一種改進的基于TransE知識圖譜表示方法
2020-05-18 11:07:04陳文杰
計算機工程 2020年5期
陳文杰,文 奕,張 鑫,楊 寧,趙 爽
(中國科學院 成都文獻情報中心,成都 610041)
0 概述
知識圖譜的起源可以追溯到語義網,語義網是一種通過計算機可以理解的方式對事物進行描述的網絡,其目的是實現人與計算機的無障礙溝通。知識圖譜本質上是一種大規模的語義網絡,主要目標是構建一張巨大的網絡圖來描述真實世界中存在的各種實體之間的關系。知識圖譜作為一種結構化的語義知識庫,通常采用三元組(h,r,t)的形式來表示知識,h和t代表頭和尾2個實體,r代表關系。知識圖譜的構建主要包括知識獲取、知識融合、知識驗證、知識推理和應用等部分。知識表示是知識圖譜構建和應用的基礎,但是基于三元組的知識表示形式無法充分且完全地刻畫實體間的語義關系,同時存在計算復雜度高、推理效率低和數據稀疏等問題。
近年來,隨著大數據和深度學習技術的發展,表示學習在自然語言處理和圖像識別等領域得到廣泛應用。表示學習的目的是用低維稠密的向量來表示研究對象,在低維空間中對象距離越近,對象在語義上越相似[1]。文獻[2]提出一種DeepWalk算法,其較早將word2vec的思想引入到網絡表示學習中。DeepWalk充分利用圖中的隨機游走信息,并通過實驗驗證了文檔中的單詞和隨機游走序列中的節點均服從冪律定律,在此基礎上,將word2vec應用在隨機游走的序列上,從而得到節點的向量表示。但是,DeepWalk在游走過程中完全隨機,難以針對特定目標進行有選擇性地游走。
現有網絡表示學習模型更側重于節點本身信息,忽略了邊上豐富的語義信息,而且邊通常不具有方向。知識圖譜表示學習是網絡表示學習的子領域,由于圖譜中的邊含有特定的語義且具有方向,因此其模型的設計更為復雜。在現有的知識表示模型中,TransE模型較具代表性,該模型將尾節點看作頭節點加關系的翻譯結果,使用基于距離的評分函數來估計三元組的概率。TransE模型取得了較好的預測結果,但是存在3個方面的缺陷,一是使用距離作為評分度量,每一維的特征權重相同,不夠靈活,知識表示的準確性會受到無關維度的影響,二是無法處理好一對多(1-N)、多對1(N-1)和多對多(N-N)等復雜關系,三是模型獨立地學習每一個三元組,忽略了圖譜中的網絡結構和語義信息[3]。
當前多數知識圖譜表示學習方法獨立地學習三元組而忽略了知識圖譜的結構特征。為了解決該問題,本文利用近鄰結構特征作為補充,進一步增強知識圖譜的表示效果,在此基礎上,提出一種向量共享的交叉訓練機制,以實現圖譜結構信息和三元組信息的深度融合。
1 相關工作
