針對不平衡數據的過采樣和隨機森林改進算法
2020-06-09 07:18:10張家偉郭林明楊曉梅
計算機工程與應用 2020年11期
張家偉,郭林明,楊曉梅
四川大學 電氣工程學院,成都610000
1 引言
目前,對于二分類問題,機器學習方法大多基于正負樣本的比例相近這一假設建立分類模型[1],而在實際應用中,通常會出現數據不平衡現象,這種不平衡常會給分類器的實用性帶來很大的影響,如醫(yī)療領域的腫瘤診斷,假設腫瘤診斷數據集中有100 樣本,其中99 個正樣本(良性腫瘤),1個負樣本(惡性腫瘤),分類器經過訓練后,把這100個樣本都分為了正類,準確率為99%,然而被誤分的這個負樣本卻可能影響診斷結果。因此,當遇到數據不平衡問題時,以總體分類準確率為學習目標的傳統(tǒng)分類算法會過多地關注多數類,從而使得少數類樣本的分類性能下降,難以獲得有效的分類模型。
國內外現有對數據不平衡問題的解決方法一般有三類:數據預處理、代價敏感學習、集成學習分類[2-3]。數據預處理分為過采樣和欠采樣,過采樣利用少類樣本生成新樣本來提升少數類樣本數量,應用最為廣泛的是SMOTE[4],SMOTE在每個少數類樣本與其K 個近鄰樣本之間的連線上產生合成新樣本。然而SMOTE沒有對每個樣本進行區(qū)別選擇,這會導致生成冗余樣本。針對文獻[4],文獻[5-6]使用聚類、最近鄰的方法改變用于合成新樣本的中心樣本,一定程度避免了生成樣本的冗余現象。欠采樣通過舍棄多數類樣本來平衡數據集,如文獻[7-8],雖然保留下來的樣本相對具有代表性,但依然有可能丟棄對分類有用的樣本。代價敏感學習在分類算法中引入代價函數,通過最小化錯分代價構造分類器,如文獻[9-10]通過數據的非平衡系數和決策樹的分類準確度給決策樹加權,增加模型對少數類樣本判錯的代價,提升少數類樣本分類正確率。集成學習分類把性能較低的多種弱學習器通過適當組合形成高性能的強學習器,如文獻[11-12]將Adaboost 與過采樣和欠采樣結合,提出SMOTEBoost 和RUSBoost 算法,使分類器有更強的魯棒性,提高了分類器準確率。文獻[13]使用欠采樣和隨機森林算法根據氣象參數預測PM2.5濃度,獲得了較好的預測精度,文獻[14-17]使用隨機森林(Random Forest,RF)算法在多種不平衡數據分類場景和其他工程領域應用中取得了良好的效果,模型泛化能力強。
