異構系統中的Web服務器軟件框架研究
2020-06-09 07:17:58尤國華
計算機工程與應用 2020年11期
尤國華,劉 媛,高 東
北京化工大學 信息科學與技術學院,北京100029
1 引言
2018年3月統計顯示,Facebook的用戶已經超過了2.17億,而且還在不斷增加。為了滿足龐大用戶群的互聯網需求,數據中心必須提供更強大的處理和存儲能力。為提升數據中心的性能,傳統的方法是增加數據中心的服務器節點,甚至建立更多的數據中心,因此也會帶來更高的購置成本和使用成本(如耗電量和機房空間等)。為了滿足需求并且降低成本,提升單臺服務器的性能成為重要而迫切的任務[1]。
近年,隨著CPU 主頻遇到天花板,多核+協處理器的異構模型已經成為服務器端架構的主流。協處理器,如GPU、MIC等,可以極大提升服務器端的處理能力,彌補CPU 在某些計算方面的劣勢。相比GPU,MIC 協處理器更適合于云計算這樣的高吞吐量場景。GPU 基于單指令多數據(Single Instruction Multiple Data,SIMD),屬于數據并行。針對云計算場景,如果想充分利用GPU的性能,batch size 就不能太小,但這會引起延遲的增加,從而降低服務質量(Quality of Service,QoS)。而且,對于一些復雜的分支邏輯,GPU會產生“分支退化”的問題[2]。MIC協處理器每個核心與CPU核心類似,適宜于邏輯運算和流水線并行;MIC協處理器的核心雖然主頻低,但數量多,適用于云計算這樣的計算場景[3]。圖1為MIC協處理器Intel Xeon Phi 5110p的示意圖,5110p具有57個物理核心(每個物理核心有4個硬件線程),每個核心的主頻為1.05 GHz。

圖1 Intel Xeon Phi 5110p結構示意圖
雖然MIC 協處理器的加入從硬件方面提升了web服務器的性能,但一些常用web服務器軟件,如Apache、nginx等,均不能充分發揮多核CPU+MIC協處理器的性能優勢。因此,若要充分利用多核CPU+MIC協處理器的異構系統的性能,必須要研究與之匹配的web服務器軟件體系[4]。
雖然以前的研究者對如何發揮GPU、MIC等協處理器的性能進行了不少的研究[5-9],如Agrawal 等[10]針對CPU+GPU 的異構系統提出了Rhythm 的web 軟件框架。Rhythm 依據請求之間的相似性,將請求的處理過程劃分成不同的階段,并將部分處理階段分配至GPU執行。根據他們的實驗結果,Rhythm 可以有效地使用GPU處理用戶請求。但Rhythm適用于處理邏輯比較簡單的請求,對于復雜些的請求,由于GPU 的固有特性,可能導致“分支退化”。Fj?lling 等[11]使用batching 技術充分利用GPU 的SIMD 特性來優化web 應用程序,與CPU相比可提升2到3倍的性能。但他們的工作主要集中在優化特定的web應用程序,缺乏通用性和擴展性。
為了充分利用多核CPU+MIC 協處理器的性能,本文提出了一種新的web 服務器軟件框架。該框架通過將部分動態請求卸載至MIC協處理器執行,從而可以在CPU 和MIC 上并行處理動態請求,進而提升服務器的性能。此外,新框架也能保持多核CPU 和MIC 協處理器之間的負載均衡。
2 新的軟件框架
為充分利用MIC協處理器的計算性能,新框架將一部分到達web服務器的動態請求卸載至MIC協處理器,由MIC 協處理器和多核CPU 并行處理動態請求,從而提升web服務器處理動態請求的效率。同時,新框架也可以在CPU 各核心之間,以及CPU 與MIC 處理器之間達到負載均衡。
2.1 軟件框架描述
新的軟件框架基于分階段事件驅動模型(Staged Event Driven Architecture,SEDA),將web 服務器中請求的處理過程分為Receiver,Reader,Parser,Scheduler,Handler 和Writer 六個階段,分別對應于建立連接,讀動態請求,分析動態請求,動態請求的調度,動態請求的處理和寫響應六個處理過程。每個階段都由一個服務線程池,一個任務隊列和任務處理邏輯構成。其中,Receiver,Reader,Parser,Scheduler 和Writer 五個階段只部署在主機,而Handler 分別部署在主機和MIC 協處理器上。新服務器軟件框架的處理過如圖2所示。

