基于屬性加密的計算機數據庫安全檢測工具的設計與運用
2020-06-04 10:08:18陳良英
網絡安全與數據管理 2020年4期
陳良英
(四川信息職業技術學院,四川 廣元 628017)
0 引言
我國信息技術研究起始于20世紀60年代。經過數十年的發展,已經融入到我國國民生活的各個角落。現階段我國互聯網相關領域和技術正在不斷與社會接軌,我國正處于高速發展的信息時代。信息社會使個人和企業之間以數據信息的形式進行交流,這就讓現代互聯網數據信息量不斷增長。在這樣一個數據量激增的時代,企業和個人均會產生巨大的數據資源,這些數據資源的存儲離不開數據庫。社會中的個人和企業,均與數據庫存在緊密的關系,不僅個人的財政信息如銀行卡余額、身份證號碼等存在于數據庫中,大量企業信息甚至是涉及國家高度軍事機密或重要數據也存在于數據庫中。然而因為現代互聯網信息具有巨大的潛在價值,其存儲位置相對集聚性較強,不法分子針對數據庫的網絡攻擊往往可以獲取最直接有效的攻擊效果,數據庫已經成為非法人員進行資源竊取的首要攻擊目標。2018年,Virerzon公司發布了《2018年度數據庫泄露報告》,該報告是由Virerzon公司以及39家合作企業共同完成的,其中包括了著名數據網站Delouti、EMC、Chetk、Intouerce、Froint公司等。報告內容顯示,僅2018年上半年,全球就發生了945起較大型的數據泄露事件,共計導致45億條數據泄露,與2017年相比數量增加了133%。為了有效降低安全隱患,現代計算機數據庫的管理人員必須對數據庫進行安全檢測,消除安全隱患。傳統情況下,針對計算機數據庫安全檢測工具一般基于數據代碼和數據密匙,這種檢測手段在初期雖然取得了一定效果,但是隨著入侵技術的提高,對數據庫安全隱患的隔離率,已經不能滿足數據庫維護的需要。針對這一情況,設計提出了以屬性加密為核心的計算機數據庫安全檢測工具,維護計算機系統數據庫的安全[1]。
1 計算機數據庫安全檢測工具設計
設計的安全檢測工具主要分為三個部分:一是文件屬性加密部分,設計通過生成公有和私有密匙進行文件屬性加密;二是加密文件數據序列索引,對加密文件進行序列重組;最后利用數據文件建立TRIE樹結構,根據索引序列進行數據遷移,即完成數據檢測。
1.1 文件屬性加密
基于屬性的加密機制是現代云計算網絡以及分布式等環境下,對數據中心數據庫進行訪問控制的主體研究熱點之一。因為現代計算機數據庫一般均采用分布式處理結構,而且在多分部機構ABE中,一般不會采用中央授權的管理方式,所以在對數據庫全局身份標識進行共謀攻擊時,身份全局管理會出現一定的安全隱患。而設計的計算機數據庫安全檢測攻擊引入了一種新型的文件屬性加密方案,用戶在進行多項密匙申請時,可以根據用戶自身的指令協要,實現用戶標識不公開,提高屬性加密效果。