然而這些方法容易出現兩個方面的問題,數據預處理層面,欠采樣可能會丟棄對分類器很重要的有價值的潛在信息[18],經典的過采樣SMOTE 算法每個樣本合成相同數量的新樣本,沒有充分利用那些更具有類別代表性樣本,可能會產生冗余數據。算法層面,隨機森林算法在分類問題方面已經得到了廣泛的應用,但是,受樣本不平衡影響,在訓練階段隨機選取訓練集時會加劇訓練樣本的不平衡度,其次,每棵決策樹在投票時權重都相等,但受訓練時的數據影響每棵決策樹的分類效果不同,總會有一些訓練效果不高的決策樹投出錯誤的票數,從而影響隨機森林的分類能力。
為了解決上述問題,本文提出了加權過采樣和加權隨機森林算法。加權過采樣策略根據每個少數類樣本相對于剩余少數類樣本的歐式距離給每個樣本分配不同的權重,利用SMOTE算法合成新樣本過程中,每個少數類樣本生成新樣本的數量根據其權重變化,從而增加更有類別代表性樣本合成數量。加權隨機森林根據Kappa系數評價決策樹訓練效果,給每棵樹分配不同的權重,每棵決策樹在進行投票時,通過權重的設置,提高分類效果好的決策樹的投票話語權,降低效果差的決策樹對結果的影響。加權過采樣和加權隨機森林結合使用能夠進一步提升算法的分類效果。
2 加權過采樣
經典的過采樣SMOTE 算法中,每個少數類樣本生成的新樣本數量是相同的,這會產生很多對類別區(qū)分價值不大的樣本,從而影響之后的分類器訓練效果。因為并不是每個樣本對類別區(qū)分的價值都一樣,離類別中心越近的樣本更能代表本類特征,離邊界越近的樣本能夠更好地區(qū)分不同類別的界限,這兩種樣本包含更多的分類信息,對分類的價值更大,希望能夠充分利用樣本與類別中心和邊界的距離,在SMOTE 算法中讓靠近類別中心和邊界的樣本生成新樣本數量更多。對此,使用每個少數類樣本相對于剩余少數類樣本的歐式距離確定每個樣本的相對位置,為每個樣本分配不同的權重。使靠近類別中心和類別邊界的樣本擁有更大的權重,在生成新樣本時,每個樣本根據權重確定生成數量,權重越大,生成數量越多。
