基于K-SVD算法和組合字典的語音信號清濁音判決研究
2020-05-20 15:05:18王蓮子李鐘曉陳倩倩莊曉東
王蓮子 李鐘曉 陳倩倩 莊曉東


摘要:針對語音中清音和濁音特性的不同,本文提出了一種新的清濁音判別方法,利用K奇異值分解(K singular value decomposition, KSVD),分別對數(shù)據(jù)樣本中的清音和濁音進(jìn)行字典學(xué)習(xí),訓(xùn)練出符合樣本信號特性的濁音字典和清音字典,將多個(gè)單清音字典組合成組合清音字典,多個(gè)單濁音字典組合成組合濁音字典,并將待測信號在組合濁音字典和組合清音字典上進(jìn)行稀疏表示,通過對比其系數(shù)的稀疏性來判別清濁音。研究結(jié)果表明,在相同條件下,與傳統(tǒng)的清濁音判別方法相比,基于組合字典的判別方法對于多音素的清濁音判決具有更加準(zhǔn)確的判決結(jié)果。該研究對語音識別和語音編碼具有重要作用。
關(guān)鍵詞:語音判別; 字典學(xué)習(xí); 稀疏表示; 組合字典
中圖分類號: TP391.42; TN912.34文獻(xiàn)標(biāo)識碼: A
語音是由氣流激勵(lì)聲道從嘴唇或鼻孔輻射出來而產(chǎn)生的。根據(jù)聲帶是否振動,發(fā)音可分為濁音和清音[1]。濁音和清音有明顯的區(qū)別,濁音具有周期信號的特征,而清音則具有隨機(jī)噪聲的特征;濁音在頻域上具有共振峰結(jié)構(gòu),其能量主要集中在低頻帶,清音的振幅值相對較小,在時(shí)域和頻域沒有明顯的規(guī)律性。清音和濁音的正確判斷在語音識別、語音合成、語音編碼中具有重要作用[2]。傳統(tǒng)的清濁音區(qū)分方法有:短時(shí)能量法、短時(shí)自相關(guān)函數(shù)法和過零點(diǎn)法等。由于實(shí)際語音常有連讀以及單音素發(fā)音過短的情況,現(xiàn)有的清濁音判斷方法也會出現(xiàn)判斷不準(zhǔn)確的情況。2006年,D. L. Donoho等人[34]提出了壓縮感知,進(jìn)一步促進(jìn)了稀疏表示理論的發(fā)展,使稀疏表示由最初的數(shù)據(jù)壓縮推廣到眾多領(lǐng)域中,并在各方面均取得了較好的應(yīng)用效果。信號需要在字典上進(jìn)行稀疏表示,合適的字典直接影響信號的稀疏表示效果。因此,本研究將字典學(xué)習(xí)和稀疏表示與清濁音判斷相結(jié)合,提出了一種基于組合字典上稀疏表示的清濁音判別方法,實(shí)驗(yàn)數(shù)據(jù)表明,該方法在多音素的清濁音判決上具有較高的準(zhǔn)確率。該研究為語音信號的判決提供了理論基礎(chǔ)。
1稀疏表示和字典學(xué)習(xí)方法
1.1信號的稀疏表示
稀疏表示是信號在一組特定的向量組上進(jìn)行線性分解[21],其線性分解的系數(shù)必須盡可能的稀疏。稀疏表示的求解模型[57]為
式中,y表示信號分幀后的矩陣,為n行m列;D表示字典,為n行s列矩陣;di為D的一列原子;C為稀疏系數(shù),C的每一列為語音信號矩陣每一列在字典D上的稀疏系數(shù)向量。
正交匹配追蹤(orthogonal matching pursuit,OMP)是一種貪婪算法,它是匹配追蹤(matching pursuit,MP)的一種改進(jìn)算法,OMP算法中的當(dāng)前殘差與所有被選入的原子正交。OMP算法的具體模型[8]為
式中,e是每次迭代后的殘差;dr0是與索引集合中對應(yīng)的原子數(shù);r0是下標(biāo)索引集。OMP算法的具體流程[911]為
OMP算法整個(gè)稀疏求解過程的迭代次數(shù)減少,收斂速度比MP算法要快,且OMP算法結(jié)合了基追蹤(basis pursuit,BP)算法和MP算法的優(yōu)點(diǎn)[12],在保證信號精度的同時(shí),也可以相應(yīng)的提高運(yùn)算效率。因此,本研究選擇OMP算法作為稀疏求解方法。
1.2K-SVD字典學(xué)習(xí)算法
