一階速度-應力雙相介質方程逆時偏移及GPU 加速實現
2020-05-29 07:10:36張曉波劉保華于凱本楊志國于盛齊
海洋科學進展 2020年2期
關鍵詞:模型
張曉波,劉保華,于凱本,劉 苗,楊志國,于盛齊,宗 樂
(1.自然資源部 國家深海基地管理中心,山東 青島266237;
2.青島海洋科學與技術試點國家實驗室 海洋地質過程與環境功能實驗室,山東 青島266061;3.中國海洋大學 環境科學與工程學院,山東 青島266100;4.青島海洋科學與技術試點國家實驗室 公共關系部,山東 青島266061)
逆時偏移算法出現于20世紀80年代早期[1-2],其基于雙程波動方程理論而不需要對波動方程進行分解,避免了因對波動方程近似而造成的傾角限制,因此該方法是公認的對復雜構造的理想成像方法,一直以來都是地球物理領域的研究熱點。Chang和Mc Mechan首先將二維逆時偏移推廣到彈性波領域[3],隨后又將其推廣至三維情況[4-5];張會星等[6]基于程函方程實現了多波多分量資料的逆時偏移。為有效壓制逆時偏移的層間反射,何兵壽等[7]發展了任意廣角聲波方程逆時偏移技術;Yoon等[8]將Poynting矢量成像條件引入到逆時偏移中;Sun等[9]提出在縱橫波場分離的基礎上實現彈性波逆時偏移。針對逆時偏移的大存儲量問題,Clapp[10]、王保利等[11]利用隨機邊界以及吸收邊界存儲策略降低了常規逆時偏移方法中存儲空間消耗;石穎等[12]就隨機邊界條件和吸收邊界條件在逆時偏移算法中的應用效果以及相應的4種存儲策略展開具體分析,給出了不同存儲策略下的計算成本和存儲量需求。
經過近幾十年的發展,逆時偏移已逐漸由模型實驗走向實際生產,但在部分富含油氣的復雜構造區域的偏移成像上遇到困難,其主要原因是這類區域往往具有雙相介質的特性[13],而當前常規的逆時偏移算法多基于聲波和彈性波等單相介質理論,無法對具有雙相介質特性的地下構造進行準確成像[14]。因此,要實現雙相介質特性區域的精確成像需基于雙相介質理論波動方程進行逆時偏移處理,在此方面目前已有學者進行了初步的嘗試和探討,劉欣欣等[15]基于二階雙相介質方程實現了雙相介質的逆時偏移。其實驗結果顯示,對于雙相介質區域,雙相介質方程逆時偏移比彈性波逆時偏移更具優越性。
雖然雙相介質逆時偏移技術更適合復雜油氣構造區域的成像處理,但由于雙相介質方程比聲波和彈性波方程更為復雜,因此其計算效率低下,難以適應大規模實際生產的要求。近年來,GPU(Graphics Processing Units)憑借其優異的浮點運算能力和更快的訪存速度已成為解決大計算量問題的新興高性能運算工具。自CUDA(Computer Unified Device Architecture)推出后,GPU 加速運算在地球物理領域得到廣泛推廣,目前已有學者將其引入逆時偏移領域用以解決計算效率的問題[16-17]。朱博等[18]實現了基于多卡GPU 集群的多次波逆時偏移成像處理;Foltinek等[19]研究了二維和三維聲波逆時偏移的GPU 加速效果;劉紅偉等[20]詳細分析了二階聲波方程逆時偏移的GPU 加速效果;馬慶珍[21]研究了彈性波逆時偏移的關鍵技術和GPU 加速技術。上述研究成果表明,聲波和彈性波逆時偏移的GPU 加速均可獲得幾十倍的加速比。由于波動方程逆時偏移的實現過程具有相似性,因此可以預見,應用GPU 加速將可顯著提高雙相介質逆時偏移的計算效率,使其能夠早日服務于生產。
本研究基于Biot雙相介質理論[22]實現了二維一階速度-應力雙相介質方程逆時偏移及其GPU 加速,并利用模型實驗驗證了基于GPU 加速的雙相介質方程逆時偏移的優越性。
1 雙相介質方程逆時偏移算法
根據Whitemore[1]所提出的在時間域進行波場重建的逆時偏移理論,雙相介質逆時偏移首先需應用雙相介質方程的有限差分波場延拓方法得到炮點正向波場和檢波點逆時波場,然后根據互相關成像條件得到地下每個網格點的成像值。
1.1 基于一階速度-應力雙相介質方程組的波場延拓
常規的雙相介質方程逆時偏移波場延拓多基于一階速度-應力雙相介質方程組的交錯網格有限差分實現,其在二維情況下的表達式為