2.1 權重計算步驟
設訓練集的一個少數類的樣本數為M ,每個樣本包含C 個特征。
(1)計算每個樣本到其他樣本間的歐氏距離,如式(1)所示:
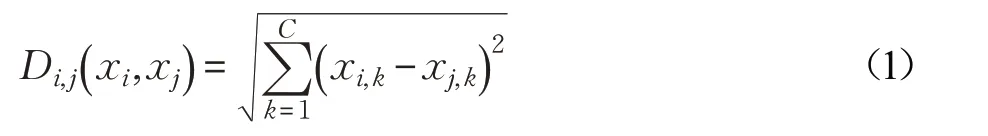
式中,i=1,2,…,M ,j=1,2,…,M ,i ≠j,Di,j( xi,xj)表示第i 和j 兩個樣本間歐式距離。
(2)計算樣本xi到其他樣本距離之和Di,Di越大表示xi越靠近邊界,Di越小表示xi越靠近中心,如式(2)所示:
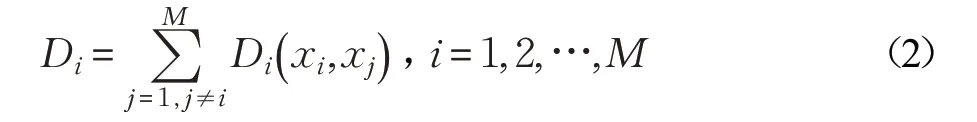
(3)對Di進行歸一化,如式(3)所示:
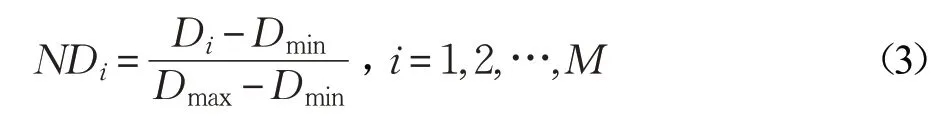
(4)計算RNDi,即為ND 中各元素與ND 均值之差的絕對值,RNDi越大則表示該樣本越靠近類別中心或者類別邊界,樣本價值越高,對分類更有效,它所生成的新樣本數量就應該越多,如式(4)所示:
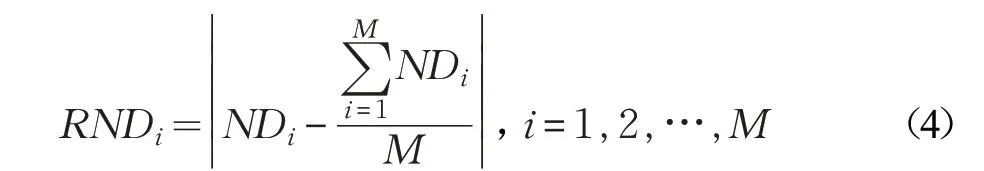
(5)計算每個樣本的權重,如式(5)所示:
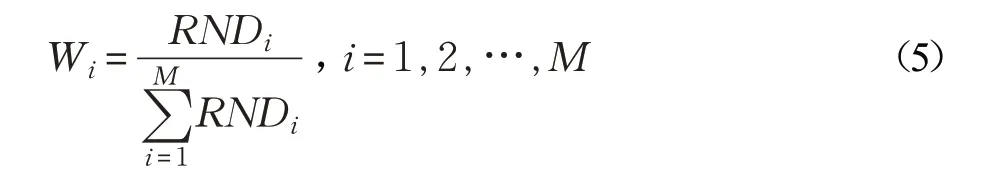
Wi為第i 個樣本的權重值。需要生成新樣本的數量乘以此權重即為最終該樣本生成新樣本的數量。
表1展示了新樣本生成數量隨權重變化的特點,假設某少數類有5 個樣本A、B、C、D、E,需要生成的新樣本總數為25,那么傳統(tǒng)SMOTE方法中每個樣本都會生成5 個新樣本,為簡化計算,給每個樣本到其他樣本距離之和D 隨機賦值,如表1 中所示,經過權重計算步驟后,每個樣本的生成數量不一樣,靠近中心和邊界的樣本生成數量更多。
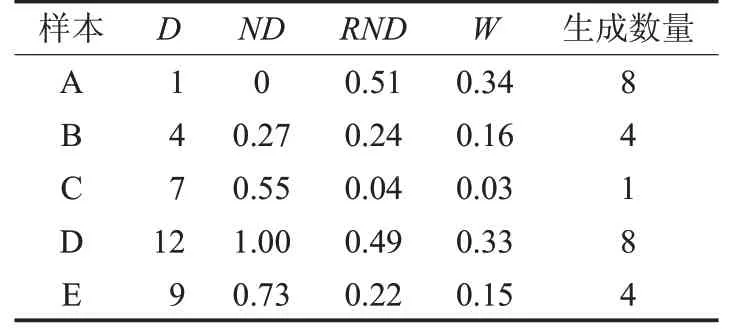
表1 權重計算示意
2.2 加權SMOTE算法步驟
設加權SMOTE 算法將為訓練集的少數類合成N個新樣本,N 是正整數。
