自適應聚合策略優化的密度峰值聚類算法*
2020-04-15 09:45:52錢雪忠
計算機與生活 2020年4期
錢雪忠,金 輝
江南大學 物聯網工程學院 物聯網技術應用教育部工程研究中心,江蘇 無錫 214122
1 引言
隨著信息技術和互聯網的快速發展,數據源的多樣化和數據量的高速增長,如何進行大規模的數據挖掘和快速獲得有價值的信息成為近期研究的焦點。聚類分析作為一種重要的數據挖掘技術,廣泛應用于模式識別、圖像處理、機器學習、信息檢索等領域。聚類是一個根據樣本間的相似性將數據集劃分成簇的過程,使得簇內的對象最大程度地相似,同時不同簇間的對象最大程度地相異。
在聚類分析的發展過程中,相繼提出了DBSCAN[1](density-based spatial clustering of applications with noise)、FCM(fuzzy C-means)、AP(affinity propagation)等一系列的具有代表性的聚類算法。2014年Science[2]上發表了一篇Clustering by fast search and find of fast search(DPC),論文提出一種快速搜索和發現密度峰值的聚類算法。該算法簡單高效,無需迭代,性能不受數據空間維度影響自動給出數據集樣本的類簇中心,而且對數據集樣本的形狀沒有嚴苛的要求,對任意形狀的數據集樣本都能實現高效的聚類。然而DPC 算法也存在一些缺陷:算法需要設置截斷距離dc,算法的準確性需要依賴截斷距離dc的選擇和對數據集的密度估計;算法使用歐氏距離定義樣本之間的相似性來計算局部密度,存在局限性;聚類中心的選擇需要人工干預而且有的時候聚類中心的選擇不是那么明顯,選擇起來有一定的困難等。
