人工智能能力平臺建設思路
2020-04-20 11:25:52山東張誌張延彬邢慶文楊濱
網絡安全和信息化 2020年3期
■山東 張誌 張延彬 邢慶文 楊濱
運營商人工智能能力平臺應包括如下部分:
1.硬件基礎設施,包括各類服務器及網絡設備。
2.IaaS 層能力,包括各類資源的虛擬化、租戶管理能力、資源調度能力。
3.PaaS 層能力,包括各類基礎軟件包、運行環境、算法框架等開發環境,以及面向圖像識別、人臉識別、語義理解、語音識別、語義理解、語音合成等基礎能力服務,以便于上層應用進行調用及集成。
4.SaaS層能力,提供面向智慧營業廳、智能基站巡檢等業務場景的成型解決方案,供不同使用單位(租戶)按需進行調用。同時,人工智能能力平臺還需與外部人工智能開放平臺進行銜接,以獲取相關訓練數據、調用外部既有能力等。人工智能能力平臺整體架構如圖1 所示。
基礎設施層建設思路

圖1 人工智能能力平臺總體架構
近年來人工智能特別是深度學習的崛起,與計算能力的突飛猛進關系密切。而引領計算能力飛速提升的、則是異構計算的發展。異構計算,主要指不同類型的指令集和體系架構的計算單元組成的系統的計算方式,目前主要的異構計算平臺包括“CPU+GPU”、“CPU+FPGA”、“CPU+ASIC”架構。相較于純CPU 的計算平臺,異構計算平臺帶來了數十甚至上百倍的性能提升、同時帶來數十倍的能效提升。各類計算平臺特點說明如表1 所示。
考慮到運營商所面對AI 業務場景的多樣化,需要根據不同場景選擇相應的AI 算法,例如圖像識別場景與語義分析場景所適用的AI 算法存在較大差別,因此需要更為通用的硬件計算平臺;同時,需考慮運營商現有的自研能力與業界前沿的互聯網廠家有較大差距,因此需要優先選擇較為成熟的商業化產品,借助業界研發力量、滿足自身業務需求。

表1 各類AI 計算平臺特點比較
綜上考慮,雖然“CPU+FPGA”、“CPU+ASIC”架構在性能、能效比方面具備優勢,但也需要非常強的算法甚至芯片級的自研能力,而這些能力并非運營商優勢領域,因此建議在計算平臺選擇時,總體優先考慮“CPU+GPU”架構平臺,尤其是在訓練場景;隨著5G 發展,未來可以在自動駕駛等實時性要求非常高的推理場景考慮引入“CPU+ASIC”等架構,以提供更高的計算性能、降低時延。
就“CPU+GPU”架構平臺而言,目前業界產品主要以GPU 服務器方式提供,包括NVIDIA 原廠DGX 服務器,以及服務器廠商采購NVIDIA GPU 卡、并進行OEM 的GPU 服務器。相比較來看,NVIDIA原廠DGX 服務器使用了更高效的NV-Link 總線接口,單服務器內部各GPU 可以做到全線速互連,并隨服務器配置了專門優化的操作系統、驅動程序、開發包等軟件,性能相比OEM 服務器更高,預置功能也比較全面,但其價格也相應的遠超OEM 服務器。運營商在設備選型時,應綜合衡量性能與價格,選擇適合自身需求的產品。
目前GPU 服務器單臺最多支持16 塊NVIDIA V100 GPU 卡,如存在超出單臺GPU服務器處理能力的需求,可考慮將多臺GPU 服務器通過外部網絡進行互連、組成計算集群。外部互連網絡可選擇40Gbps 以上高速以太網、或Infiniband 網絡。從集群總體性能來看,同一GPU板卡內通信速率在1000Gbps級別、同一服務器內速率在300Gbps 級別,而服務器間通信速率在100Gbps 以下,因此網絡接口為GPU 服務器集群的主要性能瓶頸;同時,網絡協議的處理也將占用大量的系統資源、造成相應的延遲,因此需要選擇端口速率高、網絡協議簡單的組網方案。
