基于知識圖譜和協同過濾的電影推薦算法研究*
2020-05-04 07:05:34成振華
計算機工程與科學 2020年4期
關鍵詞:用戶
袁 泉,成振華,江 洋
(1.重慶郵電大學通信與信息工程學院,重慶 400065;2.重慶郵電大學通信新技術應用研究中心,重慶 400065;3.重慶信科設計有限公司,重慶 401121)
1 引言
數據冗余是大數據時代的常見問題。協同過濾推薦系統可以過濾冗余的信息,以幫助人們減輕信息過載帶來的負擔。協同過濾推薦算法因為具有較高的準確率而被廣泛應用于電影、音樂和電子商務等領域。算法的主要依據是假設用戶行為習慣相似則他們對相似物品的喜好也相似[1]。例如2個用戶在觀影偏好上具有相似性,則可以向他們推薦對方未看過的電影。協同過濾推薦算法主要基于用戶評級確定用戶喜好,用戶評級的數據完整性與真實性直接影響推薦的準確率。在實際應用中,協同過濾推薦受到數據稀疏性影響,即用戶數量和物品的種類較多,用戶對物品的評分較少,大部分物品沒有用戶的評分記錄,則無法計算相似度,或者計算出的相似度精度不高。近年來研究者們提出各種基于協同過濾的改進算法并且取得了良好的效果。文獻[2]提出采用矩陣填充的辦法來提高評分矩陣密度。文獻[3]提出采用矩陣分解的辦法降低系統對稀疏性的敏感度。上述方法僅利用了用戶對物品評級的信息,忽略了實際中物品之間的屬性關系。文獻[4]提出將內容與協同過濾的推薦算法相結合,在新聞推薦中表現良好。文獻[5]利用知識圖譜分析用戶喜好原因,理解用戶的興趣點,根據興趣點向用戶推薦他們可能喜歡的物品。文獻[6]采用異構網絡數據,增加多個信息源,提升了推薦過程中的參考依據。通過觀察發現,物品在嵌入知識圖譜時2個物品之間可能具有多種關系。例如《終結者》系列電影之間存在著導演、編劇、主演等多個相似關系。基于TransE(Translating Embedding)算法[7]的知識圖譜表示模型在計算相似度時只能處理實體間簡單的單個關系,并不能真實地反映電影之間的多個關系。TransHR(Translating embedding for Hyper-Relational data)模型[8]將電影間的關系嵌入到關系空間中,可以保留電影間的多關系向量。但是,該算法在表示多關系時增加了時間與空間復雜度。
本文主要貢獻如下所示:
(1)提出構建電影領域知識圖譜彌補協同過濾推薦算法受到的數據稀疏性干擾問題。
(2)改進了知識圖譜算法TransHR,用其取代TransE算法進行知識圖譜構建,提升了計算出的電影間的相似度準確率。
(3)將知識圖譜相似度與基于用戶評分的物品相似度融合,結合SVD分解,提升推薦性能。
2 相關理論
2.1 協同過濾推薦算法