近年來,隨著Linking Open Data、Freebase和OpenKG等開放數據集的廣泛應用,互聯網從文檔萬維網向數據萬維網方向快速發展。谷歌在2012年提出了知識圖譜的概念,用于改善搜索結果[4]。隨后,多家互聯網公司開始構建知識圖譜,如蘋果的“Wolfram Alpha”、百度的“知心”和搜狗的“知立方”。知識圖譜被廣泛應用于語義搜索、智能問答和輔助決策等任務,在人工智能領域也具有良好的應用前景。
知識表示學習是將知識圖譜中的實體和關系映射到連續稠密的低維向量空間,同時保留圖中的結構和語義關系[5]。知識表示學習可以降低知識圖譜的高維和異構性,高效實現語義相似度計算等任務,并顯著提升計算效率,此外,其將每個實體映射為一個稠密的向量,有效地解決了數據稀疏問題。知識表示學習能夠實現異構知識的融合,將不同來源的實體和關系映射到同一語義空間中,還可以廣泛地應用于知識圖譜補全、關系抽取和智能問答等各類下游學習任務中[6]。知識表示學習的模型主要分為基于距離的翻譯模型、基于語義的匹配模型、矩陣分解模型和神經網絡模型等[2]。
目前,知識表示學習的研究熱點主要集中在基于距離的翻譯模型上,以Trans系列模型為代表。這類模型將尾節點看作頭節點加關系的翻譯結果,使用基于距離的評分函數來估計三元組的概率。文獻[7]于2013年提出TransE模型,該模型基于歐氏距離上的偏移量來衡量計算實體之間的語義相似度。TransE模型相對簡單,且具有良好的性能。TransE被提出之后,出現了一系列對其進行改進和補充的模型,如TransH、TransG、TransR和CTransR等。其中,為了有效處理1-N、N-1和N-N間的復雜關系,TransH模型令每一個實體在不同的關系下擁有不同的表示,將關系映射到另一個空間[8]。TransAH在TransH的基礎上引入一種自適應的度量方法,通過對角權重矩陣將目標函數中的歐式距離轉換為加權歐式距離[3]。TransA同樣提出一種自適應的度量方法,為每個關系定義一個非負的對稱矩陣,從而為表示向量中的每一個維度添加權重,有效地提升了模型的表示能力[9]。TransG模型使用高斯混合來刻畫實體間的多種語義關系,利用最大相似度原理訓練數據,該模型能夠有效解決多語義問題[10]。TransE和TransH假設實體和關系全都在一個空間內,在一定程度上限制了模型的表示能力。TransR則假設不同的關系具有不同的語義空間,將每個實體投影到對應的關系空間中[11]。為了解決TransR參數過多的問題,TransD將映射矩陣轉換為2個向量的乘積,TranSparse則引入自適應稀疏矩陣[12-13]。文獻[11]提出的CTransR模型是對TransR的擴展,該模型首先對關系對應的頭尾實體作差值,然后根據差值聚類將關系細分為多個子類[11]。但是,在CTransR模型的學習過程中,參數過多,計算量很大,不適用于大規模知識圖譜。除了將實體在不同關系下表示為不同向量,TransE方法進行另一類改進,其放寬翻譯模型的約束條件[6]。TransM為每一個三元組(h,r,t)分配一個與關系r相關的權重,其中,當r屬于1-N、N-1和N-N等復雜關系時權重值較低[14]。TransF模型不嚴格限定V(h)+V(r)≈V(t),要求向量V(h)+V(r)與向量V(t)在方向上保持一致即可[15]。