針對DPC 聚類算法存在的不足,Xu 等[3]提出將網格劃分和圓劃分的方法應用于DPC 算法來篩選點,提出基于網格劃分的密度峰值聚類算法和基于圓劃分的密度峰值聚類算法,都能降低算法復雜度,前者的計算時間更短,后者在大規模數據集上的準確度要高于DPC 算法。Du 等[4]提出一種基于K近鄰的快速密度峰值搜索并高效分配樣本的算法KNNDPC(study on density peaks clustering based onKnearest neighbors and principal component analysis),解決了DPC 算法聚類結果對截斷距離dc比較敏感和因為一步分配所帶來的連帶分配錯誤的問題,但是該算法的聚類結果對近鄰數K的選取比較敏感。針對如何準確獲取密度峰值聚類算法聚類中心的問題,文獻[5-6]提出了新的獲取聚類中心的策略,并且較少受到參數影響,提高了聚類的準確率,但是在處理復雜數據[7-10]和大數據時稍顯不足。
本文針對上述遇到的問題,提出了自適應聚合策略優化的密度峰值聚類算法AKDP(optimited density peak clustering algorithm by adaptive aggregation strategy)。AKDP 算法根據數據點的K近鄰數來計算每個數據點的局部密度[11-16],然后用一種新的方法來確定初始聚類中心,最后提出類簇間密度可達的概念來聚合相似度高的類簇,實驗證明AKDP 算法具有更加優秀的聚類效果。
2 局部密度和初始類簇中心
密度峰聚類DPC 算法基于這樣的假設:聚類中心具有比其鄰居更高的局部密度,并且與其他中心的距離相對較大[17-19]。為了建立決策圖然后找到理想的聚類中心,DPC 計算每個點i的兩個量:由式(1)定義的局部密度ρi和由式(2)定義的和更高密度點的距離δi。

其中,dij是點i和點j之間的距離,dc是用戶輸入的截止距離,其可以根據百分比參數p計算得到,p則表示數據對象的近鄰數占總樣本數的平均百分比,一般情況下p在1~2 取值時,DPC 算法能夠取得較好的聚類效果。如果t<0,則χ(t)=1,否則χ(t)=0。對于具有最高密度的點,其Δ取為δi=maxj(dij)。