,采用峰值信噪比PSNR、結(jié)構(gòu)相似性SSIM(structural similarity index)和滲透指數(shù)PI 來評估改進(jìn)的網(wǎng)絡(luò)。PSNR 是對已處理圖像與原始圖像之間的誤差進(jìn)行定量計(jì)算,PSNR 的數(shù)值越大,說明失真越小。SSIM 的數(shù)值越逼近于1,說明處理后的圖像結(jié)構(gòu)與原始圖結(jié)構(gòu)極為近似,表明生成的結(jié)果圖像越好。
PSNR 公式如式(6):
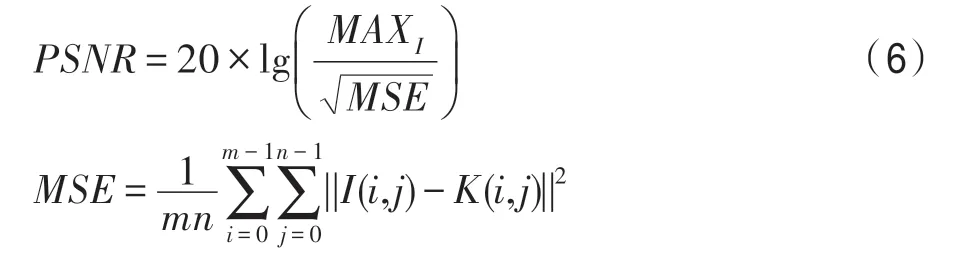
其中,I(i,j)和K(i,j)分別表示原始高分辨率圖像和生成高分辨率圖像。
SSIM 公式如式(7):
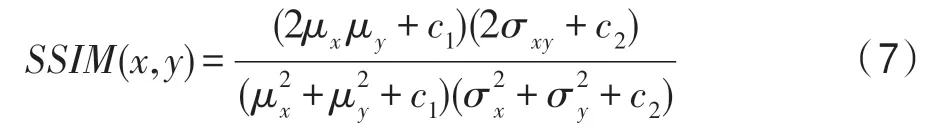
其中,μx是x的平均值,μy是y的平均值,是x的方差,是y的方差,σxy是x和y的協(xié)方差,c1=(k1L)2,c2=(k2L)2用來維持穩(wěn)定的常數(shù)。L是像素的動(dòng)態(tài)范圍,k1和k2是常數(shù),分別為0.01 和0.03。
3 實(shí)驗(yàn)結(jié)果與分析
PESRGAN 的實(shí)驗(yàn)在CPU 為Intel CoreTMi7-6800K@3.400 GHz,GPU 為NVIDIA GTX1080Ti,內(nèi)存為16 GB 的主機(jī)上進(jìn)行。實(shí)驗(yàn)平臺(tái)搭載的操作系統(tǒng)為Ubuntu16.04,深度學(xué)習(xí)框架為pytorch 0.4.0、CUDA9.0。實(shí)驗(yàn)使用DIV2K 訓(xùn)練集和Flickr2K 數(shù)據(jù)集一共1 800幅圖像進(jìn)行訓(xùn)練,其中800 張為DIV2K 數(shù)據(jù)集的訓(xùn)練集圖像,1 000 張為Flickr2K 數(shù)據(jù)集圖像。為了梯度下降的快速與穩(wěn)定,實(shí)驗(yàn)中使用Adam 優(yōu)化器,批大小為16,即一次梯度下降使用16 張圖像訓(xùn)練。由于實(shí)驗(yàn)所使用的GPU 顯存限制,訓(xùn)練過程中生成器網(wǎng)絡(luò)輸入大小為48×48×3 的圖像,經(jīng)過兩個(gè)上采樣層輸出大小為192×192×3 高分辨率圖像,判別器網(wǎng)絡(luò)輸入大小為192×192×3 高分辨率圖像,輸入為二分類,最后測試過程中輸入大小為M×N×3,輸出大小為(4M)×(4N)×3,即四倍上采樣的高分辨率圖像。
經(jīng)過實(shí)驗(yàn),發(fā)現(xiàn)直接使用生成器的總損失函數(shù)很難訓(xùn)練且沒有較好的結(jié)果。因此先使用像素?fù)p失對網(wǎng)絡(luò)進(jìn)行預(yù)訓(xùn)練,后融合相對GAN 損失、多層特征損失和像素?fù)p失來進(jìn)行二次訓(xùn)練。這樣先使用像素?fù)p失預(yù)訓(xùn)練可以減少相對GAN 損失對像素?fù)p失產(chǎn)生的影響,以加速模型整體的收斂,更重要的是經(jīng)過預(yù)訓(xùn)練,判別器最先接收的是較好內(nèi)容的高分辨率圖像,繼續(xù)訓(xùn)練會(huì)更加關(guān)注真實(shí)高分辨率圖像的紋理特征。Set14 數(shù)據(jù)集中的baboon 圖像實(shí)驗(yàn)對比結(jié)果如圖3 所示。