(1)對于該少數類中第i 個樣本xi,計算它到該類其他所有樣本間的歐式距離,得到其k 個近鄰樣本。
(2)對于第i 個樣本xi,從其k 個近鄰樣本中隨機選取個樣本為向下取整。
(3)在(2)中選取的Nw個樣本中,根據公式(6)生成Nw個關于少數樣本xi的新樣本。
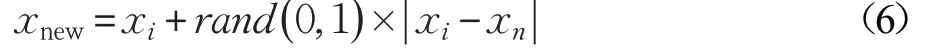
其中,rand( )0,1 是0 和1 之間的隨機數。SMOTE 和加權SMOTE示意圖如圖1所示。
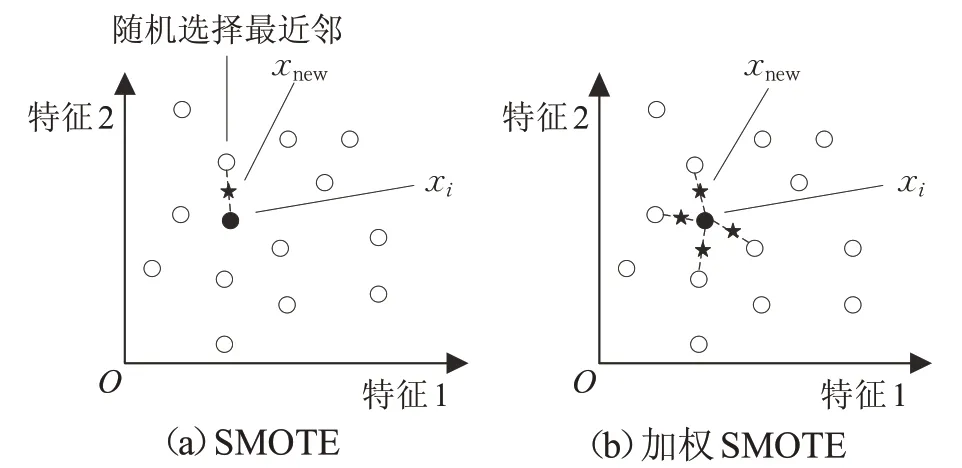
圖1 SMOTE和加權SMOTE示意圖
3 加權隨機森林
3.1 隨機森林算法
隨機森林算法是Breiman L[19-21]提出的一種分類算法,它是一種集成機器學習方法,實質是將Bagging算法和random subspace算法結合起來構建了一個由多棵互不相關的決策樹組成的分類器,它改善了決策樹容易發(fā)生過擬合現象的缺點[22],訓練樣本采用自助法重采樣(Bootstrap)技術,從原始數據集中有放回重復隨機抽取N 個樣本作為一棵樹的訓練集,每次隨機選擇訓練樣本特征中的一部分構建決策樹,每棵決策樹訓練生長過程中不進行剪枝,最后采用投票的方式決定分類器最終的結果。例如,對一個訓練好的隨機森林模型,測試集為X,類別數為C,決策樹數量為T,則模型的輸出為:
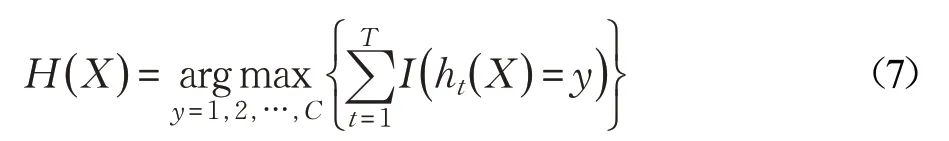
其中,ht( X )為第t 棵決策樹的輸出,I(?)是一個指示函數,函數中參數為真時,函數值等于1,否則等于0。
3.2 加權隨機森林算法
由公式(7)可知,每棵決策樹在投票時權重都相等,但是由于每棵樹訓練集不同,又互相獨立訓練,所以決策樹的分類精度會不同,加之受到樣本類別不平衡的影響,會進一步影響決策樹的分類效果,使得一些效果不好的樹投出錯誤的票數,從而影響隨機森林的分類能力。為此本文提出了加權隨機森林模型,主要方法是在決策樹訓練階段,評估決策樹的分類效果,并給每棵樹賦予一個權重,在隨機森林算法投票時,每棵樹都要乘對應的權重值,這樣可以降低訓練精度不高的決策樹對整個模型的影響。因此,公式(7)中的模型輸出改寫為:
