卷積自注意力編碼過濾的強化自動摘要模型
2020-05-09 03:04:22徐如陽曾碧卿韓旭麗
小型微型計算機系統 2020年2期
徐如陽,曾碧卿,韓旭麗,周 武
1(華南師范大學 計算機學院,廣州 510631)2(華南師范大學 軟件學院,廣東 佛山 528225)
1 引 言
文本摘要是應對信息過載的利器,廣泛用于各項自然語言處理任務,例如新聞標題生成和多文檔摘要融合[1]等.文本摘要的目標是從長文本中獲得重要的信息,輸出具有代表性且能保留原文主要思想的文本序列.目前文本摘要面臨的主要挑戰是如何評價和選擇原文中關鍵的信息,如何過濾冗余信息,以及如何生成通順可讀的摘要.
早期的文本摘要技術主要包括手工規則[2]、以及統計機器學習技術[3]、以及語法樹[4]等,這些方法存在3個缺點:1)需要花費大量的人力進行特征標注;2)通用性不足,即生成的摘要通常具有領域局限性;3)不能概括文章的核心思想.隨著大數據與人工智能技術在各個領域的延伸,使用神經網絡的方法已經在文本摘要任務上取得長足的進步.這些方法使用端到端模型對原文進行編碼,然后將其解碼為一個摘要[5].自動文本摘要方法主要有兩種:抽取式(extractive)和生成式(abstractive).抽取式方法采用特定的評分規則和排序方法,從原文本中選取一定數量重要的句子組成摘要,該方法可以確保輸出句子的語法正確,但是抽取的句子之間通常具有語義獨立性,因此不利于讀者理解整篇文章的意圖.與抽取式摘要不同,生成式摘要能夠獲取文本的上下文信息,根據原文的核心思想重構摘要,確保生成的摘要具備語義相關、可讀性強等特點,故該文采用生成式方法完成文本摘要任務.
近年來,基于注意力的序列到序列(sequence to sequence,seq2seq)框架[6]在生成式文本摘要任務上取得了顯著的進展,seq2seq的解碼器可根據編碼器狀態的注意力得分抽取信息[7].seq2seq框架最早應用于機器翻譯任務上,但是自動摘要與機器翻譯任務的主要區別在于原文本與目標輸出之間沒有位置對齊的關系,將seq2seq直接用于文本摘要會導致編碼器的輸出中包含噪聲,影響注意力得分的計算[8],導致生成的摘要出現語義無關,語句不通順的問題,進而會直接影響讀者理解原文本內容,對讀者具有誤導作用.
循環神經網絡(Recurrent Neural Network,RNN)由于具有良好的序列依賴關系提取能力,在文本摘要任務上得到廣泛應用,與基于卷積神經網絡(Convolutional Neural Network,CNN)的模型相比,基于RNN的模型在推理階段(即測試階段)容易出現梯度消失的情況[9].此外,RNN在訓練的過程中下一個時刻編碼的輸出由上一時刻真實輸出的詞嵌入、隱藏狀態及上下文向量計算得到,但是在測試階段,模型并不確定上一時刻生成真實詞匯的詞嵌入,而是根據上一時刻預測的詞作為輸入生成下一個詞,導致錯誤不斷累積,引發曝光偏差(Exposure Bias)[10]的問題.例如表1中是當前廣泛使用的基于RNN的序列到序列模型[11]生成的摘要,該模型生成的摘要不僅存在沒有準確把握原文核心思想的問題,同時也存在句內重復和語句不通順的問題,產生的摘要更是扭曲了事實,這種類型的自動摘要系統在實際場景中幾乎毫無用處.
表1 傳統seq2seq生成摘要案例
Table 1 Generating summarization case of traditional seq2seq

Source:UNK and the China meteorological administration Tuesday signed an agreement here on long-and short-term cooperation in pro-jects involving meteorological satellites and satellite meteorology.Reference:UNK China to cooperate in meteorology.Seq2Seq:weather forecast forecast for major China citys.
