基于RDPSO-RBF的糧食產后儲藏環節損耗評估模型
2020-06-01 07:58:51鄭沫利趙艷軻陳思露陳祺東孫俊
江蘇農業科學 2020年8期
鄭沫利 趙艷軻 陳思露 陳祺東 孫俊

摘要:為使減少糧食儲藏環節的損耗,調查儲藏環節中糧食作物的損失情況并進行評估預測。通過分析問卷,統計描述影響損失率的各個因素,應用隨機漂移粒子群優化算法(random drift particle swarm optimization,RDPSO)和徑向基函數(radial basis function,RBF)網絡對儲藏環節損耗進行評估預測,將調查問卷獲得的數據作為RBF模型數據集,應用RDPSO算法進行模型的參數訓練,從而獲得糧食損耗的智能評估模型。采用稻谷數據作為各模型的數據集,通過仿真試驗,對比數據擬合情況和均方誤差,其RDPSO-RBF模型學習性能和泛化性能更強。因此,RDPSO-RBF能更好地應用于實際的糧食管理中。
關鍵詞:產后糧食;統計描述分析;RDPSO-RBF模型;儲藏損耗;評估
中圖分類號: F326.11文獻標志碼: A
文章編號:1002-1302(2020)08-0307-05
收稿日期:2019-03-05
基金項目:國家公益性行業(糧食)科研專項(編號:201513004、201513004-6)。
作者簡介:鄭沫利(1967—),男,廣東陸豐人,教授級高級工程師,主要從事糧食經濟學研究,E-mail:zhengmoli@sohu.com。共同第一作者:趙艷軻(1987—),女,河南洛陽人,博士研究生,中級工程師,主要從事糧食經濟學研究,E-mail:zhao_yanke@126.com。
通信作者:孫?俊,博士,教授,主要從事人工智能、機器學習、計算智能和高性能計算研究。E-mail:sunjin_wx@hotmial.com。
糧食是人類最基本的生存物資,是人類生活的第一要求,在國民經濟中占有重要地位。長期以來,我國在保障糧食安全問題上一直較注重產前與產中的管理與投入。然而在糧食產后損失的關注嚴重不足,產后大概分為收獲、運輸、干燥、儲藏、加工、銷售和消費等環節[1]。而每年糧食的產后損失情況極其嚴重,儲藏環節糧食損失在產后總損失中所占比例較高。若在此環節能采取有力的防護措施,將可有效控制產后儲藏環節中糧食的損耗。目前,已有不少的學者對糧食產后損失展開廣泛的研究。在產后糧食損失方面,主要在儲糧的損耗分析和減損措施。如儲糧技術和儲糧安全,主要是研究不同因素對儲糧損耗的影響,進而采取相關技術減損,保證儲糧的質量與數量[2-3]。在儲糧模型構造方面,主要是依據機器學習或優化算法對儲糧害蟲進行研究[4-6]。鮮有對糧食產后儲藏環節的損失率預測的分析研究。