在計算所有點的密度和Δ值之后,DPC 繪制決策圖,其由點的集合(ρi,δi)組成。可以在決策圖的右上區域找到聚類中心,這些聚類中心是具有高δ和相對高ρ的點。通過聚類中心,DPC 可以在一個步驟中將剩余的點分配給與其最近的較高密度的鄰居相同的聚類。結果,DPC 的執行是有效的。具體地,對于“小”數據集(例如,對于聲納數據集),難以對密度進行可靠的估計。因此,DPC 采用式(3)給出的另一個密度度量來計算局部密度。

然而,它沒有客觀的度量來決定數據集是小還是大,而使用這兩個密度指標進行聚類會產生非常不同的結果。此外,對于小型數據集,即使使用式(3)計算局部密度,DPC 的聚類結果也會受到截止距離dc的極大影響。為了消除截止距離dc的影響并為任何大小的數據集提供統一的密度度量,本文將引入K最近鄰居的思想來計算局部密度,采用一種新的方法來選擇初始聚類中心,并且提供一種新的聚合策略來聚合初始的類簇。
為了使得核心區域中的點更易于區分其他區域中的點,也為了提供一個統一的密度度量,通過使用高斯核函數提出了基于K最近鄰概念的新密度度量,這將有助于群集獲得更準確的結果。相對于原先的局部密度度量計算不同數據集需要的不同度量方式,本文提出的局部密度度量減少了算法的人為選擇,也使算法更易區分類簇中心。為了簡化算法使算法具有更高的普適性和減少人為的干預,將截斷距離dc定義為一個普適性的公式,使算法更加智能。因此,本文提出了一種新的局部密度定義公式,如式(4)所示:
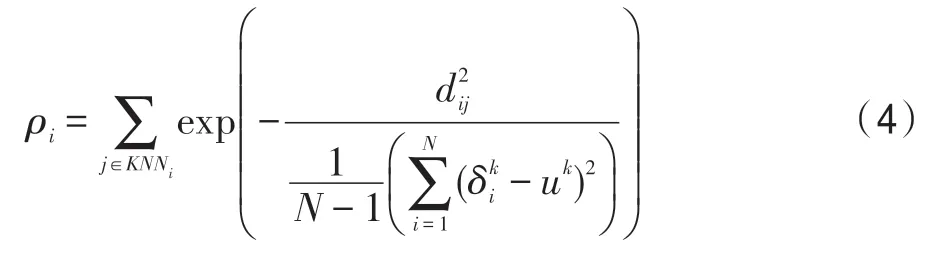
其中,N指的是數據點的個數,指的是數據點i和它的第K個近鄰之間的距離,uk指的是所有數據點和它的第K個近鄰之間的距離的平均值,即所有數據點的值的平均值。為了AKDP 算法的聚類效果,定義了一個確定初始聚類中心的閾值α,如式(5)所示:
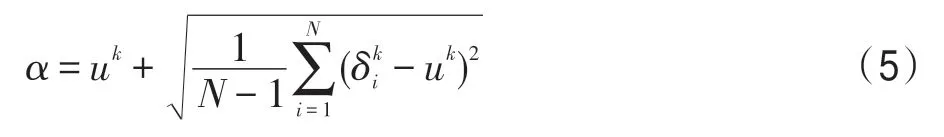
3 聚合策略
為了使AKDP 算法更加智能有效地將數據集進行有效的聚合分離,本文基于以下的定義提出了一種新的有效的聚合策略。