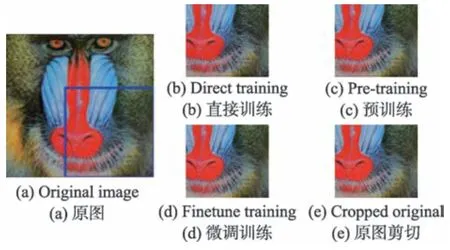
Fig.3 Comparison results of baboon image experiment圖3 baboon 圖像實(shí)驗(yàn)對比結(jié)果
實(shí)驗(yàn)結(jié)合了LeakyReLU 和Swish 激活函數(shù),并修改ESRGAN 算法中生成器基本網(wǎng)絡(luò)結(jié)構(gòu),將本實(shí)驗(yàn)的生成器損失和ESRGAN 生成器特征損失進(jìn)行對比,如圖4 所示(使用預(yù)訓(xùn)練模型)。
由圖4 可知,PESRGAN 的生成器損失收斂速度略快于ESRGAN,雖然Swish 函數(shù)比LeakyReLU 復(fù)雜,但由于對生成器基本網(wǎng)絡(luò)RRDB 的改進(jìn),減小了大量參數(shù),從而提高了算法的速度,且引入了Swish激活函數(shù),使模型具有非線性、平滑和非單調(diào)性的特點(diǎn),最終改進(jìn)算法的損失略低于ESRGAN,說明對激活函數(shù)和網(wǎng)絡(luò)結(jié)構(gòu)的改進(jìn)是有效的。在Set5 數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),平均PSNR、SSIM和PI值結(jié)果如表1所示。
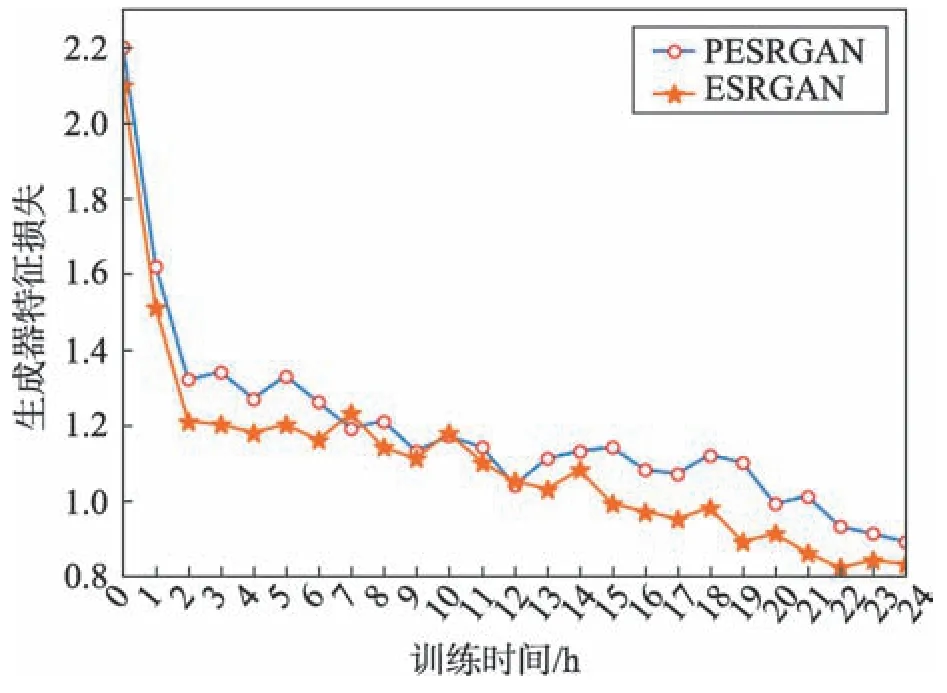
Fig.4 Feature loss comparison of ESRGAN and PESRGAN generators圖4 ESRGAN 和PESRGAN 生成器特征損失對比圖

Table 1 Comparison of average PSNR,SSIM and PI value表1 平均PSNR、SSIM 和PI 值對比
由表1 可知,雖然PESRGAN 相對ESRGAN 的PSNR、SSIM和PI值有所改進(jìn),但對PSNR、SSIM和PI指標(biāo)的提升不是很明顯,尤其是兩種算法的PI值均較大,說明都產(chǎn)生了過多的偽細(xì)節(jié)。
為了產(chǎn)生較少的偽細(xì)節(jié),在以上實(shí)驗(yàn)的基礎(chǔ)上引入PI值作為損失權(quán)重來進(jìn)一步優(yōu)化算法;同時(shí)生成器網(wǎng)絡(luò)使用融合兩層特征損失,明確模型收斂方向。最后使用Set5、Set14、BSDS100、Urban100、DIV2K測試集(100 張)和部分Flickr2K 數(shù)據(jù)集(100 張)進(jìn)行測試,發(fā)現(xiàn)實(shí)驗(yàn)取得優(yōu)秀的重建結(jié)果。同時(shí)使用Bicubic、SRGAN 和ESRGAN 算法進(jìn)行比較,將各測試數(shù)據(jù)集的平均PSNR值、平均SSIM值和平均PI值列成表2、表3 和表4。