針對RNN的缺陷和seq2seq存在的曝光偏差問題,本文在seq2seq的基礎上提出一種基于自注意力卷積門控單元的生成式摘要方法(Convolutional Self-Attention Gated Encoding Model,CSAG),用于更好地提取文本局部特征表示和全局特征表示.為避免部分關鍵信息經過門控機制時被視為非關鍵信息而被過濾的問題,將指針機制應用于CSAG模型,以提升模型捕獲信息的能力,并解決未登錄詞的問題.此外引入強化學習方法[12]用于解決曝光偏差的問題.論文的貢獻主要如下:
1)提出了一種自注意力卷積門控單元的編碼過濾方法,使用疊加的卷積神經網絡架構提取編碼器輸出的局部特征,構成當前時刻的句內局部特征.利用多端自注意力機制可以獲取當前特征表示和其他特征表示之間的關系,使得該模型既能學習n-gram局部特征,又能從多角度、多層次學習全局的特征表示.
2)將自省序列訓練用于基于自注意力卷積門控編碼的自動摘要模型(Reinforced Convolutional Self-Attention Gated Encoding Model,RL-CSAG)訓練之中,將以往工作中使用的最大似然交叉熵損失和策略梯度強化學習的獎勵相結合,并利用不可微的摘要度量指標ROUGE對模型進行優化,從而避免模型出現曝光偏差問題.
3)在Gigaword1http://catalog.ldc.upenn.edu/ldc2012t21數據集上的多組對比實驗結果表明,本文提出的模型具有較好的特征捕獲能力,在ROUGE-1、ROUGE-2、ROUGE-L三個度量指標上分別提升了2.1%、1.8%和1.2%.通過多組新聞標題生成案例研究表明,模型在性能明顯提升的同時,也改善了句內重復和語義無關問題.
2 相關工作
自動文本摘要在壓縮原文同時保留其核心思想,研究人員為解決這項挑戰性的任務提出了很多的方法,主要分為抽取式方法[13-15]和生成式方法兩大類.Rush等[5]以CNN作為編碼器,神經網絡語言模型(Nerual Network Language Model)作為解碼器,并結合注意力機制,在文本摘要任務上取得了重大突破;Chopra等[7]在Rush等[5]基礎上使用RNN作為編碼器并取得了更好的表現;Nallapati等[11]將解碼器用RNN代替形成了完整的RNN seq2seq模型;為解決未登錄詞的問題,Gu等[16]和Zeng等[17]將復制機制引入seq2seq模型,該機制能夠處理未登錄詞的問題,同時也允許使用更小規模的詞匯集;Shen等[18]將句子的長度,句子之間的相似度等信息融入到句子特征向量的計算中,用于構建抽取式自動摘要;Gulcehre等[19]提出了使用軟開關來控制是從原文復制還是由解碼器生成一個詞;Ma等[20]通過提高原文和摘要在表達上的相似性來提升彼此之間的語義相關性;Vaswani等[21]提出了一個完全依賴注意力實現的機器翻譯模型,引入了自注意力機制,該機制可以學習模型中的長期依賴關系.
與RNN相比,CNN不僅可以通過并行計算提高訓練效率,而且可以避免RNN梯度消失問題.最近,Gehring等[22]提出ConvS2S模型,解碼器和編碼器均由多個CNN構建,在語言建模和機器翻譯任務表現優于基于RNN模型的最佳效果.因此CSAG模型在編碼部分融合RNN和CNN,充分利用二者在特征提取任務上各自的優勢,以生成高質量的摘要.
強化學習(Reinforcement Learning,RL)用于優化不可微的語言生成度量指標,能夠緩解曝光偏差問題.Paulus等[12]將策略梯度強化學習應用于生成式摘要模型,可直接使用不可微的摘要評估指標ROUGE作為強化學習的回報.因此該文結合強化學習提出了RL-CSAG,用于增強模型在訓練和測試階段的一致性,并提升語言的流暢性和穩定性.