定義1(簇核距離(core-distance of a cluster))一個類簇u的核距離,表示為σu,定義為:

其中,|Cu|指的是類簇u中的數據點的個數,di,center指的是數據點i和類簇中心之間的距離。
定義2(邊界點對(border-points-pair))在類簇Cu和類簇Cv之間的邊界點對,表示為,定義為:
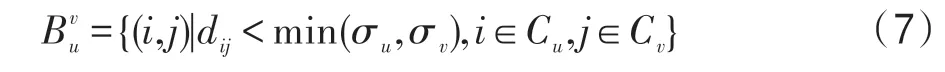
定義3(邊界密度(border-density of a cluster))類簇u的邊界密度表示為,定義為:
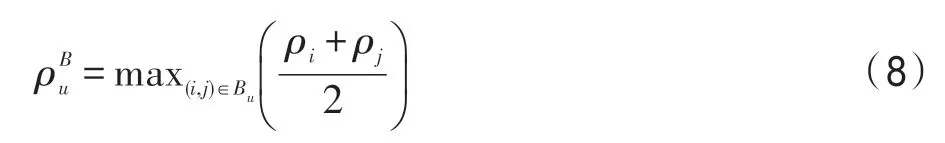
其中,Bu是類簇u和數據集中所有其他的類簇的邊界點對。
定義4(密度直接可達(density directly-reachable))一個類簇u和一個類簇v可以通過邊界密度直接密度可達,只要滿足以下條件:
即類簇u和v之間存在邊界點對,且存在邊界點對滿足第二個條件。
定義5(密度可達(density reachable))如果存在類簇u和類簇w直接密度可達,類簇w又和類簇v直接密度可達,那么說類簇u和類簇v是密度可達的。
通過以上定義,在實驗中如果發現兩個類簇之間是密度可達的,那么就會合并這兩個類簇。通過自適應合并策略,可以找出所有的初始類簇中心,但是這些初始類簇并不一定就是最好的聚類結果,它們之間具有一定的相似性,通過類簇間密度可達合并相似類簇,不會遺漏掉類簇原本的類簇中心,也大大提高了算法的準確性。
根據以上理論,提出AKDP 算法,AKDP 算法的主要優點:
(1)用一種新的基于K近鄰的公式來計算數據點的局部密度,避免了參數敏感問題,提高了算法對數據集的普適性;
(2)算法自適應策略給出的初始閾值可以找出所有的初始類簇中心,確保不會遺漏掉真實的類簇中心,有效提高算法準確率;
(3)用一種有效的、無參的聚合策略來產生最后的結果,合并相似度高的類簇,提高聚類效果。
