挖掘軟件源代碼的代碼注釋自動生成方法
2020-05-20 01:19:36張麗萍
計算機工程與應用 2020年10期
白 楊,張麗萍
內蒙古師范大學 計算機科學技術學院,呼和浩特 010022
1 引言
代碼注釋是軟件開發的一個重要組成部分,能夠輔助編程人員有效地理解源代碼。代碼注釋一般用自然語言的形式闡述代碼背后實現的邏輯或功能[1],開發人員依賴代碼注釋了解源代碼描述的功能。在規范的軟件開發過程中,編程人員會被要求在源代碼的適當位置添加適量的代碼注釋[2]。
在實際中,缺乏代碼注釋是軟件工程領域中的常見問題,大多數軟件代碼注釋較少,大部分程序員只注重所編寫的代碼,而忽略與代碼相對應的注釋或者文檔,這就導致程序的可讀性和可維護性大大降低,同時降低開發效率。再者,如果程序員在編寫代碼的同時手動書寫代碼注釋或者文檔,既浪費程序員的時間,又使得工作效率降低。因此,自動生成代碼注釋是必要的,它不僅可以節省開發人員編寫注釋的時間,提高工作效率,而且程序可讀性和可維護性也會大大提升。
本文通過檢測原項目軟件和目標軟件的相似性代碼,對提取的代碼和注釋進行精簡優化處理,最終為目標軟件自動生成代碼注釋。
2 相關工作及概念
2.1 代碼注釋的概念及類型
代碼注釋即對代碼的解釋和說明,主要是為了讓開發者迅速理解代碼,是程序員為語句、程序段、函數等給出的解釋或提示,能提高程序代碼的可讀性。換句話說,代碼注釋就是用自然語言的形式闡述代碼背后實現的邏輯或功能,是描述軟件功能的可讀性自然語言,是架起程序設計者與開發者之間的通信橋梁,與此同時能夠提高團隊開發合作效率,因此,自動生成代碼注釋在整個注釋的研究中是至關重要的。
代碼注釋按照注釋對象可以分成三種類型[3],即文檔注釋(Javadoc/Document Comment)、塊注釋(Block Comment)和行注釋(Line Comment)。為了直觀說明,圖1給出了三種代碼注釋類型的例子。其中,文檔注釋包括類注釋、方法注釋、屬性注釋、包注釋和概要注釋,一般以/**...注釋內容...*/或者@...的形式表示;塊注釋分隔源代碼區域,該區域可以跨越多行或單行的一部分,使用起始分隔符和結束分隔符指定此區域,通常以/*...注釋內容...*/的形式表示;行注釋是指以注釋分隔符開始并一直持續到行的結尾,或者在某些情況下,從源代碼中特定列(字符行偏移)開始,并繼續直到行的結尾,簡單地說,行注釋是指跟在代碼行后面,描述當前代碼所表達的功能,例如Java 語言中,單行注釋以“//”開頭,跟在“//”后面的文本就是注釋內容。其中文檔注釋可以由工具自動生成[4-5],而塊注釋和行注釋則需要由編程人員手動添加。
2.2 國內外研究現狀
對于代碼注釋自動生成國內外均有一定的研究基礎,Wong等人提出了一種從StackOverflow上挖掘大規模問答數據來自動生成代碼注釋的方法[6]。該方法計算目標軟件代碼和StackOverflow上的代碼片段之間的相似性,并將StackOverflow 上的代碼片段的描述用于生成目標軟件代碼段的注釋。該方法雖然生成相應的代碼注釋,但只能自動生成有限數量的注釋。
