化學計量學方法在脂質組學數據解析中的應用
2020-05-08 13:40:46覃佐劍
分析測試學報 2020年3期
覃佐劍,謝 亞,魏 芳,陳 洪
(中國農業科學院油料作物研究所,農業農村部油料加工重點實驗室(武漢),脂質化學與營養 重點實驗室(湖北),湖北 武漢 430062)
脂質組學研究中,一方面,由于樣本中不同的脂質種類濃度通常呈數量級級別差異且雜質干擾嚴重,研究者需根據樣本特點,采取有效的脂質樣本前處理方法(如液液萃取、固相萃取等),將待測脂質從生物樣本提取出來[7-8],并針對不同類型樣本,選擇合適的質譜檢測技術(如直接進樣技術、色譜-質譜聯用技術),優化色譜洗脫條件、質譜離子化方式和數據采集模式(如產物離子掃描、中性丟失掃描、多反應監測等),以獲得高質量的原始數據,為脂質組學數據解析奠定基礎。另一方面,采用合適的化學計量學方法和軟件包來解析脂質信號,是獲得準確分析結果的重要保證。在此基礎上,結合“脂質代謝物和代謝途徑研究策略”(Lipid metabolites and pathways strategy,LipidMAPS)[9]、格拉茨理工大學脂質數據庫(LipidHome)[10]、人類代謝物數據庫(Human metabolome database,HMDB)[11]、加州大學戴維斯分校脂質計算數據庫(LipidBlast)[12]、京東大學基因及基因組百科全書(Kyoto encyclopedia of genes and genomes,KEGG)[13]、美國斯坦福研究院脂質實驗數據庫(MetCyc)[14]等多種脂質結構和代謝通路數據庫,可實現脂質的定性定量分析和代謝通路研究。針對脂質組學復雜數據的處理問題,不同研究團隊已經開發出了多種集成化學計量學算法的脂質組學數據分析軟件和方法包,如XCMS[15]、MZmine[16]、OpenMS[17]、LipidDataAnalyzer[18]、LOBSTAHS[19]、LipidHunter[20]等。這些算法和工具包的使用,在一定程度上降低了數據解析的難度,提高了脂質組學數據處理的能力。
脂質組學數據的預處理和統計分析是降低數據復雜度、提取特征脂質信號,實現脂質定性定量、挖掘脂質生物標記物和樣本生物學意義的關鍵步驟。研究表明,化學計量學在脂質組學數據的基線校正與背景扣除、信號峰識別、保留時間校正、同位素分布解析等領域得到了廣泛應用[15,18,20-24]。針對脂質組學復雜數據的解析問題,研究人員已建立了如小波變換[25]、多項式擬合[26]、非負最小二乘法[27]、去卷積算法[28]、機器學習[29]等大量的化學計量學算法。同時,隨著新型多維高通量儀器的使用,脂質數據更為復雜,分析難度進一步增大,新的化學計量學方法和數據處理策略成為研究人員關注的熱點。化學計量學在脂質組學數據分析中的應用主要分為背景及基線校正(Baseline correction and background noise deduction)、信號峰識別(Signal peak detection)、保留時間校正(Retention time alignment)、同位素分布解析(Isotope distribution resolving)和統計學分析(Statistical analysis) 5個部分(圖1)。本文就近年來化學計量學在脂質組學數據解析中的應用進行了綜述。
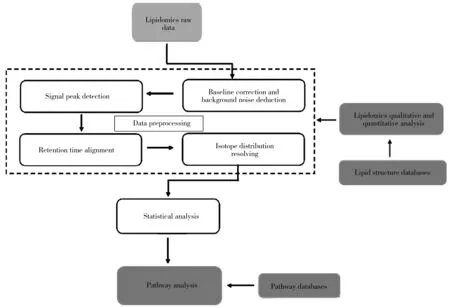
圖1 脂質組學數據分析流程
Fig.1 Workflow of lipidomics data processing
1 色譜基線校正與背景噪聲扣除
在脂質組學原始數據采集的過程中,因為固定相的性質差異和流動相化學組分的改變,經常會產生基線漂移和背景噪聲,這些不穩定因素會嚴重干擾數據的后續分析。因此,有效的基線校正和背景扣除對于脂質數據的準確分析,具有十分重要的意義。研究表明,基于化學計量學的基線校正和噪聲扣除算法,能夠有效地提高數據處理的自動化程度和定性定量的準確性[26,30-36]。