設計提出的文件屬性加密主要基于新型的密匙架構,加密方案將密匙主要分為兩個部分即域內密匙和域外密匙。域內密匙的生成,主要是通過具有域內密匙屬性的授權加密機構(AA)進行密匙授權。AA會為當前加密用戶提供一個特質的屬性密匙。而域外密匙則需要域內屬性密匙原本數據代碼完成,詳細的域內和域外密匙分發方案如表1所示。

表1密匙組成數據表
每一個數據庫授權結構均有一個相應代碼下的加密公共密匙和一個私有密匙。具有通信鏈路的不同授權書信機構之間,可以在密匙建立的初期,通過密匙信息共享建立公共密匙的信任鏈路。數據庫每一個網絡域的屬性授權機構,如果要建立加密,需要具有信任域中所有區域的屬性授權機構公共密匙信息。詳細密匙授權架構如圖1所示[2]。

圖1 網絡域內屬性密匙分布架構圖
根據圖1可以看出,AA1具有自身的公共密匙和私有密匙,同時獲取了其他域內的私有密匙,可以直接用于生成具有管理屬性的公共密匙,以及文件加密的私有密匙。對于每一個文件網絡域屬性,都有一個公共密匙,用于加密文件。一個文件數據的管理者可以根據訪問策略,利用不同域內屬性的公共密匙進行數據加密。具體方案為:
令數據N=p1p2p3,其中p1p2p3為素數,G和GT分別為數據N的雙線數據群,用e:G×G→GT表示加密數據未知結構下數據線性映射。在AA中生成用戶數據文件標識,映射到G文件中的群元素中,另外制定數據外定義下的有限數據文件哈希函數集合,每一個AA生成的私有密匙,均需要存在于且僅存在于哈希函數集合中,對文件屬性進行處理[3]。需要著重說明的是,該方案主要基于文件屬性多數字階層的群構造,但是所有的G文件均需要存在于子群中。文件屬性加密操作如下。
(1)Globat Setup(GP),輸入安全性參數λ,根據參數生成全局性公共參數GP,選擇一階GP為數據N的實際下述線性數據集群。在GP中,主要包括數據N,Gp1的生成源g1,以及隨機屬性加密函數的H1和T1表述。
(2)Authery Setup(AP):根據屬性授權機構密匙執行下的初始化進程,每一個授權單位均需要選擇一個隨機指數;從上述建立的哈希函數集中生成一個具有一致性的隨機函數,將這個函數作為屬性授權機構的索引,也就是授權機構的加密密匙,則屬性授權機構的私有密匙表示為SKa,公有密匙表示為CKa,而IDA則表示為當前屬性授權機構的身份編碼。其表達公式為:
SKa=[Sa,xa,?a]
(1)

(2)
(3)Auto-attacker:因為屬性公共密匙的授權機構需要根據網絡域屬性進行公參,屬性標識以及授權屬性私有密匙生成,其中:
IDj=IDAπID
(3)
則Pki的生成公式可以表示為:
Pki={Pkje(g1,g2)sa(Hxa(IDj)),PKgiHxa(idj)}
(4)