鑒于此,本研究調查了稻谷、大米、小麥、玉米、大豆5大糧食作物,通過問卷的形式記錄了10個省份的產后糧食損失率和損失因素。為了解損失因素和其損失率的關系,將問卷進行變量處理和統計分析,并將各品種糧食作物生成變量相同的數據集。然后采用人工智能的方法,研究損失數據的因素對在儲藏環節產后糧食損失率的影響,提出了基于RDPSO(random drift particle swarm optimization)-RBF(radial basis function)損失預測模型。RBF神經網絡能很好地逼近非線性數據,真實地反映輸入、輸出變量間的內在聯系,在眾多神經網絡中RBF逼近能力比較突出。但直接采用RBF作為損失率預測模型,其初始隨機參數很難確定最優值,導致預測結果隨機化。而RDPSO是一種全局優化算法,在搜索能力、收斂速度以及高維問題上表現突出。因此,用RDPSO優化RBF網絡中參數,以之克服RBF網絡預測結果的隨機性,可使預測值更接近實際值。在實際儲糧中,可以根據該預測值,判斷是否需要采取措施來改善某些因素的影響,以達到減少糧食損耗的目的。
1?產后糧食儲藏環節調查研究
1.1?產后糧食儲藏環節損失率調查概況
以儲藏環節的產后糧食作物稻谷、大米、小麥、玉米、大豆這5類品種作為調查主體。本研究根據全國糧食種植分布數據,抽取了青海、湖南、重慶、江西、福建、江蘇、安徽、黑龍江、貴州、遼寧10個省份的數據,分別對這5類作物產后糧食的損失率情況進行專項調研。此外,在每個地區的抽樣中選出幾個市(區),對該抽樣出的市(區)儲糧企業單位進行訪問。為了使問卷真實、有效,通過與該企業代表人“一對一”訪談并當場答卷的方式進行調查,并由調查人員填寫問卷。最后,調查得到有效的關于產后糧食在儲藏環節損失率的問卷324份。其中,調查稻谷的樣本問卷占總問卷的36.7%,其次是玉米、小麥分別占29.3%、27.2%,最后大豆和大米占 4.3% 和2.5%。因此,本研究選擇稻谷作為代表糧食,分析影響其損失率的特征變量。
1.2?糧食產后儲藏環節特征描述
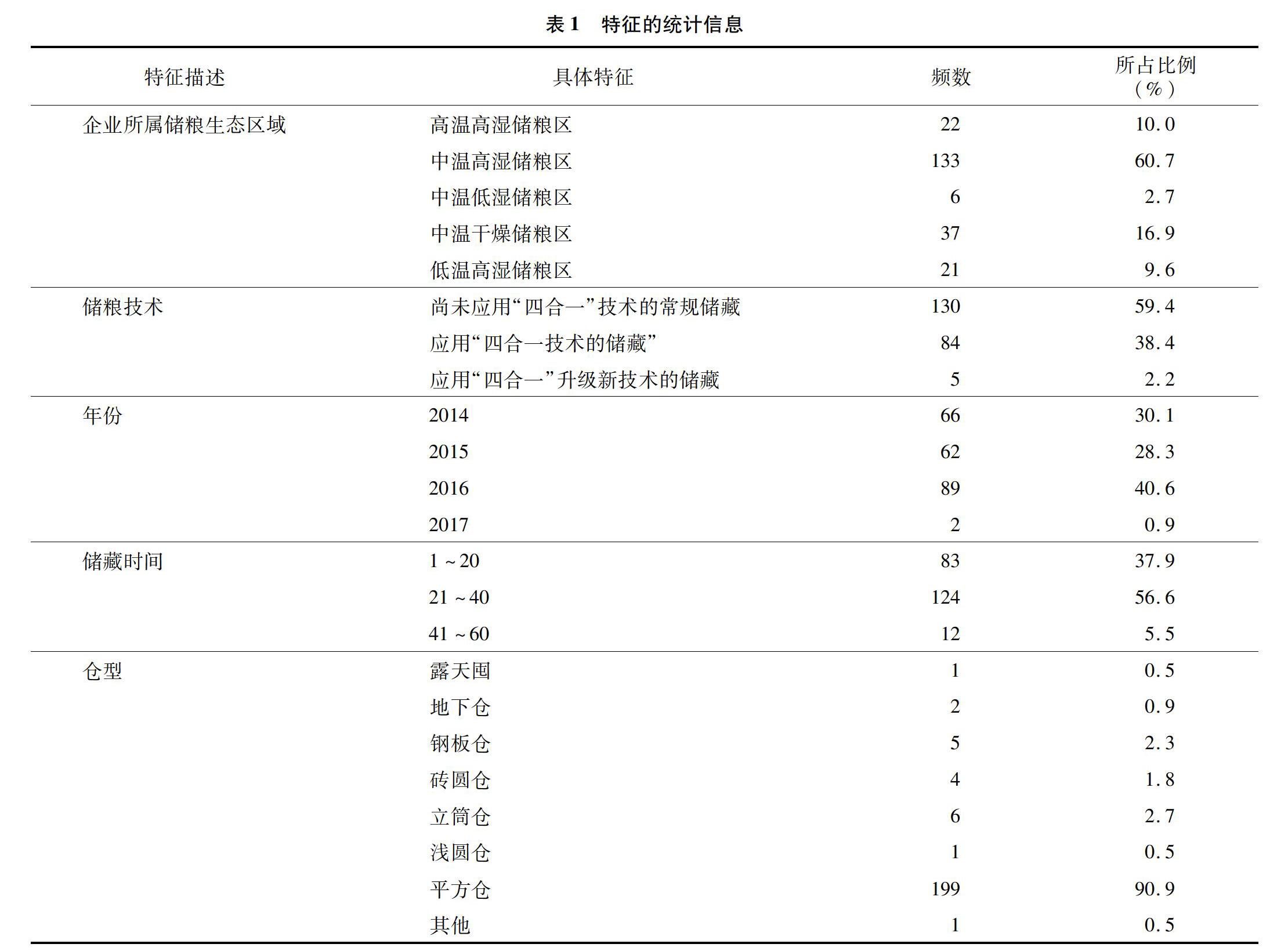
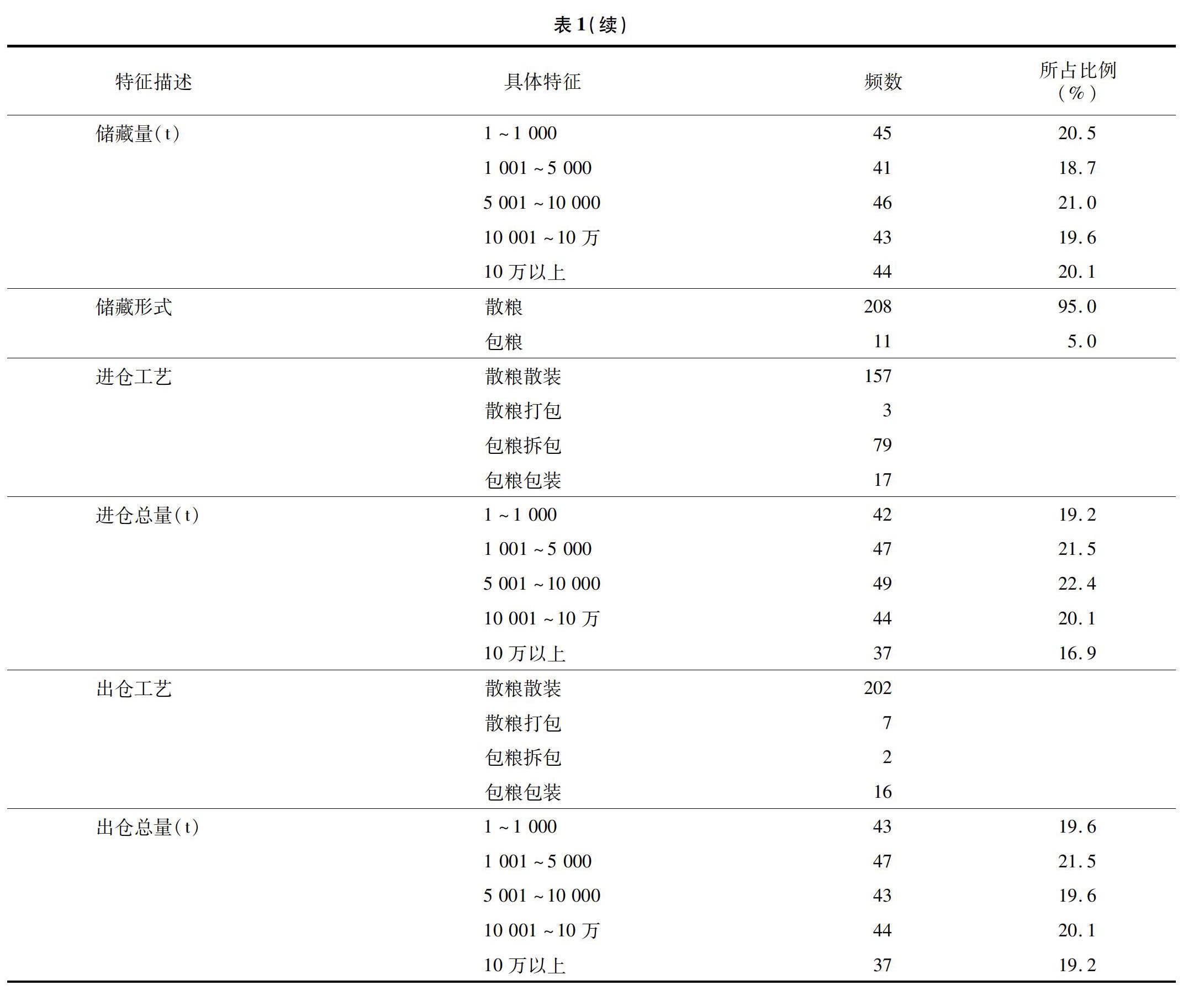
在此次問卷中,該產后糧食損失率是對產后糧食總損失率的描述,即為產后糧食在儲藏環節中的進倉損失率、出倉損失率、蟲害損失率、鼠害損失率、霉變損失率、其他損失率的總和。而影響這些損失率的因素包含了受訪者、受訪企業的信息,產后糧食儲藏的情況(年份、儲藏品種、儲藏時間、倉型、儲藏量、儲藏形式)、進倉損失信息(進倉工藝、進倉總量)、出倉損失(出倉工藝、出倉總量)等。從表1可以看出,糧食產后的儲藏條件并不是很理想,其中儲糧生態區域有60.7%為中溫高濕儲糧區;儲糧技術有59.4%是尚未應用“四合一”技術的常規儲藏;儲藏形式采用散裝的占95.0%。同時,除了儲藏倉型(使用平方倉的比例為90.9%),其他特征所占比例分布相對較均勻。
2?RDPSO-RBF模型