算法AKDP:


假設AKDP 算法要處理的數據集有N個數據點,存儲每個點到第K個近鄰點的距離需要K×N個空間;其次,存儲每個數據點的δ和ρ值,需要2×N個空間;最后,存儲邊界點對集合最多需要N2個空間,因此AKDP 算法的空間復雜度是O(N2)。
AKDP 算法的時間復雜度由以下幾點決定,計算數據點之間的距離的時間復雜度是O(N2),但可以用快速排序降至O(N×lgN),每個數據點的邊界點的數量理論上可以達到N,計算邊界點對的時間復雜度為O(N2),因此AKDP 算法的時間復雜度為O(N2)。
AKDP 算法對參數K的選擇遵循一定的規律,一般先選擇數據樣本的10%作為初始值,聚類個數如果偏多則增加K的值,反之減小K的值。
4 實驗結果與分析
為了證明AKDP 算法的有效性,將AKDP 算法與DPC[2]、DBSCAN[1]、KNNDPC[4]算法在合成數據集和UCI 數據集上進行實驗,真實數據集上加上了Kmeans 算法進行對比。圖1 顯示了4 個合成數據集。Data1由兩個不平衡的流形類組成,共567個點。Data2由3 個復雜流形類組成,共3 603 個點。Data3 由7 個復雜球形類組成,共788 個點。Data4 由31 個高密度復雜球形類組成,共3 100 個點。對于DPC 算法、KNNDPC 算法和DBSCAN 算法,進行多次實驗取效果最好的結果進行對比,但DPC 算法和KNNDPC 算法在人為選擇聚類中心時要符合選取聚類中心的一般規則。
圖2 顯示了Data1 在DPC、DBSCAN、KNNDPC和AKDP 算法上的聚類效果。DPC 算法能聚類正確的類簇數,也可以將所有點準確聚類,聚類效果較好,KNNDPC 算法同樣可以準確聚類,DBSCAN 算法無法準確確定類簇的個數,聚類效果不好,錯誤地將一個類簇的點聚類成了兩個類簇,AKDP 算法能準確聚類,聚類效果也很好,明顯比DBSCAN 算法聚類效果要好,總之在Data1 數據集上,DBSCAN 算法聚類效果不好,DPC 算法、KNNDPC 算法和AKDP 算法可以準確確定類簇的個數且聚類效果很好,但是DPC算法和KNNDPC 算法需要一定的人為選擇,有不確定因素。