實體間的關鍵路徑通常也能反映實體間的語義關系。Path Ranking算法將2個實體的關鍵路徑作為特征,以預測實體之間的關系[16]。TransE等模型存在一定的局限性,往往獨立地學習每一個三元組。PTransE以TransE為基礎,提出一種考慮關鍵路徑的表示學習方法,并取得了顯著的效果[17]。基于語義的匹配模型[18-19]為了尋找實體間的語義關系,定義了多個投影矩陣來描述實體間的內在聯系,將實體和關系投影到隱語義空間以進行相似度計算。以RESACL[20-21]為代表的模型,采用矩陣分解來進行知識圖譜表示學習,利用三元組構建一個大矩陣,然后將矩陣分解為實體和關系的向量表示。為了精確刻畫實體和關系間的語義聯系,文獻[22]提出了單層神經網絡模型,該模型能夠使用非線性變換為實體和關系提供微弱的關聯,但其計算復雜度大幅提高。張量神經網絡模型使用雙線性張量取代傳統的線性變換層,能夠更精確地刻畫實體和關系的語義聯系,但其訓練需要大量數據,不適用于稀疏知識圖譜。文獻[23]基于卷積神經網絡構建一種融合實體文本屬性的學習模型,該模型使用低秩矩陣對頭實體和尾實體進行映射,從而更好地表征復雜關系。
2 TransGraph知識表示方法
TransE模型簡單,參數較少,計算效率較高,但其獨立地學習單個三元組,忽略了三元組形成的復雜網絡關系,因此,TransE難以處理三元組中1-N、N-1和N-N等問題。為此,本文基于TransE提出一種TransGraph模型,以在學習三元組的同時有效融合知識圖譜的網絡結構特征。
為了更好地描述知識圖譜和相應的算法模型,本文給出相關的定義和符號表示。將知識圖譜記作G=(E,R,S),其中,E是實體集,R是關系集,S?E×R×E表示三元組的集合,集合中的每一個元素用(h,r,t)表示,h、r和t分別表示頭實體、關系和尾實體。知識表示學習的目的是將實體和關系映射為低維稠密的向量V(h)、V(r)和V(t)。TransE采用最大間隔法來增強知識表示的區分能力,其目標函數定義如下:
d(h,r,t)=|V(h)+V(r)-V(t)|L1/L2
其中,[x]+表示x的正值函數,l是間隔距離參數,S′是三元組集S的負采樣集,d(h,r,t)是向量V(h)+V(r)和V(t)之間的L1或L2距離。
2.1 網絡結構特征學習