字典的構(gòu)造一般分固定字典和學(xué)習(xí)字典。字典學(xué)習(xí)就是對于某一類特定的信號進(jìn)行學(xué)習(xí),訓(xùn)練一組符合樣本信號結(jié)構(gòu)特性的過完備向量,并使該信號能夠在此字典進(jìn)行稀疏表示。字典學(xué)習(xí)一般分為稀疏編碼階段和字典更新階段。常見的字典學(xué)習(xí)算法有K-SVD算法和最優(yōu)方向(method of optimal directions,MOD)算法。K-SVD算法是一種經(jīng)典的字典學(xué)習(xí)方法[1316]。K-SVD算法目標(biāo)優(yōu)化函數(shù)為
K-SVD算法的具體流程[1720]如下:
設(shè)信號矩陣為y(n×m),初始字典為D0(n×s),t=1,誤差為ε,K為稀疏度。whileC0
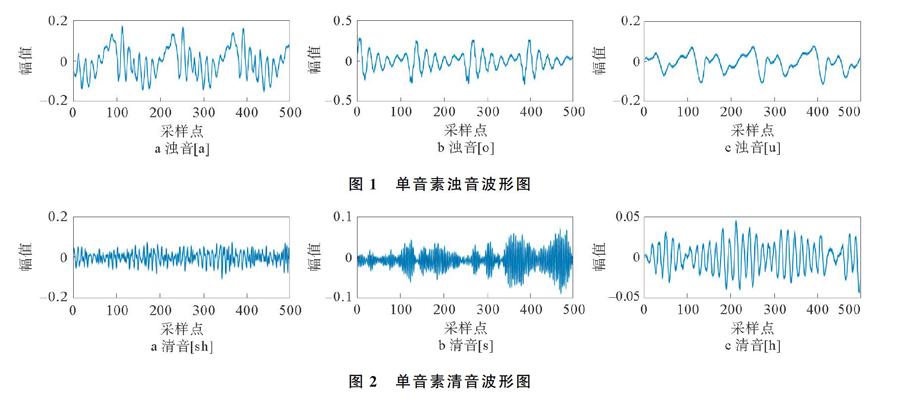
利用稀疏表示算法,通過字典D得到稀疏系數(shù),對D進(jìn)行逐列更新:找到dt,t=1,…,s對應(yīng)的稀疏表示稀疏Ct中非零元的下標(biāo),并將下標(biāo)放入索引集合w中。w=j|C(t,j)≠0,1 MOD算法構(gòu)造簡單,但計(jì)算復(fù)雜,并沒有得到廣泛地應(yīng)用。K-SVD算法是對MOD算法的一種改進(jìn),其計(jì)算速度快于MOD算法[18]。因此,本研究選擇K-SVD算法作為字典學(xué)習(xí)算法。 2基于組合字典的清濁音判決的實(shí)現(xiàn) 2.1基于組合字典的單音素清濁音判決 本研究選擇OMP算法來實(shí)現(xiàn)稀疏求解,并利用K-SVD算法對清音樣本和濁音樣本進(jìn)行字典學(xué)習(xí)。通過字典學(xué)習(xí),訓(xùn)練出單個(gè)清音字典和濁音字典,將多個(gè)清音字典組合起來構(gòu)成組合清音字典,多個(gè)濁音字典組合起來構(gòu)成組合濁音字典,將待測信號分別通過組合濁音字典和組合清音字典進(jìn)行稀疏表示,得到兩組不同的稀疏系數(shù),比較兩個(gè)組合字典下稀疏系數(shù)的稀疏性,進(jìn)而判別出清濁音。實(shí)驗(yàn)主要分3個(gè)階段:即組合字典訓(xùn)練階段、稀疏表示階段及清濁音判別階段。 實(shí)驗(yàn)的運(yùn)行環(huán)境為:Windows 7和matlab2014a,研究所采集的樣本數(shù)據(jù)以及測試數(shù)據(jù)是在安靜的環(huán)境下錄制,采樣頻率為16 kHz。語音幀長為128 ms,因?yàn)閱我粢羲剌^短,為了獲取數(shù)量較多的幀數(shù),選取幀移為32 ms。 在組合字典訓(xùn)練階段中,選取英文單詞中常見的單音素,清音音素有[s],[],[h]等,濁音音素有[a],[o],[u],[i:],[e]。先利用K-SVD算法對以上單音素進(jìn)行字典訓(xùn)練,以清音[s],[],[h]為樣本,訓(xùn)練出相應(yīng)的Ds清音字典、Dsh清音字典和Dh清音字典,并將上述幾個(gè)清音字典組合起來,構(gòu)成組合清音字典Dunvoiced=[Ds,…Dh]。同時(shí),以濁音[a],[o],[u],[i:],[e]為樣本,訓(xùn)練出相應(yīng)的Da濁音字典、Do濁音字典和Du濁音字典等多個(gè)濁音字典,并將其組合起來,構(gòu)成組合濁音字典Dvoiced=[Da,Do,…Du]。在稀疏表示階段,將待測信號通過OMP算法分別在Dunvoiced和Dvoiced上稀疏表示,得到不同的稀疏表示系數(shù),即:組合清音字典系數(shù)Sunvoiced和組合濁音字典系數(shù)Svoiced。 在清濁音的判決階段,以幀為單位,比較每一幀Sunvoiced和Svoiced稀疏性的強(qiáng)弱來判決當(dāng)前時(shí)刻的清濁音。在進(jìn)行比較之前,需先計(jì)算每一幀Sunvoiced和Svoiced的稀疏性,稀疏性是指稀疏系數(shù)的l0范數(shù),因?yàn)閘0范數(shù)計(jì)算繁瑣,本研究為了獲取比較準(zhǔn)確的結(jié)果和較低的計(jì)算復(fù)雜度,選擇稀疏系數(shù)的l05范數(shù)作為稀疏性比較的依據(jù)。