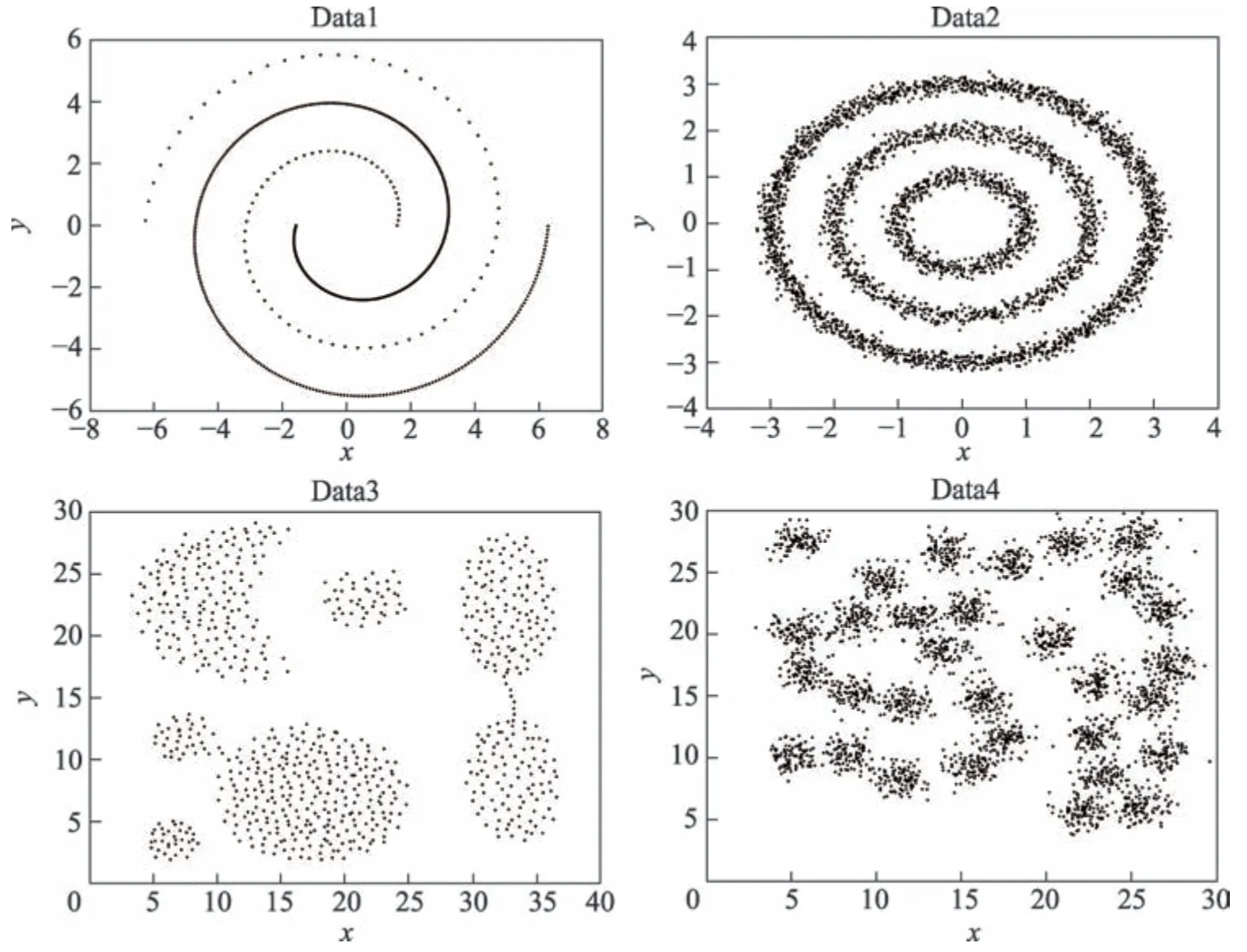
Fig.1 Original dataset圖1 原始數據集
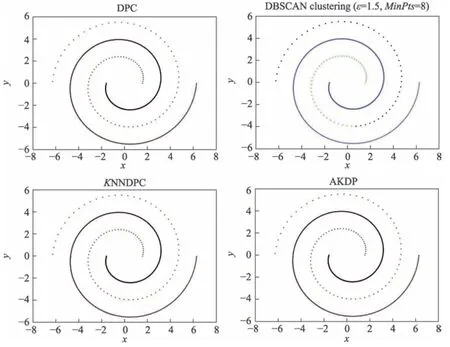
Fig.2 Clustering results of DPC,DBSCAN, KNNDPC and AKDP on Data1圖2 Data1 在DPC、DBSCAN、KNNDPC、AKDP 上的聚類結果
圖3 顯示了Data2 在DPC、DBSCAN、KNNDPC和AKDP 算法上的聚類效果。DPC 算法雖然選擇了正確的類簇數,但無法將所有點準確聚類,聚類效果不好,KNNDPC 算法同樣只是將復雜流形簇距離近的點聚為一類,DBSCAN 聚類算法和AKDP 算法都能準確聚類,聚類效果都很好,但是DBSCAN 算法需要更多的參數。
圖4 顯示了Data3 在DPC、DBSCAN、KNNDPC和AKDP 算法上的聚類效果。DPC 算法對球形簇的聚類效果很好,對復雜流形簇也有一定的聚類效果,但是對Data3 數據集顯然沒有取得很好的聚類效果,將離得近的一大兩小三個球形數據集錯誤地聚為一個類簇,KNNDPC 算法存在和DPC 算法類似的問題,錯誤地將兩個流形的數據集聚為一類,聚類產生偏差,顯然DBSCAN 算法聚類效果優于DPC 算法和KNNDPC 算法,對數據集具有很好的聚類效果,但是DBSCAN 算法的參數需求更大,AKDP 算法能夠準確確定類簇的個數,同時最后的聚類效果也十分優秀。
圖5 顯示了Data4 在DPC、DBSCAN、KNNDPC和AKDP 算法上的聚類效果。DPC 算法和KNNDPC算法雖然選擇了正確的類簇數,聚類效果也很不錯,但是聚類時間較長,且在人工決策圖上需要選出的聚類中心點多且密集,稍有偏差就會對聚類效果產生不好的影響,DBSCAN 獲得了正確的類簇數,也獲得了好的聚類效果,但是同樣的需要較多的參數,AKDP 算法獲得了正確的聚類數并獲得了很好的聚類效果,人為影響較小。