對于色譜背景頻率基線呈常數的情況,可以應用空白對照譜圖進行簡單校正,但通常色譜背景由于程序升溫或者流動相梯度等因素的改變,大多呈現非線性變化,因此應用該方法會產生較大偏差。針對非線性變化的復雜背景基線校正,Windig等[30]開發了基于均值扣除的成分檢測算法(Component detection algorithm,CODA),該算法先對色譜峰背景進行均值計算,自動扣除低于均值的噪聲信號,再通過引入相似系數對處理結果進行驗證篩選,實現背景噪聲的扣除和基線校正。但該方法準確度不高,難以捕捉高度相關樣品的細微差別。改進的CODA算法,先通過標準計算自建模交互技術的偽秩,確定信號的連續性,再依據實際信號與篩選信號的峰寬相似度進行噪聲過濾和背景校正。該法提高了對重復樣本的處理能力,但對于信號強度接近背景噪聲的組分信號,依然不能進行有效處理[37]。另一類是基于多項式擬合的基線校正方法。簡單的多項式擬合并不能解決復雜的基線漂移問題,中山大學甘峰團隊[26]結合遞歸法提出了改進的多項式擬合法,該法首先應用多項式擬合基線噪聲對未擬合的部分自動生成閾值,然后通過迭代算法重復優化預測模型,最終實現較為準確的基線校正和背景噪聲過濾。經比較分析,可對正常信號實現準確識別,在針對包含重疊峰、拖尾峰等復雜的色譜信號時,也有較好的效果。小波變換算法在處理以時間和頻率為窗口的色譜信號方面具有較大的優勢,被廣泛應用于色譜的噪聲抑制、色譜信號識別、背景校正等[38]。經典的小波變換算法,過于依賴濾波器和參數的手動選擇,并不適用于復雜數據的快速處理。Liu等[39]在經典小波變換的基礎上,提出最小均方(Least mean square,LMS)的自適應小波變換。該方法運用算法實現濾波器的自動選擇,對多種色譜信號均具有較好的兼容性,有效地解決了因小波變換濾波器選擇導致的分析結果不穩定的問題。Bertinetto等[40]提出了基于迭代擬合的連續小波變換(Continuous wavelet transform,CWT)的基線自動識別算法,可自動選擇和擬合具有代表性的典型數據點,實現大量圖譜的快速處理。與一般的小波變換對比表明,該方法解決了參數設置復雜和耗時長的問題,可實現背景基線的快速準確識別,已用于人類卵巢癌細胞樣本中磷脂酰膽堿(Phosphatidylcholine,PC)、磷脂酰乙醇胺(Phosphatidyl ethanolamine,PE)、鞘磷脂(Sphingomyelin,SM)等脂質代謝物的研究分析[41]。
此外,針對高分辨率儀器產生的復雜數據基線校準和背景扣除問題,研究者提出了一些基線校正和背景扣除的新方法。如Liu等[42]為解決背景噪聲對待測組分的干擾,開發了基于雙邊指數自動校正算法(Automatic two-side xponential baseline correction algorithm,ATEB),該算法除可有效地校正基線之外,還能通過多次平滑消除異常值的影響。Filgueira等[36]結合多種一維色譜基線漂移校正方法,提出了LC×LC色譜聯用的二維背景校正算法(Orthogonal background correction,OBGC),并將其用于二極管陣列背景信號的解析。
2 信號峰識別
信號峰識別是指從噪聲干擾嚴重的原始數據中提取有效的脂質組分信號。由于生物樣本(如血漿、肝臟等)中的脂質種類多、脂質同分異構和同重現象普遍等內部因素及儀器不穩定、信號響應差異大等系統因素,使得原始數據中假峰、重疊峰等普遍存在。因此,復雜樣本中脂質組分信號的準確識別已成為數據解析的一大難點。基于化學計量學的信號自動識別算法,在復雜脂質信號識別處理方面已取得了重要進展[43-50]。
