一種基于卷積神經(jīng)網(wǎng)絡(luò)的快速說話人識別方法
2020-05-18 07:30:58蔡倩,高勇
無線電工程 2020年6期
蔡 倩,高 勇
(四川大學 電子信息學院,四川 成都 610065)
0 引言
聲紋識別(又稱說話人識別)屬于生物特征識別技術(shù),是一種利用人體固有的生理特征進行個人身份鑒定,對說話人的語音信號進行特征分析和提取,并將目標說話人的語音與集合內(nèi)說話人進行匹配的過程。
說話人識別系統(tǒng)通常由預(yù)處理、特征提取和模式匹配3部分組成。首先,預(yù)處理是語音信號處理中不可或缺的環(huán)節(jié)。發(fā)聲器官物理特性的差異使得產(chǎn)生的語音信號自身物理特性不一,因此不能直接對原始語音信號進行特征分析,要對其進行預(yù)加重、分幀和加窗等預(yù)處理操作。其次,特征選取是識別精度的關(guān)鍵。常用的特征參數(shù)有:梅爾倒譜系數(shù)(Mel-scale Frequency Cepstral-Coefficients,MFCC)[1]、小波系數(shù)、線性預(yù)測倒譜系數(shù)(Linear Prediction Cepstrum Coefficient,LPCC)和i-vector等。MFCC是最常使用的語音特征,提取MFCC用到的Mel三角濾波器組模仿了人的聽覺特性,其在低頻部分的分辨率高。本文采用Gammatone濾波器組[2]更能夠模擬人耳特性,能仿真人耳基底膜的動態(tài)響應(yīng),從而得到更好的說話人個性特征——基于Gammatone濾波器倒譜系數(shù)(Gammatone Frequency Cepstral-Coefficients,GFCC)[3]。由于GFCC不依賴于信號的性質(zhì),又利用了聽覺模型的研究成果。因此,GFCC和基于聲道模型的LPCC相比具有更好的魯棒性。最后,模式匹配是整個說話人識別系統(tǒng)的核心。在說話人識別領(lǐng)域,高斯混合模型(Gaussian Mixture Model,GMM)是一種經(jīng)典有效的識別模型。通過不斷研究,以GMM為基礎(chǔ)的高斯混合模型—通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)成為主流方法。近年來,隨著深度學習研究技術(shù)及成果的不斷涌現(xiàn),神經(jīng)網(wǎng)絡(luò)被成功運用于說話人識別中。在之前的研究中[4],呂亮等人對深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Networks,DNN)進行了文本無關(guān)說話人識別研究。林舒都、邵曦等人[5]利用DNN來提取說話人特征,然后將提取的特征用于說話人模型的建立。在文獻[6-8]中,預(yù)先訓練好的DNN用來提取特征向量,將同一個說話人的特征向量平均化來創(chuàng)建每個說話人的模型,這稱為d-vector系統(tǒng)。文獻[9]提出的卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)用于語音信號的預(yù)處理,沒有將CNN用于模式匹配。文獻[10-11]提出將語音信號的語譜圖作為CNN的輸入,這種思想類似于用CNN實現(xiàn)圖像的分類。
本文利用CNN同時實現(xiàn)說話人內(nèi)在特征的提取和說話人模型的匹配,在CNN的框架構(gòu)成中,網(wǎng)絡(luò)的輸入是GFCC與其差分系數(shù)歸一化得到的統(tǒng)計特征,全連接層輸出作為表征每個說話人的深層次特征向量,最后softmax分類器實現(xiàn)說話人模型的匹配。本文提出的說話人識別系統(tǒng),在保證高識別率的前提下,降低了識別的復(fù)雜度,減少了系統(tǒng)的訓練時間和識別時間,大大提高了識別效率。
1 特征參數(shù)提取
1.1 預(yù)處理
在提取特征參數(shù)之前,先將語音信號進行預(yù)加重和端點檢測等預(yù)處理。
預(yù)加重目的是對語音的高頻部分進行加重處理。發(fā)音時,語音受到輻射通道(口腔、鼻腔等)影響,低頻段的信號能量大,高頻段的語音信號能量明顯較小,所以在對語音信號分析前有必要進行高頻部分的補償,傳遞函數(shù)為(a=0.98):
H(Z)=1-aZ-1。
(1)
語音信號端點檢測技術(shù)的目的是區(qū)分出靜音段和非靜音段。端點檢測可以減少計算量,提高計算精度,同時減少噪聲對說話人識別的影響。傳統(tǒng)的基于短時能量和過零率的端點檢測方法對帶噪語音的檢測性能不夠理想。基于譜熵法的端點檢測[12]比基于短時能量和過零率的方法有更好的性能。本文采用譜熵端點檢測算法除去語音中的靜音段,檢測過程如圖1所示。