在知識圖譜網絡中,有2種拓撲結構能夠描述目標實體,一種是目標實體和相鄰實體組成的鄰接結構,如圖1所示,另一種是從一個實體到目標實體的關系路徑[11],如圖2所示。如果采用TransE從圖1的三元組中學習知識表示,將會使得“奧巴馬”“布什”和“特朗普”的向量相同,造成實體表示的區分度低,原因是TransE模型獨立學習三元組,在處理復雜關系時存在不足。鄰接結構反映了實體間的1-N和N-1等多重關系,因此,在表示學習過程中結合網絡結構特征能夠捕獲到網絡中隱含的復雜關系,從而有效改善TransE的不足。
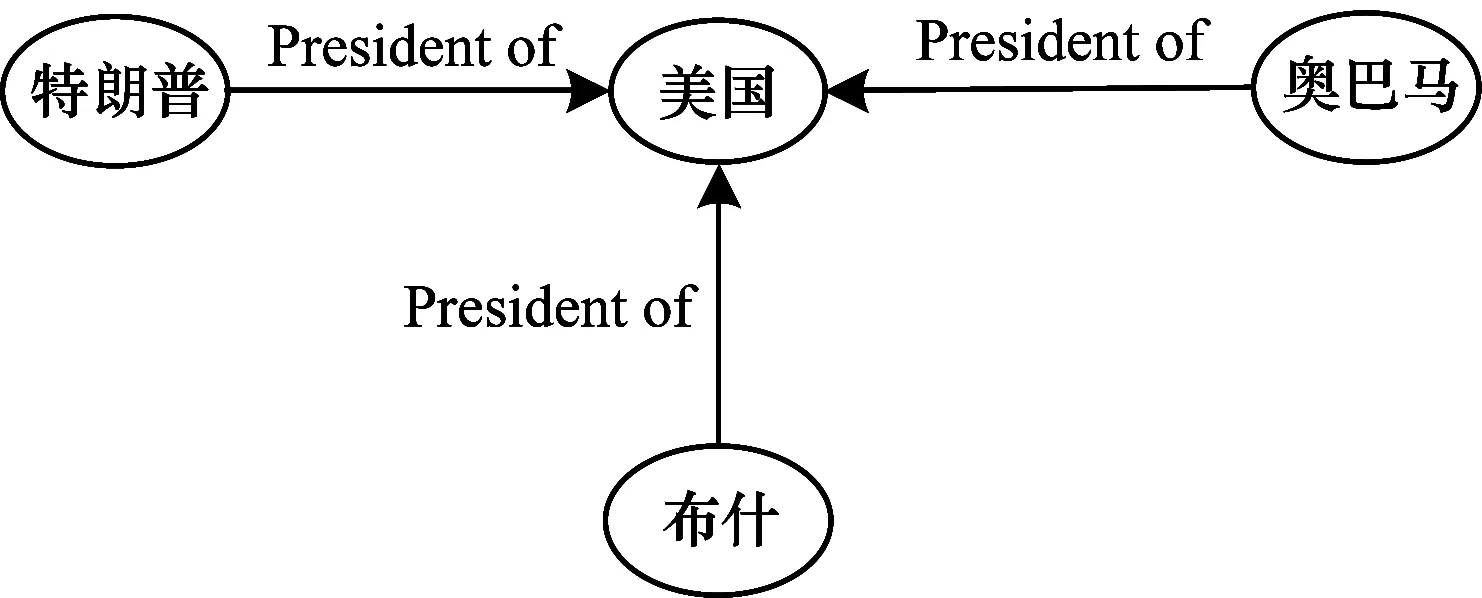
圖1 鄰接結構
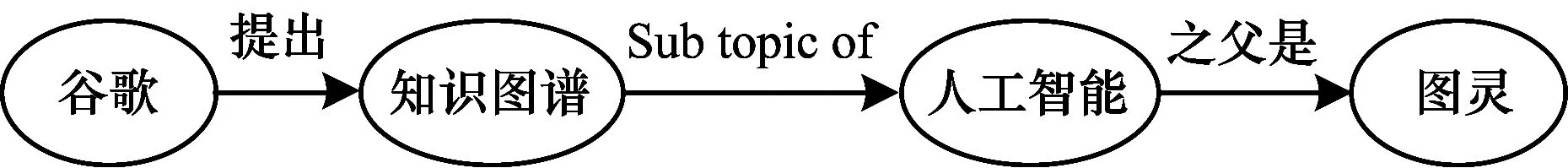
圖2 關系路徑
Fig.2 Relationship path
從直覺上來看,在知識圖譜中,拓撲結構相似的實體應該具有相近的向量表示。局部線性表示假設節點在較小的局部區域內是線性的,即一個節點的表示可以由多個鄰居節點的表示線性組合近似得到。文獻[24]研究表明,網絡中節點的鄰居節點集合對于表征節點間的結構相似性具有重要意義,鄰接結構相似的實體往往具有相近的語義。
根據目標節點到鄰居節點的距離,將目標節點的鄰接結構分為一階近鄰結構和多階近鄰結構,一階近鄰結構特征的學習過程如下:類似于CBOW模型利用上下文預測目標單詞,本文將鄰居實體和關系集視作一種特殊的“上下文”,在已知實體鄰接結構的情況下預測實體的概率,即通過最大化目標實體的預測概率來學習知識圖譜中的一階近鄰結構。例如,在圖1中用(奧巴馬,President of)、(布什,President of)和(特朗普,President of)來預測“美國”的概率值。將鄰居實體和關系作為輸入,目標實體作為輸出,構建3層神經網絡如圖3所示。

圖3 一階近鄰神經網絡模型
以預測概率為學習目標,定義一階近鄰結構學習目標函數如下:
其中,Nr_1(t)表示尾實體t的一階近鄰,Nr_1(t)={(h1,r1),(h2,r2),…,(hn,rn)}。投影層的中間向量作為一階近鄰結構的表示向量,采用累加求和的方式計算:

p(t|Nr_1(t))概率值的計算是典型的分類問題,本文使用softmax函數進行計算:
其中,E表示實體集,yt是實體t未歸一化的概率,計算如下:
yt=b+UXt
其中,b、U是softmax函數的參數。
在知識圖譜中,一階近鄰是十分稀疏的,因此,本文考慮使用多階近鄰實體和關系的向量來表示目標實體向量。假設目標實體t存在一個n階近鄰的實體h,則從h到t構成了一條n步的關系路徑。在知識圖譜中,多步的關系路徑往往能夠表征實體間的語義關系,文獻[16]基于關系路徑預測實體間的關系。為了構建關系路徑向量,PTransE對路徑上的所有關系進行語義組合,如圖4所示。
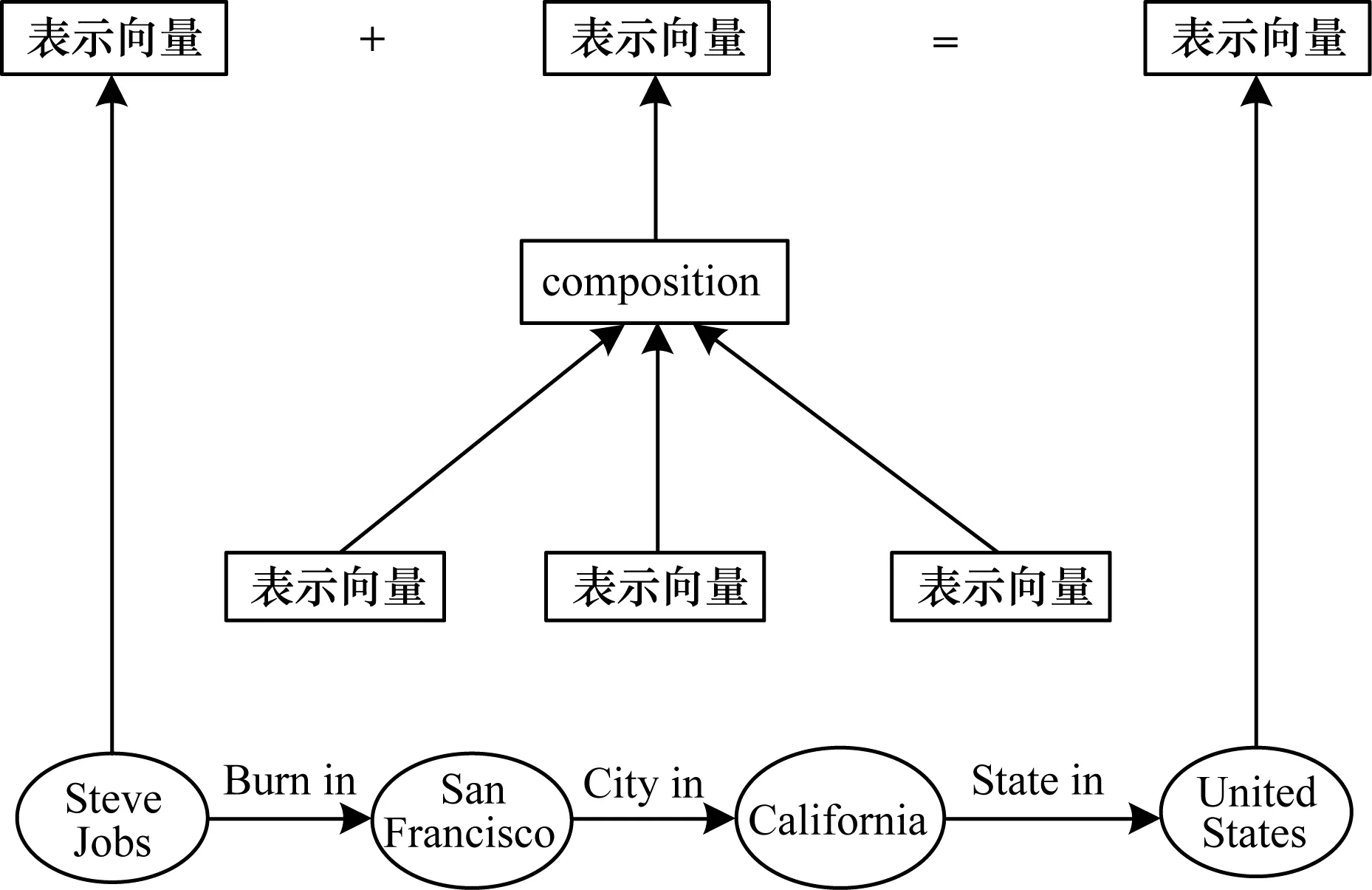
圖4 關系路徑向量