電影推薦中可以使用基于物品的協同過濾ICF(Item Collaborative Filtering),它以用戶傾向于喜歡類似的電影為假設,將用戶對物品的評分記為1個向量,利用評分向量計算物品間的相似度,推測用戶最有可能喜歡的物品。其總體分為3個步驟[9]:
(1)構建評分矩陣。
以通過用戶對某一物品進行打分等方式收集用戶的觀影偏好,用戶評分是算法的數據基礎。假設系統中有m個用戶和n個物品,用U={U1,U2,…,Um}表示用戶集合,用I={I1,I2,…,In}表示物品集合。則用戶Ux對物品Iy的評分為Sx,y,用矩陣Rm×n表示如式(1)所示:
(1)
(2)計算物品相似度。
物品向量的相似度可以用余弦相似度作為評價標準。將用戶對某個物品的評分當成1個m維向量,則某個物品Ii的評分向量為Ii={S1,i,S2,i,…,Sm,i},物品Ij的評分向量為Ij={S1,j,S2,j,…,Sm,j},計算Ii與Ij的余弦相似度:
(2)
其中,Ui和Uj分別表示對電影Ii和電影Ij評分的用戶集合,Ui,j表示同時對電影Ii和電影Ij評分的用戶集合。式(2)的取值為[0,1]。
余弦相似度在實際中未能考慮用戶評分的差異。例如,有些用戶給電影評分普遍評分較高,有些用戶則普遍給出較低分數。這樣用戶對于同樣評分的電影的喜好實際上并不相同。因此,采用修正的余弦相似度,公式如下所示:
(3)
(3)近鄰選擇。
近鄰選擇算法有K近鄰選擇和閾值法2種,其中K近鄰選擇算法是將相似度進行排序從而篩選出前K個最相似的物品進行推薦。閾值法是設置閾值T,將相似度高于閾值T的物品列入推薦列表。本文采用K近鄰算法作為決策的參考依據。
2.2 知識圖譜介紹
知識圖譜是谷歌在2012年提出的,最初是為了提高檢索的性能。知識圖譜將知識信息嵌入到1個低維的圖譜當中從而將知識用向量表示,利用知識向量可以進行實體相似度的計算。知識圖譜的另一個作用是關系預測。知識圖譜可以根據已有的關系數據集快速推斷還未標注的實體間的關系,使得相似度計算的結果更加準確。大量的知識庫為知識圖譜的研究提供了豐富的數據集,常見的有FreeBase[10]、YOGA[11]、Wikidata[12]和DBpedia[13]等。
知識表示的過程是將零散知識嵌入到知識圖譜中形成知識向量。知識表示模型主要分為神經網絡模型、張量模型和翻譯模型。文獻[14]引入神經網絡非線性模型刻畫了實體相關性,但是該模型的計算開銷較大。文獻[15]介紹了將不同維度中的實體統一在一起的思想,描述了實體之間的關系,稱為張量模型。Bordes等[7]受到平移不變性的啟發提出了翻譯模型TransE。由于基于翻譯模型的知識圖譜計算量小且能有效地表示語義知識庫,因此本文在用戶評分數據稀疏時利用知識圖譜輔助算出實體間相似度,并應用于協同過濾算法中,以彌補數據稀疏問題。TransE在處理實體間只存在單關系時具有良好的效果,但是當實體間存在多個關系時,由于TransE的實體與關系嵌入在同一個平面內,無法準確反映出實體間的多關系模型,導致相似度計算不準確。本文采用改進的翻譯模型TransHR,可以將實體間的多重關系表示出來。