在此方法的基礎上,Wong 等人又提出了另一種通過挖掘現有軟件代碼庫來自動生成代碼注釋的方法[7]。該方法使用代碼克隆檢測技術從軟件代碼庫中發現語法相似的代碼片段,并將代碼注釋應用于其他語法類似的代碼片段上。該方法雖然可以產生良好且可提交的注釋,但自動生成注釋的產量和精度相對較低。
Sridhara等人提出了一種對Java方法生成注釋的方法[4]。該方法給定一個方法名和方法體,在自動生成注釋的同時描述該方法的功能。Sridhara等人還使用啟發式算法對Java方法的參數自動生成注釋[5]。這些方法雖然可以直接從代碼元素中合成自然語言的句子,但過度依賴于程序中的標識符名稱和方法名。
Moreno 等人對Java 類生成注釋[8]。該方法根據一組啟發式方法,并使用現有的文本生成工具編寫注釋。生成的注釋主要描述了類本身涵蓋的內容以及該類的功能。雖然該方法是第一種自動生成類的自然語言摘要的技術,但其質量還需提高。
McBurney 和 McMillan 也提出了一種對 Java 方法生成注釋的辦法[9]。該方法總結了上下文,而不是方法內部的細節。該方法使用PageRank在該上下文中找到最重要的方法,并使用SWUM(Software Word Usage Model)來收集描述這些方法行為的關鍵字。同時設計了一個自定義NLG(Natural Language Generation)系統來創建關于此上下文的自然語言文本。該方法雖然生成注釋的質量優越,但評估方法單一,影響結果。
綜上所述,在代碼注釋自動生成方面,大多數對代碼注釋的研究都存在注釋稀少、準確度不高的問題,而且程序理解本身就存在一定的難度,因此本文針對這一問題,使用注釋復用的方法來提高代碼注釋的產量和質量。
2.3 注釋復用及克隆檢測
研究者試圖利用人工及自動化的方法為代碼添加注釋,其中自動化方法主要包括注釋復用及注釋抽取[4-5,8]。本文使用了注釋復用的方法,從已有軟件項目和目標軟件項目中找出相似代碼,將已有項目中的注釋信息處理后映射到目標項目中的相似代碼段上。因此,找出相似代碼是其中的關鍵步驟,本文使用克隆檢測加以解決。在克隆研究領域,人們普遍將相同或相似的代碼段叫作克隆代碼,簡稱克隆[10]。現在比較權威的說法,克隆代碼可以被分為Type-1、Type-2、Type-3和Type-4四類[11]。克隆檢測指的是查找并反饋軟件系統中的克隆代碼,為軟件開發、維護、軟件重構和演化等活動提供最基本的參考信息。
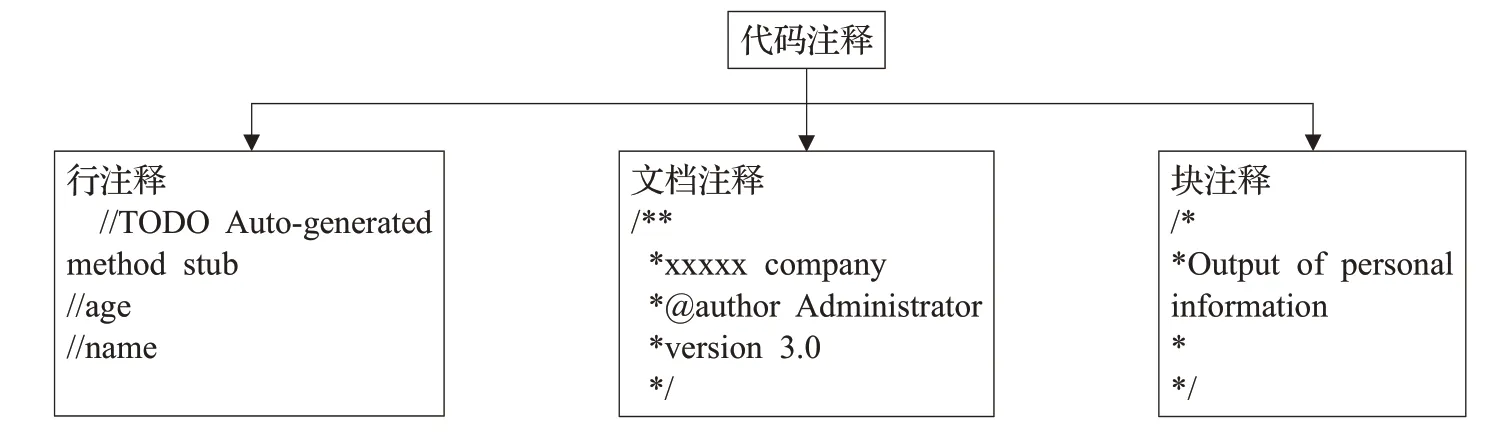
圖1 代碼注釋類型示例
國內外關于克隆檢測方法和技術的研究已經相對成熟。很多研究者對克隆檢測進行了實驗,Roy等人開發的Nicad應用靈活的過濾和規范化機制對文本檢測進行改進[12],可有效檢測Type-1、Type-2以及Type-3克隆。