3 生成式自動摘要模型(CSAG)
生成式摘要模型CSAG是基于注意力機制的RNN seq2seq模型提出的,模型的整體結構如圖1所示.CSAG模型由3個部分組成:1)雙向長短期記憶網絡(Long Short Term Memory,LSTM)編碼器;2)基于疊加卷積神經網絡的多端自注意力門控單元;3)單向LSTM解碼器.模型首先使用雙向LSTM編碼器讀取輸入序列(x1,x2,…,xn)并構建編碼器的狀態表示.其次,為了獲取每個編碼步驟的核心信息,在編碼器輸出的頂部加入一個卷積門控單元,對所有編碼器輸出進行卷積操作.受Vaswani等[21]的啟發,使用多端自注意力機制(self-attention)鼓勵模型從多角度、多層次學習長期依賴關系,獲取編碼器局部-全局的特征表示;在卷積門控單元輸出的頂端,使用單向LSTM作為解碼器.為避免部分關鍵信息不能通過門控單元,導致摘要中關鍵信息缺失的問題,模型在解碼階段引入指針機制[19]來復制原文中子序列,以輔助解碼輸出,并解決未登錄詞的問題.
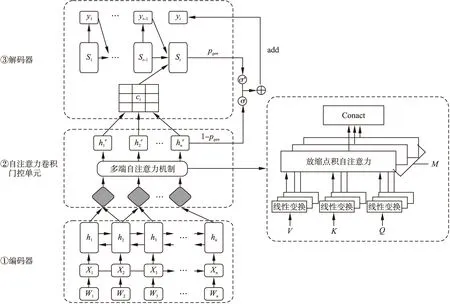
圖1 卷積自注意力門控機制的生成式摘要模型Fig.1 Abstractive summarization model based on convolutional self-attention gated mechanism
3.1 句子編碼器

(1)
(2)
3.2 多端自注意力卷積門控單元
在基于seq2seq的機器翻譯模型中,編碼器用于將輸入句子映射到向量序列,解碼器將向量序列解碼為句子[6].之前研究人員同樣將seq2seq框架應用于文本摘要[5,7,11]任務中,但與機器翻譯不同:1)在文本摘要中除了常見單詞外,輸入句子和輸出摘要之間并沒有對齊的關系;2)文本摘要需要保留句子的重要信息,舍棄不重要的信息,而機器翻譯需要保留輸入輸出文本的所有信息.
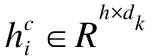
(3)
其中fconv函數表示卷積操作.
長期依賴關系可以幫助模型發現語言中包含一些內部特征,如短語結構和句內關系等.受Vaswani等[21]工作的啟發,在卷積模塊輸出層應用自注意力(Self-Attention)機制,在不增加計算復雜度的情況下鼓勵模型學習長期依賴關系,以捕獲編碼器輸出的全局特征信息.本文采用放縮點積注意力[21](scaled dot-product attention)對卷積模塊的輸出Q和KT執行點積操作,為每個時刻的局部特征表示和全局信息之間建立聯系.考慮到一個放縮點積注意力無法從不同角度、不同層面捕獲編碼狀態的特征,所以模型使用多端注意力機制(Multi-head Attention)充分挖掘特征信息.圖1給出了多端注意力的計算流程,首先在不共享參數的情況下對卷積模塊輸出Q,K,V做線性變換,然后重復M次放縮點積注意力計算,將每層的輸出的結果進行拼接.
(4)
headi=Attention(QW1,KW2,VW3)
(5)
MultiAttention=head1⊕head2…⊕headM
(6)
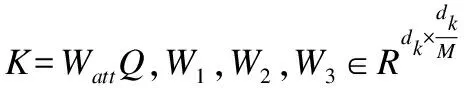
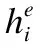
gate=δ(Wg(MutiAttention(Q,K,V))+bg)
(7)
(8)
其中,δ表示sigmoid激活函數,Wg是一個可學習的參數,bg是一個偏置項.
經過自注意力卷積門控單元的處理,CSAG利用卷積神經網絡學習到全文的n-gram的局部特征表示,利用多端自注意力機制可以從多角度和多層次學習輸入文本的長期依賴關系和全局特征信息,使得模型能夠正確理解輸入文本的核心思想,并生成語義相關、可讀性較好的摘要.通過特征融合、過濾,模型會有選擇地刪除和保留某些特征信息,且能有效避免由于注意力滯留造成的句內重復的問題.
3.3 句子解碼器
在多端自注意力卷積門控單元后使用一個帶有注意力機制的單向LSTM作為句子的解碼器,以生成原文本的摘要.

st=LSTM(xt-1,ct-1,st-1)
(9)
(10)
其中,Wd是一個權重矩陣,bd是一個偏差向量.
(11)
其中,We是一個權重矩陣.