由表2~表4 可知,PESRGAN 與Bicubic 相比,雖然PSNR和SSIM指標(biāo)差別不大,但Bicubic 的PI值過大,說明重建的細(xì)節(jié)太少,生成的圖像非常模糊;PESRGAN 與SRGAN 相比,PSNR和SSIM指標(biāo)均有明顯優(yōu)勢,且SRGAN 的PI值不穩(wěn)定,說明重建效果不好;PESRGAN 與ESRGAN 相 比,PESRGAN 的PSNR和SSIM指標(biāo)均高于ESRGAN,說明圖像經(jīng)過PESRGAN 重建后可以獲得更接近原圖的高清圖像,ESRGAN 的PI值遠(yuǎn)低于1,說明ESRGAN 在超分辨率重建過程中會(huì)產(chǎn)生很多偽細(xì)節(jié),而PESRGAN 的值比較接近于1,說明重建后產(chǎn)生的圖像具有與原圖差不多的細(xì)節(jié)量,且經(jīng)過PESRGAN 重建的圖像PSNR和SSIM指標(biāo)均比較好,說明PESRGAN 在超分辨率重建過程中復(fù)現(xiàn)出更多的真實(shí)細(xì)節(jié)。

Table 2 Comparison of average PSNR values of each algorithm in different data sets表2 各算法在不同數(shù)據(jù)集的平均PSNR 值對比 dB

Table 3 Comparison of average SSIM values of each algorithm in different data sets表3 各算法在不同數(shù)據(jù)集的平均SSIM 值對比

Table 4 Comparison of average PI values of each algorithm in different data sets表4 各算法在不同數(shù)據(jù)集的平均PI 值對比
Bicubic、SRGAN、ESRGAN 和PESRGAN 算法在Set5、Set14、BSDS100、Urban100、DIV2K、Flickr2K 數(shù)據(jù)集上的平均運(yùn)行時(shí)間如表5 所示。由于各數(shù)據(jù)集圖像大小不同,故超分辨率重建的時(shí)間也有所不同。
由表5 可知,Bicubic 算法最快,因?yàn)锽icubic 只有插值操作,而SRGAN、ESRGAN、PESRGAN 均含大量卷積層,導(dǎo)致超分辨率重建速度較慢。其中SRGAN最慢,而PESRGAN 在ESRGAN 的基礎(chǔ)上引入更深的網(wǎng)絡(luò),故速度略慢于ESRGAN。綜合以上實(shí)驗(yàn),PESRGAN 算法在沒有損失過多速度的同時(shí),明顯提高了超分辨率圖像重建的PSNR、SSIM和PI指標(biāo),驗(yàn)證了PESRGAN 算法的有效性。
使用Bicubic、SRGAN、ESRGAN、PESRGAN 算法對經(jīng)典圖像Set5-baby、Set14-comic、DIV2K-0801進(jìn)行測試,如圖5 所示,其中HR 為高分辨率原圖,LR為HR 通過區(qū)域插值得到的低分辨率圖像。