Kamiya等人開發了一款名為CCFinder的克隆檢測工具[13]。此工具將每一行代碼單獨轉化為Token 序列,然后合并所有的Token序列,這樣做是因為即使變量名和代碼結構發生變化,也不會影響檢測結果。
Gabel等人將PDG(Program Dependence Graph)中的子圖同構問題規約為子樹同構問題[14],再利用Deckard進行檢測,來提高檢測的速度和可擴展性。
本團隊在克隆檢測方面也進行了大量研究。史慶慶等人使用優化后綴數組的方法進行克隆代碼檢測[15],并實現了一款檢測軟件源代碼中克隆群的工具FCD(Function Clone Detector);張久杰等人實現了基于Token編輯距離的檢測方法[16],能有效檢測Type-3 克隆代碼。這些為本文的后續研究奠定了基礎。
3 代碼注釋自動生成
3.1 研究框架
本文自動生成代碼注釋分為四個階段:(1)克隆檢測階段;(2)代碼和注釋提取階段;(3)克隆代碼和注釋優化精簡階段;(4)代碼與注釋映射階段。圖2 顯示了自動生成代碼注釋的步驟。
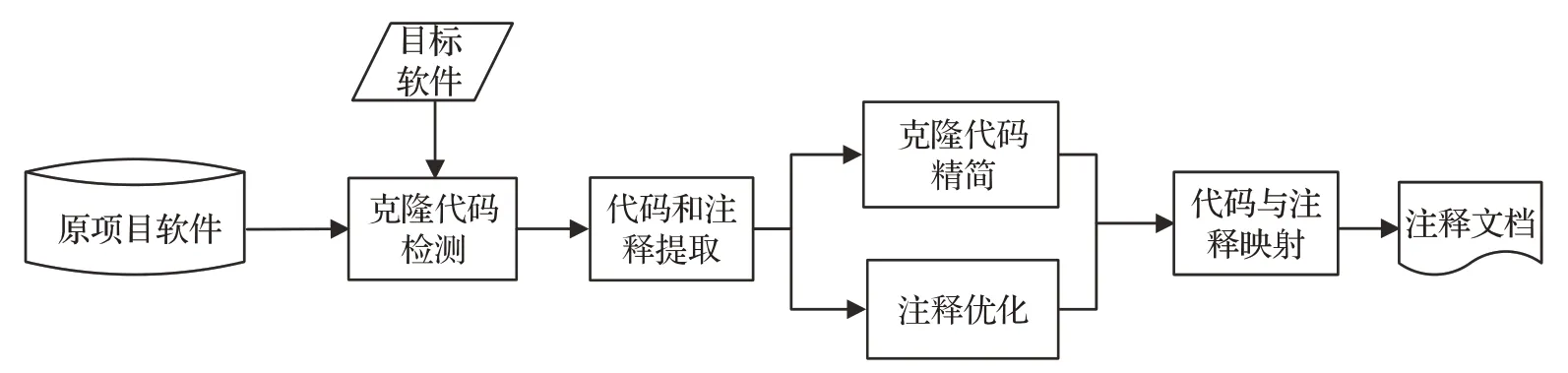
圖2 總體研究路線
本文提出的代碼注釋自動生成的方法,需要提供兩個輸入:(1)原項目軟件,擁有數量豐富、質量較高的代碼注釋,可以從中提取規范的代碼注釋信息,本文從Github下載開源項目。(2)目標項目軟件,通過該方法為其添加代碼注釋的項目軟件,即從原項目軟件中提取注釋信息,經過精簡優化映射到目標項目軟件中相應的代碼段上,本方法的輸出則是為目標項目自動生成的代碼注釋文檔。
3.2 克隆代碼檢測
自動生成代碼注釋之前需要檢測克隆代碼,即原項目軟件與目標軟件的相似代碼片段。檢測軟件中的克隆代碼是提取代碼和注釋的基礎,因此精準的克隆檢測是自動生成代碼注釋的關鍵步驟。本文使用當前領域較成熟的克隆檢測工具Nicad 進行克隆檢測。Nicad 是基于文本的克隆檢測工具,可以較準確地檢測出Type-1、Type-2、Type-3的克隆代碼。此工具可以檢測軟件內部的克隆代碼,也可以檢測跨版本軟件的克隆代碼,為本文后續代碼注釋的研究提供更加準確的數據來源。
本文在原項目軟件和目標軟件之間找到相似的代碼段。從GitHub上下載了100個開源項目軟件,這些開源項目軟件的代碼注釋是由開發人員編寫。原項目的代碼注釋是經過軟件演化過程最終沉淀形成的,相對完善成熟,質量高并且規范化,極具參考價值,因此可以選取其作為標準集。本文將100款原項目軟件和5款目標軟件作為輸入,利用Nicad 檢測這些原項目軟件和5 款目標軟件,檢測結果以克隆對和克隆群的形式反饋。本文只采用克隆群形式的檢測結果,檢測結果存儲到XML(Extensible Markup Language)文件中。下面以FreeMind為例,介紹克隆檢測結果。圖3呈現了以克隆群形式反饋的部分內容檢測結果。該XML顯示了檢測到的克隆代碼的相似度、文件路徑和文件名等詳細信息。

圖3 克隆檢測結果存儲方式
3.3 克隆代碼及其注釋的提取
