基于圖像與點云的三維障礙物檢測
2020-04-24 08:56:32張耀威卞春江陳紅珍
計算機工程與設計 2020年4期
張耀威,卞春江,周 海+,陳紅珍
(1.中國科學院國家空間科學中心 復雜航天系統綜合電子與信息技術重點實驗室,北京 100190;2.中國科學院大學 計算機科學與技術學院,北京 100049)
0 引 言
近幾年來,伴隨著人工智能技術的不斷發展,智能機器人具備了更多的功能,包括:環境監測、巡邏安檢、導航、自主灌溉等等,越來越多的機器人應用于室外場景。因此室外機器人的感知能力對于其應用起著至關重要的作用。本文立足于室外輪式機器人的應用,改進了一種三維障礙物檢測的方法,提升了其檢測精度。
在傳統的檢測方法中,謝德勝等[1]使用了模板匹配的方法進行障礙物檢測,王海等[2]使用了聚類的方法進行障礙物檢測。近幾年來,基于圖像的檢測技術已經非常的成熟了,有經典的Faster Rcnn[3,4]系列,Yolo[5-7]系列和SSD[8]系列等,其在圖像檢測領域已經達到了非常高的水平,如陸峰等[9,10]是用了Faster Rcnn在雷達數據的俯視圖進行障礙物的檢測。
一般地,帶有三維信息的數據輸入有深度圖像和雷達點云兩種。通過雙目視覺獲取的深度圖像有著距離短、夜晚效果差的缺點,所以大部分室外場景的實驗和應用都使用雷達點云作為輸入。近兩年來,有許多針對點云數據處理的方法,如使用體素的VoxelNet[11],使用多角度的Multi-view 3D[12],針對點云整體處理的Pointnet[13]等。其中Frustum PointNets[14](平截頭點云網絡)利用二維檢測鎖定目標,再提取點云并使用Pointnet進行三維點云檢測,提高了Pointnet的檢測效率。本文基于平截頭點云網絡的架構,提出了一種擴張平截頭點云的三維障礙物檢測方法。該方法對其二維網絡和三維網絡之間結合的部分進行改進,加入了擴張包圍框,提高了三維檢測的精度。