對于多階近鄰結構,本文考慮使用近鄰實體到目標實體的多條關系路徑來表示目標實體。類似于一階近鄰結構學習,本文將多個關系路徑向量作為輸入,目標實體作為輸出,構建3層神經網絡模型,如圖5所示。
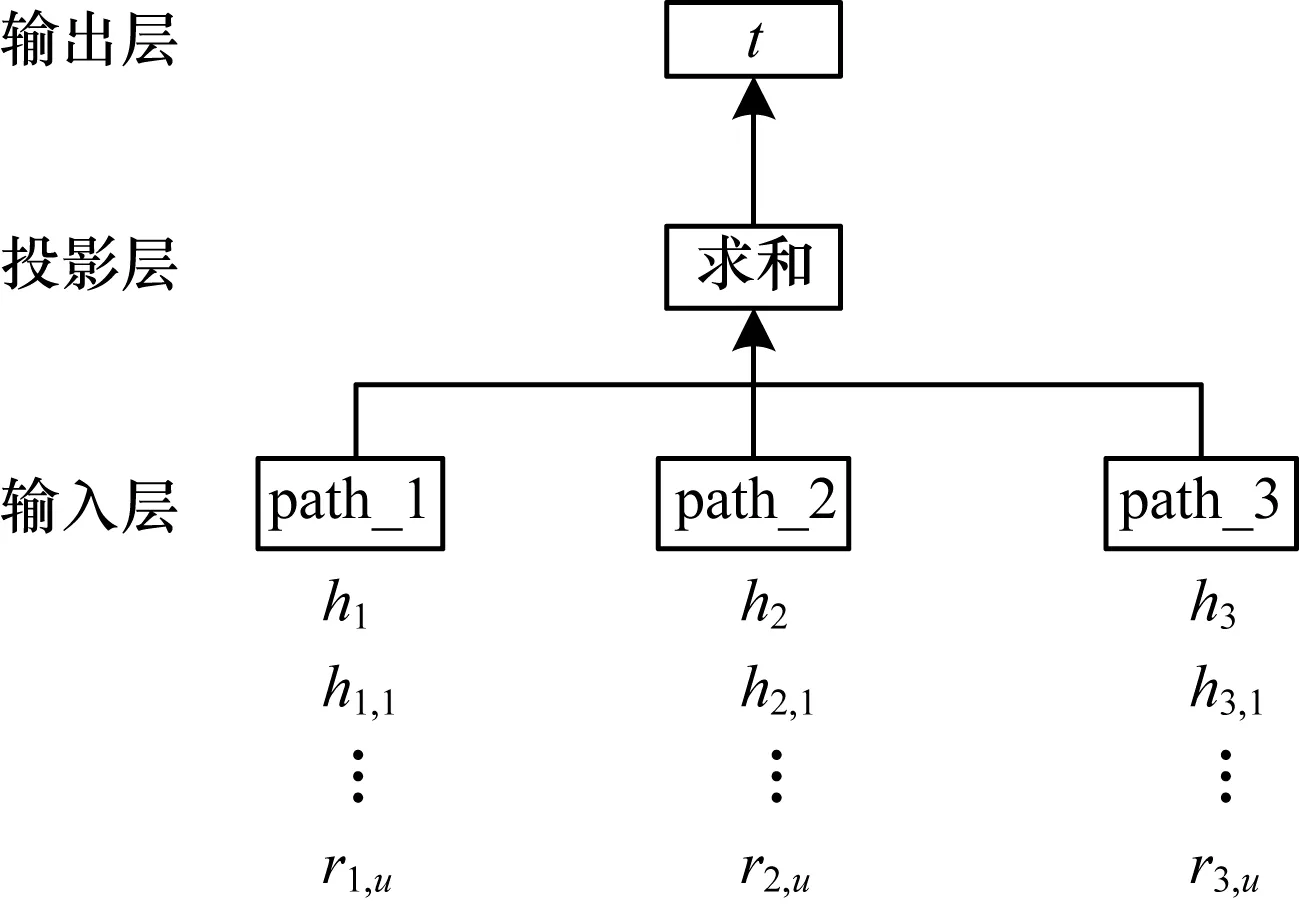
圖5 多階近鄰神經網絡模型
定義n階近鄰結構學習目標函數如下:
其中,Nr_n(t)表示所有小于等于n階的近鄰實體到尾實體t的關系路徑,Nr_n(t)={path1,path2,…,paths},pathi=(hi,r1,r2,…,ru),hi表示近鄰的實體,r是路徑上的關系,1≤u≤n。投影層的中間向量采用累加求和的方式計算:

同樣采用softmax函數計算p(t|Nr_n(t))概率值,此處不再贅述。
2.2 混合特征學習
當前多數方法獨立地學習三元組而忽略了知識圖譜的結構特征,為了解決這一問題,本文利用近鄰結構特征作為補充,進一步增強知識圖譜的表示效果。模型的目標優化函數如下:
L=ηLn+LTransE
其中,η是平衡結構特征和三元組特征的學習參數,通過不斷調整權重能更好地將模型應用于不同數據場景。一方面,目標函數L利用n階近鄰向量預測目標實體,使得表示向量包含圖譜的結構特征;另一方面,表示向量又參與了TransE模型中的三元組表示學習訓練。為了實現圖譜結構信息和三元組信息的深度融合,本文提出一種向量共享的交叉訓練機制,如圖6所示,其中,左右兩部分模型交替訓練,實體和關系向量在2個模型中共享,通過不斷地迭代訓練來更新向量,最終得到融合后的向量表示。
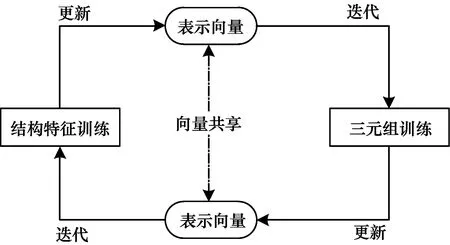
圖6 交叉訓練機制
為了提高模型的訓練速度,研究人員通常使用hierarchical softmax替代softmax。當計算p(t|Nr_n(t))時,hierarchical softmax以實體和關系作為葉子節點,將實體和關系在三元組集S中出現的頻率作為節點的權,構造一顆哈夫曼樹。對于每一個實體或關系v,哈夫曼樹中必然存在一條從根節點到v對應節點的路徑pv,v出現的頻率越高,則路徑的長度越短。在路徑pv上存在lv個分支,每個分支都視作一次二分類并產生一個概率,將分支產生的概率相乘便得到p(t|Nr_n(t))的值。因此,得到:
其中,有:

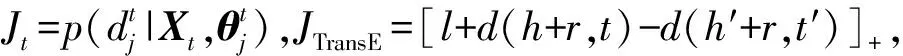
算法1TransGraph訓練算法
輸入triple setS,vector sized,marginl,learn rateα,balance rateη

1.Build Huffman Tree from S
2.Initialization V
3.for each epoch∈epochs do