基于一維質譜的脂質組學分析方法,能夠根據分子極性差異實現不同脂類的快速高通量分析。對于一維的質譜信號解析算法,主要有局部最大值(Local maximum)、遞歸閾值(Recursive threshold)、信噪比過濾(Signal noise ratio filtering,SNR)、連續小波變換(Continuous wavelet transform,CWT)等[43]。局部最大值法通過檢測原始數據中的局部最大值,來識別組分的質譜信號,該法簡單直接,已被安裝在LIMSA[44]、MZmine[16]、mMass3[45]等多個軟件工具中。遞歸閾值法類似于局部最大值法,前者適合于不需要平滑處理的數據,而后者對在連續掃描下采集的原始數據處理效果更好[16]。但這兩種方法對低豐度組分信號識別準確度不高。SNR閾值過濾法是通過預先設定的閾值來對一定信噪比強度的峰進行識別篩選,但在識別較弱的脂質信號時,需調整相關閾值。該法在一定程度上解決了低豐度信號的識別問題,并已被應用于腦脊液樣本的研究以發現與神經類疾病相關的脂類生物標記物[46]。與SNR閾值過濾法不同,Lange等[47]提出應用CWT算法來解決質譜信號的解析問題,其先將譜圖分段處理,然后在確定的分段尺度下利用CWT來檢測峰值并估計峰值參數,實現信號識別。該法適用于噪聲信號復雜的樣本數據,但需選擇合適的分段尺度才能達到理想的識別效果,分段處理的不同會導致結果有較大差異。Du等[48]在CWT算法基礎上結合信號峰形參數,開發了2D-CWT信號峰自動識別算法,先將小波變換到小波空間中,再利用小波系數中附加的峰形參數進行優化處理,這樣可以大大提高信號的有效信噪比,也可實現低豐度信號的有效檢測。對一維的質譜數據進行解析時,基于以上方法,能夠對峰形好、豐度高的組分信號進行有效的處理,但對于低信噪比的信號需手動優化參數。而對于重疊嚴重的復雜脂質信號識別問題,還需借助多維的分析技術和算法來實現準確的解析。
二維色譜-質譜聯用脂質分析技術,結合了色譜的分離能力和質譜的高選擇性,在復雜脂質的有效分離和高通量分析上具有獨特優勢,已成為脂質組學研究的主要手段之一。針對二維技術的復雜信號分析,Hastings等[49]基于保留時間(Retention time,RT)和質譜質荷比(m/z)構建了數據對矢量化峰值檢測算法,通過色譜和質譜信號的一一對應,來有效避免噪聲,實現組分信號的準確識別。Andreev等[50]開發了噪聲過濾扣除算法(Matched filtration with experimental noise determination,MEND)來解決LC-MS的信號解析問題。Zhang等[51]開發了基于降維的PeakID算法,用以解決多維信號的處理問題,可實現高維復雜數據的快速分析。Yu等[29]開發了基于機器學習的信號識別策略,該方法先通過對原始數據的自適應分段處理,得到包含特征信號的提取離子譜(Extracted ion chromatograms,EICs),再通過邏輯回歸(Logistic regression)、支持向量機(Support vector machine,SVM)、隨機森林(Random forest,RF)等多種分類模型對EIC進行篩選,最后借助交叉驗證模型處理,即可得到匹配度最好的提取譜圖,用于后續的定性定量分析;該方法對二維及以上的復雜色譜數據處理具有獨特優勢。Collins等[19]基于脂質加合物離子的m/z、RT等多種特性,提出了一種正交識別算法(Orthogonal screening criteria),并將其用于硅藻樣本中脂質、氧化脂質、脂質生物標志物的自動分析,已成功地從海洋硅藻樣本的21 869特征峰中準確鑒定了1 969種核心脂質。
3 色譜保留時間校正
在脂質組學分析研究領域,脂質分子的色譜保留時間與分子極性、脂肪酸酰基鏈長度和不飽和程度密切相關。脂質數據的色譜保留時間校正是實現多樣本平行分析、脂質組分差異判斷的重要依據[52-54]。在實驗操作中,因色譜柱老化、分析物互相反應、檢測器非線性響應等不可控制因素,色譜圖會出現色譜峰漂移現象,干擾脂質組分的分析,這就需要借助保留時間校正對其進行校正。脂質組學研究中,保留時間校正通常有內標校正和保留時間校正兩種策略。
而除了袖子里能放一些小物件外,漢服的胸前也是可以放東西的。古人的著裝要求一般都會把上衣掖在中褲或下裳里(就像現代規范的襯衫要塞在褲子里一樣)。這樣,腰帶與交領結合處就形成了一個三角形口袋。只要這個東西不大、不滑、不細、不硬就可以放在里邊了。由于是交領右衽,所以拿取物品很是容易。我們現在所說的“懷揣”就是指這個地方。