2.1?RBF神經網絡簡介
RBF神經網絡是一種前饋神經網絡[7]。一般最基本的RBF神經網絡由輸入層、隱含層、輸出層構成3層網絡結構,其公式如下:
Y=f(x)=∑Kk=1αkφk(x)。(1)
式中:αk是第k個隱含層節點到輸出層的連接權值,φk(x)是第k個隱含層結點的輸出值,其定義如下:
φk(x)=exp-‖x-μk‖2σ2k。(2)
式中:μk和σ2k分別代表了第k個隱含層結點的中心向量和擴展常數。
2.2?RDPSO算法簡介
隨機漂移粒子群(RDPSO)算法是基于PSO對于受到自由電子運動軌跡分析的啟發而提出的[8-9]。當金屬導體在外電場時,其導體內的自由電子會發生定向漂移,同時還存在無規則的隨機熱運動,這2種運動的結合可以使整體的勢能逐漸變小。因此,電子的運動過程類似于優化問題中的求解最優解使得目標函數值最小化。在RDPSO算法中,第t+1次的第i個粒子在j維的定向速度和隨機熱運動速度分別為Vdt+1i,j、Vrt+1i,j,因此第t+1次粒子速度為:
Vt+1i,j=Vdt+1i,j+Vrt+1i,j。(3)
根據PSO算法中粒子趨向局部位置的學習機理,定向漂移速度Vdt+1i,j的定義如下:
Vdt+1i,j=c1·rti,j·(Pti,j-Xti,j)+c2·Rti,j·(Gtj-Xti,j)。(4)
式中:c1和c2為常數;rti,j和Rti,j是在(0,1)區間內均勻分布的隨機數,Pti,j是個體粒子最優值,Gtj是其所有粒子中最優值。而式(4)可以等價為
Vdti,j=β·(pti,j-Xti,j);(5)
β=c1·rti,j+c2·Rti,j;(6)
pti,j=c1·rti,j·Pti,j+c2·Rti,j·Gtjc1·rti,j+c2·Rti,j。(7)
式中:β為漂移系數;pti,j為吸引子。
假設RDPSO中的粒子的無規則隨機熱運動速度Vrt+1i,j服從雙指數分布,通過蒙特卡洛法得到其表達式如下:
Vrt+1i,j=δti,j·φti,j。(8)
式中:φti,j為高斯分布函數;δti,j是高斯分布的標準差,定義為
δti,j=α·|Mti,j-Xti,j|。(9)
α為熱敏系數;Mti,j為當前種群中所有粒子個體的歷史最優位置平均值,即
Mti,j=1N∑Ni=1Pti,j。(10)
因此,式(8)可以改寫為:
Vrt+1=α·|Mti,j-Xti,j|·φti,j。(11)
綜上,RDPSO算法中粒子速度和位置的更新公式為:
Vti,j=β·(pti,j-Xti,j)+α|Mti,j|-Xti,j·φti,j;(12)
Xti,j=Xti,j+Vt+1i,j。(13)
2.3?RDPSO-RBF模型
2.3.1?RBF神經網絡模型確定