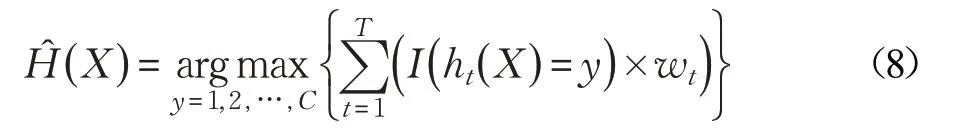
其中wt為第t 棵決策樹的權重值。
從原始訓練集中有放回地隨機抽取樣本作為每棵樹的訓練集,抽取數量等于原始訓練集樣本數量,由于是有放回抽樣,會有部分樣本未被抽中,這部分被稱為袋外樣本[23],數量通常為原始樣本數量的三分之一,利用袋外樣本作為每棵樹的測試集來評估分類性能,并據此賦予該決策樹相應的權重,使分類性能更好的決策樹擁有更大的權重。
對于使用不平衡數據的分類器,常用的分類精確度這個評價指標無法很好地衡量分類能力,因為它只考慮了被正確分類樣本的情況,認為多數類和少數類的分類錯誤同樣重要[24]。因此,使用Kappa 系數(Kappa Coefficient,CK)來評價決策樹整體分類能力,CK 是1960年Cohen等人提出用于評價判斷的一致性程度的指標,它同時考慮了各種漏分和錯分樣本,代表著分類與完全隨機的分類產生錯誤減少的比例,其計算結果為(-1,1),但通常情況下CK 是落在(0,1),CK 值越大說明預測結果和實際結果一致性越高,分類器性能越好[25]。CK計算如式(9)所示:

其中,ACC(accuracy)為分類精確度,表示分類的實際一致性比率,CKc為分類的偶然一致性比率。 ACC 和CKc通過表2所示的混淆矩陣[26]計算得到。
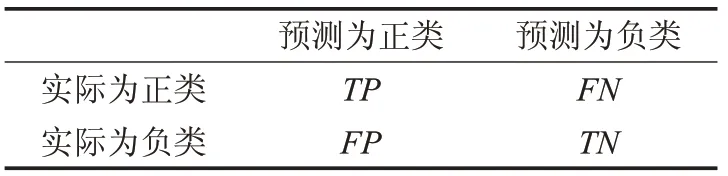
表2 二分類混淆矩陣
混淆矩陣中,TP(True Positive)表示實際是正類,預測也是正類的樣本數。FN(False Negative)表示實際是正類,預測是負類的樣本數。FP(False Positive)表示實際是負類,預測為正類的樣本數。TN(True Negative)表示實際是負類,預測為負類的樣本數。
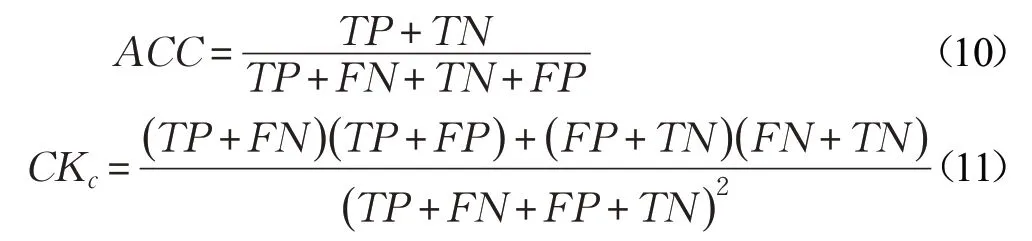