因此,AKDP算法在Data1數據集上的聚類效果明顯優于DBSCAN 算法,在Data2、Data3 上的聚類效果明顯優于DPC算法和KNNDPC 算法,且比DBSCAN需要更少的參數,比DPC 算法和KNNDPC 算法需要人為干預的更少,具有一定的魯棒性。
接著,將AKDP 算法在UCI 數據集上進行實驗,數據集信息如表1 所示。
在實驗中,采用Acc(準確率)、F-measure(加權F值)和算法聚類個數與正確的類簇數的比這3 個聚類指標來評價AKDP 算法,并將AKDP 算法與DPC、DBSCAN、KNNDPC、K-means 算法對比,實驗結果如表2 所示。
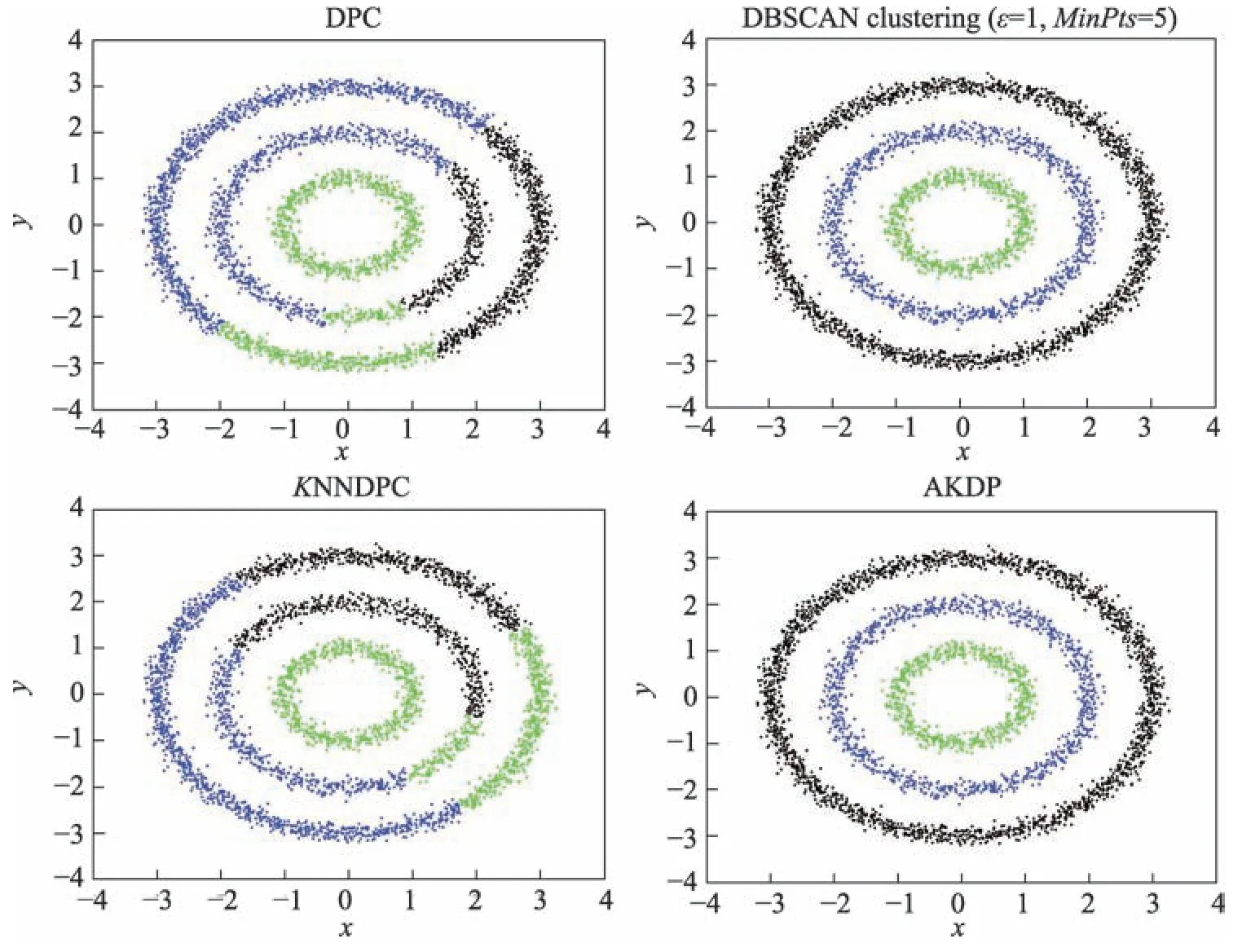
Fig.3 Clustering results of DPC,DBSCAN, KNNDPC and AKDP on Data2圖3 Data2 在DPC、DBSCAN、KNNDPC、AKDP 上的聚類結果

Fig.5 Clustering results of DPC,DBSCAN, KNNDPC and AKDP on Data4圖5 Data4 在DPC、DBSCAN、KNNDPC、AKDP 上的聚類結果
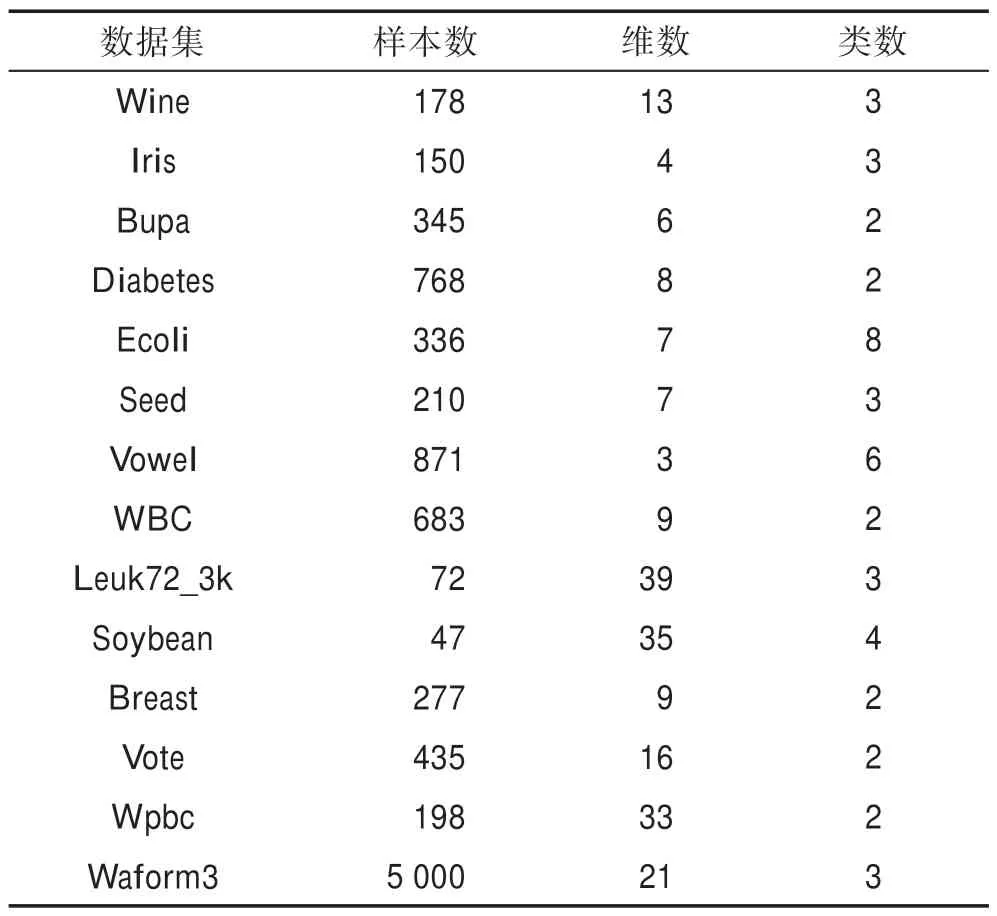
Table 1 Information of datasets表1 數據集信息
由表2 可知,在準確率上,除了在Vote 數據集上KNNDPC 算法比AKDP 算法高0.2 個百分點,在其他數據集上AKDP 算法要明顯優于DPC、DBSCAN、KNNDPC 和K-means算法。
