基于Storm的局部放電信號集合經驗模態分解
2020-05-20 01:19:40朱永利
計算機工程與應用 2020年10期
楊 航,朱永利
華北電力大學 控制與計算機工程學院,河北 保定 071003
1 引言
近年來,隨著分布式計算框架的出現,數據流的實時處理技術逐漸在設備狀態監測領域得到應用。目前,電力生產行業正朝著智能化的方向發展,各種電力設備的監測數據以數據流的形式源源不斷地傳到遠程的監控中心。數據流有著產生速率快、數據量大的特點,因此往往難以存儲,必須及時處理。電力大數據的出現,對數據中心的計算能力提出了更高的要求。目前國內外對變壓器、容性設備、高壓斷路器等電力設備的在線監測都做了大量深入研究,監測量的范圍也越來越廣泛[1]。時序波形信號作為電力設備重要的監測量,為電力設備的狀態評估提供了重要依據。局部放電信號是時序波形信號的一種,它既是變壓器絕緣劣化的征兆,又是變壓器絕緣劣化的原因[2]。不同類型的局部放電對變壓器絕緣的破壞力有較大差異,因此有效分析和識別放電類型對設備的檢修及維護具有重要的指導意義。
現階段的電力設備在線監測平臺大多僅能接收監測裝置的“熟數據”,如一次設備絕緣放電電流波形信號須在監測裝置處被處理成放電次數、峰值和平均電流后方能上傳,這樣就丟失了大量的頻譜信息[3]。因此本文提出基于Storm 計算框架對監測到的原始時序信號進行特征提取,以保證信息的完整性。通過分析更完整的時序信號,可以對電力設備的運行狀況進行診斷。其中特征提取是故障診斷的重要前提,針對非平穩信號目前有很多特征提取的方法,常用的有傅里葉變換、小波變換、經驗模態分解(Empirical Mode Decomposition,EMD)等。其中EMD方法相對傳統的信號處理方法有著更好的分辨率和自適應性,被廣泛用于非平穩信號的分析。但EMD 存在著模態混疊和端點效應等問題,因此又有學者提出了改進的EMD 算法,即集合經驗模態分解(Ensemble Empirical Mode Decomposition,EEMD)。EEMD分解方法跟大多信號分解方法一樣,都是計算密集型的算法,在很多要求有較高實時性的信號處理場景下,傳統串行處理方法往往無法滿足需求,因此本文結合Storm分布式計算框架部署EEMD并行算法,從而實現流式波形信號的快速分析。
EMD 算法是由Huang 提出的,到目前為止已經有很多學者將該方法應用到非平穩信號的分析當中。EMD的應用領域非常廣泛,例如風速預測[4-6]、腦電波信號分析[7]、轉動機械的故障檢測[8-9]等。在電力設備的故障檢測中也有很多應用,但大多是單機環境下的信號分析方法,只有為數不多的基于Spark 和MapReduce 的并行處理方法。文獻[10]利用MapReduce 實現了并行EEMD分析,但是MapReduce適合離線的大批量數據處理,因此實時性較Storm 弱一些。文獻[11]利用EEMD方法在Spark平臺進行了不同長度的單個波形信號的并行分解,因為其讀寫是基于HDFS(Hadoop Distributed File System),所以對信號處理速度造成了一定影響。本文基于信號是否分段處理提出兩種并行策略,利用Storm分布式計算框架設計部署并行EEMD算法來進行信號的并行化分解,使用Redis作數據源,并針對信號的流式處理給出了優化策略,以滿足實際的應用需求。