內標校正法即在樣本預處理過程中,向樣本中加入標準濃度的內標參考物,通過參考物的出峰時間和豐度對樣本數據進行校正。脂質色譜出峰時間與不同類別脂質的極性、不飽和度及分子大小密切相關,同類脂質在保留時間維度具有明顯規律,應用內標校正法可實現保留時間的有效校正。但該方法對內標的濃度和純度要求較高,需研究人員依據樣本中目標脂質信息,對內標參考物濃度等進行調整優化,以達到最好的效果,內標校正法適合樣本量較少的脂質分析。該方法已被用于生物樣本中磷脂、鞘脂信號的有效校正和鑒定分析[55-56]。
針對大樣本量的脂質組學分析,運用保留時間校正算法來校正,能夠有效降低數據處理的復雜性,縮短分析時間。色譜保留時間漂移通常包括線性和非線性兩種。針對線性漂移,Nielsen等[57]提出了相關優化翹曲算法(Correlation optimised warping,COW),該算法先將色譜信號分成系列節段,再對每個節段進行線性翹曲校正,最后將校正后的節段重新組合,從而實現保留時間校正;但該方法易造成信號損失,需人為設置節段的長度和調整保留時間漂移相關參數來優化效果。Bylund等[58]在此基礎上,應用更利于時間對齊的協方差作為校正效果函數,并引入了質譜m/z用以校正色譜信號。平行因子分析(Parallel factor analysis,PARAFAC)和主成分分析(Principal component analysis,PCA)對LC-MS信號校正的效果評價表明,該法比原COW算法更具實用性和選擇性。值得注意的是,上述算法均需漂移時間小于鄰近峰之間的保留時間差,才能實現準確有效的校正。
相比于色譜保留時間的線性漂移,因實驗時間間隔差異和分析平臺不同產生的色譜非線性保留時間漂移更為普遍[59]。Smith等[15]開發了基于非線性校準算法的工具包XCMS,該方法在提取離子色譜峰(Extracted ion base-peak chromatogram,EIBPC)的基礎上,選擇峰形完好的樣本序列作為“臨時標準”,再基于每組色譜信號的保留時間中值及其與樣本序列的偏差進行校正,并結合低階多項式的局部回歸擬合算法排除異常值,實現保留時間的校正。Katajamaa等[60]開發了alignToMaster算法用以解決樣本數據保留時間校正問題,該方法可自動識別生成峰序列,并參考鄰近序列峰進行匹配校正,對于未識別的色譜峰,還可根據質譜碎片離子豐度實現自動補齊。但其缺點是校正準確性依賴于參考樣本序列的構建,也需手動優化相關參數來提高校正的準確性。為實現更為準確和快速的非線性保留時間校正,Pluskal等[21]將RANSAC(Random sample consensus)算法應用于保留時間校正,該法可通過迭代來自動預測擬合模型的相關參數和異常值,隨著迭代次數的增加,校正也更準確。集成上述非線性保留時間校正算法的XCMS和MZmine開源方法包,得到了眾多研究者的認可和使用,被廣泛用于靶向(Targeted)和非靶向(Untargeted)脂質組學數據的色譜保留時間校正。Masoodi等[61]應用XCMS成功對疾病細胞的LC-MS數據進行了保留時間校正,實現了復雜調控網絡中的脂類生物活性介質(Lipid mediators)的綜合分析。Cajka等[62]應用XCMS、MZmine等對血漿脂質組學數據進行處理,實現了包括溶血磷脂酰膽堿(Lysophosphatidylcholine,LPC)、磷脂酰膽堿(Phosphatidylcholine,PC)、磷脂酰乙醇胺(Phosphatidylethanolamine,PE)、溶血磷脂酰乙醇胺(Lysophosphatidylethanolamine,LPE)等12類495種脂質的有效校正和鑒定分析。
近年來,研究者們還基于核密度(Kernel model)、線性回歸(Line regression)、自適應多維核函數(Tailored multidimensional kernel function)、分治算法(Divide-and-conquer algorithm)等模型開發了SIMA[63]、BIPACE[64]、PIRTA[65]等軟件包,在逐步提高校正精度的基礎上,實現了色譜保留時間的有效校正。