知識圖譜由知識三元組頭實體h、尾實體t和關系向量r組成。翻譯模型TransE將頭向量h通過關系向量r映射于尾實體向量t,如圖1所示。通過設置三者的值使得三者關系為真時有h+r-t≈0,當三者關系不成立時,其值應當很大。
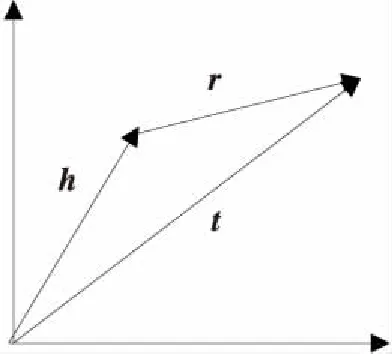
Figure 1 TransE model圖1 TransE模型
實際應用中一對實體間可能具有多重關系,具有多個關系的電影應當具有更高的相似度,在推薦時出現在用戶列表的可能性應當更高。TransHR的原理如圖2所示。
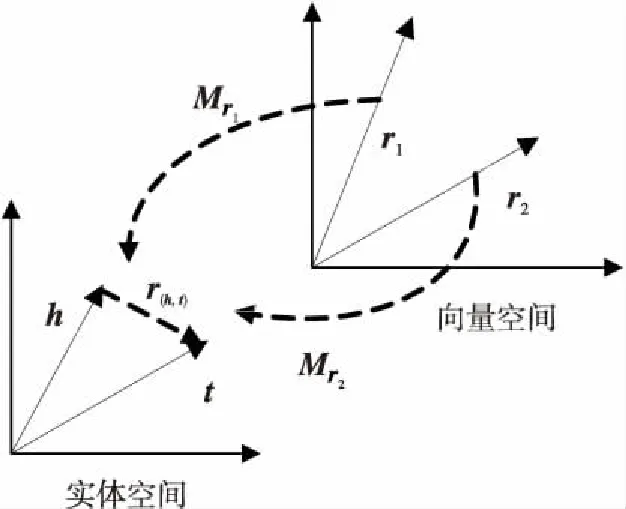
Figure 2 TransHR model圖2 TransHR模型
TransHR將頭尾實體嵌入一個平面內,與TransE不同的是,TransHR將關系向量嵌入在特定的關系空間當中。當2個實體有v個關系時,第i個關系表示為ri,將所有的關系存在單獨的矩陣空間中,記為Mr。則TransHR的關系向量為:
r′(h,t)=riMri,i=1,2,…,v
(4)
通過矩陣空間的關系映射將實體間的多重關系表示在關系矩陣Mri中,則通過映射形成的向量r(h,t)實現了頭尾實體的關系鏈接。則在TransHR模型中頭尾實體映射為:
h+r(h,t)≈t
(5)
TransHR表示出每個實體的同時保留了實體間多重關系,在知識圖譜中計算電影相似度時可以依據多重關系進而加權計算出電影間的相似度。相較于TransE模型,TransHR提高了計算的相似度準確率。由于TransHR將實體間多個關系存儲在矩陣Mri中,使得復雜度提升,因此本文采用對角矩陣Ari代替Mri降低了關系矩陣的復雜度,此時向量映射為:
r(h,t)=riAri,i=1,2,…,v
(6)
3 基于圖譜權重的推薦算法
通過知識圖譜輔助計算出電影間的相似度,與協同過濾推薦算法結合,可以緩解協同過濾算法數據稀疏性問題。基本原理為:通過融合因子將協同過濾算法得出的推薦結果與基于用戶喜好構建的知識圖譜得出的推薦結果相融合,作為最終的推薦結果向用戶推薦。基于物品協同過濾算法實際是從外部向用戶推薦;而基于知識圖譜的語義相似度推薦是基于物品內容向用戶推薦。
本文提出基于TransHR的知識圖譜協同過濾推薦算法TransHR-CF(Translating embedding for Hyper-Relational data Collaborative Filtering),如圖3所示,構建電影知識圖譜,根據知識圖譜計算電影間的語義相似度,形成基于知識圖譜的相似矩陣。根據用戶評分矩陣計算余弦相似度形成相似度矩陣。最終通過設置融合因子將2個矩陣融合。