1 正 文
本文基于平截頭點云網絡,加入了二維包圍框擴張,提出了一種擴張平截頭點云檢測的方法。該方法使用了圖像和雷達點云數據,完成了室外街道場景中障礙物的三維檢測和識別,提高了障礙物檢測的精度。
該方法首先使用了Yolov3在圖像中進行了障礙物的檢測與識別;然后對得到的二維包圍框進行擴張,利用擴張后的二維包圍框提取雷達數據中對應的點云;最后利用改進的Pointnet對該點云進行計算,得到對應點云的三維坐標。對于障礙物識別,使用圖像分類的類別作為識別結果。本文使用的方法構架如圖1所示。
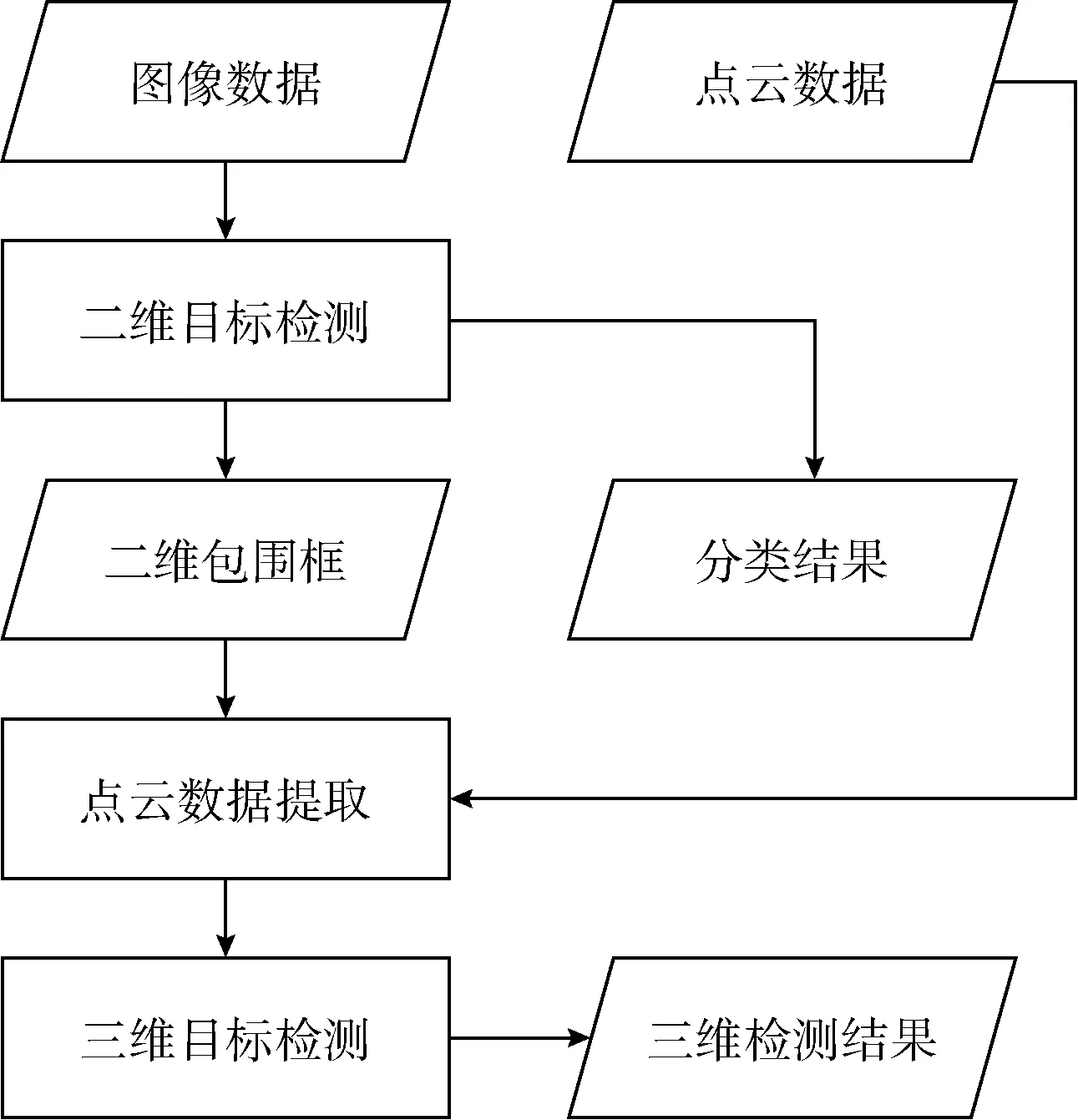
圖1 擴張平截頭點云檢測方法架構
1.1 二維目標檢測
本文借鑒平截頭點云網絡的結構,實現室外街道場景中障礙物的檢測和識別,整個架構的開始依賴于二維目標檢測的結果,因此首先使用二維目標檢測網絡對障礙物進行檢測。
目前主流的目標檢測網絡有兩個階段類型的Faster Rcnn系列和一個階段類型的Yolo、SSD系列。其中Yolov3使用多個尺度融合進行了檢測,對小目標的檢測結果提升,網絡結構簡單,檢測速度也比較快。
二維包圍框的好壞會影響后續檢測的效果。與其它的二維目標檢測網絡相比較,Yolov3在COCO(common objects in context)數據集中的檢測效果更好,與其它方法對比的結果見表1[7]。
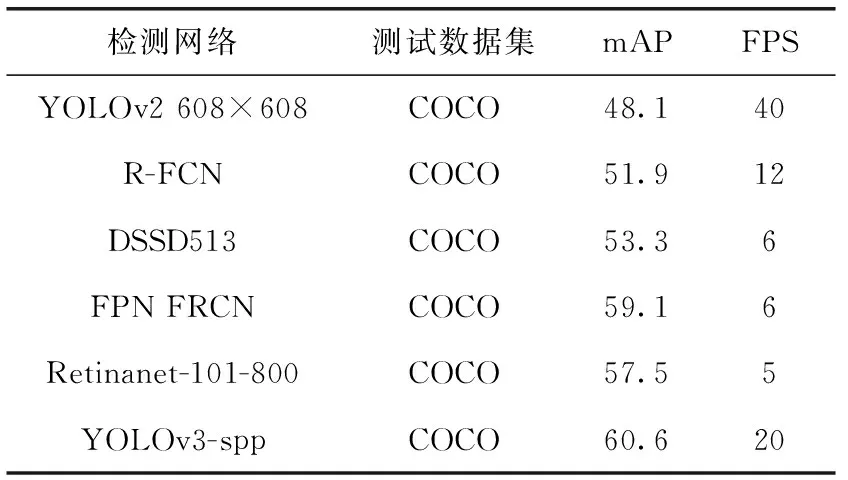