Sunvoiced和Svoiced稀疏性的強(qiáng)弱,則是由比較Sunvoiced和Svoiced的l05范數(shù)的大小來確定,l05范數(shù)較小的系數(shù)視為稀疏性較強(qiáng)。當(dāng)Svoiced的稀疏性強(qiáng)于Sunvoiced的稀疏性時(shí),此幀判決為濁音;當(dāng)Sunvoiced的稀疏性強(qiáng)于Svoiced的稀疏性時(shí),此幀判決為清音。由于實(shí)際語音發(fā)音的復(fù)雜性,一些幀的稀疏系數(shù)不足以準(zhǔn)確區(qū)分濁音和清音,為了解決這一問題,在進(jìn)行Sunvoiced和Svoiced的稀疏性比較之前,需對每一幀稀疏系數(shù)向量的l05范數(shù)進(jìn)行中值濾波。為了驗(yàn)證本方法的有效性,先對單音素語音進(jìn)行判決測試,單音素濁音波形圖如圖1所示,單音素清音波形圖如圖2所示,單音素濁音判決結(jié)果如圖3所示,單音素清音判決結(jié)果如圖4所示。 圖4單音素清音判決結(jié)果由圖1和圖2可以看出,濁音與清音具有明顯不同的結(jié)構(gòu),其中濁音表現(xiàn)有周期信號的特性,振幅較大,而清音的特性與隨機(jī)噪聲相似,振幅值較小;由圖3和圖4可以看出,基于組合字典的稀疏表示方法,對單音素的清濁音識別是有效的。當(dāng)Svoiced的l05范數(shù)小于Sunvoiced的l05范數(shù)時(shí),此幀判決為濁音。由圖3還可以看出,[a],[o],[u]這3個(gè)濁音音素Svoiced的l05范數(shù)均小于Sunvoiced的l05范數(shù),即組合濁音字典上系數(shù)的稀疏性強(qiáng)于組合清音字典上系數(shù)的稀疏性。當(dāng)Sunvoiced的l05范數(shù)小于Svoiced的l05范數(shù)時(shí),此幀判決為清音;由圖4還可以看出,[sh],[s],[h]這3個(gè)清音音素的Sunvoiced的l05范數(shù)均小于Svoiced的l05范數(shù),即組合清音字典上系數(shù)的稀疏性比組合濁音字典上系數(shù)的稀疏性強(qiáng)。 為進(jìn)一步證明基于組合字典清濁音判決的有效性,現(xiàn)將清濁音判決方法應(yīng)用于多音素單詞中,并將判決結(jié)果與傳統(tǒng)的清濁音判決方法作比較。在判決過程中,為了更加直觀的觀察判決結(jié)果,每一幀的判決結(jié)果用0或者1表示,其中1代表此幀判決為清音,0代表此幀判決為濁音。分別對[statistics],[face],[show]這3個(gè)語音單詞進(jìn)行分割實(shí)驗(yàn),其多音素的語音信號波形及其判決結(jié)果如圖5~圖7所示。 由圖5可以看出,開始時(shí)語音發(fā)音是清音[s]和[t],在判決結(jié)果圖中判決為1;當(dāng)濁音[ˊ]發(fā)音時(shí),Svoiced的稀疏性強(qiáng)于Sunvoiced,此時(shí)判決結(jié)果為0。清音[t]發(fā)音時(shí),Svoiced的稀疏性弱于Sunvoiced,判決結(jié)果為1;當(dāng)濁音[]發(fā)音時(shí),判決結(jié)果又一次為0;由圖6可以看出,開始時(shí)語音發(fā)音為清音[f],在判決結(jié)果圖中判決為1;當(dāng)濁音[e]發(fā)音時(shí),此時(shí)判決結(jié)果為0;清音[s]判決結(jié)果為1。由圖7可以看出,開始時(shí)語音發(fā)音為清音[],判決結(jié)果為1,當(dāng)濁音[]發(fā)音時(shí),其判決結(jié)果為0。由圖5~圖7表明,[statistics],[face],[show]的判決結(jié)果與其發(fā)音一致,基于組合字典的清濁音判決方法對于多音素的清濁音判決具有顯著的效果。 