2 EEMD算法基本理論
2.1 EMD算法
經驗模態分解[12]是由Huang 提出的一種自適應的信號分解算法,其可將一個復雜信號分解為一組單分量信號,這些單分量信號叫作本征模函數(Intrinsic Mode Function,IMF)。其中,IMF要滿足如下兩個條件:
(1)在整個數據段內,極值點的個數和過零點的個數必須相等或相差最多不能超過一個。
(2)在任意時刻,由局部極大值點形成的上包絡線和由局部極小值點形成的下包絡線的平均值為零,即上、下包絡線相對于時間軸局部對稱。
EMD 算法獲取IMF 是通過不斷篩選得到的,最先得到的是頻率較大的信號分量。其算法的步驟如圖1所示。
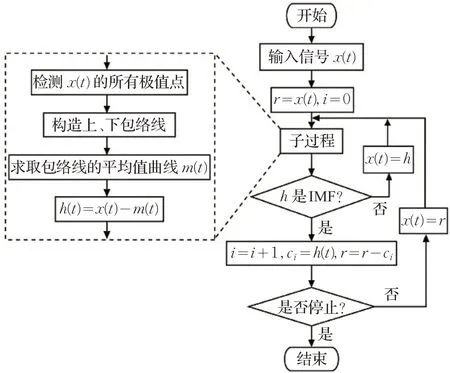
圖1 EMD算法流程圖
2.2 EEMD算法
模態混疊最先是在含有間斷信號的分解中發現的,其指的是在一個本征模函數(IMF)中包含了多種頻率的分量,或者相近頻率的成分分散在不同的IMF 中,導致分解結果失去意義。因此,為了改善EMD 的模態混疊問題,Wu 和Huang 提出了基于噪聲輔助數據分析的方法——集合經驗模態分解(EEMD)。EEMD 利用白噪聲零均值[13]的特性來抑制噪聲信號的影響,其通過對原始信號加入不同的白噪聲進行EMD 分解,最后把獲得的全體IMF分別按層求均值來抵消噪聲,從而讓真實信號凸顯出來。雖然EEMD 是EMD 的改進,繼承了原有的信號自適應分解、無需選擇基函數的優點,且能較好地處理模態混疊的問題,但是對于所加白噪聲的幅值大小、信號的染噪次數等參數往往需要根據具體的使用場景人為經驗確定。根據文獻[14],當添加的噪聲幅值較大時,為了減少噪聲對結果的誤差影響,染噪次數一般設置得較大。這就造成了EEMD 算法的運算量大幅增加,普通的串行EEMD算法將無法滿足實際應用中對處理速度的要求,因此考慮使用集群來并行化EEMD算法以提高處理效率。
3 Storm框架介紹
Storm 是一個由Twitter 開源的分布式實時計算框架,其主要用于流數據的處理,彌補了Hadoop批處理無法實時處理的不足,具有健壯性、容錯性、動態調整并行度等特性。Storm 編程相對簡單,可以使用多種編程語言。Storm 的實時性體現在可以支持納秒級的時延計算,比SparkStreaming 這種基于時間窗口“微批”處理的準實時框架具有更低的延遲[15]。Storm在數據的實時在線處理方面有著獨特的優勢,主要用于日志分析、大數據實時統計、在線學習、持續計算和分布式RPC(Remote Procedure Call)等。