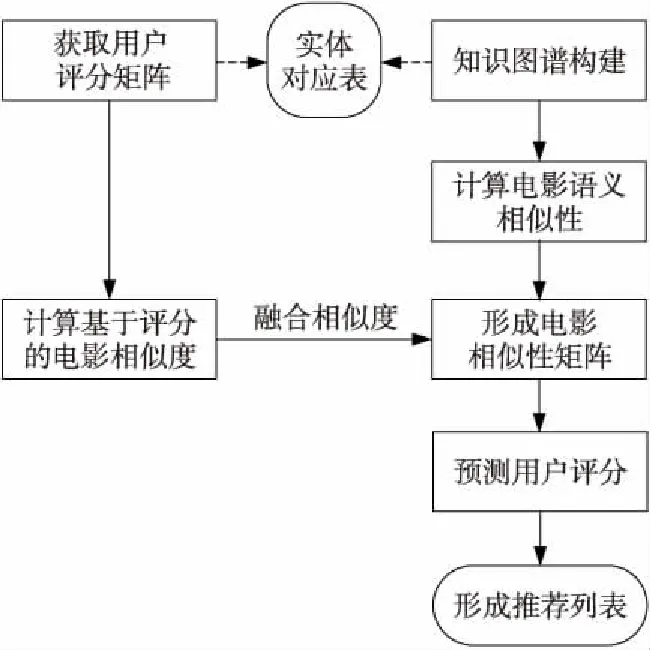
Figure 3 TransHR-CF algorithm圖3 TransHR-CF算法
3.1 構建語義圖譜
在電影領域知識圖譜中,實體主要包括片名、影片類型等。所有這些特征之間的關系形成一張電影領域的知識圖譜。2部電影間往往存在著相同的演員或者導演等相同關系,如《回到未來》和《回到未來2》之間存在著影片類型、導演、主演等多個相同關系,因此在知識圖譜中電影之間相同關系越多,則判定2部電影相似度越高。本文采用改進的TransHR模型,訓練損失函數如式(7)所示:
(7)
其中,γ是邊緣參數,d(·)為歐氏距離,(h,r,t)為正確的三元組表示,在正確三元組中隨機選出1個實體進行替換得到(h′,r′,t′)。如正確三元組為(回到未來,類型,科幻),錯誤三元組在三者中隨機替換1個實體,如(回到未來,類型,驚悚)。
最終通過TransHR模型將電影實體嵌入在一個低維空間中,電影實體間的多重關系存儲在關系矩陣Ari中。該方法使得正確的三元組之間距離很近,錯誤的三元組之間距離很遠。當用戶給某個電影評分時,與之相似度較高的電影也會被判定為用戶可能喜歡的實體類型。
3.2 知識圖譜實體相似度
將物品電影嵌入知識圖譜,物品Ii用向量表示:
Ii=(E1i,E2i,…,Edi)T
(8)
物品被嵌入成為d維向量,其中Epi為對應第p維度的值。構建知識圖譜時采用歐氏距離訓練損失函數,所以在計算物品相似度時也采用歐氏距離:
(9)
利用歐氏距離可以計算2個物品的相似度:
(10)
在TransHR構建的知識圖譜中,2個實體之間的多關系向量被映射到關系空間中,擴展了關系數量。因此,2個物品之間關系越多,則相似度應該越高。定義C1(Ii,Ij) 函數統計知識圖譜中Ii與Ij的直接關系數量,如《回到未來1》與《回到未來2》之間存在導演、主演1、主演2、影片類型等4種相同的屬性關系,則它們的C1(Ii,Ij)=4。同理定義C2(Ii,Ij)為Ii與Ij間隔度為1的關系數量。Ii與Ij在多步關系權重下的相似度為:
simg(Ii,Ij)=
(11)
其中,x<1為權重因子,表征多步關系之間的重要程度。在用戶選擇時更傾向于直接關系,因此直接關系的權重值應當比間接關系的權重值大,設置直接關系權重為x,間接關系權重為x2,從而獲得更好的相似度表示效果,這也符合預期。
根據圖3的流程,按照知識圖譜求得電影相似度后,可以生成1個電影相似性矩陣。如表1所示。