圖6[face]基于組合字典的清濁音判斷圖7[show]基于組合字典的清濁音判斷本研究利用短時(shí)過零點(diǎn)法和短時(shí)能量法,分別對清音音素和濁音音素進(jìn)行測試,經(jīng)過大量實(shí)驗(yàn)數(shù)據(jù)得出,清音音素的短時(shí)過零點(diǎn)次數(shù)一般在一幀20次以上,因此短時(shí)平均過零點(diǎn)法的判決閾值為20,短時(shí)平均過零點(diǎn)次數(shù)大于20的幀判決為清音,小于20的幀判決為濁音。而清音的短時(shí)能量幅值一般在0.15以下,因此短時(shí)能量法的清濁音判決閾值為0.15,短時(shí)能量幅值小于0.15判決為清音,短時(shí)能量幅值大于0.15的判決為濁音。對[face],[statistics],[show]這3個(gè)單詞分別進(jìn)行清濁音判決,現(xiàn)只展示部分判別情況,[face]基于短時(shí)能量法和短時(shí)平均過零點(diǎn)法的清濁音判決結(jié)果如圖8和圖9所示。 圖8[face]基于短時(shí)能量法的清濁音判決結(jié)果圖9[face]基于短時(shí)平均過零點(diǎn)法的清濁音判決結(jié)果由圖8和圖9可以看出,對于一些位于濁音和清音重疊區(qū)域的音素,短時(shí)平均過零點(diǎn)法和短時(shí)能量法的判決效果并不準(zhǔn)確。短時(shí)能量法并沒有很好的區(qū)分出語音中存在的爆破音;而清音的特性與噪聲特性類似,噪聲的平均過零率也比較高,當(dāng)待測語音中出現(xiàn)噪聲時(shí),短時(shí)平均過零法較容易將噪聲誤判為清音。此外,短時(shí)過零點(diǎn)法和短時(shí)能量法的閾值是根據(jù)大量實(shí)驗(yàn)測試得出,在判決過程中也會有個(gè)別點(diǎn)出現(xiàn),導(dǎo)致一些幀的判別結(jié)果并不準(zhǔn)確。在判決過程中,閾值的選取極為重要,而閾值的選取依賴于大量的實(shí)驗(yàn)數(shù)據(jù),這就要求對樣本實(shí)驗(yàn)數(shù)據(jù)有著極高的準(zhǔn)確率,才能達(dá)到比較準(zhǔn)確的判決效果。因此,這兩種傳統(tǒng)的清濁音判別方法表1傳統(tǒng)方法與組合字典的清濁音判決正確率對比 判決音素準(zhǔn)確率/%短時(shí)過零法短時(shí)能量法組合字典法face85.9887.2399.07statistics49.6693.10100.00show97.0699.73100.00在多音素的判決中并沒有得到理想的檢測效果。 傳統(tǒng)方法與組合字典的清濁音判決正確率對比如表1所示。由表1可以看出,在相同條件下,與傳統(tǒng)的判別方法相比,新提出的方法在多音素清濁音判決上具有更加準(zhǔn)確的判別結(jié)果。這是因?yàn)榛诮M合字典的清濁音判決方法并不依賴于閾值,排除了個(gè)別點(diǎn)的干擾,只將組合清音字典上和組合濁音字典上系數(shù)的稀疏性做比較,比較方法具有相對性,而且清音和濁音具有很大的結(jié)構(gòu)差異,不同字典上系數(shù)的稀疏性差別較大,清濁音的區(qū)分程度更大,因此新方法對于清濁音的判決也更加明顯。 3結(jié)束語 本文將字典學(xué)習(xí)和稀疏表示與清濁音判決相結(jié)合,提出了一種新的清濁音判決方法。利用K-SVD算法對清音音素和濁音音素進(jìn)行字典學(xué)習(xí),分別訓(xùn)練出符合清音特性的清音字典和符合濁音特性的濁音字典,并將多個(gè)單音素的清音字典組合成組合清音字典,多個(gè)單音素的濁音字典組合成組合濁音字典,將待測信號在組合清音字典和組合濁音字典上稀疏表示,得到相應(yīng)的稀疏系數(shù),比較清濁音組合字典上系數(shù)的稀疏性強(qiáng)弱,進(jìn)而實(shí)現(xiàn)清濁音判決。與傳統(tǒng)的清濁音判決方法相比,基于組合字典的清濁音判決方法并不依賴于閾值,受其他樣本數(shù)據(jù)測試結(jié)果的影響較小,排除了一些偶然性的干擾,在多音素的判決上具有較高的準(zhǔn)確性。 參考文獻(xiàn): [1]趙力. 