公式(4)中的屬性身份標識IDj主要是由AA的身份表示屬性和對應編碼生成,而IDA則主要表示為授權機構內的身份編碼。文件屬性的多樣化全局加密標識,使得屬性標識是整個局域網信任域中唯一的驗證性標識,所以每個公共屬性標識在信任域中,也具有唯一性[4]。根據全局加密表示,設計為加密用戶提供了全局身份標識,此標識由當前數據庫和使用用戶所在域的AA標識組成。在IDA下,使用用戶需要申請屬性標識,而且設計為了實現使用用戶標識的全網唯一性,會為使用用戶提供一個不同屬性編碼。在加密過程中,加密工具會首先檢查使用者身份是否具有屬性授權機構的負責項,然后驗證使用者的實際身份,檢測是否具備屬性授權的可能性,如果不可以則輸出結果為空,反之則生成數據密匙。
(4)Decrypt:針對屬性密匙的機密算法為CT輸出密文,全局參數。同一個身份標識,用戶的機密屬性密匙集具有外部相似性。如果使用者的屬性密匙滿足加密時的訪問控制要求,則可以完成屬性解密。
1.2 建立Apriority數據序列索引架構
利用上述方式對數據庫文件進行加密后,原本的序列架構會被打亂,在進行安全檢測過程中,無法進行有效識別。設計針對加密文件的密匙序列[5],對其進行文件關鍵序列架構重組。因為加密屬性文件具有明顯的封閉開源性,所以設計提出了Apriority封閉性數據索引架構。整個架構采用集中式數據管理,包括序列程序檢索、序列存儲以及序列引源的建立。這種索引數據架構的相對配置資源較為簡單,配置體系和操作整體較為便捷,其架構如圖2所示。

圖2序列索引架構示意圖
設計的索引序列架構從索引功能上來說包括四個索引單元分別為:Apriority底層數據管理單元、Apriority數據序列交換單元、Apriority并行序列解析單元、Apriority文檔數據解析單元[6]。
Apriority底層數據管理單元主要負責幫助安全檢測管理工具的使用用戶,建立正常的加密數據文件序列索引庫,將使用者提交的加密數據文檔和文檔序列號,利用鏡像索引結構進行數據準壓縮、數據合并以及數據優化。另外Apriority底層數據管理單元還可以針對使用用戶提交的各類加密文件索引語句進行密匙解讀。
Apriority數據序列交換單元主要負責對加密文件序列索引用戶的各類處理結果進行回饋,包括數據輸入文檔的檢索信息以及數據高亮分頁處理等。該序列交換命令的解析包括整個索引庫的數據分配過程,使用用戶在進行操作時,用戶界面和后臺服務界面會進行數據資源管理器之間的數據串聯,同步傳遞狀態命令質量檢測等。此外數據序列交換單元還包括對當前加密信息的綜合判斷,并與后臺相關聯[7]。