通過調查得到的問卷,在SPSS中進行分析。樣本在變量處理后得到51個特征變量。由于某些糧食品種樣本數量相對較少,特征數量過多,在試驗中其誤差結果并不理想。通過相關性分析,得到其中8個相關性最高的變量,作為實驗室數據樣本輸入變量,而產后總損失率作為樣本輸出。因此,RBF神經網絡的輸入層結點個數為8,輸出結點1個。隱含層通過利用對手受罰的競爭學習算法確定為8。綜上所述,該RBF神經網絡模型結構為8-8-1。
2.3.2?RDPSO算法目標函數
采用均方誤差作為RDPSO算法的目標函數,評價粒子群中所有個體,從中尋找最佳個體來判斷是否更新粒子的Pti和Gt。
2.3.3?RDPSO-RBF算法步驟
步驟1:通過上述描述的思想,構建RBF網絡,同時給定輸入與輸出樣本集。
步驟2:將RBF神經網絡中的隱含層中心、擴展系數和權值編碼成實數串代表粒子個體,同時隨機產生規模為S的粒子群并初始化其位置和速度。
步驟3:解碼得到每個粒子個體串,映射到RBF網絡的不同參數,同時將N組訓練樣本輸入到RBF網絡中,得到相應的輸出,計算優化算法的目標函數。
步驟4:計算漂移系數β,根據式(10)計算群體平均最優位置。
步驟5:對每個粒子按照式(12)和(13)進行速度和位置的更新。
步驟6:更新得到全局最優值Gtj和粒子局部最優位置Ptj。
步驟7:判斷全局最優值是否滿足RDPSO算法中的結束條件,即算法給定預定值或迭代條件。如果滿足條件,轉入步驟8,否則轉入步驟3。
步驟8:算法結束。
3?結果與分析
基于上述思路在MATLAB2015a中編程,創建RDPSO-RBF網絡模型,采用的計算機配置為:Intel CoreTM i7-6500U CPU @2.5 GHz,8 G內存。這里采用產后糧食作物稻谷作為試驗數據集,將207組樣本數據隨機分成2份,前160組作為網絡的訓練數據,后47組作為測試樣本。基于上述描述,通過降維后的變量(這里利用相關性,如:企業所屬生態區域、儲藏量、進倉總量、出倉總量、進倉形式是散糧散裝進倉、出倉形式是包糧拆包出倉等)作為模型網絡的輸入,其產后糧食總損失率作為輸出。
首先,通過訓練樣本訓練出預測模型,并根據學習得到的模型輸出的訓練樣本的預測值與訓練樣本實際值作比較。為了突出RDPSO-RBF模型預測產后總損失率的效果,將設計線性回歸模型、RBF模型進行試驗效果的比較。從圖1可以看出,線性回歸模型在訓練樣本的擬合情況相當差,說明了該數據集并非線性的,線性模型在這里不適用于糧食的產后損失數據。而非線性的RBF神經網絡和RDPSO-RBF網絡,卻能較好地擬合。
通過圖1得知,RBF神經網絡算法和RDPSO-RBF算法通過訓練樣本學習到模型,其模型對訓練樣本有精準的預測輸出。因此,為了檢驗模型的泛化性能,圖2呈現了在測試集上的擬合情況,可以看出基于RDPSO-RBF模型能更好地預測損失率,其泛化性能比基于RBF神經網絡模型的更好,其RBF模型有過擬合現象。
根據表3的2種算法模型的均方誤差的數據可知RDPSO-RBF模型學習能力與泛化能力的優越性,能更好地預測糧食產后損失率。