式中,x,z分別代表空間的橫向坐標和縱向坐標;vs=(vsx,vsz)T為固相的速度向量,vf=(vfx,vfz)T為流相速度向量,σxx,σzz,txz為固相應力張量,S為流相有效壓力;ρ11表示固體相對流體運動時固體部分的等效質量,ρ22表示流體相對于固體運動時流體部分總的等效質量,ρ12表示流體和固體之間的質量耦合系數;λ,μ為雙相介質中的拉梅常數,R為流相彈性參數,Q為固相體積與流相體積變化之間的耦合關系。當前,在基于式(1)進行波場延拓數值計算時,通常采用高階有限差分方法以滿足計算精度的需要。因此,需結合時間2階、空間2N階交錯網格有限差分計算方法,進一步得到相應的一階速度-應力雙相介質方程組交錯網格有限差分格式[23]。
同時,為了提高波場模擬的精度,在逆時偏移波場延拓時需引入人工邊界條件以消除邊界反射,這里采用PML吸收邊界條件方法實現。該方法通過在計算區域外面構造有限厚度的吸收層,并在吸收層內設置衰減因子,從而使地震波在吸收層內傳播時能量不斷衰減。在式(1)所示的雙相介質方程中引入衰減因子后,相應的PML邊界條件如下式所示:

基于式(1)和式(2)所對應的交錯網格有限差分表達式,若以震源子波作為正向擾動,從初始時刻計算至最大時刻,即可實現雙相介質方程的波場正向延拓,從而獲得正向波場值;若以地震記錄作為逆時擾動,從最大時刻逆向反推計算至初始時刻,則能夠實現雙相介質方程的波場逆向延拓,從而得到逆時波場值。
1.2 歸一化互相關成像條件
采用歸一化互相關成像條件實現偏移成像[25],其主要過程是利用震源波場的零延遲互相關的結果對正向與逆向波場零延遲互相關成像的結果進行歸一化:

式中,vF為正向波場,vR為逆向波場。
利用以上成像條件成像時需要每一時刻的正向波場值。當模型較大時,若將這些波場值全部保存在存儲介質上,不僅需要大量的存儲空間而且需要較長的數據存取時間。為了克服這個問題,本研究采用基于PML的有效邊界存儲策略[11]存儲震源波場正向延拓時每一時刻各邊界上PML 邊界內與中心波場鄰接的N(當空間為2N階精度差分時)層網格點的波場值以及最后一個時刻的中心波場值,然后在沿時間反向傳播時將這些邊界波場值取出并作為邊界條件即可逐一恢復正向波場。這種方法雖然需要事先進行1次震源波場正向延拓,但這能有效降低逆時偏移的存儲量。由圖1可見,在震源波場正向和逆向延拓中,基于PML邊界條件的有效邊界存儲策略流程。

圖1 基于PML邊界條件的有效邊界存儲策略流程Fig.1 Flowchart of effective boundary storage strategy based on PML boundary conditions
2 基于GPU 加速的雙相介質方程逆時偏移算法
逆時偏移為典型的密集運算地球物理問題,而雙相介質方程逆時偏移的計算量又遠大于聲波方程和彈性波方程逆時偏移的計算量,因此若僅基于傳統的CPU 計算設備運算,其計算效率難以滿足實際生產的需要。
當前GPU 憑借其優異的浮點運算能力和更快的訪存速度已成為新一代的高性能計算工具,并且隨著計算機技術的快速發展,GPU 卡的性能不斷提高。2013年NVIDIA 公司推出的Tesla K40卡,其流處理器已達到2 880個,每秒可執行約4.29萬億次浮點運算,并且其顯存帶寬達到288 GB/s。本研究利用Tesla K40卡實現雙相介質方程逆時偏移的GPU 加速。
2.1 CUDA編程模型
GPU 加速目前多基于CUDA 平臺實現。CUDA 編程模型的主要思想將CPU 作為主機(Host),GPU作為設備(Device)。在1個系統中可以有1個主機和多個設備,其中CPU 負責向GPU 分配任務和串行計算,GPU 負責執行線程化并行計算,此外兩者擁有相互獨立的存儲器(CPU 端為內存和GPU 端為顯存)。
在GPU 上運行的函數稱為Kernel(內核)函數。一個完整的CUDA 程序是由主機函數和一系列Kernel函數共同組成的。主機函數的工作包括在Kernel函數啟動前進行的數據準備、設備初始化以及在Kernel函數之間進行的一些串行化計算。執行Kernel函數所需的GPU 線程是以線程網格(Grid)的形式組織的,每個Grid又由若干個線程塊(Block)組成,每個Block又由若干線程(Thread)組成,線程層次如圖2所示。調用時需要設定Kernel函數中Grid的Block數目以及每個Block中Thread的數目,而Block中的線程數需要根據GPU 的計算能力來合理配置以充分發揮GPU 多線程并行計算的潛力,因為Tesla K40卡的計算能力已達到3.5,因此在計算時將線程數設置為512(即該卡設計最大可用值)。