對相關性權重做歸一化處理,得到第i個詞的注意力權重,根據每個詞的注意力權重可以得到第t個目標詞的上下文向量:
(12)
(13)
指針機制[23]是一種有效處理未登錄詞的方法,在解碼過程中,pgen作為一個軟開關,控制解碼器從詞匯表vocab中生成一個單詞或從原文拷貝單詞.pgen定義為:
(14)
pvocab(wt)=p(yt|y (15) (16) Teacher forcing算法[24]用于最小化CSAG每個解碼步驟的最大似然損失Lml: (17) 與摘要評估指標ROUGE相比,最小化公式(17)的目標函數通常不會產生最優的效果. 一方面是由于存在曝光偏差[10].在訓練過程中,模型由真實的輸出序列來預測下一個單詞,而在推理過程中,模型根據上一時刻預測的單詞作為輸入,生成下一個單詞.因此,在推理過程中,每一步的誤差會不斷累積,導致生成的摘要質量下降. 另一方面是由于摘要的靈活多樣性.最大似然函數獎勵輸出和參考摘要完全相同的模型,懲罰那些輸出文本與參考摘要不一致的模型,而這些輸出的大多數文本在意義表達上是和參考摘要是一致的.雖然給出多個參考摘要可以緩解這種誤差,但對給定參考摘要的闡述方式還有多種.最小化公式(17)目標函數恰好忽略了摘要靈活性的本質.而ROUGE提供了更靈活的評估方式,讓模型更多的關注語義,而不是詞級別的對應關系. (18) 最后,通過梯度下降算法更新模型的參數. 實驗所用數據集為帶注釋的Gigaword,該數據集曾被Rush等[5]用于文本摘要任務的評估.Gigaword語料庫將新聞文章的第一句話和新聞標題配對產生,即新聞第一句話作為原文本,人工書寫的新聞標題作為參考摘要.利用Rush等發布的腳本(1)http://github.com/facebook/NAMAS構建訓練集和驗證集,該腳本執行多項文本規范化操作,包括詞語切分、字母小寫、將所有的數字用#代替,并將詞頻小于5的詞用UNK標簽標記.Gigaword共有3.8M萬對新聞句子標題對作為訓練集,189K對作為驗證集.在測試階段使用與Rush、Chopra等相同的測試集,該測試集包含2000個句子-標題對.Gigaword數據集統計信息如表2所示. 表2 Gigaword數據集統計信息 數據集屬性訓練驗證測試數量3.8M189K2000句子的平均長度31.431.729.7摘要的平均長度8.38.38.8 自動摘要的評價采用官方ROUGE(1.5.5)作為度量指標.通過計算在參考摘要和候選摘要之間的重疊詞匯單元來衡量生成摘要的質量,例如unigram,bigram,LCS(最長子序列).按照慣例,采用ROUGE-1(unigram),ROUGE-2(bigram),ROUGE-L(LCS)的F1值進行評估.其中,ROUGE-1和ROUGE-2用于衡量生成摘要的信息量,而ROUGE-L用于衡量生成摘要的可讀性. 實驗中使用大小為50k的詞匯表,詞嵌入的維度設置為256,所有的LSTM的隱藏狀態維度設置為512.使用Adam優化器,學習率的初始值設置為α=0.03,動量參數設置為β1=0.9,β2=0.999,=10-8,將Dropout rate設置為0.5.解碼器部分,設置集束搜索(beam search)大小為6.為了加快模型訓練和收斂的速度,將mini-batch的大小設置為64.在卷積自注意力門控單元中,多端注意力的M值設置為8. ABS,ABS+:Rush等[5]首次提出ABS,該模型以CNN作為編碼器,并最先將注意力機制應用于文本摘要任務.ABS+在ABS模型的基礎上加入一些人工規則,ABS+取得了比ABS更好的效果. Feat2s:Nallapati等[11]使用一個完整的基于RNN的seq2seq模型,并通過加入詞性,命名實體識別等規則加強編碼器的特征表示. RAS-Elman:Chopra等[7]將單詞和單詞位置作為輸入,使用卷積編碼器來處理源信息,并用RNN做解碼器進行基于注意力的序列解碼. DRGD:Li等[26]在傳統seq2seq的模型基礎上,結合深度循環生成解碼器學習句子內部的結構,保證生成的摘要具有較高可讀性. SEASS:Zhou等[27]利用編碼器正反向輸出的最后一個狀態構建句子特征表示,結合選擇門控機制控制從編碼器到解碼器的信息流. PCEQ:Guo等[28]改進生成式摘要模型,提出了一種多任務學習方法.