圖1 譜熵法端點檢測過程Fig.1 End point detection process of spectral entropy method
1.2 GFCC及其一階、二階差分系數(shù)的提取
Gammatone濾波器是一種基于標準耳蝸結(jié)構(gòu)的濾波器,其時域表達式[13]為:
gi(t)=Atn-1e-2πbitcos(2πfi+φi)U(t),
(2)
式中,A,fi為濾波器的增益和中心頻率;U(t)為階躍函數(shù);φi為偏移相位;n為濾波器的階數(shù);N為濾波器數(shù)目;濾波器的衰減因子bi決定了濾波器對脈沖響應(yīng)的衰減速度,與中心頻率fi的對應(yīng)關(guān)系為:
bi=1.019bEBR(fi),
(3)
式中,bEBR(fi)為等效矩形帶寬,與中心頻率fi的關(guān)系為:
(4)
GFCC參數(shù)的提取過程如圖2所示。
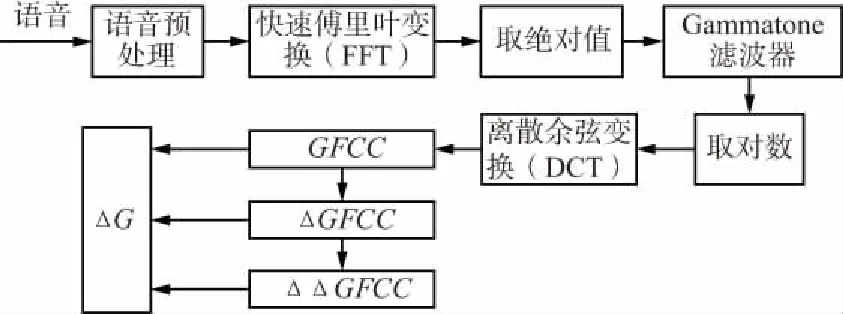
圖2 GFCC及其差分系數(shù)的提取過程Fig.2 The extraction process of CFCC and its difference coefficient
對得到的GFCC系數(shù)進行一階差分和二階差分可得到ΔGFCC,ΔΔGFCC。在實驗中,每幀語音提取12維的GFCC、12維的ΔGFCC和12維的ΔΔGFCC構(gòu)成36維的特征參數(shù)ΔG:
ΔG=[GFCC,ΔGFCC,ΔΔGFCC]。
(5)
當圖2中的Gammatone濾波器為Mel三角濾波器時,提取的是MFCC,ΔMFCC,ΔΔMFCC的組合特征ΔM。
2 卷積神經(jīng)網(wǎng)絡(luò)
2.1 網(wǎng)絡(luò)結(jié)構(gòu)
CNN網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示,包含了一個由卷積層和子采樣層構(gòu)成的特征抽取器。在卷積層中,一個神經(jīng)元只與部分鄰層神經(jīng)元連接。CNN的一個卷積層通常包含若干個特征平面,每個特征平面由一些矩形排列的神經(jīng)元組成,同一特征平面的神經(jīng)元共享權(quán)值,共享的權(quán)值就是卷積核。卷積核通過訓練學習得到合理的權(quán)值,能夠減少網(wǎng)絡(luò)各層之間的連接,降低了過擬合的風險。子采樣(又稱池化)有均值子采樣和最大值子采樣2種形式。卷積和子采樣大大簡化了模型復(fù)雜度,減少了模型的參數(shù),本文采用的是最大值子采樣。