而Apriority并行序列解析單元和Apriority文檔數據解析單元,則主要負責將各類加密文件的序列文檔進行集聚匯總,通過提取文檔解析分析內容,獲取明確的文件標識碼,進而生成解析序列。在進行序列解析過程中,需要對加密數據進行準確的數據描述和數據整理,利用適當的數據索引源進行有序數據文件標記。這些標記后的特征數據可以作為檢測工具中所有特征數據索引字段的數據集合,根據數據集合中的索引項,可以將索引序列進行割裂操作,然后生成數據序列文檔。序列內容包括序列用戶名稱、序列存儲量、序列數據量、序列生成日期、序列格式文檔ID、序列存儲位置等,如圖3所示。
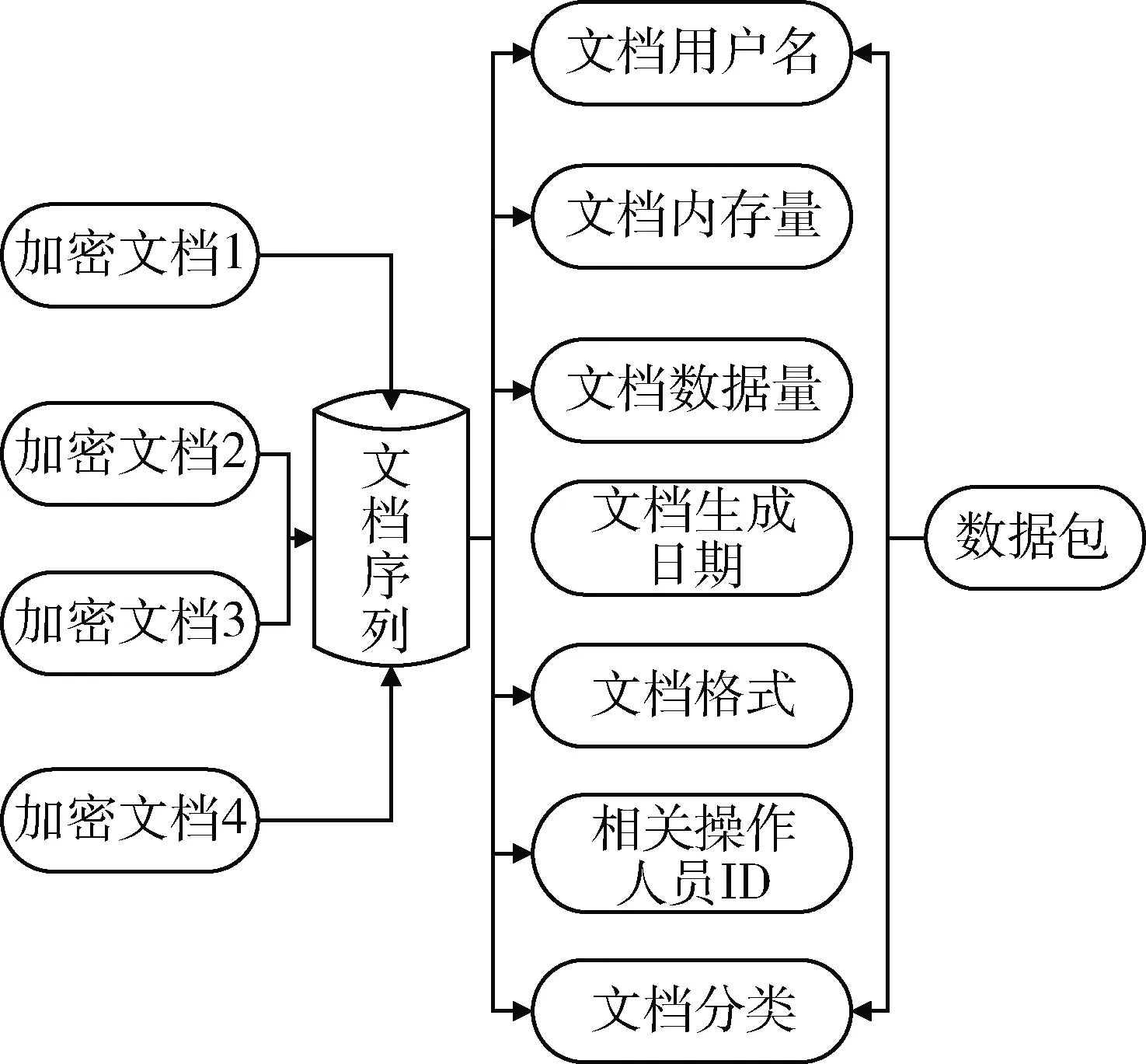
圖3 索引數據集合
在建立Apriority數據序列索引時,需要針對不同的文檔索引格式提出相應的屬性要求。
是否可以進行有效存儲:數據索引是否完全包含加密數據序列,即數據系列數據集是否存在于數據索引存儲中。這種存儲方式需要完全符合小型文本文檔內容的域名格式,否則很容易引起索引序列的索引量過載。
是否可以進行有效索引:如果當前加密數據的索引序列無法被正確索引,那么數據庫安全檢測工具的使用人員就需要在該數據源上進行分配數據檢測,例如加密文檔存儲位置檢索,文檔數據分類檢索,生成額外的檢索條件。
是否出現明確的檢索分詞:檢索分詞主要表現為按照某種特定的分詞計劃進行數據切取后,可以從數據中匹配到的屬性關鍵詞。這種關鍵詞可以有效提高搜索結果的精確度。部分加密數據檢索屬性無法作為關鍵詞使用,如數據文檔生成和歸檔日期等。
根據當前加密數據的索引序列和具體檢索需要,對當前計算機數據庫內屬性加密信息制備檢索數據,如表2所示。
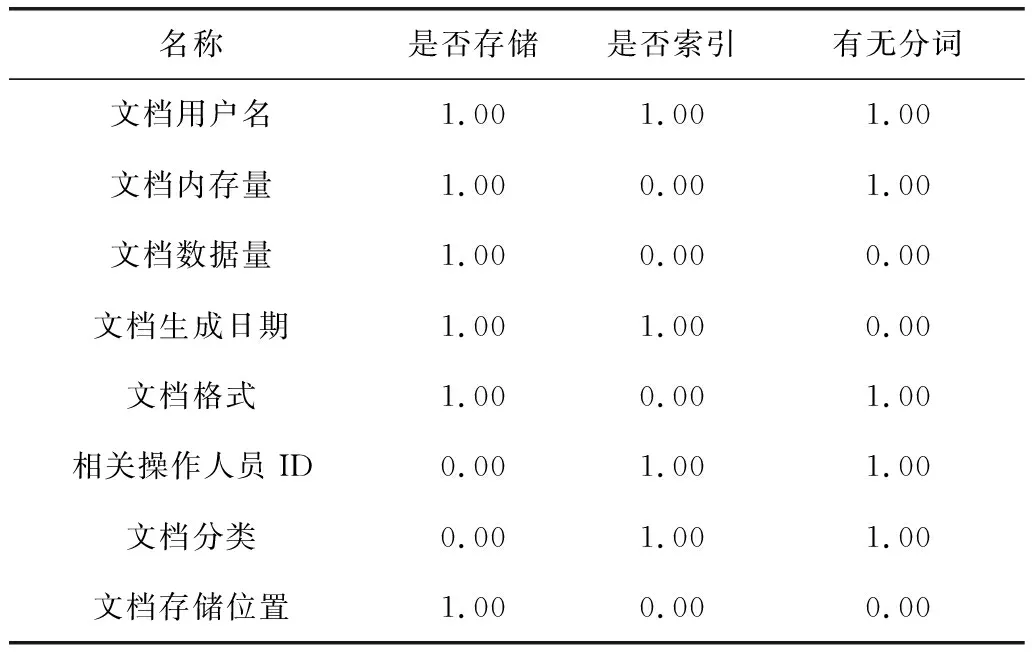
表2 Apriority數據序列索引檢索數據表
1.3 檢測工具完成
目前數據庫安全檢測算法一般采用CDM數據線性規劃算法[8],設計基于上述數據序列索引架構和加密文件域名架構,對其進行改進,提出新的TRIE樹算法,完成數據庫的檢測。TRIE樹結構最早被用于高效檢索字典結構。其根深度被定義為0。結構的第N層節點會指向第N+1層的數據節點,其指向針被稱之為檢索數據邊。每一個數據邊都用對應的字母或者ID表示。例如節點A指向節點B,則認為A節點是B節點的母系節點,B節點是A節點的子系節點。因為TRIE樹結構不僅可以有效存放檢索單次項,還可以存放各種序列集。具體方法就是將TRIE樹的節點或者邊作為有序序列集的子項,此時TRIE樹各個路徑就可以與序列重合。根據上述操作,設計將生成的Apriority數據序列作為序列項,生成序列網格。在進行數據項集發掘時,利用字母代替加密數據序列項集,這樣就可以將加密數據序列表示成由字母構成的單次項。圖4為存放了選項集的一個TRIE樹結構。

圖4 五個選項集下的TRIE樹結構
根據TRIE樹結構,對當前加密數據文件序列事物進行存儲,存儲容器為CECTOR(……),此時選擇安全精簡事物記錄,該記錄需要默認程序選擇。精簡記錄存儲容器為map