4.for each(h,r,t)∈S do
5.for each(h′,r,t′)∈T′(h,r,t)
6.V(h):=V(h)+α*η*?JTransE/?V(h)
7.V(r):=V(r)+α*η*?JTransE/?V(r)
8.V(t):=V(t)+α*η*?JTransE/?V(t)
9.end for
11.u=0
12.for j=1:ltdo
14.u:=u+α*?Jt/?Xt
15.end for
16.for path∈Nr_n(t) do
17.for each e∈path
18.V(e):=V(e)+u
19.end for
20.end for
21.end for
22.end for
算法1的流程及復雜度分析如下:
2)分析算法的時間復雜度和參數復雜度。假設每次負采樣K個三元組,則TransE部分的時間復雜度為O(|S|·k)。在鄰接結構特征學習的梯度計算過程中,傳統的softmax需要對m+n個實體和關系計算概率,采用hierarchical softmax只需計算lt次,lt數量級為lb(m+n),故此部分的時間復雜度為O(|S|·lb(m+n))。綜上,算法1的整體時間復雜度為O(|S|·(k+lb(m+n))),算法的參數是共享向量和輔助向量,參數復雜度為O((m+n)d)。
3 實驗結果與分析
本文采用WN11、WN18、FB13和FB15K等多個數據集驗證和評估TransGraph模型的有效性。其中,WN11和WN18是WordNet的子集,FB13是Freebase的子集,FB15K是基于Freebase抽取得到的一個稠密子集。實驗數據集的詳細信息如表1所示。

表1 數據集統計信息
實驗主要包括鏈路預測和三元組分類2個任務,以從不同角度評估模型的預測能力和精確度。TransGraph模型的效果受數據規模、數據類型、參數設定等因素影響,實驗將針對不同因素分別進行測試。選擇三類不同的模型進行比較:1)基于TransE的距離模型,以TransH、TransR、TransA和TransG為代表,這類模型采用矩陣映射和高斯混合等方式對TransE進行優化,且取得了較好效果;2)以SME為代表的語義匹配模型;3)基于矩陣分解的RESCAL模型。
3.1 鏈路預測
鏈路預測的主要過程是對于一個完整的三元組(h,r,t),實驗給定(h,r)后預測t或給定(h,t)后預測r,從而驗證模型預測實體的能力。本組實驗采用WN18和FB15K兩個數據集。
3.1.1 評價標準
本次實驗采用和TransE相同的標準,以便與TransE等現有模型進行對比。首先,對于測試集中的每一個原始三元組(h,r,t),隨機丟棄頭實體h或尾實體r,得到(r,t)或(h,r);然后,從實體集中隨機選擇一個實體補全(r,t)或(h,r),得到變異三元組(e,r,t)或(h,r,e);最后,利用得分函數fr(h,e)計算原始三元組和變異三元組的得分,并對得分結果進行排序,從而得到原始三元組的排序分數。