表1所示為電影內部的語義相似度矩陣,其中,aij為2部電影實體間的相似度。在推薦過程中不會向用戶推薦已經選過的電影,因此對角線元素直接設置為0,從而避免向用戶重復推薦已經觀看過的電影。
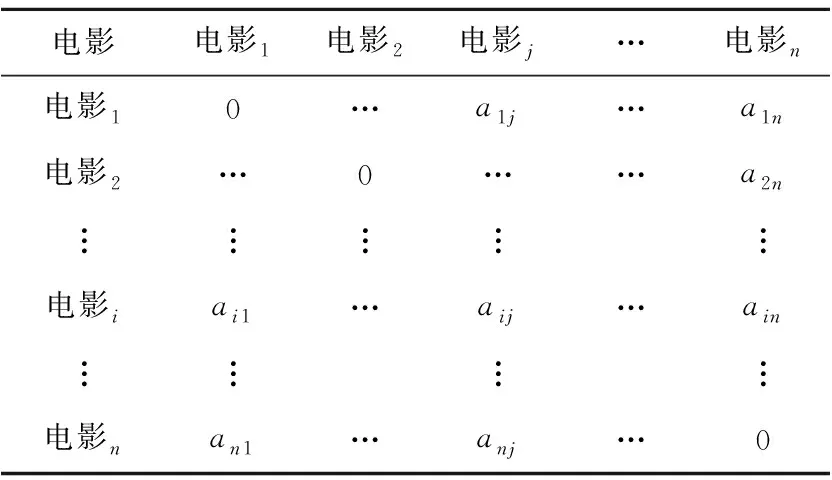
Table 1 Movies similarity matrix表1 電影相似度矩陣
3.3 2種相似度的融合
基于用戶評分矩陣計算出相似電影并且向用戶推薦。但是,協同過濾算法在實際中存在的數據稀疏性問題會導致計算出的電影相似度很低。因此,本文結合知識圖譜計算出的相似度與協同過濾算法計算出的相似度作為推薦依據。步驟如下所示:
(1)將電影領域本身的語義知識通過TransHR模型學習得到電影領域的實體表達,并計算相似度。
(2)通過用戶評分矩陣計算2部電影的余弦相似度,值越大,相似度越高。
(3)將知識圖譜計算出的相似度與協同過濾算法計算出的電影相似度進行匹配融合。
(4)通過最終預測的評分選出K個預測評分最高的結果。
根據式(3)與式(11)得TransHR-CF算法融合后的結果:
sim(Ii,Ij)=simc(Ii,Ij)+simg(Ii,Ij)=
(12)
其中,x<1,式中第1項為協同過濾算法計算得出的相似度,第2項為知識圖譜計算得出的相似度。
3.4 預測用戶評分
預測用戶對電影的評分,根據預測評分可以形成推薦列表。通過引入知識圖譜計算出的電影相似度可以更準確地估算出用戶對未評分電影的評分。用Pui表示用戶Uu對物品Ii的評分。Pui的計算公式如下所示:
(13)
其中,sim(Ii,Ij)是電影Ii與電影Ij的相似度,Su,j表示用戶對電影Ij的評分,N(u) 表示用戶Uu評分過的電影集合,S(i,k)表示前k個與Ii最相似的電影。用戶對電影Ij的評分越高,同時電影Ii與Ij相似度越高,則Pui的值越大。通過計算每一位用戶的未點擊電影的Pui形成TOP-K推薦列表。
基于SVD分解的推薦算法在應用中通過降維預測用戶評分,實現了高質量的推薦。然而該分解方法要求矩陣本身不能是稀疏的,否則需要對評分矩陣進行填充。傳統的SVD分解是填充用戶評分的均值,這種方法會使得預測結果產生偏差。尤其是當矩陣非常稀疏時,其預測結果是非常不準確的。結合知識圖譜計算出電影間相似度,預測越相似的電影越容易獲得相近的評分,從而對矩陣中用戶未評分數據進行填充可以更準確地反映影片實際的得分值。通過填充矩陣計算出用戶未觀看電影的預測分值,向用戶推薦預測分值最高的影片。
本文采用知識圖譜輔助計算相似度從而預測用戶評分的辦法填充用戶評分矩陣,結合矩陣分解為用戶形成推薦列表。SVD分解如式(14)所示:
Mm×n=UΣVT
(14)