圖2 新模型的處理流程
當用戶請求到達服務器,Receiver 通過epoll[12]技術獲取連接文件符lfd,對用戶端建立連接,然后將lfd送至Reader的任務隊列中,Reader從lfd中讀取TCP包,然后將包中內容送至Parser 的任務隊列中,Parser 解析TCP包,并從中抽取出請求。請求被送至Scheduler 的請求隊列中,由Scheduler 調度請求至CPU 或MIC 協處理器。Scheduler 中內置有請求調度算法,由該算法保證CPU與MIC協處理器之間的負載均衡。
經過Scheduler 的調度,請求被分配至運行在CPU或MIC協處理器上的Handler的請求隊列中,當Handler中有可用的服務線程時,一個服務線程會被分配給該請求。然后,服務線程解析該請求,并獲取要請求的文件名和參數。根據文件名從Cache或內存中,甚至磁盤中載入該文件中的代碼,然后根據從請求中解析出來的參數由服務線程在CPU 或MIC 協處理器上執行該代碼。代碼執行后的結果results 通過TCP 協議發送至Writer的結果隊列中,然后由Writer以HTML的格式發送至網絡,這就是響應。
2.2 請求調度算法
為了提升web服務器的性能,需要將部分請求分配至MIC協處理器上處理,這可能會導致CPU和MIC之間的負載不均衡,因此請求調度算法既要提高請求處理效率,又要保持CPU之間、CPU與MIC協處理器之間的負載均衡。本軟件框架中,請求調度算法部署在Scheduler中,對請求進行分配和調度。
請求同一個頁面的動態請求,其執行過程具有相似性[13],因此可歸為同一類動態請求。如果服務器中N類動態請求,分別是R1,R2,…,RN。動態請求對處理器的負載沖擊主要來自動態請求的數量和動態請求的服務時間,因此可用兩者的乘積表示負載,即:

其中,CC(i)是第i 種動態請求的數量,TC(i)是第i 種動態請求的服務時間,而WC(i)表示第i 種動態請求對處理器的負載沖擊。
若有P個處理器,而處理器j 上有N 類動態請求,每類動態請求的數量分別為CC(1,j),CC(2,j),…,CC(N,j),每類動態請求在處理器j 上的服務時間分別為TC(1,j),TC(2,j),…,TC(N,j),那么請求在處理器j 上產生的總負載可表示為:

動態請求的服務時間可以通過文獻[14]的方法獲取,動態請求某時間段的數量可以統計獲得。因此,從時間t0到時間tcurrent這段時間內,如果各類動態請求到達的數量分別為CC(1,j),CC(2,j),…,CC(N,j),那么時間tcurrent時處理器j 的負載可表示為:

其中,Δt=tcurrent-t0。因為在Δt 時間內,隨時間的推移,處理器會處理掉一部分動態請求,因此計算各處理器負載時要減去這段時間,但當Δt 大于各類動態請求產生的負載時長時,表明此段時間內處理器處于空閑狀態,因此負載為0。
為充分利用多核處理器中緩存的局部性和NUMA架構的特性[15],同一類動態請求最好分配至同一個處理器上,而且需要同時維護各處理器之間的負載均衡。因此,可以根據各CPU處理器的負載狀態W′j(1 ≤j ≤P)和各CPU 上動態請求的種類和數量分配新到的動態請求。若第i 種動態請求到達服務器,各CPU上負載的均值為,而第i 種動態請求在各處理器上的數量分別為CC(i,1),CC(i,2),…,CC(i,P),則可根據下式分配第i 種動態請求:

Lj(1 ≤j ≤P)中若Ll值最大,說明處理器l 上負載越小且第i 種動態請求的數量多,因此將第i 種動態請求分配至處理器l 上,可同時兼顧處理器間的負載均衡和緩存局部性。其中,α β 為公式的修正系數,可根據實際情況進行修正。
同時Scheduler可監測各處理器的負載狀態,當CPU處理器平均負載超過λ(設定的閾值)時,新到的動態請求會被分配至MIC協處理器處理。
當動態請求i 到達服務器時,各CPU處理器平均負載E(W′C)>λ,此時需要將新到的動態請求i 分配至MIC協處理器處理。
假定有Q 個MIC 協處理器,當動態請求i 到達MIC k 協處理器時(此時刻記為t′current),從時間t′0到時間t′current,協處理器MIC k 上分配到的各類動態請求數為CM(1,k),CM(2,k),…,CM(N,k)。每類動態請求在MIC k 上的服務時間分別為TM(1,k),TM(2,k),…,TM(N,k)。那么,請求在協處理器MIC k 產生的總負載可由下列公式計算:

那么時間t′current時MIC k 上的負載可表示為:
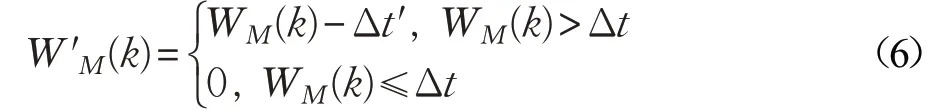
其中,Δt′=t′current-t′0。因為在Δt′時間內,隨時間的推移,協處理器會處理掉一部分動態請求,因此計算各處理器負載時要減去這段時間,但當Δt′大于各類動態請求產生的負載時長時,表明此段時間內處理器處于空閑狀態,因此負載為0。
那么,各MIC上的負載的均值為E(W′M)=(W′M(1)+W′M(2)+…+W′M(Q))/Q,而第i 種動態請求在各處理器上的數量分別為CM(i,1),CM(i,2),…,CM(i,Q),出于負載均衡和緩存局部性的考慮,可由下式分配動態請求i 至那個MIC協處理器。

Gk(1 ≤k ≤P)中,若Gr值大,說明MIC r 上負載小且第i 種動態請求的數量多,因此將第i 種動態請求分配至協處理器MIC r 上,可同時兼顧協處理器的負載均衡和緩存局部性。其中,μ,ν 為公式的修正系數,可根據實際情況進行修正。
經過上述步驟,到達Web服務器的動態請求可以被分配至合適的CPU 或MIC 協處理器上,分配的過程同時兼顧了負載均衡和緩存局部性,可以最大化地利用異構系統的計算能力,從而提高了動態請求的處理能力。
調度算法的偽碼描述如下:
//用于存儲P 個CPU處理器上已分配的N 類請求的數量
array CC[N,P]
//用于存儲P 個CPU處理器上N 類請求的服務時間
array TC[N,P]
//用于存儲Q 個MIC處理器上N 類請求的服務時間
array TM[N,Q]
//用于存儲Q個MIC處理器上已分配的N 類請求的數量
array CM[N,Q]
初始時間為t0
While(true)
{
第i 個請求到達scheduler,此時時間為tcurrent
//當前時間與初始時間的差值
Δt=tcurrent-t0
//用于記錄每個CPU的上的歷史總負載情況
array WC[P]
array W′C[P]
for(j=0; j <P; j+ +)
{
WC[j]=CC[i,j]TC[i,j]
If(WC[j]≥Δt)
W′C[j]=WC[j]-Δt
Else
W′C[j]=0
}//for
If(E(W′C)>λ)//CPU負載過大
{
//表示每個MIC的上的歷史總負載情況
array WM[Q]
array W′M[Q]
for(j=0; j <Q; j++)
{
WM[j]=CM[i,j]TM[i,j]
If(WM[j]≥Δt)
W′M[j]=WM[j]-Δt
Else
W′M[j]=0
}//for
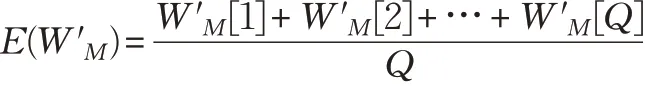
array G[Q]
for(k=0; k <Q; k++)
{

}
//求G[k]中的最大值Gmax(r)
Gmax(r)=Max{G[k]}
將該請求分配至第r 個MIC處理器
CM[i,r]++
}//If
Else
{
array L[P]
for(j=0; j <P; j++)
{

}
//求L[j]中的最大值Lmax(l)
Lmax(l)=Max{L[j]}
該該請求分配至第l 個CPU處理器
CC[i,l]++
}//Else
}//while
3 實驗及評估分析
3.1 實驗設置
本實驗采用如圖3 所示拓撲圖,多臺客戶端PC 采用httperf 向服務器Server 發送動態請求。本實驗采用一個6 核12 超線程的CPU 和一個MIC 卡作為實驗平臺,MIC協處理器為Intel Xeon Phi 5110p,具有512位SIMD 指令集,57 個物理核心,每個核心有4 個硬件線程。基于新軟件框架開發的服務器程序NSFS(New Software Framework Server)部署在服務器Server 上,用于處理到達服務器的動態請求。作為對比,基于傳統的先到先服務(FCFS)算法開發了web 服務器程序uFCFS,部署于兩臺6 核12 超線程的服務器節點上,其中一臺兼作負載均衡器使用,采用輪詢的方式向本身和另一臺部署uFCFS 的服務器轉發動態請求,由uFCFS處理動態請求,并返回響應。