Storm 是一個主從架構的計算框架,任務通過運行在Nimbus 守護進程上的Master 節點分發給運行在Supervisor 守護進程上的 Worker 節點。在 Storm 中,任務被封裝成Topology,每一個工作節點上運行著拓撲的一部分。一個Topology 一般由若干Spout 和Bolt 組成,不同的組件之間通過數據流Stream 產生聯系,其中Spout 是消息的生產者,其可以從不同的數據源讀取數據,比如消息中間件Kafka、RocketMq,也支持讀取文件、數據庫和網絡數據等[16]。Bolt 是處理數據的組件,即從上一級組件(Spout 或Bolt)獲取Tuple(Stream 的最小組成單元),經過處理加工生成新的Tuple傳遞給下一級組件。上下級組件通過訂閱的方式決定數據的流向,常用的分組策略有以下幾種:
(1)Shuffle Grouping:隨機分組,通過輪詢的方式,將Tuple均分給bolt task。
(2)Fields Grouping:按字段分組,將具有相同field-Name的Tuple分給同一個Bolt組件。
(3)All Grouping:廣播發送,對于每一個Tuple,所有Bolt組件都會收到。
(4)Global Grouping:全局分組,把上游組件產生的Tuple 分配給同一個 bolt task 去處理,一般為 task id 最低的task。
Topology的總體結構如圖2所示。
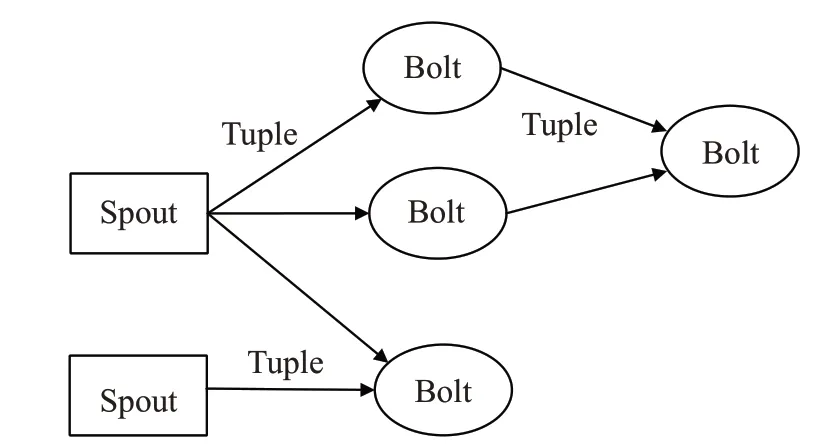
圖2 Storm計算框架示例
4 基于Storm的EEMD并行分解算法
EEMD 算法是通過添加不同的白噪聲形成不同的染噪信號,不同的染噪信號分別進行EMD分解,最終匯總求均值。染噪后的EMD分解過程是一個可以并行的階段,因此并行化EEMD 算法可以有兩種選擇,其一是直接將EMD 分解過程并行化,其二是先將原始信號分段再過程并行化。為了方便描述,把前者在Storm平臺上并行化的算法簡稱Spp-EEMD,后者簡稱Ssp-EEMD。下面詳細分析這兩種并行化策略。
4.1 Spp-EEMD
EEMD 的算法流程如圖3,可以看出原始信號每次添加不同白噪聲再進行EMD分解的過程是互不影響的獨立過程。
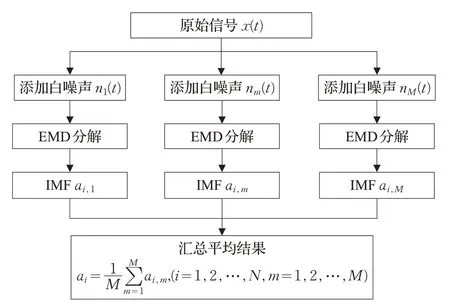
圖3 EEMD算法流程圖
顯然,此種分解方法的Storm拓撲圖如圖4,染噪過程和EMD分解過程都是并行的。分解步驟如下:
(1)Spout 從Redis 中讀取原始信號,封裝成Tuple,發送到下一級。
(2)每一個 AddNoise 組件通過 All Grouping 的分組策略從Spout 獲取原始信號,然后各自添加白噪聲生成新的染噪信號,生成新的Tuple。
(3)EMD分解組件訂閱AddNoise組件的數據流,通過Shuffle Grouping 分組方式使每個EMD 組件均分地處理上級組件發來的Tuple,保證EMD組件并行地分解染噪信號。每個EMD 組件生成的Tuple 為(id,arr),其中arr是一個二維數組[i][j](i表示篩選出IMF的個數,j表示信號長度)。