語音信號處理[M]. 北京: 機(jī)械工業(yè)出版社, 2016. [2]閆潤強(qiáng), 朱貽盛. 基于定量遞歸分析的清濁音判決[J]. 電子與信息學(xué)報(bào), 2007, 29(7): 17031706. [3]Donoho D. L. Compressed sensing[J]. IEEE Transactions on Information Theory, 2006, 52(4): 12891306. [4]于俊鳳, 曹俊興. 基于組合參數(shù)的清濁音判決方法[J]. 太原理工大學(xué)學(xué)報(bào), 2004, 35(4): 467469. [5]譚曉冰. 基于稀疏編碼的語音去噪技術(shù)研究[D]. 成都: 電子科技大學(xué), 2015. [6]Barchiesi D, Plumbley M D. Dictionary learning of convolved signals[C]∥2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Prague, Czech Republic: IEEE, 2011, 58125814. [7]鄭思龍, 李元祥, 魏憲, 等. 基于字典學(xué)習(xí)的非線性降維方法[J]. 自動化學(xué)報(bào), 2016(7): 10651076. [8]李彬. 基于稀疏表示的自適應(yīng)語音增強(qiáng)方法研究[D]. 廈門: 廈門大學(xué), 2015. [9]吳小龍, 伍松. 一種改進(jìn)的變步長OMP圖像重建算法[J]. 廣西科技大學(xué)學(xué)報(bào), 2019, 30(4): 6469. [10]莫長鑫, 畢寧. OMP算法對稀疏信號準(zhǔn)確重構(gòu)的一個(gè)充分條件[J]. 復(fù)旦學(xué)報(bào): 自然科學(xué)版, 2019, 58(1): 1924. [11]周思源, 趙錦航, 劉健均, 等. 基于優(yōu)化字典矩陣設(shè)計(jì)的OMP改進(jìn)信道估計(jì)算法[J]. 電子技術(shù), 2018(10): 102106. [12]鮑光照. 基于稀疏表示與聯(lián)合字典學(xué)習(xí)的語音增強(qiáng)算法研究[D]. 合肥: 中國科學(xué)技術(shù)大學(xué), 2015. [13]郭欣. 基于K-SVD稀疏表示的語音增強(qiáng)算法[D]. 太原: 太原理工大學(xué), 2016. [14]金卯亨嘉. 壓縮感知中字典學(xué)習(xí)算法的研究及應(yīng)用[D]. 天津: 天津大學(xué), 2014. [15]Zhou Y, Zhao H, Shang L, et al. Immune K-SVD algorithm for dictionary learning in speech denoising[J]. Neurocomputing, 2014, 137(15): 223233. [16]Rosas-Romero R, Remote detection of forest fires from video signals with classifiers based on K-SVD learned dictionaries[J]. Engineering Applications of Artificial Intelligence, 2014, 33: 111. [17]許根鵬. 字典學(xué)習(xí)算法研究及其在語音增強(qiáng)中的應(yīng)用[D]. 廣州: 廣東工業(yè)大學(xué), 2017. [18]劉雅莉, 馬杰, 王曉云, 等. 一種改進(jìn)的K-SVD字典學(xué)習(xí)算法[J]. 河北工業(yè)大學(xué)學(xué)報(bào), 2016(2): 18. [19]牛彪, 李海洋. 低字典相干性K-SVD算法研究[J]. 計(jì)算機(jī)與數(shù)字工程, 2019, 47(1): 97103. [20]羅友. 