通過克隆檢測結果只得到了這些克隆代碼的存儲路徑,在獲取克隆檢測結果之后,需要對克隆代碼和注釋進行提取。自動生成代碼注釋是以提取的克隆代碼和注釋為線索映射成的集合,因此這一步驟是后續研究的基礎。
3.3.1 克隆代碼的提取
在克隆代碼提取階段,從克隆檢測階段獲取的XML 文件中,得知有文件名、文件路徑等信息,本文使用字符流讀取XML 文件,通過文件路徑和行號讀取文件,然后創建一個可以往文件中寫入字符數據的字符輸出流對象以便存儲數據。寫入數據時,首先判斷文件是否存在,如果文件不存在,則自動創建,如果文件存在,則會被覆蓋。然后將在指定行內文件與不在指定行內文件區分,存儲在兩個緩沖區中。最后獲取指定行內文件的內容寫入文件中,完成克隆代碼的提取。具體實現方法如下。
算法1 克隆代碼提取算法
輸入:克隆檢測XML文件。
輸出:克隆代碼提取文件。
1. def getdata(path,filename)
2. file1,buffer #定義生成的文件
3. For length in data do
4. buffer=read data
5. End For
6. If file1 no exist then
7. create file1
8. Else cover file1
9. write content
10. End If
3.3.2 代碼注釋的提取
在代碼注釋提取階段,需要提取出克隆代碼相對應的注釋,通過XML文件提供的信息,獲取文件ID號、文件名、文件路徑、源文件起始行和結束行等信息。首先獲取克隆代碼,在得到克隆代碼文件以后,將克隆代碼文件解析成AST(Abstract Syntax Tree),然后從數據庫克隆代碼段的AST中檢索代碼注釋,最后將提取的代碼注釋存儲到文本文檔中。具體的代碼注釋提取算法如下。
算法2 代碼注釋提取算法
輸入:XMLpath。
輸出:克隆代碼、注釋內容文檔。
1. def getXMLdata(xmlpath)
2. ElementTree 將XML文件解析為元素樹
3. List
4. content 注釋內容
5. tar_file
6. For Clone Group in List
7. If element.getName equals“clones”then
8. Return id,clones,sourcecode,startline,endline
9. End If
10. End For
11. While content
12. If linenumber in tar_file
13. Return content
14. End If
提取的克隆代碼和注釋如圖4所示,圖中提取出的fireTreeNodesChanged()表示提取的以方法為粒度的克隆代碼,/**…*/和//后面表示此克隆代碼相應的注釋。

圖4 提取文檔部分示例
3.4 代碼及注釋精簡優化
提取出所要的克隆代碼和代碼注釋后,不能直接將這些注釋映射到目標文件的代碼,需要對提取的克隆代碼和注釋進行精簡優化,提高實驗結果的質量和準確度。因此對代碼和注釋的優化是自動生成代碼注釋的關鍵步驟之一,此步驟直接影響最后的注釋質量。這一階段分為兩個步驟:(1)克隆代碼精簡;(2)代碼注釋優化。