圖3 實驗拓撲圖
本文基于上述兩個仿真web 服務器程序NSFS 和uFCFS 進行實驗,并主要從吞吐量、平均響應時間對兩者進行評估。其中,httperf 的并發數、動態請求的服務時間是可以調整的,本文在調整這些參數的情況下進行了一系列實驗,測量吞吐量、平均響應時間隨并發數和動態請求服務時間變化的情況。
3.2 結果評估
(1)隨并發數的變化
在保持其他實驗參數保持不變的前提下,改變httperf 發送動態請求的并發數(從100 至10 000),對兩個仿真web 服務器程序NSFS 和uFCFS 進行實驗,并分別測量計算兩個仿真web 服務器程序的吞吐量和平均響應時間。實驗結果如圖4所示。
由圖4 可看出,當動態請求的并發數不斷增加時,同時到達web服務器的請求數量增多,所以導致請求排隊變長,從而導致uFCFS和NSFS的平均響應時間隨并發數的增加而增加。但uFCFS 的平均響應時間在此過程中,增加的幅度要大于NSFS 的幅度,這說明使用NSFS框架的web服務器可以充分利用多核CPU和MIC協處理器的運算能力,其處理請求的能力要強于uFCFS,即基于CPU+MIC協處理器的異構web服務器的性能要強于由兩個運算節點組成的web服務器。
uFCFS和NSFS的吞吐量可根據如下公式分析:

當并發數增加時,uFCFS 和NSFS 的平均響應時間均增加,因此根據公式(8)可知,兩者的吞吐量變化均不會大。由于NSFS能充分利用MIC協處理器,因此運算能力更強,所以平均響應時間也更短一些,從而其吞吐量要高于uFCFS,分析結果與圖4中的實驗結果一致。
(2)隨服務時間的變化
用戶請求的服務時間變化比較大,呈現重尾分布的特點[16],為模擬真實場景,不失一般性,本文實驗中的請求服務時間是可以調整的。當增大服務時間時,測量uFCFS 和NSFS 兩種服務器的吞吐量和平均響應時間,圖5為測得的結果。
根據圖5,當服務時間增加時,uFCFS和NSFS 的吞吐量均下降,這是由于隨著服務時間增加,兩種web 服務器處理動態請求的時間都隨之增長,因此導致兩種服務器的吞吐量均下降。但是NSFS 的吞吐量一直大于uFCFS,這是因為NSFS 可以整合多核CPU 和MIC協處理器的運算能力,整體性能要優于由兩臺普通節點構成的uFCFS 服務器。隨服務時間增加,uFCFS 和NSFS 的平均響應時間均增加,這是由于服務時間的增加會加重服務器的負載,從而導致排隊時間的增加,進而延長了服務器的平均響應時間。而NSFS 的平均響應時間始終低于uFCFS,這也證實了NSFS 的性能要優于uFCFS。
4 結論
本文針對由多核CPU和MIC協處理組成的異構系統,提出了可充分發揮該系統運算性能的動態請求調度算法。該算法基于分階段事件驅動模型,將動態請求的處理過程分為多個階段,運算較密集的動態請求處理階段由多核CPU 和MIC 協處理器并行承擔,并通過負載均衡算法保持多核CPU和MIC協處理器之間的負載均衡。基于此模型,本文開發了對應的仿真程序,并進行了相關的仿真實驗。實驗表明,基于該算法的web服務器的吞吐量、平均響應時間均優于由兩個節點構成的采用傳統FCFS算法的仿真web服務器。
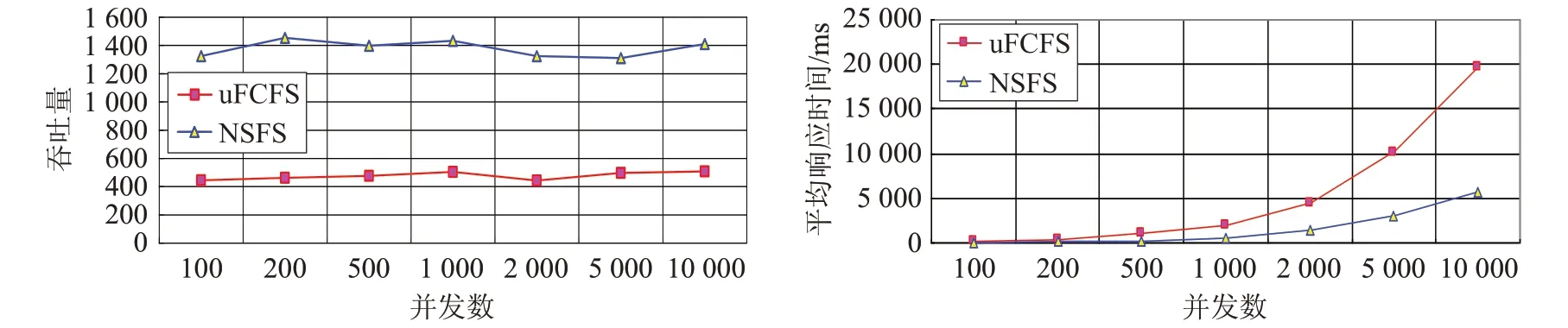
圖4 兩個仿真程序隨并發數變化時的性能對比

圖5 兩個仿真程序隨服務時間變化時的性能對比
猜你喜歡
艦船科學技術(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