為了把更大的權重分配給更有能力的分類器,文獻[27]研究表明:若一組獨立的分類器L1,L2,…,LM相互獨立,精確度為p1,p2,…,pM,那么每個分類器權重和對應精確度關系如公式(12)所示:
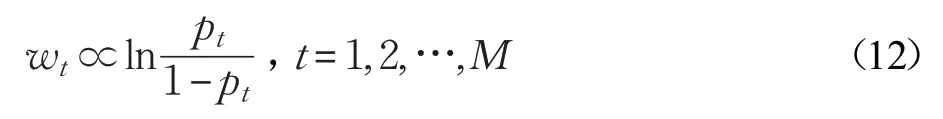
用CK 替換公式(12)中的pt,由于CK 的取值范圍為(-1,1),將公式(12)改寫為公式(13):
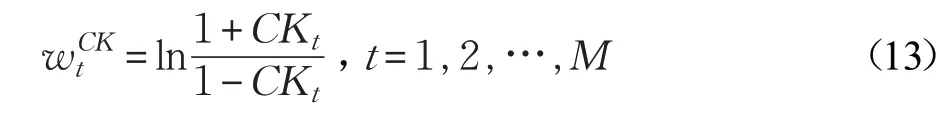
根據公式(14),決策樹的CK 值越高,則其分配的權重也越大,對最終投票的結果影響也更大。CK 和權重W的關系如圖2 所示。將公式(13)帶入公式(8),就能得到隨機森林分類器最終的輸出結果。
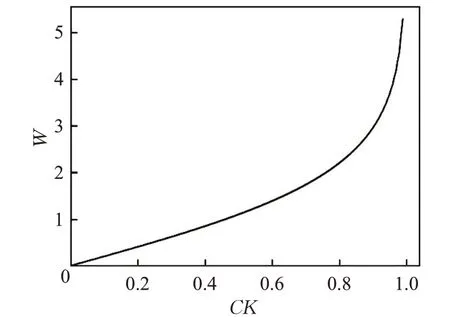
圖2 CK 和權重W 關系圖
整體算法流程如圖3所示,從數據預處理和算法兩個層面進行改進,數據預處理階段進行過采樣時,通過少數類樣本在類內的距離分布區(qū)分其對分類的重要程度,給每個樣本加權,減少生成冗余樣本,從數據層面提高訓練集的質量,使后續(xù)分類算法在訓練階段能夠獲得更多有效的少數類樣本信息,從而提高算法對少數類樣本的分類正確率,根據混淆矩陣與第4章的評價指標計算公式可知,少數類樣本分類正確率的提高又能提升整體分類性能。算法改進階段通過CK評價每棵決策樹整體分類效果,并根據CK給每棵決策樹分配投票權重,減少分類效果不好的決策樹對結果的影響,使算法的輸出結果更加合理,提高對數據集的整體分類性能。因此,這兩個層面的加權改進是有必要的。
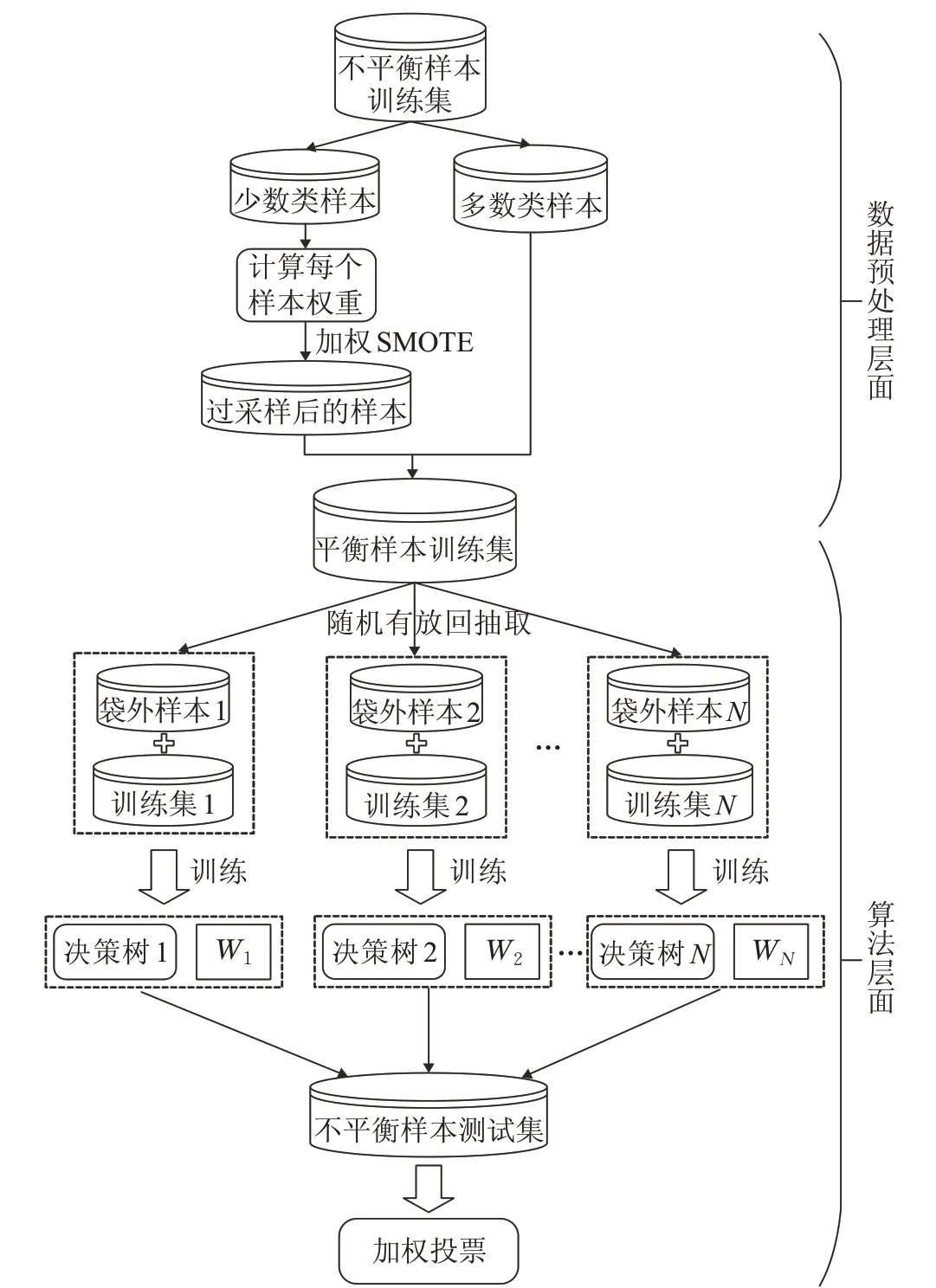
圖3 算法流程圖
4 實驗
4.1 數據集
為了驗證改進算法的有效性,從KEEL[28]數據集倉庫中選取了5個非平衡二分類數據,這些數據的信息如表3所示。
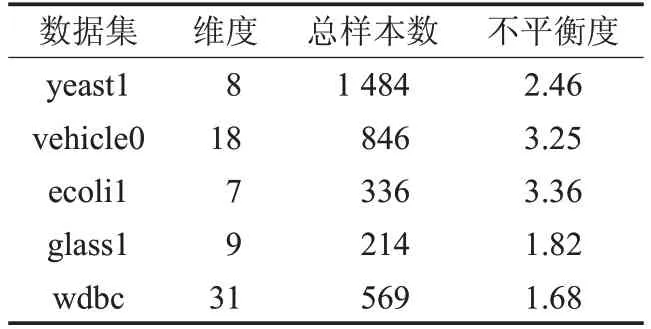
表3 實驗數據集
4.2 評價指標