3.4.1 克隆代碼精簡
代碼中包含許多的無用詞,這些詞對后續代碼與注釋映射的研究作用較小,而且無用詞的出現會對實驗結果的準確度產生噪音,因此需對這些詞進行處理。提取出克隆代碼以后,并不是每一段代碼都適合為其添加注釋,有的克隆代碼對于研究沒有很重要或者是必然的意義,克隆代碼檢測工具有時無法區分有意義匹配和無意義匹配,因此需要根據研究的實際情況來篩選出有意義的克隆代碼。本文采用兩條啟發式規則過濾各類型的停用詞,具體內容如表1所示。

表1 停用詞規則表
3.4.2 代碼注釋優化
原項目軟件中提取的代碼注釋與目標軟件中代碼所描述或者表達的意思或功能不一定一致,亦或者表達太過冗余,這樣就會大大降低軟件代碼的可讀性和可維護性,同時浪費讀者的時間。在進行代碼與注釋匹配之前,首先預處理所有提取的代碼注釋,去除無關項以及與代碼所表達的功能或含義不太相符的字符,然后對這些注釋進行優化,這樣可以使注釋變得更加淺顯易懂,開發者可以快速地理解此部分代碼所要表達的含義,提高其效率。因此,對于提取出的代碼注釋,本文通過三條啟發式規則對提取出的注釋進行了精簡優化,如表2所示。

表2 優化注釋規則
3.5 代碼與注釋映射
提取的克隆代碼和代碼注釋經過精簡優化處理后,得到了相對較高的用于實驗研究的結果,此時,本文將優化的代碼注釋映射到目標軟件的代碼,即將目標代碼提取出來,和原項目軟件提取優化的注釋進行匹配,將注釋映射到目標軟件的代碼段上。通過Nicad配置文件的行號過濾,如果是這些行號內的代碼,加上源文件提取出的對應的注釋,為每一個方法和語句添加對應的注釋,重新生成目標軟件;如果不是這些行號內的代碼,則直接寫入文件。其對應的代碼注釋映射算法如下。
算法3 代碼與注釋映射算法
輸入:優化后的XML文件和生成的注釋文件。
輸出:新的帶有注釋的代碼目標文件。
1. def writeFileContent(filepath,newstr)
2. Temp
3. If file exists then
4. filein=newstr+" ";#新寫入的行,換行
5. End If
6. For temp=br.readline()!=null do
7. Buffer.append(temp)
8. End For
3.6 生成代碼注釋
目標軟件的代碼與原項目軟件的代碼進行克隆檢測,找到二者相似的代碼,本文將克隆檢測出的代碼進行精簡處理,然后從原項目軟件中提取代碼注釋,利用4個啟發式算法對提取的代碼注釋進行優化處理,最后將優化后的注釋映射到目標軟件的代碼上,此時代碼注釋自動生成已經基本完成。本文最后自動生成的注釋和代碼的映射生成一個Java文件,其詳細內容如圖5所示。

圖5 代碼注釋生成結果圖
4 實驗結果與分析