Table 5 Average running time of algorithms in different data sets表5 各算法在不同數(shù)據(jù)集的平均運(yùn)行時(shí)間 s

Fig.5 Comparison of HR,LR,Bicubic,SRGAN,ESRGAN and PESRGAN algorithms for super-resolution reconstruction圖5 HR、LR、Bicubic、SRGAN、ESRGAN、PESRGAN 算法超分辨率重建對比
實(shí)驗(yàn)發(fā)現(xiàn)經(jīng)過Bicubic 插值重建的方法得到的圖像過于模糊,SRGAN 得到的圖像相對Bicubic 較清晰,ESRGAN 算法雖然可以得到非常清晰的圖像,但偽細(xì)節(jié)較多,而PESRGAN 產(chǎn)生的圖像不僅清晰,偽細(xì)節(jié)也較少,更符合人眼的舒適度,說明PESRGAN算法在超分辨率重建方面取得優(yōu)秀效果。
4 結(jié)論
本文提出了PESRGAN 算法,用于實(shí)現(xiàn)超分辨率重建四倍下采樣圖像,該方法通過理論分析對抗式生成網(wǎng)絡(luò)的學(xué)習(xí)和訓(xùn)練過程,并在SRGAN 和ESRGAN算法的基礎(chǔ)上對其使用的激活函數(shù)、基礎(chǔ)網(wǎng)絡(luò)和特征損失進(jìn)行改進(jìn):使用LeakyReLU 和Swish 激活函數(shù),引入1×1 的卷積層并加深RRDB 結(jié)構(gòu)以改進(jìn)生成器網(wǎng)絡(luò)的基礎(chǔ)網(wǎng)絡(luò),在生成器網(wǎng)絡(luò)使用雙層特征損失,并引入滲透指數(shù)PI作為損失權(quán)重的改進(jìn)算法。最終實(shí)驗(yàn)在經(jīng)典數(shù)據(jù)集Set5、Set14、BSDS100、Urban100、DIV2K 和Flickr2K 上進(jìn)行驗(yàn)證,PESRGAN的平均PSNR達(dá)到25.4 dB,平均SSIM達(dá)到0.73,平均PI達(dá)到1.15。結(jié)果表明了相對于Bicubic、SRGAN和ESRGAN 算法,重建四倍下采樣圖像后的高分辨率圖像在客觀評價(jià)參數(shù)上均有優(yōu)勢,且在清晰度、人眼舒適度等主觀視覺評價(jià)有很大提升,證明了所設(shè)計(jì)的PESRGAN 算法具有更好的超分辨率重建效果。
猜你喜歡
作文·小學(xué)低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學(xué)生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學(xué)低年級(2024年2期)2024-04-29 00:00:00
作文·小學(xué)低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(bào)(2022年4期)2022-08-09 08:52:06
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