4 同位素信號解析
在脂質組學的質譜分析中,由于元素同位素的存在,脂質分子會產生穩定的同位素峰。在質譜譜圖上表現為待測分子離子M之后低頻、連續、穩定的信號峰[66-67]。一方面,同位素峰的存在會增加原始譜圖中信號峰數量,產生重疊峰,干擾待測組分的有效識別;另一方面,同位素峰作為天然存在的現象,可從反面驗證待測組分的存在,降低假陽性和假陰性識別率。研究表明,有效的同位素峰識別策略可作為解析復雜脂質組分的重要手段[68-70]。
現已建立的各種同位素信號識別算法,基于數學分離的手段,先利用數據函數模型對信號分布進行理論計算,再與實際同位素峰進行匹配篩選,實現同位素信號解析。相關化學計量學算法主要有多項式[71]、傅立葉變換卷積[72]、動態規整[73]等。基于多項式的經典同位素解析算法,通過不同原子的同位素質量和數目來構建高次多項式,實現分子同位素質量和概率分布的準確計算[70,74],但該方法拓展性較差,對于復雜分子的同位素計算會占用大量計算機資源,如計算分子C112H165N27O36S的所有同位素分布概率,需占用23.63 GB儲存空間;在對大分子多項式系數階乘計算中,還會出現溢出現象,導致同位素計算結果不準確;該方法繁瑣費時,且難以實現生物大分子同位素的精確解析。Rockwood等[72,75]提出了快速預測同位素峰分布的傅立葉卷積算法,利用快速傅立葉轉換(Fast fourier transform,FFT)將復雜理論同位素峰轉換為呈整數等距分布的輪廓同位素峰(Profile mode isotopic variant)。該方法通過犧牲一定數據準確度來大幅減少計算量,解決了同位素信號解析耗時長、占用大量硬件資源的問題。其他研究者也嘗試應用不同的算法來實現同位素信號的快速識別。如Mcilwain等[73]提出了基于動態規整(Dynamic programming)算法構建完整同位素峰的識別算法。Hussong等[25]將小波變換應用于同位素峰信號解析,提出了單尺度同位素小波變換算法(Single scale isotope wavelet transform),通過設置簡單的閾值參數過濾識別同位素信號。Zhu等[76]提出了高分辨率質譜數據同位素快速識別算法(Accurate mass based spectral averaging isotope-pattern filtering,AMSA-IPF),該算法被編寫成R包,用于同位素信號的自動處理。Liebisch等[68]基于同位素校正法,自編程了Excel宏程序,可在1.3 min內實現磷脂、鞘磷脂的同位素信號的快速分析。以上方法在一定程度改善了同位素信號識別準確度不高和耗時長的問題,但對于重疊的同位素信號,大多還不能進行有效的處理。Slawski等[77]將非負最小絕對偏差回歸(Non-negative least absolute deviation regression,NLADR)算法應用于復雜同位素信號的識別,該法使用模擬的同位素模板庫與原始譜圖進行匹配,再應用自適應穩健閾值,對質譜信號進行篩選,進而實現重疊同位素峰的有效識別。與該法類似,Zeng等[78]開發了一種基于最小二乘的高分辨理論同位素分布算法(Least squares spectral resolution,LSSR)的Chrombox D方法包。該方法包先構建脂質加合物離子(如[M+H]+、[M+NH4]+、[M-H]-、[M-H2O]-等)的同位素譜圖庫,再應用該庫對原始數據進行匹配,從而實現重疊同位素信號的快速分析。對雞蛋、牛肝等生物樣本的脂質分析結果顯示,該算法可有效實現甘油酯、甘油磷脂、鞘磷脂等多類脂質的同位素信號識別,并可同時定性定量分析多種脂質組分。
針對不同的分析對象,研究人員需在同位素準確度和處理速度上予以考慮選擇。對于小分子組分的定性定量研究,運用多項式能夠準確預測和識別其同位素分布;對類似于蛋白、DNA等生物大分子的識別,選擇基于傅立葉卷積、動態規整等快速識別算法,構建同位素輪廓譜,效率更高。