目標軟件的注釋比較稀少且質量不高,因此本文通過克隆檢測找出原項目軟件和目標軟件的克隆代碼,對提取的代碼和注釋精簡優化,得到質量較高、數量適合的代碼注釋。本文為5 款目標軟件經過克隆檢測得到的55個代碼段生成了總共75條注釋。顯示了每個項目生成的代碼注釋(NC)的數量。平均為每個項目產生15條注釋,但是5 款軟件有超過105 萬行代碼,產量仍然很低。
4.1 數據來源
本文從Github上下載了100款軟件項目,然后在評估中為5個Java目標軟件生成注釋,分別為Jabref、Jbidwatcher、Vuze、MegaMek、FreeMind,基本信息如表 3 所示。其中包括評估時使用的軟件,也包括通常評估的代碼克隆檢測項目。這5款軟件在該領域被經常使用,具有代表性,且都有很長的歷史時間,比較成熟,也有其他團隊在自動生成代碼注釋時選用了這些軟件,因此適合用于實驗。使用CLOC計算每個項目的代碼總數如表3所示。CLOC是一款在許多編程語言中計算空白行、注釋行和源代碼的物理行的軟件。

表3 軟件基本信息
本文在檢測原項目軟件與目標軟件的克隆代碼時,使用Roy 團隊開發的檢測工具Nicad,此工具檢測方法基于文本檢測,能夠高效檢測出原項目軟件和目標軟件的 Type-1、Type-2 以及 Type-3 克隆代碼,并將檢測結果存儲在XML文件中,便于后期數據的提取和使用。
4.2 評估標準
本文對所得實驗結果進行了手動驗證,為了獲得更加準確的代碼注釋,考慮到自動生成注釋的準確性、充分性、簡潔性等性能,運用了以下的排名標準:
良好:自動生成的代碼注釋在描述目標軟件代碼時是準確、充分、簡潔、符合邏輯的,則被視為是好的注釋,保留此注釋。
中等:自動生成的代碼注釋在描述目標軟件代碼時不夠準確、充分、簡潔,但經過小小的修改或改變可以正確描述,則被視為是中等注釋。
不好:自動生成的代碼注釋在描述目標軟件代碼時不準確、不簡潔或者不充分,經過修改或改變以后還是無法被修正,則被視為是不好的注釋,不予以推薦。
以上標準對自動生成的代碼注釋的質量進行評估,如果評估結果是良好或者中等的,那么在以后的應用研究中就適當地推薦給程序開發人員。好的代碼注釋可以幫助程序開發人員節省閱讀代碼的時間和精力,提高效率。
本文主要對5款軟件進行了自動生成注釋的應用,以評估生成的代碼注釋的產量和質量,采用Wong 等人的標準進行評估,為了在以后的研究中可以進行對比。
4.3 實驗結果
(1)生成的代碼注釋的產量
從NC、CG、LC、DC 這四方面對生成的代碼注釋的產量進行了評估,實驗結果的詳細信息如表4所示。其中NC表示每個項目生成的代碼注釋的數量;CG表示克隆組;LC 代表目標軟件的每個克隆組中的平均代碼克隆數;DC 描述了軟件存儲庫的每個克隆組中的平均代碼克隆數;CM表示目標項目軟件已經存在的代碼注釋。
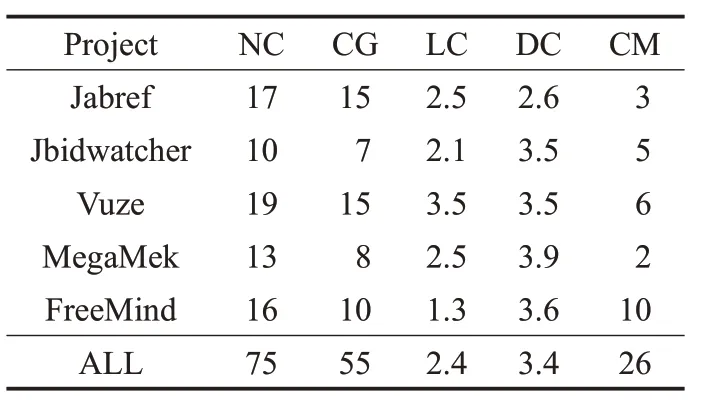
表4 生成注釋結果的產量
根據表4 可以看出,每個克隆組包含平均2.4 個本地克隆和3.4 個數據庫克隆,5 款軟件總共生成75 條代碼注釋,平均每款軟件生成15 條代碼注釋。產量相對較低,后續研究將進一步對產量進行提高,目前本實驗使用的是Nicad克隆檢測,檢測的克隆代碼數量還是很低。在以后的研究工作中,可以通過改進克隆檢測技術或利用更高級的代碼克隆檢測工具來提高生成的克隆代碼的數量,還可以通過使用更多項目擴展數據庫來增加克隆組的大小。