圖2 GPU 線程示意圖[18]Fig.2 Diagram of GPU thread[18]

圖3 CUDA 存儲器模型[18]Fig.3 CUDA memory model[18]
除了線程層次以外,CUDA 編程模型中還規定了一系列用于控制CPU 通信與GPU 通信所需存儲空間的存儲器模型(圖3),主要包括寄存器(Rigisiter)、局部內存(Local Memory)、共享內存(Shared Memory)、常量內存(Constant Memory)、紋理內存(Texture Memory)和全局內存(Global Memory)等部分。其中,共享內存、常量內存等訪存速度較快,能夠顯著提高GPU 的計算效率,但其存儲空間較小,因此在本文中將內存消耗較小的有限差分格式的差分系數數組應用共享內存進行存儲,同時將炮和道的位置坐標數組等內存消耗也相對較小的參量應用常量內存進行存儲;紋理內存適合存儲需頻繁進行地址訪問的只讀參量,因此本文將空間波場的數組應用紋理內存進行存儲;此外,由于其余參量數據量巨大而且需要頻繁修改,因此采用全局內存。
2.2 主機函數和核函數配置及CUDA 偽碼
雙相介質方程逆時偏移流程的步驟主要包括:速度模型輸入、震源子波賦值、接收點記錄輸入、震源波場正向延拓、震源波場逆向重建、檢波點波場逆向延拓、吸收邊界條件處理、震源波場邊界存儲、震源波場邊界輸入和互相關成像等。其中震源波場正向延拓、震源波場逆向重建、檢波點波場逆向延拓、吸收邊界處理以及互相關成像屬于密集運算問題,應通過調用Kernel函數來借助GPU 計算,而其余步驟應采用CPU 計算。本研究基于以上分析設置了相關的主機函數和核函數,具體名稱和功能見表1,核函數前綴為“__global__”,同時給出了基于CUDA 的雙相介質方程逆時偏移程序偽碼(圖4)。

圖4 基于CUDA 的雙相介質方程逆時偏移程序偽碼Fig.4 Pseudo code for reverse time migration of dual phase medium equation based on CUDA