(4)Average 組件通過Global Grouping 方式匯總所有EMD,即計算每層IMF的平均值,最后可以將結果寫入Redis或持久化到數據庫,用于后續的特征提取。

圖4 并行Spp-EEMD的拓撲結構
4.2 Ssp-EEMD
基于分段并行的EEMD 分解是比Spp-EEMD 更細粒度的并行算法,其通過對原始信號進行分段,然后對子段信號進行Spp-EEMD分解,最終將不同子段對應層級的IMF合并即可。此種方法的并行度雖然提高了,但是信號的分段數的增加必然帶來更多的端點效應。常用的解決端點效應的方法有鏡像延拓法、極值點對稱延拓、多項式擬合延拓、匹配延拓等。其中,極值點對稱延拓算法較為簡單,在鏡像延拓的基礎上進行了端點是否極值點的判斷,可以提高準確性,同時只需要將原有的極值點向外延拓幾個周期即可,顯著減少了運算量,可以保證在Storm中較低的處理時延。
Ssp-EEMD 算法是基于Spp-EEMD 的,拓撲結構如圖5,可以看出Spp-EEMD作為Ssp-EEMD的子過程,用于處理原始信號切分后的子段。
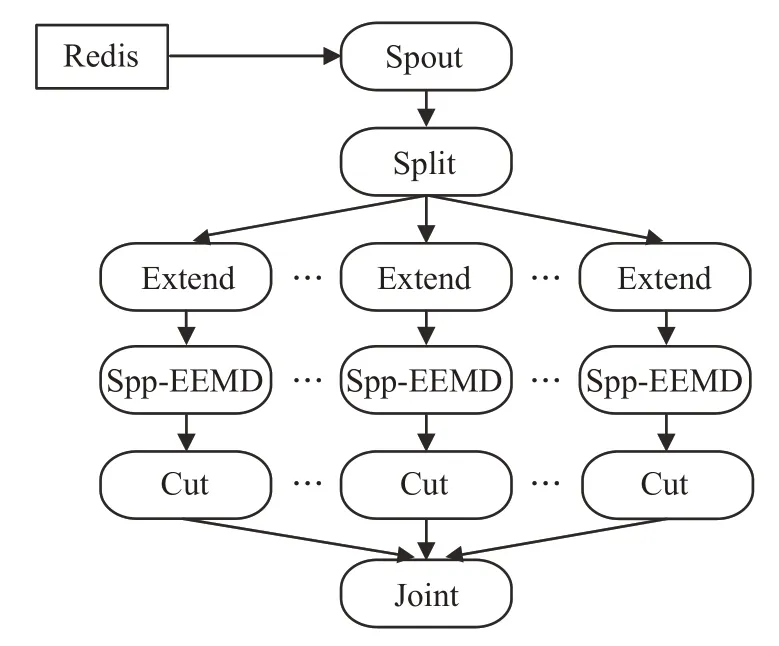
圖5 Ssp-EEMD算法拓撲圖
Ssp-EEMD進一步提高了EEMD算法的并行度,但是更細粒度的數據劃分可能導致Storm 節點間通信量的增加。此種方法更適合信號長度較長的情況,分解步驟如下:
(1)Spout 組件讀取Redis 中的原始信號x,發送至Split組件。
(2)Split 組件將原始信號劃分為等長數據段,共n段,為了保證最終Joint組件合并時信號的有序性,Splite發出的Tuple 應為(i,arr),其中一維數組arr 為信號子段,Tuple 的id 值i為該子段在原始信號中的相對位置序號,i=1,2,…,n。

圖6 原始信號分段處理示意圖
(3)Extend 為延拓組件,采用極值點延拓的處理方式減少端點效應的影響。通過Shuffle Grouping的分組方式,保證裁切后的子段平均分配到不同的Extend節點處理。
(4)進入Spp-EEMD 的處理過程,該階段需要特別注意的是Average過程。
①這里以原始信號的第一個子段為例,如圖6,子段1 經過延拓和染噪過程形成子段1 的一組染噪信號arr_i(i=1,2,…,m),對每個染噪信號arr_i進行EMD分解,生成一組IMF存儲在二維數組imf_arr_i中。
②EMD分解過后,將imf_arr_i封裝為Tuple發出,由于Ssp-EEMD 將原始信號分為多個子段,使用Spp-EEM 中的單個Average 組件策略已經滿足不了算法的并發性能。因此,Ssp-EEMD 算法需設置多個Average組件同時計算不同子段產生的IMF的均值。Average組件的分組策略應為Fields Grouping,以保證同一個子段的 imf_arr_i(i=1,2,…,m) 被同一個Average 組件接收,Average 最終產生的 Tuple 為 (a,imf_arr),其中a為子段序號,二維數組imf_arr 為該子段經EEMD 分解產生的一組IMF。