對于不平衡數據集,分類精度無法全面地評估分類效果,采用特異度(specificity)、CK、G-mean 進行評價,特異度用來評價少數類樣本分類的正確率。CK 和Gmean 用來評價不平衡數據集整體分類性能,G-mean 表示少數類分類精度和多數類分類精度的幾何平均值,是保持多數類、少數類分類精度平衡的情況下最大化兩類的精度。

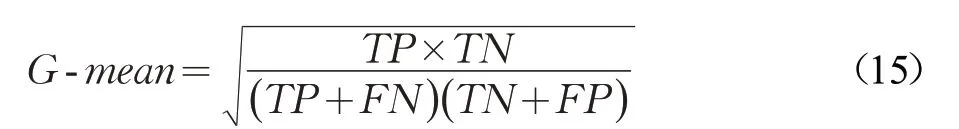
4.3 實驗結果
將SMOTE(SM)、加權SMOTE(WSM)、隨機森林(RF)、加權隨機森林(WRF)不同組合形成的算法,即SM+RF、WSM+RF、SM+WRF與本文算法(WSM+WRF)進行對比,實驗這4 種算法在vehicle0 數據集上的分類結果。數據集中多數類樣本和少數類樣本分別取70%作為訓練集,30%作為測試集,隨機森林算法中兩個常用參數為決策樹的數量(ntree)和隨機選擇特征的數量(mtry),隨著ntree 的增加,隨機森林分類誤差會趨于穩(wěn)定,由于隨機森林具有不會過擬合性,將ntree 設置足夠大。mtry 用來協調分類性能和多樣性之間的平衡[29],將mtry 設置為特征總數的平方根。
圖4 和圖5 為在vehicle0 數據集上四種算法組合的特異度和G-mean 對比結果。由圖可知,隨機森林算法中決策樹數量增加到100 棵左右時,specificity 和Gmean 趨于穩(wěn)定。在這兩個指標的表現上,WSM+RF 算法優(yōu)于SM+RF算法,WSM+WRF算法優(yōu)于WSM+RF算法,SM+WRF 算法優(yōu)于WSM+RF,結果表明,都使用隨機森林分類器的情況下,加權SMOTE 比SMOTE 對不平衡數據的處理更有效,經過訓練后,能夠使更多的少數類樣本得到正確的區(qū)分,有助于提高分類器整體分類能力。都使用加權SMOTE 處理數據的情況下,加權隨機森林比隨機森林的分類能力更好。