基于聯(lián)合字典學(xué)習(xí)和稀疏表示的語音降噪算法研究[D]. 合肥: 中國科學(xué)技術(shù)大學(xué), 2016. [21]Song L J, Peng J Y. Dictionary learning research based on sparse representation[C]∥2012 International Conference on Computer Science and Service System. Nanjing, China: IEEE, 2012, 1417.Judgement of Voiced and Unvoiced Sounds Based on K-SVD and Combined-Dictionary WANG Lianzi, LI Zhongxiao, CHEN Qianqian, ZHUANG Xiaodong (College of Electronic Information, Qingdao University, Qingdao 266071, China)Abstract:? According to the difference between voiced and unvoiced sounds, a new method has been proposed to judge them in this paper. The study selects enough voiced and unvoiced sounds as the object of dictionary learning and employs K-SVD algorithm to construct voiced dictionary and unvoiced dictionary respectively. And multiple single-voiced dictionaries are combined into a combined-voiced dictionary, while multiple single-unvoiced dictionaries are combined into a combined-unvoiced dictionary. Then the signals to be judged are sparse represented in combined-voiced dictionary and combined-unvoiced dictionary. The way to distinguish the voiced and unvoiced sounds is comparing the sparsity of coefficients in two dictionaries. The results have showed that comparing with the traditional methods by a large number of experimental results, the method based on combinatorial-dictionary is more accurate in the judgement of multiple phonemes under the same condition. This research is important for speech recognition and speech coding. Key words:? speech judgement; dictionary learning; sparse representation; combined-dictionary 收稿日期: 2019-12-18; 修回日期: 2020-02-13 基金項(xiàng)目:國家自然科學(xué)基金資助項(xiàng)目(41804110) 作者簡介:王蓮子(1995-),女,山東人,碩士研究生,主要研究方向?yàn)檎Z音信號處理。 通信作者:莊曉東(1977-),男,博士、副教授,碩士生導(dǎo)師,主要研究方向?yàn)檎Z音信號與圖像處理。 Email: xdzhuang@qdu.edu.cn