(5)Spp-EEMD處理完之后,Cut組件可采用Shuffle Grouping 隨機分組方式對imf_arr 兩端進行裁切,保證IMF與子段長度相同。
(6)Joint 組件采用 Global Grouping 方式對不同子段的IMF按子段序號進行拼接,最終輸出一個二維數組Array,維數為m×L,其中m是IMF 的層數,L是IMF信號的長度,與原始信號保持一致。該Joint 過程是串行過程,至此信號x的EEMD處理結束。
4.3 并行EEMD的數據流處理的優化策略
上述兩種基于Storm 的并行EEMD 算法都是針對單次讀入一批數據點作為原始信號進行EEMD 分解,Ssp-EEMD的Average組件和Spp-EEMD中的Joint組件等這些都是并行度為1 的匯總型計算組件。在Storm中,并行度為1意味著計算過程只在集群中的一個節點中運行,其他節點會因為空閑造成資源浪費。然而在實際生產環境中,Storm的Spout組件會連續不斷地從消息隊列中拉取待分解原始信號段進行處理,而不是等待一個原始信號段處理完畢才開始拉取另一個。因此,拓撲中某一時間點就有多個原始信號在同時分解,在設置匯總型組件時就可以設置多并發,用來同時匯總不同批次原始信號的分解結果,以提高系統的吞吐量。
在解決了并行度的問題后,還需考慮集群的計算能力。如果Spout 組件無限制地讀入數據、發送Tuple,也就是數據發送得快,處理得慢,會導致大量Tuple 堆積,造成線程阻塞,嚴重的話可能導致系統隊列溢出。常見的方法就是設置Spout 每讀入一個數據就休眠一段時間,通過在nextTuple()的方法體中設置Thread.sleep(long millis)即可。還有一種方法就是通過設置Storm的maxSpoutPending屬性值為k,即spout task上面最多可以有k個沒有處理完的Tuple(沒有ack/failed)。當未處理完成的Tuple數量達到k時,Spout task將不再調用nextTuple繼續發送數據。設置該屬性是通過在main方法中調用如下代碼:
Config conf=new Config();
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING,k);其中conf 為Storm 的配置對象,用來配置Storm 集群和Storm 拓撲上所有可能的配置的常量。在實際應用中,如果k值過小,則會導致某些工作節點算力的浪費,因此需要根據集群的計算能力與任務的復雜度設置合適的k值,才可以保障集群的高效運行。
5 實驗設計與結果分析
5.1 實驗環境
為了驗證第3 章提出的并行EEMD 分解算法的效果,在集群環境下搭建Storm集群,各節點的配置如表1。配置環境變量,并且安裝完Storm套件后,同時安裝Redis充當實驗數據源。

表1 Storm集群配置表
5.2 實驗方案設計