表1 二維檢測網絡性能對比
由表1可以看出Yolov3的性能從檢測精度和檢測時間來說,相對更好,因此本文使用Yolov3進行障礙物檢測,提取障礙物二維包圍框和分類置信度。
1.2 點云提取
圖像數據和雷達數據是不同維度的數據,在利用圖像數據提取雷達數據的時候,需要對圖像數據和雷達數據進行關聯。利用數據集提供的投影矩陣,可以完成圖像二維數據與雷達三維數據之間的相互轉換。
在KITTI[15]數據集的標定文件中包含了轉換的矩陣P,通過矩陣P可以將雷達數據投影到對應的圖像平面當中。
空間三維點的坐標可以表示為
X=(x,y,z,1)T
(1)
投影矩陣可以表示為
(2)
其中,i為第i個相機編號;
圖像與雷達數據的轉換為
(3)
其中,輸出的Y為投影到了二維相機坐標系中的坐標。
根據檢測得到的二維包圍框提取投影后對應的點云數據,因此二維包圍框的好壞直接影響到了后續點云檢測網絡的性能。二維包圍框過小造成提取出的點云不足,會影響三維檢測網絡的檢測邊界范圍;二維包圍框過大造成提取雜點過多,會導致三維檢測位置大小信息不準。根據目前目標檢測理論方法的成果,二維檢測框檢測的結果已經達到了比較好的水平,再進一步大幅度提高難度比較大,因此,可以在二維目標檢測框和三維點云提取的銜接部分進行改進。通過擴張二維檢測框,可以有效提高點云提取的召回率,避免障礙物點云信息丟失,增加了三維檢測數據輸入的完整性,進而提升三維檢測效果。本文加入對二維包圍框的擴張,利用擴張后的二維包圍框對點云數據進行提取。檢測包圍框的擴張如圖2所示。
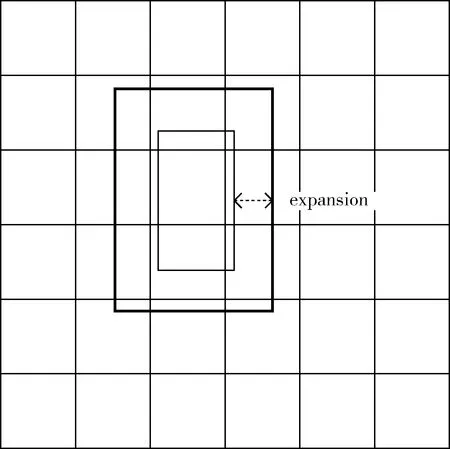
圖2 二維包圍框的擴張