其中,Mm×n是用戶評分矩陣;U是m×m階酉矩陣;Σ是m×n階對角陣,對角線的值為Mm×n的特征值;VT是n×n階酉矩陣。通過SVD分解可以實現數據降維,緩解稀疏性問題。
4 實驗分析
4.1 數據集
本節對提出的TransHR-CF算法進行實驗驗證,實驗數據集采用MovieLens數據集的數據。其中用戶記錄有943個,電影數量有1 682部,平均每個用戶評價了100多部電影,共有100 000多條評論數,評分在[1,5]。
引用TMDB數據集構建知識圖譜數據集,TMDB作為一個影視數據社區有超過15萬的使用者,TMDB的數據集可以免費爬取,方便實驗驗證。通過知識抽取最終得到了電影名、演員、電影種類等在內的11 619個實體,保留了導演關系、編劇關系等在內的25 232個關系。由于一部電影參演人數較多,本文將每部電影演員的實體數量控制為3個,目的是降低知識圖譜的構建復雜度。通過影視數據集構建基于TransHR的知識圖譜,構建過程如圖4所示。
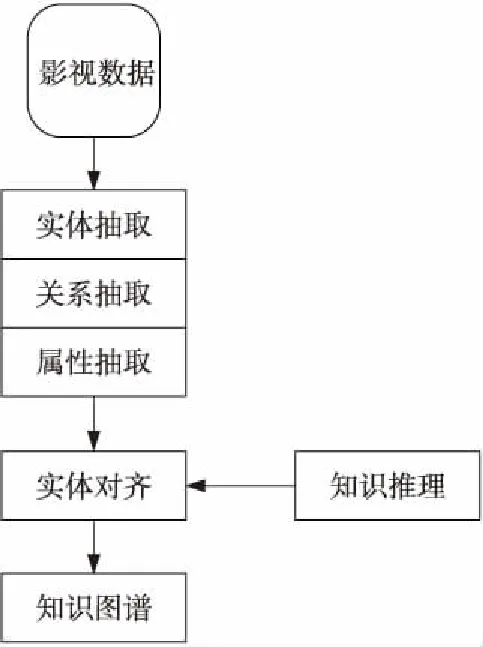
Figure 4 Construction process of knowledge graph圖4 知識圖譜構建過程
4.2 評價指標
推薦系統中常用的結果分析指標主要有3個:準確率、召回率、平均絕對誤差(MAE)。參數含義如表2所示。
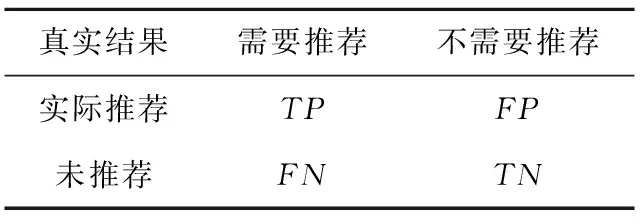
Table 2 Parameters表2 參數
召回率:
(15)
準確率:
(16)
召回率給出了推薦給用戶的電影與用戶所有喜歡的電影的比例。準確率反映了用戶的喜好是否被正確預測,即正確向用戶推薦喜歡的電影的比例。
平均絕對誤差:
(17)
平均絕對誤差反映實際預測誤差的大小。其中|M|表示預測項目集合的大小,fi表示物品的真實評分值,yi表示填充的預測值。MAE越小說明推薦越準確。
4.3 融合因子的設定
為了取得最佳推薦效果,本文提出將基于物品評分的相似度與知識圖譜相似度通過融合因子x融合,x取值從0到1遞增,每次步長0.1,做11次實驗,驗證召回率和準確率。每次實驗做10次并取平均值。結果如圖5和圖6所示。
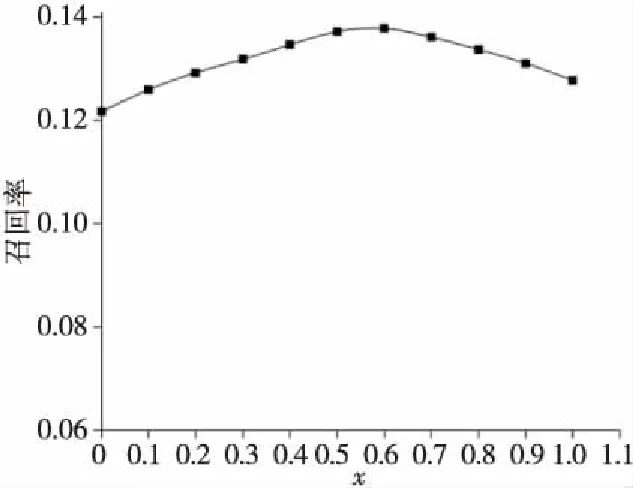
Figure 5 Recall result圖5 召回率結果
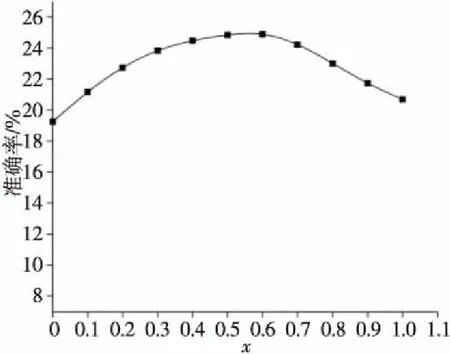
Figure 6 Precision result圖6 準確率結果
從圖5和圖6可以看出,隨著融合因子x的增大,召回率和準確率都有所改善,在0.6時性能最好。當x為0時,表示相似度完全由用戶評分矩陣決定。
4.4 算法比較