Storm 的多語言協議支持各種編程語言去實現Spout 和Bolt 組件,本實驗中采用比較常見的Java 去實現上文中介紹的兩種并行EEMD 分解算法以及Storm的處理邏輯,然后根據運行結果分析比較兩種算法。
實驗數據來自幾種常見的放電模型收集到的數據,信號的采集周期與工頻周期一致,采樣頻率5 MHz,采集頻帶為40~300 kHz。實驗中為了模擬數據流,預先根據仿真實驗需要的信號長度將采集到的數據以String類型存放在Redis中。Spout組件讀取Redis中的數據并利用Java自帶的split()函數進行字符串的切分,然后通過類型轉換為float 數組。但是由于Tuple 的value 默認只支持Byte 數組,因此需要自定義一個數據傳輸類將float數組封裝進去,然后在配置文件storm.yaml注冊該類聲明序列化,這樣就可以實現在task之間傳遞自定義的數據類型。
為了方便比較兩種并行策略的分解速度,統一將染噪次數Ne設置為50,同時將IMF 的篩選次數設為10,以避免篩選IMF 的停止準則對分解速度造成影響。對于分段并行的Ssp-EEMD算法,設置分段數為10。在批量處理實驗中,通過設置maxSpoutPending以防止Storm系統隊列溢出。maxSpoutPending 的值通過實驗選取,之所以沒有使用線程休眠的方式是由于集群的處理能力并不是恒定的,可能受到外界突發狀況的影響,當某一階段的Bolt 組件出現數據擁堵時,Spout 的數據發送速度不變會導致擁塞的惡化,最終使程序無法正常運行,設置maxSpoutPending的方法可以有效避免該問題。
為了更好地利用CPU 資源,需要根據任務的復雜程度設置組件的并行度。同時考慮到Storm 集群自動負載均衡的特點,需要將并行度設為工作節點個數的倍數,即5 的整數倍。在本實驗中對于染噪、延拓這類復雜度較低的任務,將組件的并行度設為10。而對于較為復雜的EMD 分解組件,設置并行度為30。組件的并行度需要在main方法中設置,以Spp-EEMD為例,代碼如下:
TopologyBuilder tb=new TopologyBuilder();
tb.setSpout("spout",new Spout(),2);//并行度為2
tb.setBolt("add_noise_bolt",new AddNoiseBolt(),10).allGrouping("spout");//染噪
tb.setBolt("emd_bolt",new EMDBolt(),30).shuffleGrouping("add_noise_bolt");//EMD分解
tb.setBolt("average_bolt",new AverageBolt(),10).global-Grouping("emd_bolt");//求IMF均值
Config conf=new Config();//創建拓撲配置
conf.setNumWorkers(20);//設置工作進程數量