圖3 CNN網(wǎng)絡(luò)結(jié)構(gòu)Fig.3 CNN network structure
系統(tǒng)搭建了一個具有3個卷積層的CNN。輸入數(shù)據(jù)和卷積核做卷積,并通過激活函數(shù)(ReLU)得到下一層的輸入。卷積表達式如下:
(6)
得到的特征圖作為下一個池化層的輸入,進行降維處理。降維處理對系統(tǒng)有3個作用:突出顯著特征、減少系統(tǒng)的訓練參數(shù)和增加系統(tǒng)的頑健性。X=(x0,x1,x2,…,xn)是輸入向量;H=(h0,h1,h2,…,hL)是中間層的輸出向量。
池化層的數(shù)學表達式如下:
(7)
式(6)和式(7)中,Vij是前一層輸出單元i到隱層單元j的權(quán)重;Wij是隱層單元j到前一層輸出單元k的權(quán)重;θk,bj分別為前一層輸出單元和隱藏單元的閾值。
ΔG特征參數(shù)經(jīng)過3個卷積層和池化層后,得到表征語音的深層特征,再經(jīng)過全連接層獲得固定維數(shù)的特征向量,最后通過softmax分類器實現(xiàn)分類。
2.2 批量歸一化層
對輸入的特征參數(shù)進行歸一化處理[14],將每個樣本的特征值歸一化成均值為0、方差為1的分布,從而保證訓練數(shù)據(jù)的數(shù)值都在同樣量級上,使得訓練時數(shù)值更加穩(wěn)定。批量歸一化層的引入大大加快了CNN模型的訓練時間和測試時間。
對數(shù)據(jù)點xi每一個特征維進行歸一化:
(8)
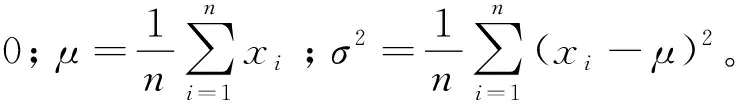
3 實驗結(jié)果與分析
3.1 實驗語料庫
本文使用的語料庫是SAS語音庫[15]。它由106個不同說話人(62個女生,44個男生)的語音組成,語種類別為英語,每個說話人包括300~400條語音(語音長度2~6 s)。語音的格式為WAV格式,采樣率為16 kHz,量化位數(shù)為16 bit,聲道為單聲道。
3.2 實驗設(shè)置
實驗隨機提取了106個說話人中的40個作為目標說話人,剩余的66個人作為GMM-UBM系統(tǒng)中通用背景模型的訓練樣本。采用與性別相關(guān)的訓練方法訓練出UBM模型,高斯混合度為64。每個目標說話人提取等量語音數(shù)(379條),共計40×379=15 160條。為了觀察說話人數(shù)對系統(tǒng)性能的影響,分別設(shè)置了數(shù)量為2,5,8,10,20,30,40人的目標說話人集合,按照4∶1的比例分成訓練樣本集和測試樣本集。本文進行了2組對比實驗,一組是基于CNN的文本無關(guān)說話人識別算法與GMM-UBM算法的對比實驗,對比了2種算法的識別率和效率;另一組實驗對比了在DNN,CNN的模型架構(gòu)下分別提取ΔM,ΔG的識別結(jié)果,如表1、表2和表3所示。
表1 不同說話人集合在不同模型下的識別率
Tab.1 Recognition rate of different speaker sets under different models

模型說話人數(shù)25810203040GMM-UBM0.970 00.925 00.920 00.913 00.900 00.880 00.795 0CNN0.991 00.989 00.985 00.980 00.970 00.966 00.939 3
表2 在DNN模型下提取ΔM,ΔG的識別率
Tab.2 The recognition rate when extracting ΔMand ΔGunder DNN model

特征參數(shù)說話人數(shù)25810203040ΔM0.956 70.901 40.866 70.833 20.752 40.708 70.626 0ΔG0.980 00.937 80.893 40.875 70.833 00.772 10.709 0
表3 在CNN模型下提取ΔM,ΔG的識別率
Tab.3 The recognition rate when extracting ΔMand ΔGunder CNN model