對比以太網與Infiniband 網絡,后者協議更加簡單,且在主流商用網卡產品情況下端口速率更高,在構建GPU 服務器集群時應優先選擇Infiniband網絡進行組網。
IaaS 層建設思路
IaaS 層主要提供對GPU服務器資源的管理及分配能力,從資源層面對GPU 服務器進行虛擬化,供多個租戶按需使用,并對租戶進行資源的分配、管理以及資源的回收。
在構建IaaS 能力時,可考慮與運營商現有云管平臺進行融合復用,即將GPU 服務器部署于企業現有私有云資源池內,通過資源池的OpenStack 平臺進行統一管理,主要通過Nova 進行資源的分配、管理、調度、回收等工作。管理過程如圖2 所示。
其中GPU 資源將作為PCI 設備隨虛擬機分配過程一并分配給租戶使用。從虛擬化對PCI 的模擬分配方式來說,為虛擬機配置GPU 包括直通、分享、GPU 虛擬化三種方式。
1.直通模式:通過PCI的透傳由客戶機進行GPU 獨占。
2.共享模式:PCI 設備由客戶虛擬機和物理機共享。

圖2 云管平臺統一納管GPU 服務器
3.GPU 虛擬化:類似于CPU 的虛擬化功能、GPU 自身支持虛擬化功能,例如NVIDIA 最新推出的vComputeServer 功能,與VMWare、KVM 等虛擬化軟件進行結合,在做到資源細粒度分享的同時、還提供vGPU 隨虛擬機遷移的能力。
從性能來說,直通模式性能接近于GPU服務器裸機性能,性能損耗低于5%,是目前主要的資源配置方式;NVIDIA 最新的GPU 虛擬化方式目前尚未大規模商用,根據其宣稱性能也接近于裸機模式,但需要額外采購其vComputeServer 軟件;而共享模式由于存在設備模擬和轉換的過程,性能損耗較大,不建議使用。
從配置靈活性來說,直通模式只能提供板卡級資源粒度劃分,即只能將1 塊或多塊GPU 分配給單個虛擬機;GPU 虛擬化模式則可以提供更細粒度的資源,相對來說更貼合客戶需求、資源利用率更高。
從業務場景來說,深度學習的訓練過程因計算量較大,一般采用GPU 服務器裸機模式、或虛擬機GPU 直通模式;而推理過程則可使用GPU 虛擬化模式,將GPU 資源盡量分配給更多租戶使用,以提升資源利用率,并增強資源配置的靈活性。
引入虛擬化能力更多是為了給租戶提供資源隔離能力、并提升管理便利性。在IaaS 構建時,還需要考慮引入容器技術,用于算法庫、算法框架等開發環境的封裝,IaaS 需提供對容器鏡像的管理能力,包括鏡像制作、下發,容器的啟動、運行、管理、回收等能力。
PaaS 層建設思路
PaaS 層應提供兩大類能力,即提供快速、實時服務能力的AI 能力,以及用于非實時、大數據量訓練的算法框架。前者主要是將成熟的語音、語義、視覺能力進行固化、服務化,為前端應用提供標準的程序接口、開發包,供各業務場景快速調用、集成,形成相應的AI 能力;后者則主要負責深度神經網絡模型的訓練,基于運營商自有的海量數據,提供針對業務場景定制的深度神經網絡模型訓練算法,并將訓練成型的模型輸出給前者,供前臺應用調用。