利用投影矩陣將點云數據投影到平面,通過圖像大小對雷達數據進行第一次裁剪,再通過二維包圍框對點云進行第二次裁剪,將裁剪后剩余的點云的數據提取出來,完成了點云數據的提取。
1.3 三維目標檢測
對于三維目標檢測,本文借助點云網絡的結構,對其
進行改進,因此使用基本網絡結構為Pointnet。Pointnet的兩個基本結構是轉換網絡與最大池化,使用轉換網絡可以使點云進行旋轉,使用最大池化可以對升維之后點進行特征篩選,解決了點云輸入無序性的問題。
針對Pointnet的網絡結構進行改進,使其可以輸出點云的三維位置,使用一個7維度的向量來表示點云的位置和大小,即 [x,y,z,l,w,h,θ], 分別表示點云的中心坐標、長寬高以及在俯視圖平面相對于正方向的轉角θ。 其中在網絡訓練的過程當中需要對檢測點云進行旋轉平移的歸一化處理,因此需要使用到轉換網絡的結構。
改進網絡結構的輸入是提取獲得的點云數據,輸出是檢測的三維結果。其中轉換網絡生成的是一個同點云維度相同的變換矩陣。
改進的Pointnet網絡結構如圖3上部分所示。輸入為 [n×3] 的點云,每個點云的使用三維度的 [x,y,z] 空間點表示,經過一個轉換網絡,對點進行變換處理;通過多層感知機將每個點的維度提升到64;再經過相同的操作將點的維度信息提升到1024;經過最大池化,提取出顯著特征,最后經過多層感知機將輸出維度改變為7維度。
其中轉換操作的具體過程如圖3的下半部分所示,原始數據經過多層感知機將維度提升到1024,在經過極大池化,最后通過多層感知機將維度改變到256維度;將得到的輸出與 [256×9] 維度的參數進行矩陣相乘,得到9維度的向量,即 [3×3] 的轉換矩陣。
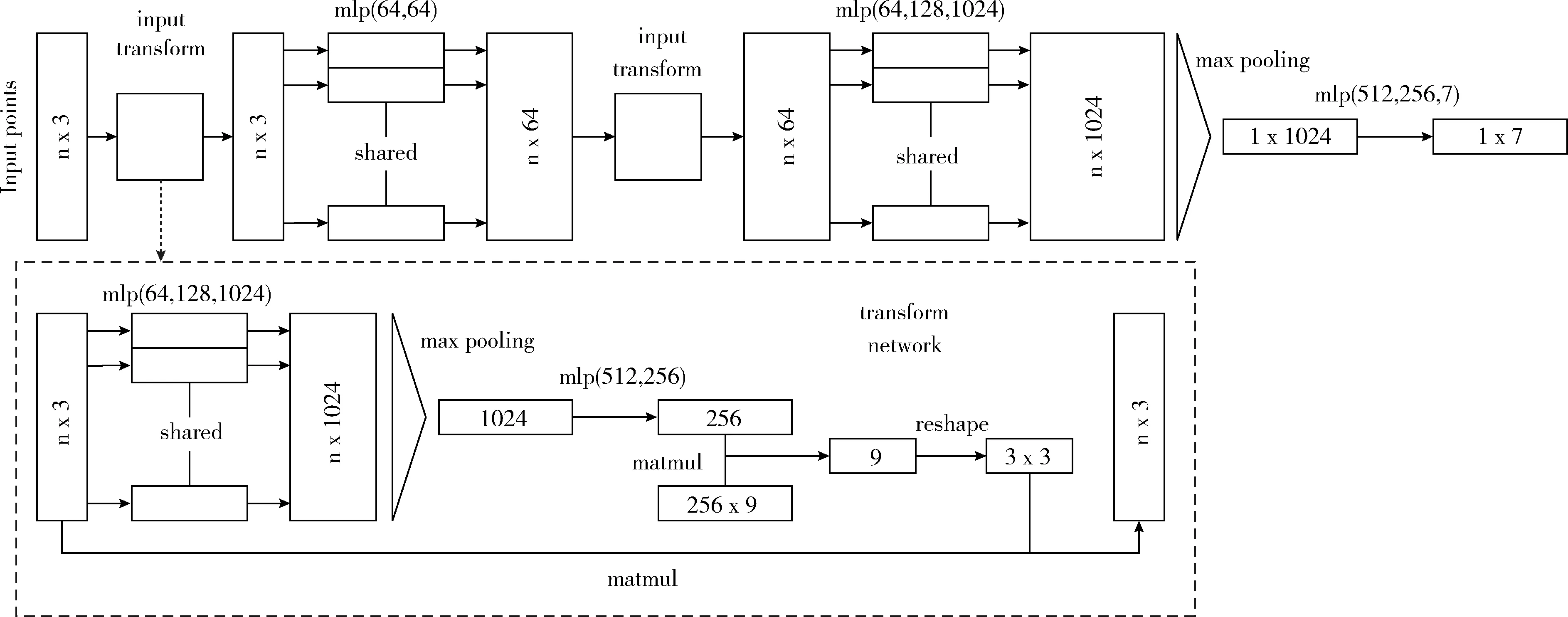