4?結論
研究儲藏環節糧食損失因素、預測糧食損失率,以期為糧食在儲藏環節損失量提供參考值。為此,本研究基于對糧食產后損失率情況的調查,描述影響損失因素的特征。為精準地預測糧食產后儲藏環節損失率,建立了RDPSO-RBF網絡模型。通過試驗對比,RDPSO優化后的RBF神經網絡能更好地對損失率作出準確預測,具有更強的泛化性能,在實際場景中預測損失率的值更加準確。
參考文獻:
[1]高利偉,許世衛,李哲敏,等. 中國主要糧食作物產后損失特征及減損潛力研究[J]. 農業工程學報,2016,32(23):1-11.
[2]張歡歡,唐浩林,葉福康,等. 糧食儲存損耗的原因分析及對策[J]. 糧食加工,2015,40(3):69-72.
[3]張?彩. 散裝糧食平房倉外圍護體系研究[D]. 鄭州:河南工業大學,2015.
[4]胡麗華,郭?敏,張景虎,等. 儲糧害蟲檢測新技術及應用現狀[J]. 農業工程學報,2007,23(11):286-290.
[5]Shen Y F,Zhou H L,Li J T,et al. Detection of stored-grain insects using deep learning[J]. Computers & Electronics in Agriculture,2018,145:319-325.
[6]郭?敏,張明真. 基于GMM和聚類方法的儲糧害蟲聲信號識別研究[J]. 南京農業大學學報,2012,35(6):44-48.
[7]Chen S,Cowan C F N,Grant P M,et al. Orthogonal least squares learning algorithm for radial basis function networks[J]. IEEE Transactions on Neural Networks,1991,2(2):302-309.
[8]Sun J,Wu X,Palade V,et al. Random drift particle swarm optimization algorithm:convergence analysis and parameter selection[J]. Machine Learning,2015,101(1/2/3):345-376.
[9]Kennedy J,Eberhart R. Particle swarm optimization:Proceedings of ICNN95-International Conference on Neural Networks[C]. Perth:IEEE,2002,1942-1948.
[10]張?鈴,張?鈸. 人工神經網絡理論及應用[M]. 杭州:浙江科學技術出版社,1997.