研究證明,整合了質荷比、保留時間、豐度、同位素和MS/MS數據庫等多維信息的解析算法和軟件包,在分析復雜脂質數據時準確度更高[18,21,23,46,79-82],表1列出了包含上述數據預處理流程和多維信息的開源數據處理軟件的相關信息。除前文介紹的XCMS和MZmine軟件包外,Hartler等[18]結合m/z、保留時間和同位素信息構建了3D算法,運用JAVA語言開發了脂質數據處理方法包Lipid Data Analyzer (LDA),并成功從C57BL雄鼠原代肝細胞脂滴中準確識別出了磷脂、甘油酯、鞘磷脂等657種信號峰。Tsugawa團隊等[22]先應用RT、m/z等信息實現組分的初步篩選,再應用特有的MS2Dec(MS/MS deconvolution)算法提取到準確特征二級碎片信息用于二次驗證,實現了脂質組分的準確鑒定。該算法已成功用于藻株脂質組學研究,并從藻株樣本中準確鑒定了1 023種脂質成分。此外,中國科學院生物與化學交叉研究中心朱正江團隊[83]基于m/z、碰撞界面CCS(Collision cross-section)、RT、MS/MS譜圖四維信息,開發了LipidIMMS Analyzer脂質數據分析軟件,結合該團隊多維的脂質數據庫,不僅能實現一般的脂質鑒定,還能有效區分生物樣本中的脂質同分異構體。

表1 脂質組學數據分析軟件Table 1 Lipidomics data analysis softwares
“√” indicates that this function is available,“-”indicates that it is uncertain whether this function is available and “×” indicates that it does not have this function. “METLIN ”is the American metabolomics database, “PubChem” is the American small organic molecule database, “MassBank” is the database of Mass Spectrometry Society of Japan(MSSJ), and “Local database”is the software built-in database(“√”表示其有此功能,“-”表示據已有資料不確定是否有此功能,“×”表示無此功能;“METLIN”為美國代謝組學數據庫,“PubChem”為美國有機活性小分子數據庫,“MassBank”日本質譜學會質譜數據庫,“Local Database”為軟件內置本地數據庫)
5 脂質組學數據統計分析
經過基線校正和背景噪聲扣除、信號峰識別、色譜保留時間校正、同位素峰解析等數據預處理步驟,可實現脂質組分的定性定量分析。在此基礎之上的統計學分析,可通過樣本均值差異、總體分布或變量之間的相關性分析來挖掘樣本的生物學意義和發現潛在的生物標記物。脂質組學統計分析主要包括單變量(Univariate significance tests)和多變量(Multivariate significance tests)差異分析。
單變量分析常用于比較簡單樣本的差異顯著性,主要有t檢驗(t-test)、Wilcoxon假設檢驗、方差分析(Analysis of variance,ANOVA)等。t-test系列檢驗主要用于探究兩組樣本數據均值是否存在顯著性差異;Wilcoxon假設檢驗可應用于單樣本,檢測樣本濃度中位數與假設濃度中位數值是否存在區別,也可用于雙樣本,判斷2個樣本間的濃度中位數值差異是否顯著;ANOVA分析類似于t-test檢驗,主要用于兩組以上樣本數據的均值差異比較,該法被廣泛用于脂質組學的數據分析[84-86]。