在本實驗中,共設置了20個Worker(工作進程),一個Worker 就是一個jvm 虛擬機進程,組件并行度10 和30即為Executor(線程)的個數。Executor運行在Worker中,默認情況下一個Executor 中運行一個Task,三者的關系如圖7所示。Storm的負載均衡機制會將Worker和Executor 平均地分配給集群中的Supervisor 工作節點,使每個節點的計算資源都得到充分利用。
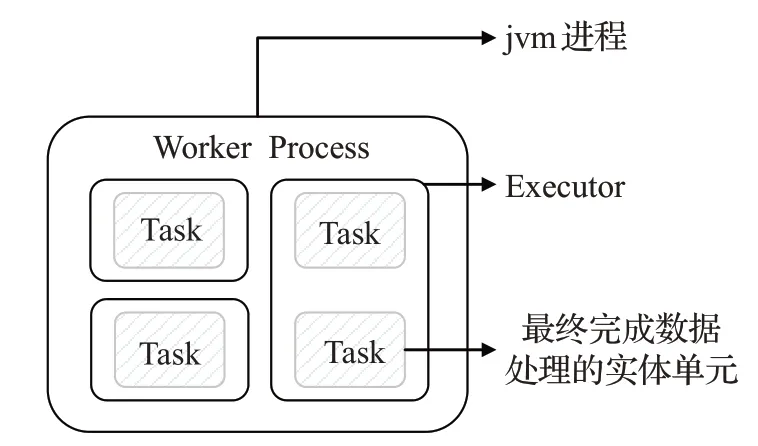
圖7 Worker、Executor和Task之間的關系
5.3 實驗結果與分析
4.3 節提到通過設置maxSpoutPending 值來提高并行EEMD 算法對數據流處理的效率,但是maxSpout-Pending 需要根據Storm 集群的算力進行合理的設置。圖8 是在待處理數據為200 條,數據長度為10 000 的條件下記錄的不同maxSpoutPending對應的處理時間。從圖中可以看出,兩種算法分別在50 和60 左右取得最優值。在最優值的左側因為未充分利用所有的算力,所以會隨著maxSpoutPending的增加而處理時間變短。在最優值的右側由于集群處理能力和內存的限制,導致線程擁塞,處理速度反而變慢,當達到150時,兩種算法由于系統隊列溢出都無法正常運行。因此兩種算法的max-SpoutPending值取其各自的最優值,即可最大程度發揮算法的處理能力。與此同時,由于集群的處理能力是固定不變的,當信號長度成倍數增加時,maxSpoutPending值也應減少相應的倍數,例如信號長度為20 000 時,兩種算法的maxSpoutPending值應分別設為25和30。
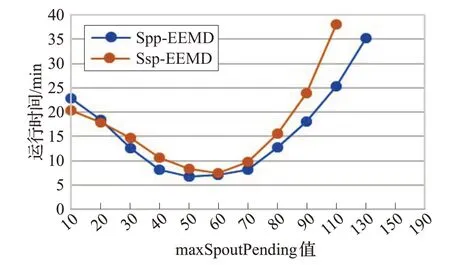
圖8 maxSpoutPending值對批量處理的影響
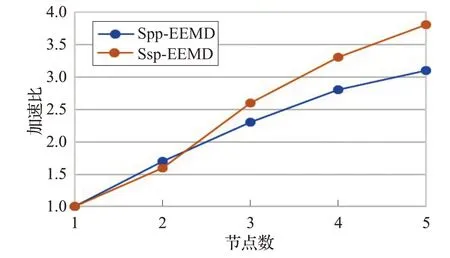
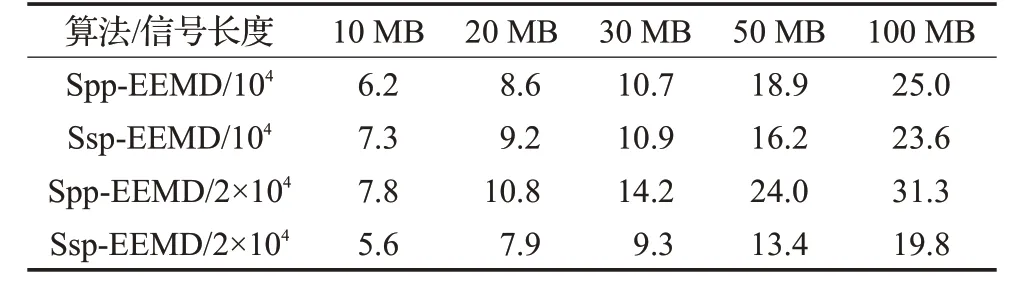
圖9 記錄了幾種方法在分解不同長度信號時所花費的時間。其中標注為Java的曲線是在JVM(Java Virtual Machine)下執行的,為了充分利用多CPU 核心,EMD 分解階段采用的是 Java 的 ThreadPoolExecutor 線程池技術來實現多并發。Local Mode 為Storm 在本地模式下執行(即單點執行)。可以看出兩者的執行時間比較相近,Local Mode由于Storm的ack機制和tuple發送機制等,時間比Java 方式稍長一點。Spp-EEMD 和Ssp-EEMD 兩種方法的時間曲線存在交點k(15 圖9 數據運行時間 圖10 為兩種算法在批量處理中的加速比,并行算法的加速比最優的情況下是隨著集群節點數的增加呈線性變化。但考慮到Storm 集群間的通信協調和序列化的Tuple 在節點間傳遞花費一些時間,因此實際效率會低一些。