表5顯示了克隆組大小的分布。根據所得數據,知道有76.8%的克隆組包含2 個size。在以后的研究中可以通過使用更多項目擴展數據庫來增加克隆組的大小,或者利用更高級的代碼克隆檢測技術。
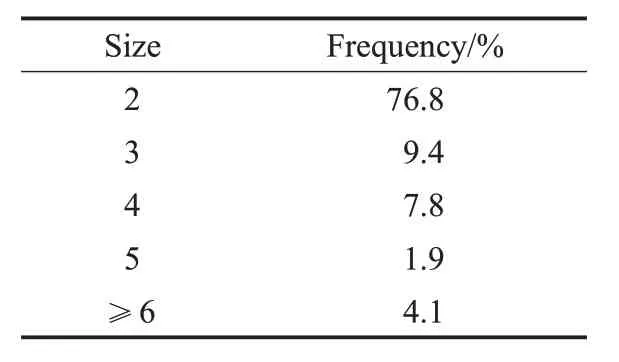
表5 克隆群代碼克隆的頻率分布
(2)生成的代碼注釋的質量
根據上一節中提到的評估標準,本文將自動生成的代碼注釋進行手動驗證,分為良好、中等和差三個等級,具體信息如表6所示。其中GD表示好的代碼注釋,FX代表可以修復的注釋,BD 表示壞的代碼注釋。從表中可以看出,得到的好的代碼注釋的數量不是平均分布的,每一款軟件得到的結果不同,本文分別計算了自動生成良好代碼注釋、中等注釋以及差的注釋的總和來表現生成代碼注釋的質量。本實驗總共生成75條代碼注釋,其中有21(28%)條代碼注釋是良好的,3(4%)條代碼注釋需要被修改,有51(68%)條代碼注釋是壞的。根據這些數據可以發現,需要被修改的代碼注釋很少。對于中等和差的代碼注釋,將在后續研究中進行總結,分析問題的來源,通過改進實驗進一步提高生成代碼注釋的質量。
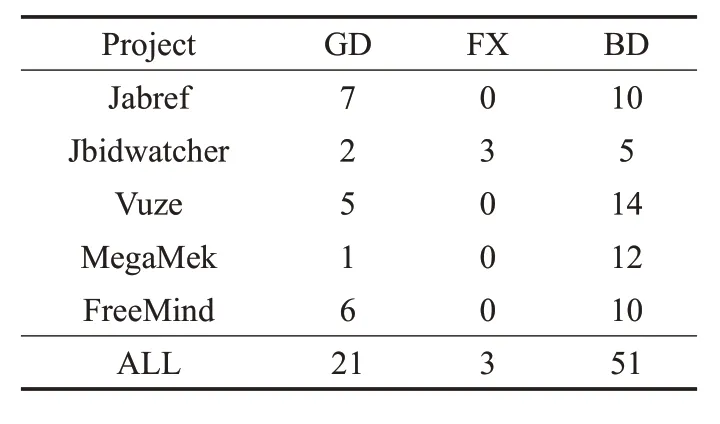
表6 生成注釋結果的質量
自動生成的代碼注釋中,部分注釋在目標軟件中是已經存在的,本實驗比較了已經存在的和自動生成的代碼注釋,人工評估這部分自動生成的代碼注釋與原有注釋比較,是否有改進,以便在后續實驗中進行改進。根據表2可知,5款目標軟件已有的注釋總數為26條,占自動生成代碼注釋總數(76)的34.7%。具體的比較信息如表7所示。其中Better表示生成的代碼注釋比現有的代碼注釋好,Similar表示生成的代碼注釋和現有的代碼注釋相似,Worse表示生成的代碼注釋比現有的代碼注釋差。

表7 自動生成代碼注釋VS現有的代碼注釋 %
由表可以看出,自動生成的代碼注釋相比原有的代碼注釋,在良好的代碼注釋中,3.5%的代碼注釋比原有的更好,25.4%的代碼注釋與原有的代碼注釋相似;在中等的代碼注釋中9.2%的注釋更差。可以看出,目標軟件已有的代碼注釋優于自動生成的代碼注釋,但有25.4%自動生成的代碼注釋與現有代碼相似,由來自表4的結果知,目標軟件中有65.3%(100%-34.7%)的注釋以前沒有,是新生成的。這意味著雖然自動生成的代碼注釋通常不如已有代碼注釋更貼近主題,由于生成注釋的工作還沒有很成熟,得到比原有更優的3.5%已經很不容易,在后續的實驗中會逐步提高,但為沒有代碼注釋的代碼段生成代碼注釋仍然是有益的。因此,本實驗對于自動生成代碼注釋是有價值的,為以后的工作奠定了一定的基礎。