與傳統協同過濾算法和基于TransE翻譯模型的協同過濾算法進行實驗對比。此處選取使召回率和準確率最高的融合因子x=0.6,驗證不同近鄰數下的召回率和準確率。近鄰數K分別選擇50,70,100,120實驗10次并取平均值。由圖7和圖8可以看出,本文算法在召回率和準確率指標上都有提升。說明利用了影視實體之間的關系計算影視相似度更加準確。
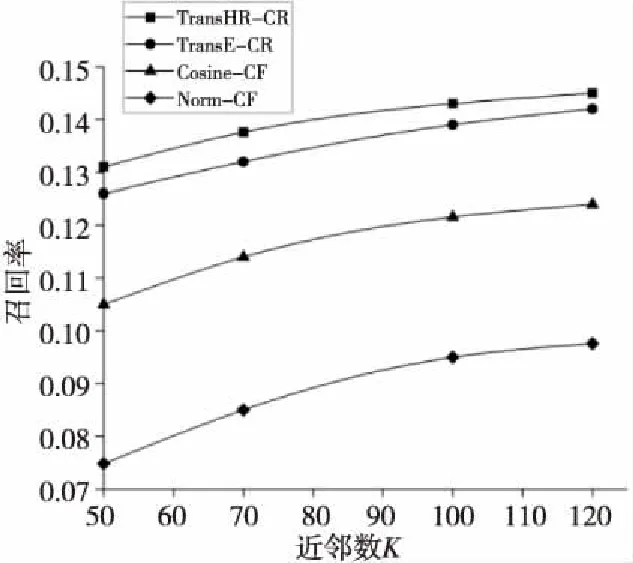
Figure 7 Recall under different neighbor numbers圖7 不同近鄰數下的召回率
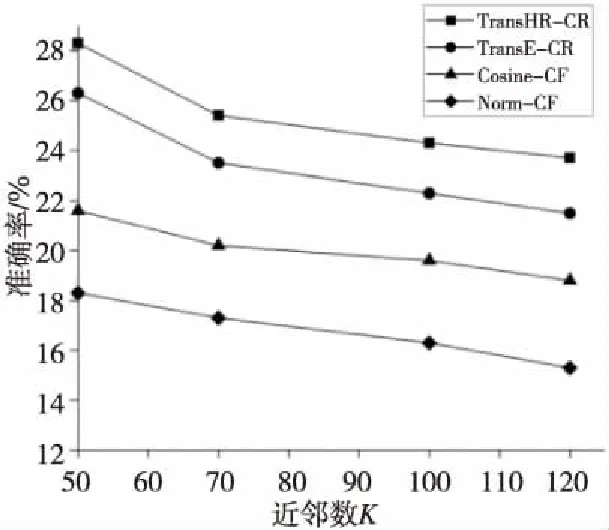
Figure 8 Accuracy under different neighbor numbers圖8 不同近鄰數下的準確率
與基于傳統知識圖譜的協同過濾算法相比,當近鄰數為100時,基于TransHR模型的協同過濾算法在召回率上提升了約5%,準確率提升了約10%,彌補了協同過濾算法的不足以及TransE嵌入過程中的精度不高問題。這說明本文算法的有效性。
為了進一步驗證本文算法的準確度,結合矩陣分解比較了MAE值。將式(13)計算出的預測評分填充矩陣,與基于TransE的知識圖譜計算出的用戶評分和基于用戶均值填充的矩陣,做SVD比較。根據式(13)選取知識圖譜中K個與預測電影最相似的電影時,推薦性能會隨著近鄰數K的不同而不同。分別取近鄰數K為10,15,20,30,驗證MAE值,結果如圖9所示。
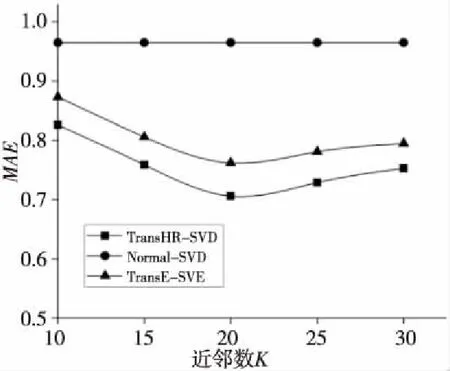
Figure 9 MAE under different neighbor numbers圖9 不同近鄰數K的MAE值
傳統SVD分解采用均值填充的辦法,與知識圖譜中的近鄰數K值無關,因此不會隨K值變化而變化。基于TransE與TransHR的矩陣分解的MAE值在近鄰數取20時效果最好,其中基于TransHR相似度融合的SVD分解推薦優于傳統SVD與基于TransE的推薦。這說明了本文利用TransHR進行相似度融合的優越性。
5 結束語
本文改進了基于知識圖譜的協同過濾推薦算法中使用的表示學習算法,在影視推薦過程中更充分地考慮了影視作品間的多重關系屬性。通過將電影間的多關系嵌入在一個單獨的關系矩陣中,使得TransHR模型可以構建多關系模型,從而改進了電影間的語義相似度,優化了推薦結果。結合SVD分解的推薦結果也比傳統的SVD分解推薦結果更好。本文采用的TransHR模型在推理和表示過程中只能表示出單步相鄰的電影實體,不能推理出電影實體之間存在的多步關系。今后將嘗試引入多步關系推理算法挖掘更多電影信息用于相似度計算。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