圖3 改進的Pointnet網絡結構
使用二維圖像分類的結果作為最終的分類結果,使用點云檢測的結果作為障礙物檢測位置和大小的結果。
2 實驗分析
實驗使用KITTI數據集,數據集包括了8個類別,分別是:car,van,truck,pedestrian,person sitting,cyclist,tram,others。室外街道場景中最常見的運動障礙物為人、車和自行車,為了簡化數據集,對數據集進行預處理,將類別重新劃分成3類:car(包括了car、van、truck、tram),pedestrian(包括了pedestrian、person sitting),cyclist。因為測試數據沒有標簽,無法進行測評,因此重新劃分數據集。訓練數據集中一共有7480份圖片和雷達數據,將1/3劃分為測試集,其余的為訓練集和驗證集。劃分后訓練數據有4488份圖像和雷達數據,驗證數據有498份圖像和雷達數據,測試數據有2494份圖像和雷達數據。
使用的二維障礙物檢測網絡為Yolov3檢測網絡,檢測的類別分別有car,pedestrian和cyclist這3個類別。
實驗主要探究了二維檢測與三維檢測之間的關系以及三維檢測的效果。本文通過擴張二維檢測網絡輸出包圍框的大小,探究二維包圍框擴張比例對檢測結果的影響,分別設置擴張比例為5%,10%,15%,20%,30%,40%,50%,60%,70%,80%,90%,100%進行實驗,通過對比不同二維包圍框下三維包圍框檢測效果,進行分析。