在脂類研究中,多變量分析的應用更為廣泛,包括主成分分析(Principal component analysis,PCA)、偏最小二乘法判別分析(Partial least squares discriminant analysis,PLS-DA)和多元方差分析(Multivariate analysis of variance,MANOVA)等。PCA分析是通過保留原始數據大部分相關信息的主成分變量來解釋數據的變化。同時,主成分具有正交性,可有效避免數據的重復,再借助得分圖和載荷圖,可直接判斷樣本是否具有組間分類趨勢和數據離群點。Shen等[87]將PCA用于鱸魚、鯽魚和草魚3種魚類內臟的磷脂差異分析。結果表明,PC和PE是3種魚類內臟的主要脂質種類,其中磷脂酰絲氨酸(PS 18∶0/22∶6)、磷脂酰肌醇(PI 18∶0/20∶4)和磷脂酰肌醇(PI 18∶0/20∶5) 3種脂質還可作為魚類物種分化的重要指標。PLS-DA分析是一種常見的樣本分類方法,其將數據分為代表原始數據的矩陣X和代表分類信息的矩陣Y,通過選取矩陣中的典型相關因子來關聯矩陣X和Y(Variables importance on projection,VIP)得分值,從而實現數據的分類。Sato等[88]將PLS-DA用于阿爾茲海默癥患者的血漿磷脂酰絲氨酸(Phosphatidylserine,PS)數據的判別分析,依據VIP得分差異成功區分了阿爾茲海默癥患者和健康對照組的血漿樣本。其分析主要應用于涉及多種測量變量(如:多種脂質的濃度)的多變量因子主要作用和相互作用研究,根據不同的因子水平可實現組間的差異比較,其優點是可在減少無關測量變量數量,降低數據復雜度的條件下,實現樣本數據的差異分析。在實際的脂質組學數據分析中,ANOVA、PCA和PLS-DA分析的結合使用更為普遍,廣泛應用于脂質生物標記物挖掘、脂質的代謝通路研究[89-90]。
此外,一些其它的化學計量學方法也被應用于脂質組學的數據分析中,如隨機森林(RF)、支持向量機(SVM)等。Cutler 等[91]提出了基于分類樹的RF算法,分類樹中的決策方法可應用于脂質組學數據的有效分類,這為脂質組學樣本的分類和差異分析提供了一種新思路。SVM是一種基于核密度函數的非監督機器學習法,該方法先基于訓練數據構造的超平面實現不同類別樣本數據的分離[92]。但是以上兩種方法的實際效果依賴于分類特征的選擇,不同分類特征下,分析結果差異較大。脂質組學數據復雜、研究對象趨于多元,具體的統計分析問題,還需科研人員根據實際需求,結合不同化學計量學方法,靈活選擇處理。
6 前景與展望
脂質組學數據處理具有數據復雜多維、分析流程復雜、分析過程耗時長等特點。目前,在脂質組學的數據處理方面已有較多算法和軟件包,在一定程度上解決了數據處理耗時長、假陽性/假陰性識別等問題,降低了數據處理的難度。但仍然存在以下問題:①對于低濃度、低豐度的脂質信號,目前的算法和方法包仍然難以快速有效地識別。②針對大批量的原始數據,已有軟件包和算法尚不能實現大規模自動化解析。③脂質相關數據庫還不夠完善,目前僅有40%~60%的脂類能夠通過軟件匹配得到有效識別,大量未知的脂類由于缺乏有效的信息,還無法進一步研究。④在脂質樣本差異分析和生物標記物挖掘方面,研究人員需綜合不同統計學方法的優點和不足,才能得到較為準確的結果。隨著新型高維高通量分析儀器在脂質組學中的應用,數據結構將更為復雜,分析難度也會成倍增加。一方面,在現有算法和數據庫進一步完善的基礎上,整合了多種算法、數據庫和統計分析等部分的完整數據自動解析平臺將成為研究者進行數據解析的重要手段。另一方面,新的擬合模型和化學計量學方法如平行因子(Parallel factor analysis,PARAFAC)、多元曲線分率(Multivariate curve resolution alternating least squares,MCR-ALS)等[93-94]在數據解析中的應用,將為低豐度脂質準確定性定量、樣本差異分析和生物標記物挖掘等提供新思路。未來,以化學計量學為手段,借助前沿計算機技術的數據自動化解析策略將推動脂質組學進一步發展。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