表1 主機函數及核函數表Table 1 Host function and kernel function
3 模型實驗與分析
3.1 基于GPU 的雙相介質方程逆時偏移模型實驗
使用雙相介質模型(圖5a)進行雙相介質方程逆時偏移的實驗,模型介質參數如表2所示,其中第7,8層為雙相介質地層。模型中雙相介質地層由于孔隙流體的存在(孔隙率>0),其表示液相及固液耦合相的參數Q,R,ρ22以及ρ12等均不為0。模型水平方向長度為2 500 m,垂直深度為1 000 m,空間網格大小為5 m×5 m;本實驗采用雙邊觀測系統,炮點深度為5 m,炮間距10 m,總炮數為300炮;接收點深度為5 m,每炮接收道數為100道,道間距5 m。使用雷克子波作為震源函數,子波主頻為40 Hz。利用雙相介質方程實現基于GPU 的逆時偏移,并得到固相垂向速度分量偏移剖面如圖5b所示。
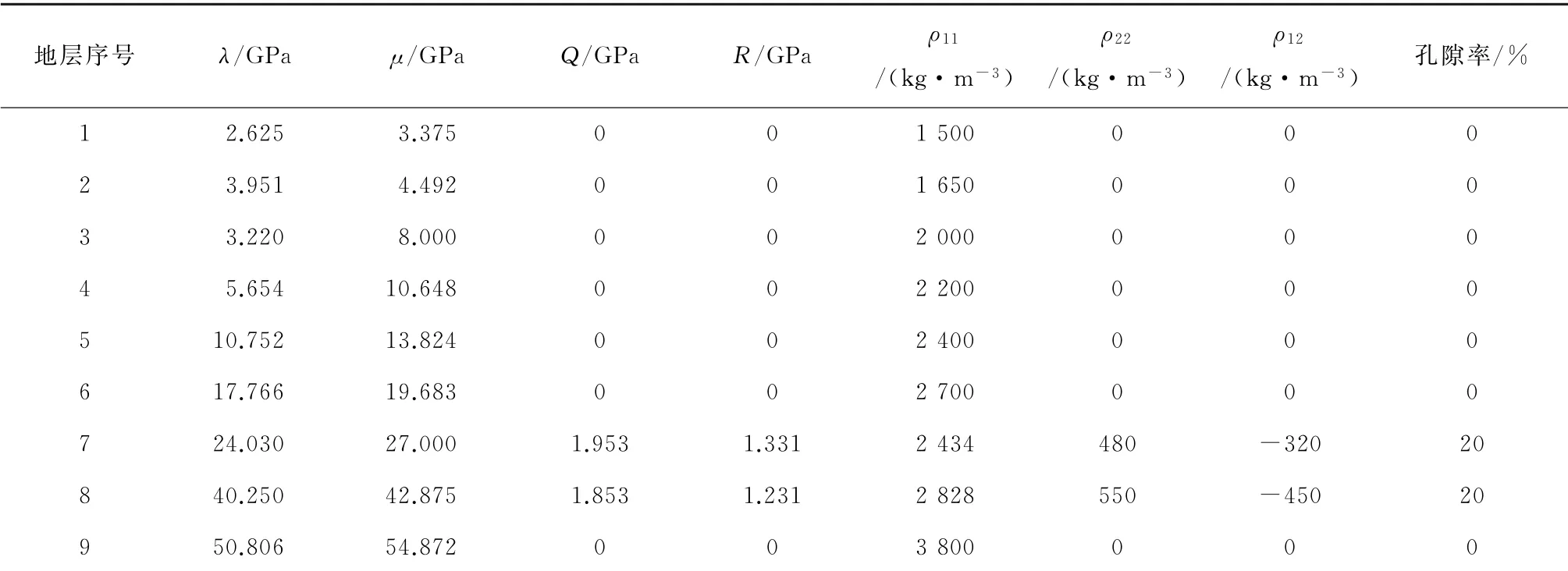
表2 復雜模型雙相介質模型彈性參數Table 2 Elastic parameters of dual-phase medium model of complex model
目前實際生產中常用的逆時偏移方法多基于彈性波方程或聲波方程實現。為比較其與雙相介質方程逆時偏移效果,本研究根據雙相介質參數與彈性波介質參數以及聲波介質參數的關系[26-27],從表2所示的雙相介質參數中分別提取彈性波介質參數和聲波介質參數并由此實現基于彈性波方程以及聲波方程的逆時偏移(偏移剖面分別如圖5c和圖5d所示)。為便于3種方法所得結果的對比分析,這里分別將圖5中對應于雙相介質區域的模型和剖面進行放大顯示(圖6)。

圖5 雙相介質模型及逆時偏移剖面圖Fig.5 The dual-phase medium model and reverse time migration profiles

圖6 偏移剖面局部放大對比圖Fig.6 Partial enlarged drawing of reverse time migration profile
由圖5b,5c,5d和圖6可知,在非雙相介質的地層處,彈性波方程與聲波方程均能較好的描述構造的形態,而在雙相介質假設的地層處,其偏移剖面的構造形態則與介質模型存在明顯差異,其主要原因為單相介質中未考慮填充在固體介質孔隙中的流體對介質參數的影響,這就使得單相介質模型參數與雙相介質模型參數之間存在差異,其會導致波的傳播過程出現偏差,從而影響成像點的位置和成像質量。而對于雙相介質逆時偏移來講,無論是在雙相介質區域還非雙相介質區域,其均可精確成像,這說明雙相介質逆時偏移方法對雙相介質地層成像的有效性。
此外,本研究的模型實驗顯示,基于Tesle K40卡的雙相介質逆時偏移其計算時間僅為1 860 s,而基于型號為Intel Core i5-2400 的CPU 其計算時間則需約50 400 s,其加速比可達到27倍,這說明與常規基于CPU 平臺的算法相比,GPU 加速技術能夠顯著提高雙相介質逆時偏移的計算效率。
4 結 論
基于一階速度-應力雙相介質方程實現了基于GPU 加速的逆時偏移,通過理論分析和數值實驗可以得出如下結論:
1)無論是在雙相介質區域還是在非雙相介質區域,雙相介質逆時偏移均可精確成像,這說明雙相介質逆時偏移方法對雙相介質地層成像的有效性;
2)與常規基于CPU 平臺的算法相比,應用GPU 加速技術的雙相介質逆時偏移可達到27倍的加速比,能夠顯著提高雙相介質逆時偏移的計算效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