圖4為使用Yolov3檢測的二維結果和使用提取點云檢測的三維結果。從3類檢測的總體結果來看,通過擴張二維包圍框在Pointnet網絡中進行檢測,檢測的精度會得到一定的提升。car,pedestrian和cyclist類型的三維檢測結果在擴張比例分別在10%,5%,50%的時候效果最好,提升約為2%,1%,15%。總體趨勢都有提升,說明適當的增加提取點的數量,可以增加三維檢測的結果,但是隨著擴張的提升,三維的檢測結果都會下降,說明提取的雜點過多,會導致三維檢測結果下降。最終car,pedestrian,cyclist三維檢測的最高AP值分別為64.34,42.61,15.5,mAP為40.82。
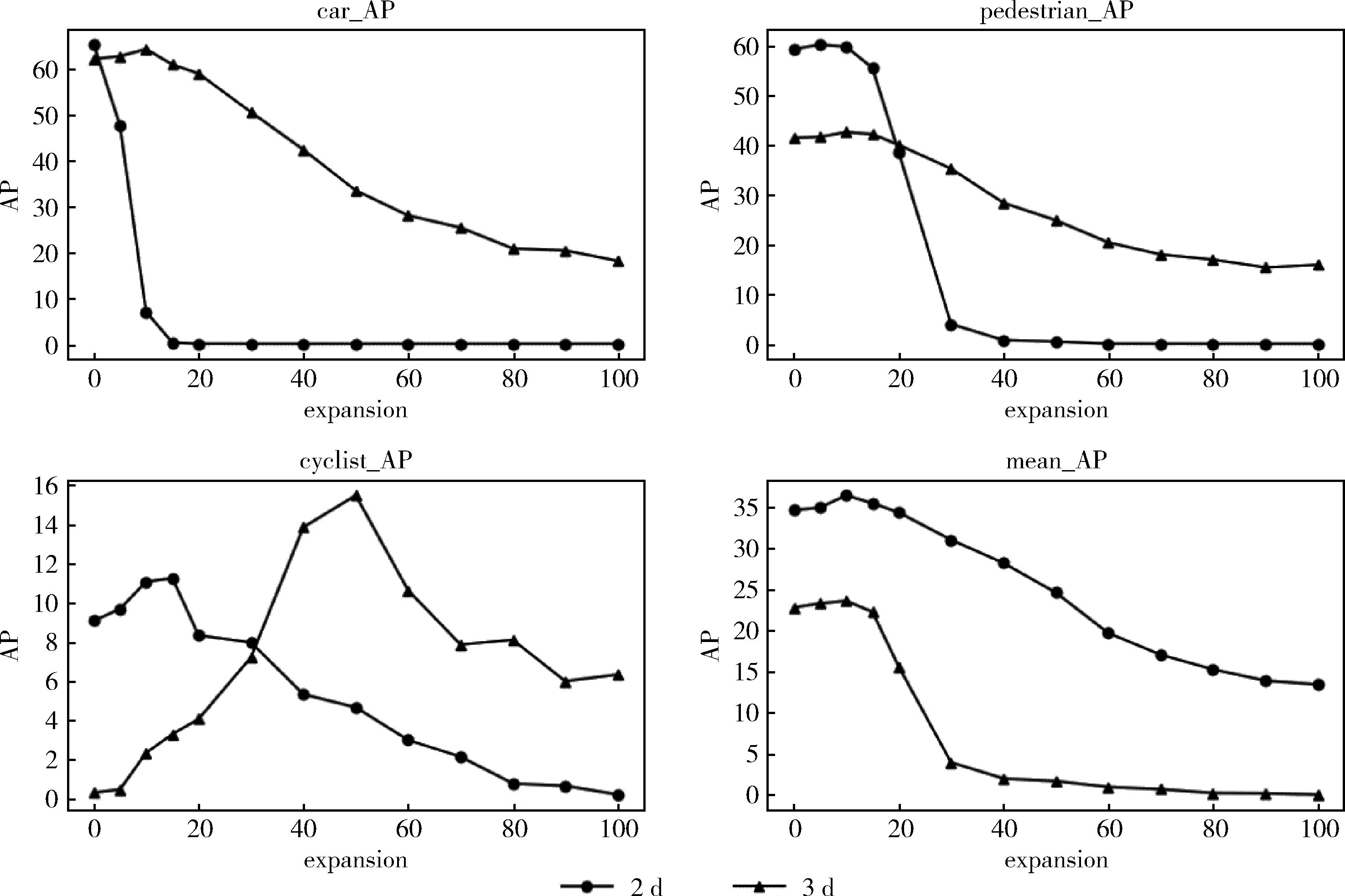
圖4 擴張二維框的二維和三維檢測結果左上:car類型的AP;右上:pedestrian類型的AP左下:cyclist類型的AP;右下:檢測的mAP
檢測可視化結果如圖5所示,第一、二排為街道車輛的檢測結果,第三、四排為行人的檢測結果,第五、六排為人騎車的檢測結果。第一、三、五排為使用Yolov3檢測的結果,第二、四、六排為使用本文方法檢測的三維結果。從檢測結果來看,在車輛和人流比較密集的地方可以達到良好的檢測效果,較遠位置的人和車也可以達到良好的檢測效果。

圖5 檢測結果可視化
3 結束語
本文基于平截頭點云網絡,針對二維和三維連接的部分,提出了擴張平截頭點云檢測的方法。該方法在二維檢測包圍框之后增加了比例擴張方法,增加了點云提取的完整性,通過平截頭點云網絡結構完成了障礙物的三維檢測。通過KITTI數據集的實驗對比,該方法通過比例擴張二維包圍框,可以有效地提高道路障礙物檢測的精度。但是,該方法比較依賴二維檢測網絡效果,召回率低的網絡會影響該方法的效果,今后可以從此處進行提高和改進。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