對于自動生成的代碼注釋,在代碼注釋的相應代碼段沒有現有注釋的前提下,本文將評估出的良好的自動生成的代碼注釋報告給5位專家,讓他們也根據本文的評估標準對這些良好的代碼注釋再次進行評估。目前專家對兩款軟件的注釋給予了好評,即也將其視為是良好的代碼注釋,開發人員認為可以將其作為代碼最后的注釋。
4.4 對比實驗及分析
國內外通過使用注釋復用自動生成代碼注釋的方法較少,其中具有代表性的方法是文獻[6]。文獻[6]中Wong 等人通過基于Token 的方法進行克隆檢測,而本文使用Nicad基于文本的方法進行克隆檢測,中間對于代碼和注釋的處理方法也不同,因此僅對生成的代碼注釋的產量和質量進行對比。Wong等人實現了一個代碼注釋自動生成工具Clocom。本文研究與文獻[6]都使用從Github上下載的Java開源軟件,實驗的平臺均為操作系統Ubuntu 16.04 64位、8 GB內存。產量對比結果如表8所示。

表8 代碼注釋產量對比結果
本實驗在克隆檢測階段檢測出的克隆代碼類型比Clocom檢測出的類型多。實驗結果顯示,在這5款軟件中,本實驗總共生成75 條代碼注釋,Clocom 生成67 條代碼注釋,本實驗比Clocom多生成8條代碼注釋,在代碼注釋產量上高于Clocom。因此在這4個參數中,本實驗生成代碼注釋的產量相對Clocom較多。
然后對生成代碼注釋的質量進行了對比,如表9所示。通過表9 可以看出,在生成的代碼注釋中,對于每一款軟件,本實驗生成的代碼注釋的質量都比Clocom大約提高5個百分點,5款軟件中有4款在生成的注釋中良好的代碼注釋所占的比例比Clocom大,質量較高,有一款軟件良好的代碼注釋所占的比例略微低于Clocom。
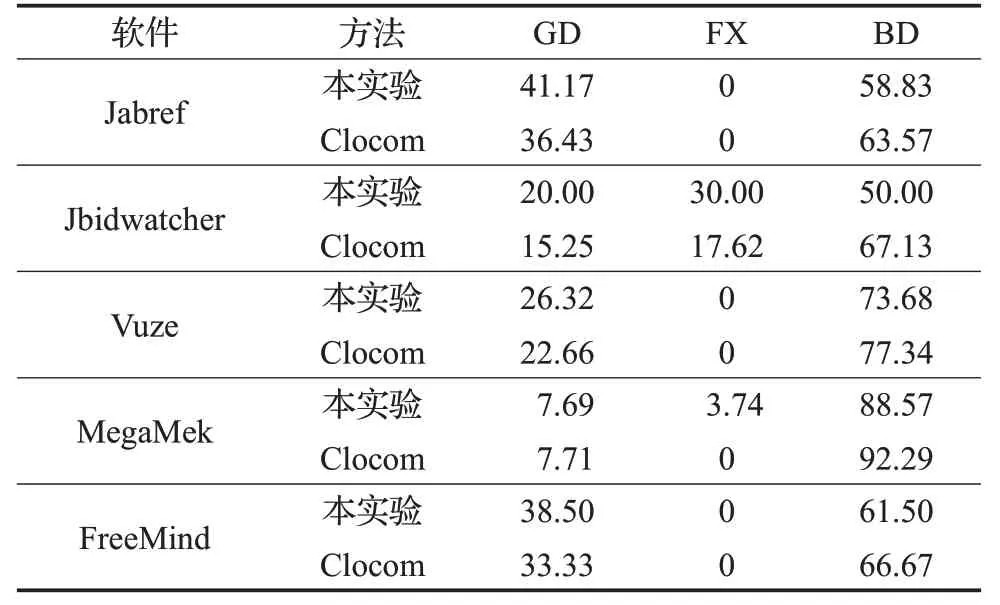
表9 生成代碼注釋質量對比結果 %
綜上,本實驗自動生成代碼注釋的產量比Clocom提高了約12%,質量也相比于Clocom提高了約5個百分點,均高于Clocom。
5 結束語
對于現在行業中代碼注釋數量稀少、質量不高等,導致軟件的可讀性和可維護性下降的問題,本文提出了一種自動生成代碼注釋的方法來提高注釋的數量和質量,幫助程序員提高代碼的可讀性和可理解性。本文首先通過克隆檢測工具Nicad檢測出開源項目軟件庫和目標代碼軟件庫之間的相似代碼即克隆代碼,根據代碼注釋提取算法通過Nicad 生成的XML 文件提取出克隆代碼;其次根據行號等提取出相對應的代碼注釋;然后對提取出的代碼和注釋經過一系列的啟發式規則,將克隆代碼和注釋精簡優化成所需要的代碼和注釋;最后將注釋與代碼匹配映射,自動為目標代碼生成注釋。
本文的研究工作還存在一些不足之處,例如檢測相似克隆代碼時用到的工具,雖然檢測的克隆代碼數很多,包含Type-1、Type-2和Type-3三種類型,但是時間復雜度會很高,這會影響到最終實驗結果的時間效率。在最后的評估中生成代碼注釋的質量也很低。本文將在后續的研究中考慮這些問題,為人們在該領域的研究提供更有力的數據,并奠定堅實的基礎。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