進行多次數據庫掃描后,數據庫本體數據項會存在于存儲容器中。這里的精簡事物即只存在于數據庫中的頻繁數據項。此時重復數據將被計數,以此建立數據公式:
(5)
公式中σeq、[σeq]1分別為當前數據庫數據最高項序列和最低項序列;Tmax和[Tmax]1分別為數據庫掃描后的最大存儲和最小存儲;σb和[σb]1數據邊的兩個極值。根據公式(5)數據庫本體文件序列會完全遷移到數據容器中,當出現安全問題項或者未加密數據項時,該項無法生成加密序列,同時無法被遷移,通過文件基數,即可為探知,檢測宣告完成。
2 仿真實驗
為驗證本文設計的基于屬性加密的計算機數據庫安全檢測工具的實際檢測效果,進行有效性試驗檢測。通過對預設目標進行多范圍多角度數據攻擊,獲取檢測數據,進而證明該工具的實際有效性。在試驗過程中,模擬樣本數據建立數據庫。使用CTM數據檢測工具作為對比組,進行檢測效果對比。檢測包括誤用異常檢測和偽裝攻擊檢測兩部分,具體實驗數據如下。
2.1 誤用異常檢測
誤用異常檢測時,主要檢測對象為每條用戶日志以及聚簇規則是否完全匹配,以下為實驗檢測定義。
定義1如果當前數據庫文件的一條日志記錄與當前聚簇規則的兩側規則均具有統一性,則認定其具有匹配規則。
定義2一個加密數據文件如果其加密序列不符合當前聚簇規則,則其可信度加權值作為異常檢測值出現。
根據定義1和定義2,以實驗數據庫為目標,進行誤用異常數據輸出,并利用實驗對比的兩種工具進行檢測,其檢測結果如圖5所示。

圖5 誤用異常檢測率對比
根據圖5數據可以看出,應用設計的屬性加密計算機數據庫安全檢測工具,對誤用異常檢測具有較好的檢測效果。根據數據統計可以確定,其數據庫文件誤用異常檢測率提高了17%,可以證明其有效性。
2.2 偽裝攻擊檢測
偽裝攻擊是對當前數據庫進行主動攻擊活動的總稱。偽裝攻擊檢測,主要驗證檢測工具的魯棒性。實驗共進行了10組有效的偽裝攻擊,其攔截率如表3所示。

表3 偽裝攻擊攔截率
根據以往的數據攔截經驗,當攔截率高于90%時,可以認定為絕對攔截,此時處于絕對安全狀態;當攔截率為75%~90%時,為次攔截屬于基本安全狀態;當攔截率低于70%時,數據庫為危險狀態。根據實驗數據可以看出,應用屬性機密的安全檢測工具,攔截率均高于90%,數據庫處在絕對安全狀態,比傳統CTM檢測工具攔截率提高了20%以上,進一步證明了其有效性。
3 結論
數據庫信息安全,是數據庫建設和維護的核心工作之一。對國民生產和經濟保障具有重要意義。本文基于屬性加密,提出了新型數據庫數據安全檢測工具,可以有效提高數據庫安全保障,具有實際應用價值。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
海峽科技與產業(2016年3期)2016-05-17 04:32:12
財經(2016年3期)2016-03-07 07:44:46