在算法框架選擇方面,既需要提供GPU 底層的CUDA等編程框架、cuDNN 等加速庫,也需要提供深度學習相關算法框架,以降低開發門檻、加速業務實現進度。目前主流的深度學習算法框架包括TensorFlow、Caffe 等,各類框架對比如表2 所示。其中TensorFlow 已成為近年最為流行的算法框架,但不同的框架適用的領域不完全一致,各有優劣,因此在平臺構建時,應考慮多種主流模型的預置,并根據后續實際需求不斷補充。
接口層建設思路
主要包括PaaS 層對外提供AI 服務能力的相關接口、與運營商大數據平臺對接接口,以及與外部優勢AI 廠家合作的程序或數據接口。
PaaS 層對外提供AI 服務能力的相關接口包括多種形式接口,例如可供上層應用直接調用的應用程序開發接口,接收外部數據輸入的接口等。該接口是最終使用用戶與人工智能能力平臺交互的接口。
大數據平臺對接接口則用于從運營商自建大數據平臺獲取相關訓練用原始數據,例如長期存儲的賬單、詳單、網管記錄信息等反應用戶畫像的相關數據,業務受理單、用戶身份證等圖像數據,客服受理記錄等原始語音數據,以及集中性能平臺等網絡類大數據平臺存儲的網元相關性能、故障、配置、優化等數據,通過訓練得到相應模型,用于客戶服務、市場營銷、網絡智能化運維及優化等業務場景。
此外,運營商人工智能能力平臺還需要與科大訊飛、百度等各領域領先的AI 企業建立接口,通過使用外部平臺進行訓練、自有資源池部署外部應用等多種途徑集成第三方人工智能開放平臺。與外部平臺采用何種合作方式需根據數據的保密等級、建設進度、建設成本等多方面因素綜合考量。
SaaS 層建設思路
SaaS 層主要考慮對于一些通用性較強的AI 應用進行產品化,在全網或全省統一部署,由各省、各地市、各業務部門等作為租戶進行調用,實現AI 能力的快速推廣和使用。
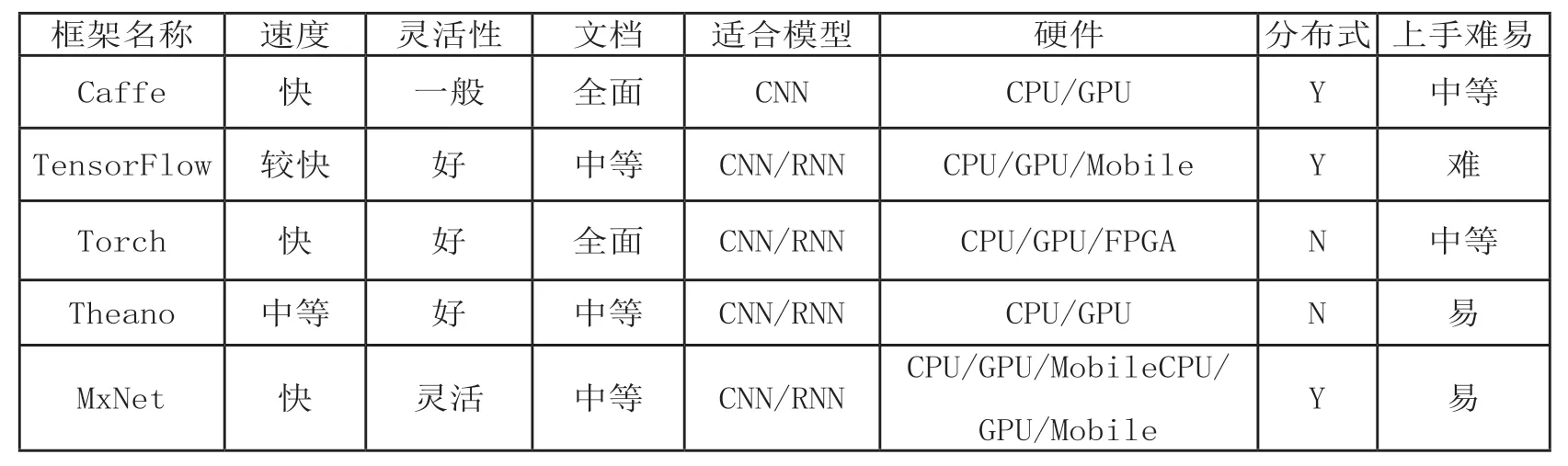
表2 各類深度學習算法框架特點比較
目前可考慮引入的SaaS服務包括智能客服、智慧營業廳、智慧運維、自動化巡檢、產品智能推薦以及智能家居產品推廣等,后續可根據業務需求不斷豐富SaaS服務種類。
結束語
目前人工智能技術在基礎硬件(GPU 加速異構計算)、關鍵算法(圖像、語音、語義識別)等領域已逐步進入成熟期、正在快速迭代演進,運營商應抓住機遇,及早構建自有人工智能能力平臺,力求在5G 時代發力自動駕駛、遠程醫療、虛擬現實等業務領域,形成核心競爭力,并為社會提供智慧服務能力。
猜你喜歡
發明與創新(2022年30期)2022-10-03 08:40:56
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
商界(2019年12期)2019-01-03 06:59:05
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
IT經理世界(2018年20期)2018-10-24 02:38:24
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
小康(2017年16期)2017-06-07 09:00:59
資源再生(2017年3期)2017-06-01 12:20:59