特征參數(shù)說話人數(shù)25810203040ΔM0.985 00.984 00.982 30.977 50.965 00.944 50.926 7ΔG0.991 00.989 00.985 00.980 00.970 00.966 00.939 3
3.3 說話人識別方法對比試驗
在系統(tǒng)前端對語音進行預(yù)加重、VAD等預(yù)處理,按幀長256、幀移80逐幀提取語音的ΔG特征參數(shù),將歸一化的ΔG特征參數(shù)送入2種網(wǎng)絡(luò),得到了不同集合在2種模型下的識別結(jié)果,如圖4所示。
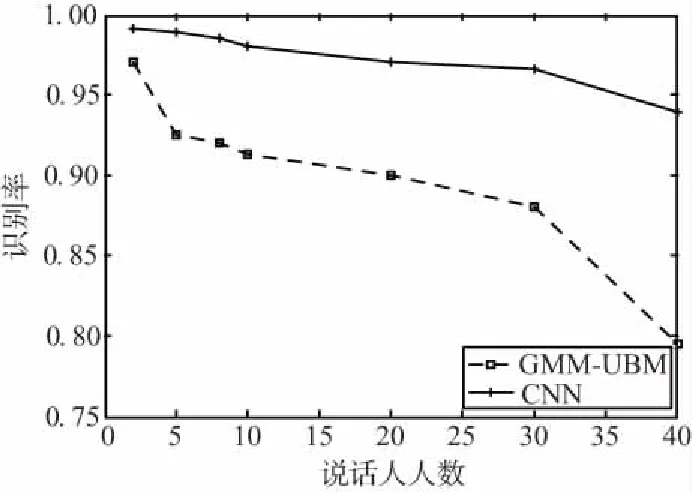
圖4 不同說話人集合在不同模型下的識別率Fig.4 Recognition rate of different speaker sets under different models
從圖4可知,CNN模型在不同數(shù)量的說話人集合下的識別率均高于GMM-UBM模型,且隨著說話人數(shù)的增加,CNN模型的識別率變化更加穩(wěn)定。從2個人的集合到40個人的集合,在GMM-UBM模型下的識別率變化了0.175,在CNN模型下變化了0.051 7。由此可以看出,針對說話人數(shù)的變化,CNN模型穩(wěn)定性更好。
為觀察2種模型在訓練和識別時長上的差異,表4列出了說話人數(shù)為40時2種模型訓練時間和測試時間的對比結(jié)果。
表4 實驗仿真數(shù)據(jù)結(jié)果
Tab.4 Experimental simulation data results

模型訓練時間/min識別時間/sGMM-UBM506CNN101
從表4可以看出,CNN模型在保證更高識別率的情況下,同時能減少對語料的訓練時間和識別時間,具有更高的識別效率。
3.4 特征參數(shù)選取對比實驗
在實驗中,分別提取了ΔM,ΔG這2種特征參數(shù),得到了不同說話人集合在不同特征參數(shù)下的識別結(jié)果。
為了進一步證實ΔG特征參數(shù)和CNN模型結(jié)合效果最佳,表2給出了在DNN模型下2種參數(shù)的識別結(jié)果。由于DNN結(jié)構(gòu)中神經(jīng)元之間只是簡單的全連接,對輸入特征進行深層抽取的能力不如CNN,故總體的識別率都低于CNN模型下的結(jié)果。從表3可以看出,針對ΔG,ΔM兩種不同的特征輸入,CNN模型都能達到較好識別效果,每一組說話人集合的識別率都在0.92以上。
在CNN模型下提取ΔM,ΔG的識別率如圖5所示。

圖5 在CNN模型下提取ΔM,ΔG的識別率Fig.5 The recognition rate when extracting ΔM and ΔG under CNN model
從圖5可以看出,在不同數(shù)量的說話人集合下ΔG作為特征參數(shù)時相較于ΔM識別率更高,采用ΔG作為特征參數(shù)送入卷積神經(jīng)網(wǎng)絡(luò)的說話人識別系統(tǒng)整體性能更好。
4 結(jié)束語
通過分析人耳聽覺模型原理的基礎(chǔ),采用Gammatone濾波器組模擬人耳聽覺感知特性,結(jié)合倒譜技術(shù)進行倒譜提升,構(gòu)建聽覺模型,得到一種基于Gammatone濾波器組的聽覺倒譜系數(shù)。通過實驗總結(jié),基于CNN的說話人識別系統(tǒng)將ΔG作為特征參數(shù)能得到更好的識別效果。ΔG與ΔM相比,針對不同數(shù)量的說話人都能得到更高的識別率。同時本文采用的CNN系統(tǒng)能實現(xiàn)快速模式匹配,相較于傳統(tǒng)的GMM和GMM-UBM系統(tǒng)不僅能提高識別率,同時能明顯減少訓練時間和識別時間。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