在F值的計算上,除了在Breast 和Wpbc 數據集上DBSCAN 要稍稍優于AKDP 算法,其他數據集上AKDP 算法都明顯優于DPC、DBSCAN、KNNDPC 和K-means算法。
在最終聚類數的準確率上,AKDP 算法都能聚類出正確的類數,K-means 算法由于提前選擇了正確的類簇數目,因此不存在能不能聚類出最終正確的類簇數這一評價指標,DNSCAN 算法在Ecoli、Seed、Waform3、Vowel 和Wpbc 數據集上無法聚類正確的類簇個數,而DPC 算法無法在Bupa、Ecoli、Vowel、Leuk72_3k 和Breast 數據集上聚類正確的類簇個數,KNNDPC 算法在Wine、Ecoli、Vowel 和Leuk72_3k 數據集上無法聚類正確的類簇個數。因此在聚類正確類簇個數這個評價指標上,AKDP 算法也是最優秀的。
綜合這三方面,顯然AKDP 算法是最優秀的。
5 結束語
本文提出了一種新的自適應聚合策略優化的密度峰值聚類算法AKDP。首先該算法通過最近K近鄰的概念,用一個新的公式來定義數據點的局部密度,然后根據閾值判斷初始聚類中心,最后通過類簇間密度可達概念來把相似的類簇合并產生最后的聚類結果。通過實驗,AKDP 算法在對人工數據集、UCI 數據集和復雜流形數據集的處理上具有相當大的優越性,比DPC、DBSCAN、KNNDPC 和K-means算法更準確有效,且受人為影響更少。
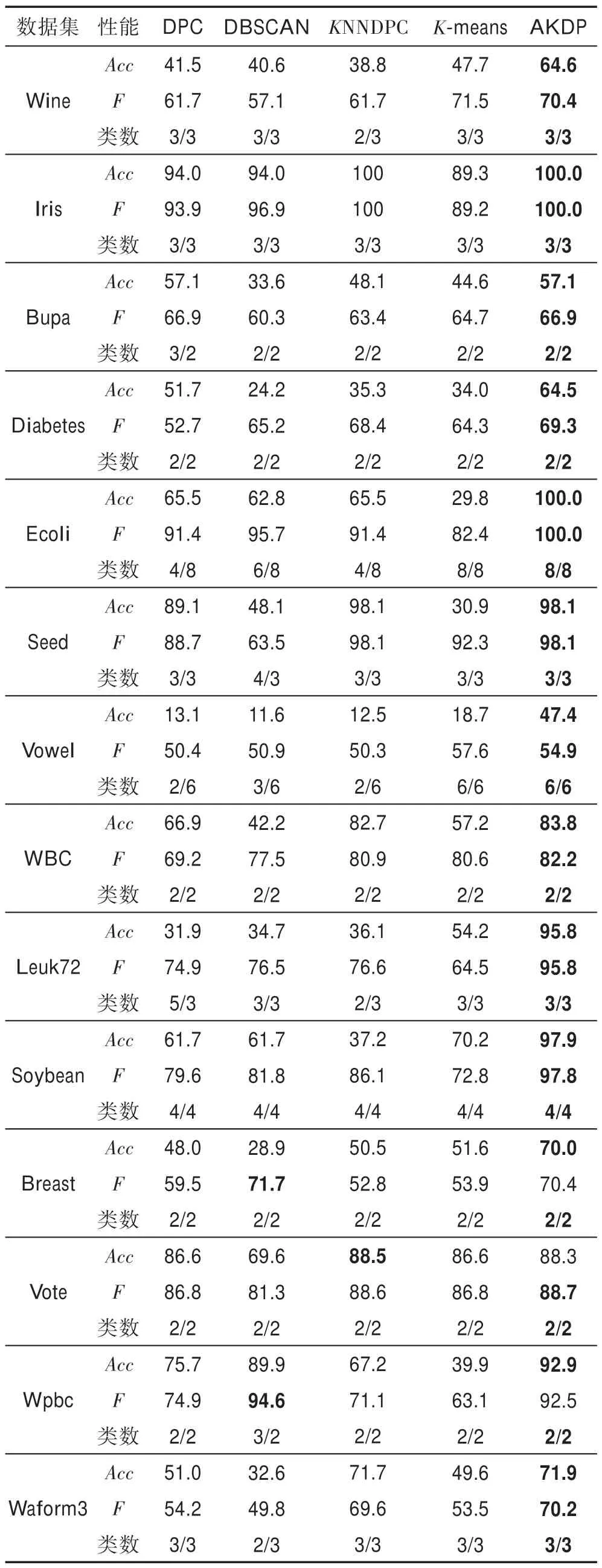
Table 2 Information of clustering index表2 聚類指標信息
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
山東青年(2016年1期)2016-02-28 14:25:25
中國醫藥科學(2015年19期)2015-02-27 12:33:11
軍事體育學報(2014年3期)2014-02-27 16:00:13
當代修辭學(2014年3期)2014-01-21 02:30:44