結合問題生成和句子語義生成輔助任務,進行突出信息檢測和文檔邏輯推理,并在此基礎上加入了指針覆蓋機制[23]. Pointer:在基于注意力機制的序列到序列模型的基礎上加入指針機制用于解決未登錄詞的問題.該文將Pointer模型作為基線模型. 對比模型及本文提出模型在Gigaword數據集上的實驗結果如表3所示,CSAG模型是本文提出的基于卷積自注意力門控編碼模型,RL-CSAG是加入強化學習后的模型.右上角數字表示模型提出的年份.表3對比模型部分,將在ROUGE-1,ROUGE-2,ROUGE-L上表現最佳的結果加粗顯示. 表3 模型對比實驗結果 模型ROUGE-1ROUGE-2ROUGE-LABS201529.611.326.4ABS+201529.811.927.0Feat2s201632.715.630.6RAS-Elman201635.316.632.6DRGD201736.317.633.6SEASS201736.217.533.6PCEQ201836.017.833.6Pointer34.316.432.0CSAG36.418.233.2RL-CSAG36.818.034.1 本文實現的兩組模型和7個對比模型的實驗結果如表3所示,由表3可知: 1)CSAG模型在性能上優于大多數的對比模型,且在ROUGE-1上對比最佳模型DRGD高出0.1%,在ROUGE-2上對比最佳模型PECQ高出0.4%.加入強化學習之后,模型在ROUGE-1和ROUGE-L指數上得到提升,且這兩個指標均高出對比模型最佳結果0.5%.證明該文提出的模型為生成高質量摘要做出了一定的貢獻. 2)與基線模型Pointer相比,CSAG在3個度量指標上分別高出基線模型2.1、1.8和1.2個百分點,證明CSAG能夠提取出文本中的潛在特征信息,生成更優質的摘要. 3)加入強化學習得到RL-CSAG之后,RL-CSAG模型性能在CSAG基礎上有了進一步的提升,在ROUGE-1、ROUGE-L兩個度量指標上,RL-CSAG分別提升了0.4%和0.9%.在ROUGE-L上的大幅提升,說明基于自省序列訓練強化學習方法能夠幫助模型生成更具可讀性的摘要. 4)從3個評估指標來看,CSAG模型生成的摘要能夠在多個維度上準確領會輸入文本的核心思想,說明該文提出的卷積自注意力門控單元能模擬人類處理信息的方法.先抓住局部重點信息,在局部信息和全局信息之間建立聯系,再從全局層面以多角度不同層面進行歸納,而不是對單詞進行簡單的拼湊,故生成的摘要具有較好的連貫性、流暢性和語義相關性. 為了對實驗結果做進一步分析,該文將RL-CSAG與Pointer模型生成的摘要進行比較,表4中顯示了原文本、參考摘要、模型生成的摘要.從這些案例中可以看出,RL-CSAG可以捕捉到一些與參考摘要相一致的核心信息.例如,案例1生成的摘要“australian fm says dialogue with dprk important”與參考摘要基本一致,但是Pointer只將原文中這件事的場景(“Australia's foreign minister shelve the opening of an embassy in Pyongyang”)給抽取出來,未能真正捕獲文本的核心內容,且產生了扭曲的事實.案例中RL-CSAG將“foreign minister”簡化成“fm”,表明RL-CSAG更好地學習了文本中的潛在信息.案例2中RL-CSAG生成的摘要和參考摘要在語義上高度吻合,而Pointer模型雖然有多個單詞和參考摘要相同,可以在測試中獲得較高的ROUGE評分,但是生成的摘要不僅語句不通順,而且存在嚴重的語法錯誤.通過上述案例的對比分析,說明該文提出RL-CSAG模型具有較好的特征表示捕獲能力,能夠在序列數據中從多角度、不同層次提取更有效、更復雜的潛在信息.