通常通過平均排序得分(MeanRank)和排序不超過10的百分比(HITS@10)2個指標來度量原始三元組的排序結果。MeanRank越低、HITS@10越高,意味著實驗結果越好。需要注意的是,如果變異三元組仍然在知識圖譜中存在,說明該三元組剛好由一個原始三元組變異為另一個原始三元組,在實驗中這種三元組會干擾原始三元組的排序得分。為了消除上述干擾,在生成變異三元組集時需要過濾掉干擾三元組,以保證變異三元組不屬于訓練集、驗證集和測試集等,這一過程稱作Filter。未經Filter過程的實驗設置稱作Raw,Filter后的實驗結果往往更好,擁有更低的MeanRank和更高的HITS@10。
3.1.2 實驗過程
在訓練TransGraph時,學習率α設為{0.01,0.1,1},間距l設為{0.25,0.5,1},向量維度d設為{20,50,100},模型間的平衡率η設為{0.01,0.1,1,10},近鄰結構階數n設為{1,2,3}。經過多次實驗得到最優的參數配置如下:在FB15K數據集中,α=0.01,l=1,d=50,η=0.1,n=2;在WN18數據集中,α=0.01,l=1,d=20,η=0.1,n=2。TransGraph與TransE等現有模型的實驗對比結果如表2、表3所示。
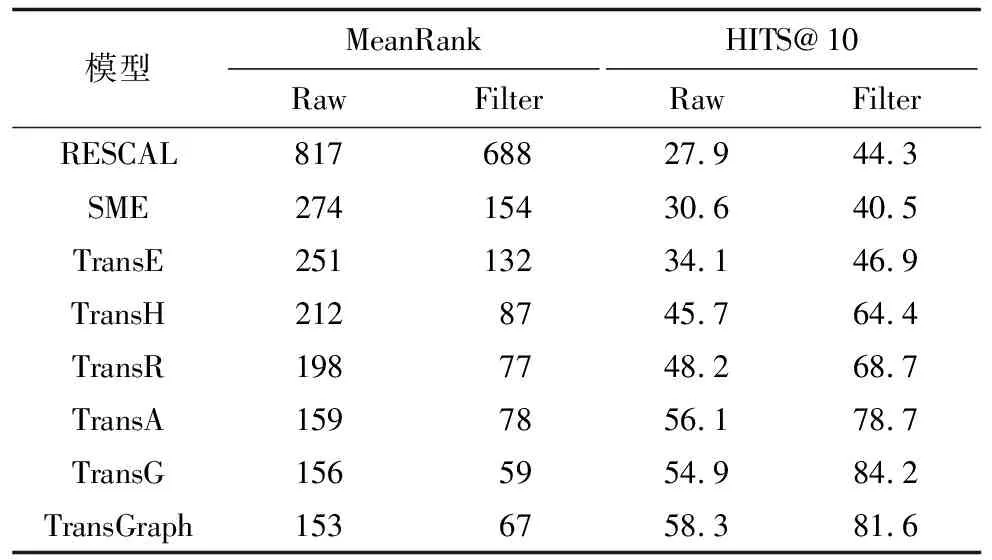
表2 FB15K數據集上的實驗對比結果
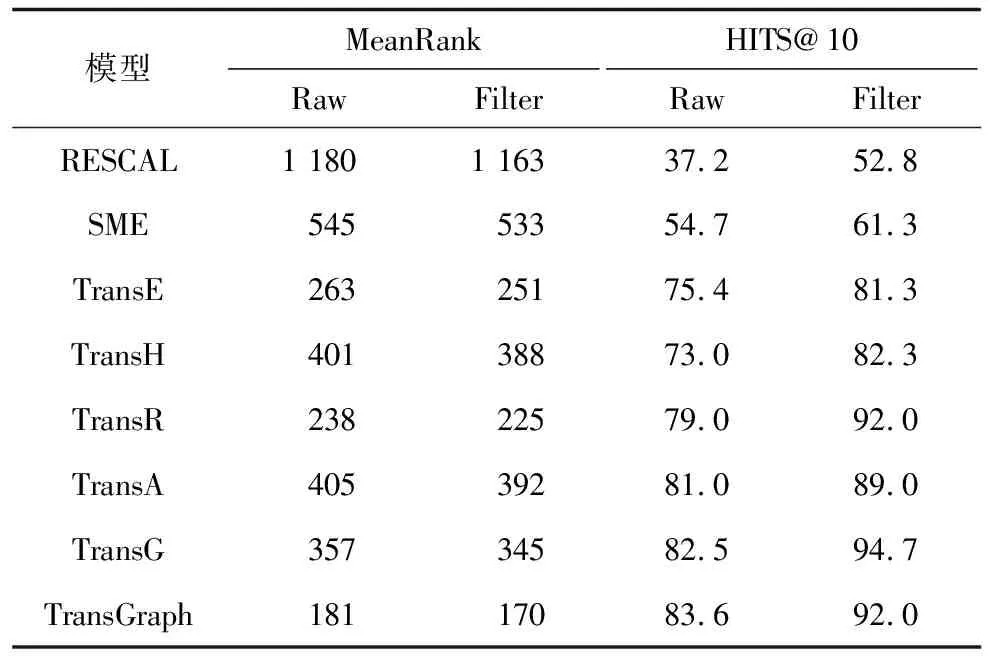
表3 WN18數據集上的實驗對比結果
從表2、表3可以看出,與TransE模型相比,TransGraph的MeanRank指標更低,HITS@10指標更高,在FB15K數據集上提升39.3%,在WN18數據集上提升30.4%,該結果進一步說明了將TransE和Skip-gram相結合后在表達復雜關系的場景中擁有較大優勢。需要注意的是,相較于WN18數據集,TransGraph在FB15K數據集上的MeanRank指標值更低,主要原因是FB15K是一個更加稠密的數據集,三元組組成的知識圖譜擁有更復雜的網絡結構,TransGraph更能發揮網絡結構特征學習的優勢。因此,TransGraph能夠更好地處理三元組中1-N、N-1和N-N等問題,進而完成知識獲取、知識融合和知識推理等。
3.2 三元組分類
三元組分類任務用于驗證模型識別原始三元組和變異三元組的能力,對于給定的三元組(h,r,t),模型需要對三元組進行二元分類。在本次實驗中,使用WN11和FB13數據集,采用和鏈路預測同樣的方式生成變異三元組。分類的標準是對于一個給定的三元組(h,r,t),計算得分函數fr(h,e),如果得分低于一個閾值σ,則將三元組分類為原始三元組;如果高于閾值,則將三元組分類為變異三元組。若三元組分類正確,則給三元組生成正標簽,反之則生成負標簽。