Ssp-EEMD算法具有更高的并行度,因此具有較Spp-EEMD更高的加速比,更適合做集群的擴展。 圖10 兩種并行算法加速比 表2 是兩種算法分別以10 000 和20 000 點為單條數據長度處理不同大小的數據集所用的時間對比。在信號長度為10 000的情況下,基于分段的Ssp-EEMD算法在處理30 MB 以上大小的數據集時有較小的時間優勢,但在20 000 信號長度下Ssp-EEMD 算法明顯優于Spp-EEMD。造成這種現象的主要原因是當信號較長時,EMD分解組件因其本身算法復雜度較大,花費時間較長,造成數據流擁堵于該階段,而其他組件則處于相對閑置狀態。Ssp-EEMD 算法通過分段處理將信號變短,雖然比Spp-EEMD增加了子信號端點效應處理的時間花費,但是較短信號在EMD 分解階段花費的時間也相對較少,緩解了數據流的擁塞狀況。因此在信號的批量處理中,數據流在Ssp-EEMD的整個處理流程中分布較均勻,各級組件的線程都處于運行態,CPU的利用率比Spp-EEMD 更高,使得基于分段的并行算法Ssp-EEMD在批量處理場景下處理長信號有更大的吞吐量。 表2 不同EEMD批量執行時長對比 min 大數據技術的發展使時序信號的在線快速處理成為可能,本文基于Storm提出了兩種并行EEMD分解算法。通過設置Bolt組件的并行度,將待處理數據封裝為Tuple 發送給處理組件,實現EEMD 算法的并行求解。通過實驗驗證了兩種并行分解算法的可用性以及各自適用的場景,在處理單個信號時,基于分段的Ssp-EEMD信號分解算法比Spp-EEMD 算法有更高的并行度和更好的加速比,在處理長信號時效率更高,而Spp-EEMD更適合10 000以內短信號的處理。在批量處理場景下,信號較長或者是數據量較大都推薦使用Ssp-EEMD 算法,該算法吞吐量大,處理速度更快。但是Ssp-EEMD會由于信號分段引入端點效應,如果要求準確率,則只能使用Spp-EEMD 分解方式。較傳統的串行EEMD 算法,兩種基于Storm的并行EEMD算法在處理速度上都具有較大的優勢,且可以通過擴展Storm的集群規模來進一步提升處理速度。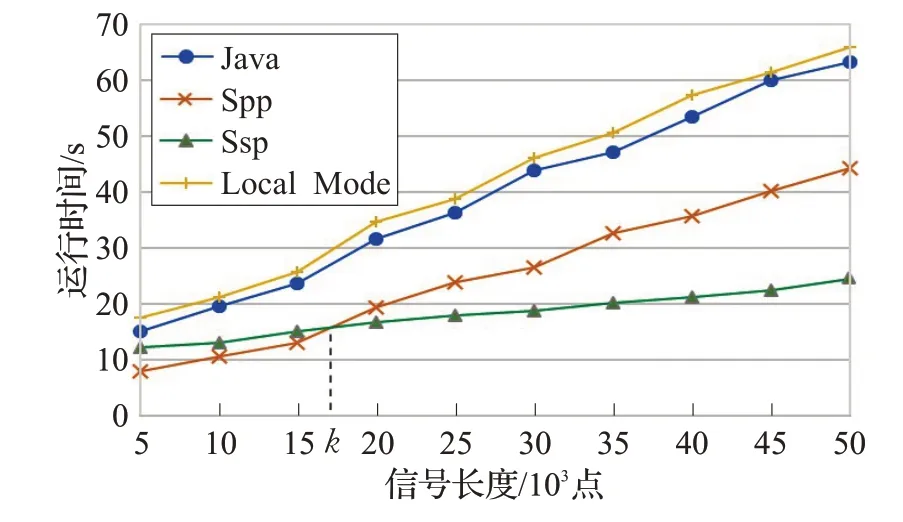
6 結束語
猜你喜歡
少先隊活動(2021年4期)2021-07-23 01:46:22
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
攝影之友(影像視覺)(2019年3期)2019-03-30 01:36:50
中國生殖健康(2019年3期)2019-02-01 06:12:26
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
醫學教育管理(2015年3期)2015-12-01 06:43:16
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
中國艦船研究(2014年5期)2014-05-14 06:43:09