因此,RL-CSAG生成的摘要與真實摘要的內容具有較好的一致性.此外RL-CSAG生成的摘要可讀性較好、內容重復度低. 表4 模型生成案例分析 案例1:continued dialogue with the democratic people 's republic of korea is important although australia’s plan to open its embassy in pyongyang has been shelved because of the crisis over the dprk’s nu-clear weapons program,australian foreign minister alexander downer said on friday.參考:dialogue with dprk important says australian foreign ministerPointer:Australia's foreign minister shelve the opening of an embas-sy in Pyongyang.RL-CSAG:australian fm says dialogue with dprk important.案例2:the #### tung blossom festival will kick off saturday with a fun-filled ceremony at the west lake resort in the northern taiwan county of miaoli,a hakka stronghold,the council of hakka affairs-lrb-cha-rrb-announced tuesday.參考:#### tung blossom festival to kick off Saturday.Pointer:tung blossom festival on Saturday at the west lake holiday.RL-CSAG:#### tung blossom festival to kick off in Miaoli. 該文在序列到序列模型的基礎上結合強化學習理論提出卷積多端自注意力編碼過濾模型RL-CSAG,用于生成式自動文本摘要研究.CSAG模仿人工書寫摘要的行為,分階段從不同角度概括上下文信息,生成摘要.利用自省序列訓練緩解曝光偏差問題,提升模型性能.在開源英文數據集Gigaword上實驗結果表明,RL-CSAG在ROUGE度量指標上取得較大提升,同時模型生成的摘要具有較高的語義相關性、可讀性. 實驗主要是基于短文本的摘要生成,未來工作中將嘗試在長文本或多文檔的數據集上評估該文提出的模型,并探索能提升強化學習穩定性的方法.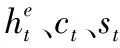
4 強化學習
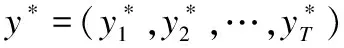
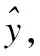
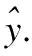
5 實 驗
5.1 數據集
Table 2 Gigaword dataset statistics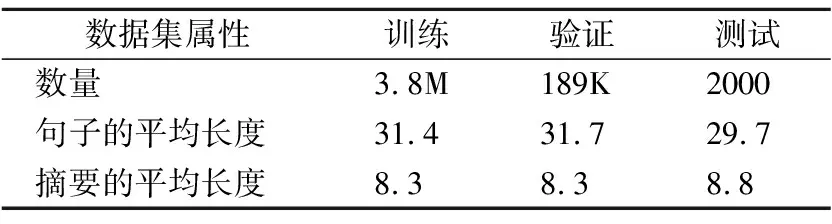
5.2 評價指標
5.3 實驗參數設置
5.4 對比模型
Table 3 Performance comparison of models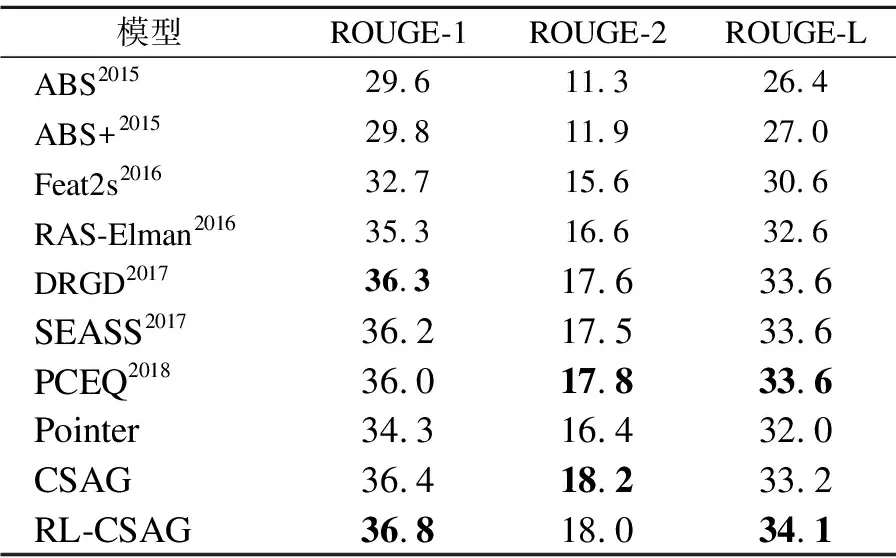
5.5 案例研究
Table 4 Case analysis of generated summarization
6 結 論
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