在實驗過程中,設置TransGraph的學習率α={0.01,0.1,1},間距l={0.25,0.5,1},向量維度d={20,50,100},模型間的平衡率η={0.01,0.1,1,10},近鄰階數n={1,2,3}。經過多次實驗得到最優的參數配置如下:在FB13數據集中,α=0.01,l=1,d=50,η=0.1,n=2;在WN11數據集中,α=0.01,l=1,d=20,η=0.1,n=2。TransGraph與TransE等現有模型的實驗對比結果如表4所示。
表4 三元組分類準確率對比
Table 4 Comparison of accuracy rate of triple classification %
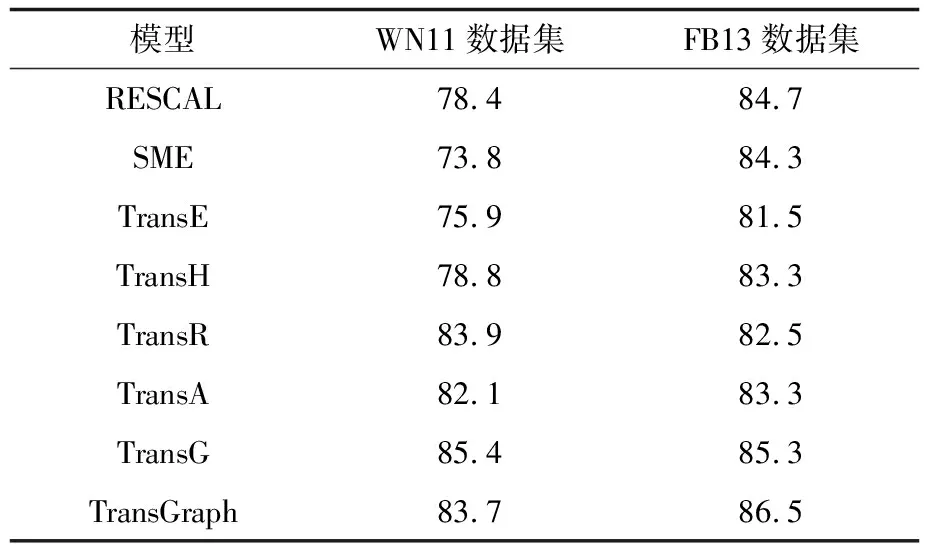
模型WN11數據集FB13數據集RESCAL78.484.7SME73.884.3TransE75.981.5TransH78.883.3TransR83.982.5TransA82.183.3TransG85.485.3TransGraph83.786.5
從表4可以看出,相較于TransE模型,TransGraph的準確率在WN11數據集上提升10.3%,在FB13數據集上提升6.1%。因為FB13的關系數量和實體數量都大于WN11,即FB13是一個密度更大、關系更復雜的數據集,所以TransGraph模型在FB13數據集上的分類效果更好。在實驗過程中,η的取值范圍是{0.01,0.1,1,10},通過不同的取值能夠探究網絡結構特征對實驗結果的影響。當η=0.1時,模型在數據集中取得最優性能;當η較小時,網絡結構特征對表示向量的影響較弱,因此,模型在處理復雜關系時效果不佳;當η較大時,三元組(h,r,t)對應的表示向量不滿足V(h)+V(r)≈V(t)這一約束條件,導致模型的翻譯能力下降。
4 結束語
傳統基于距離的翻譯模型存在無法處理復雜關系和忽略知識圖譜網絡結構的問題,導致知識表示的效率不高。為此,本文提出一種同時學習三元組和知識圖譜網絡結構特征的TransGraph模型。在WN11、WN18等公開數據集上對鏈路預測和三元組分類2項任務進行實驗,結果表明,與TransE等模型相比,TransGraph的準確率較高。但是,本文僅研究三元組及圖譜結構,忽略了實體的描述文本和互聯網文本等信息,因此,下一步考慮將多源信息進行融合以優化TransGraph模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