為了進一步驗證加權SMOTE和加權隨機森林對分類結果的影響,用未過采樣Ori+RF、Ori+WRF、SM+RF、WSM+RF、SM+WRF 與本文算法在更多數據集上進行實驗,分類結果取決策樹數量大于100 后的穩(wěn)定值,結果如表4所示,可以看出,WSM、WRF與Ori和RF相比,都能提升分類結果的specificity,使少數類的分類正確率得到提高。通過表4中Ori+RF和Ori+WRF的結果可以看出,WRF對數據集的整體的分類效果提升明顯,每個數據集的CK 和G-mean 均有提升,與未改進算法相比,CK 最高提升了3.75%,G-mean 最高提升了2.56%。通過表4、表5中Ori+RF、SM+RF、WSM+RF結果可以看出,SM的CK和G-mean高于Ori,WSM的CK和G-mean又高于SM,因此,WSM對數據集的整體分類效果也有提升。vehicle0使用WSM+RF算法的CK高于SM+WRF,ecoli1使用WSM+RF算法的CK和G-mean高于SM+WRF,glass1和wdbc使用WSM+RF算法的CK和G-mean低于SM+WRF,這是因為vehicle0 和ecoli1 數據集的不平衡度比glass1和wdbc高,WSM從數據層面的改進比WRF從算法層面的改進對分類效果的提升更明顯。本文算法結合WSM和WRF對不平衡數據集的整體分類效果最好。
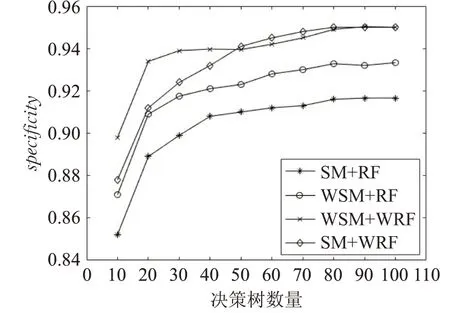
圖4 vehicle0數據集specificity對比圖
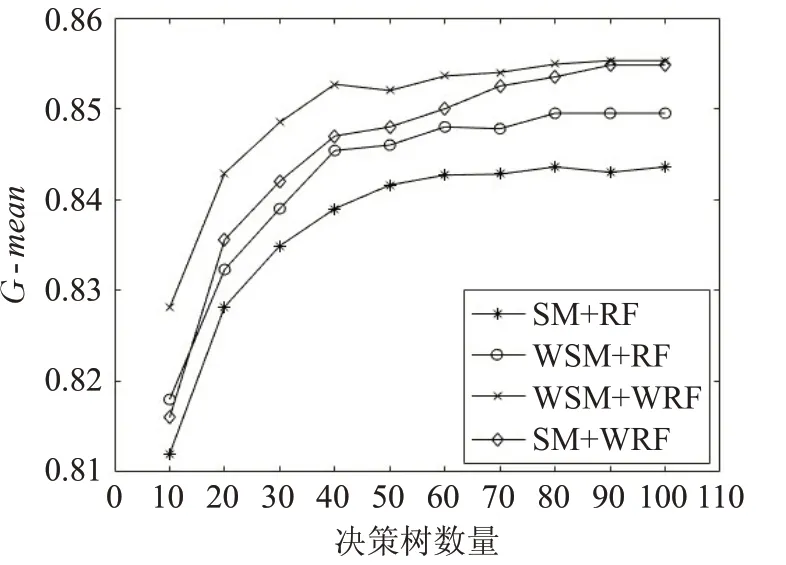
圖5 vehicle0數據集G-mean對比圖
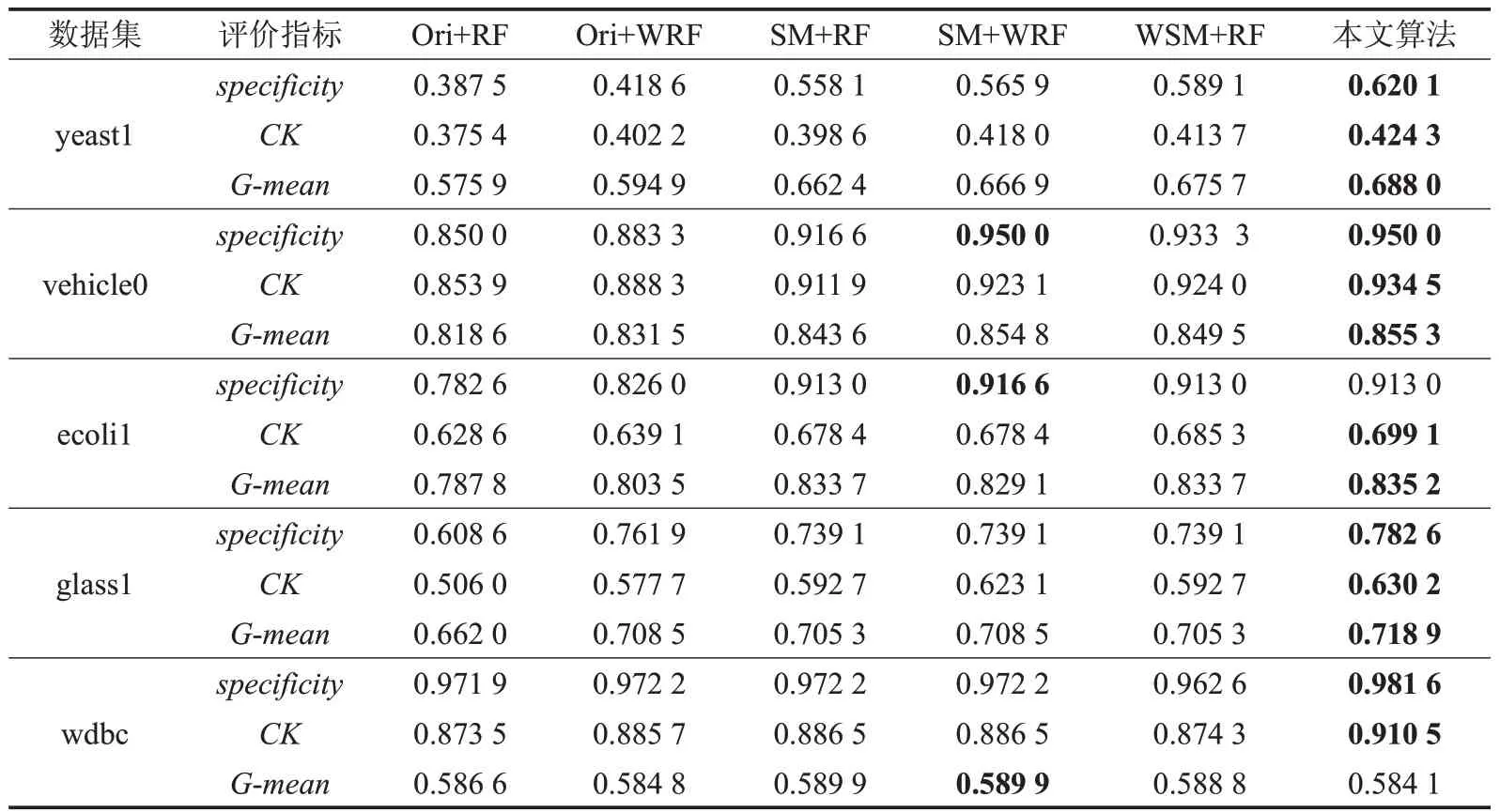
表4 不同數據集上不同算法與本文算法分類結果對比
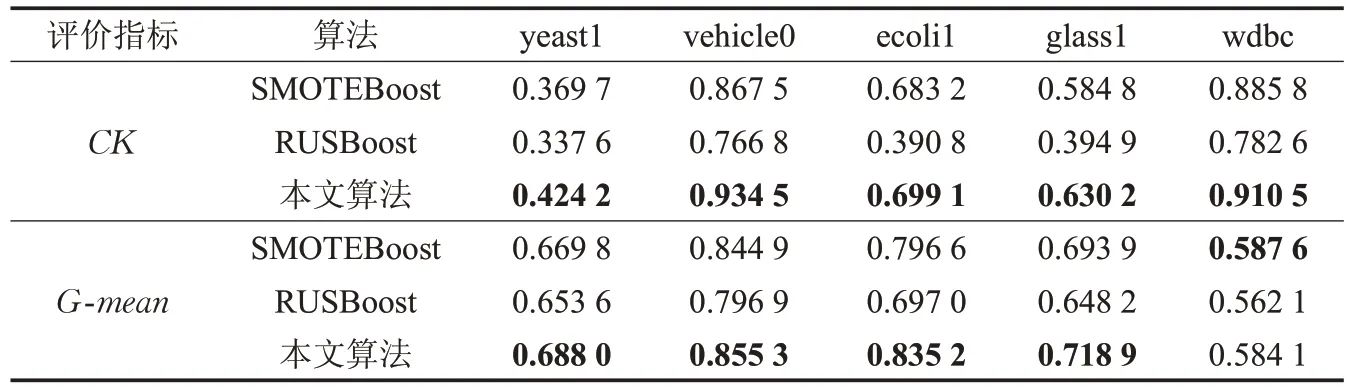
表5 本文算法與其他算法分類結果對比
4.4 與其他算法比較
為驗證本文提出的加權SMOTE和加權隨機森林算法的有效性,與SMOTEBoost、RUSBoost算法進行對比,如表5所示,可以看出,本文WSM+WRF算法在yeast1、vehicle0、glass1、wdbc 數據集上的G-mean 和CK 比其他兩個算法都有明顯的提升,wdbc 數據集上G-mean低于SMOTEBoost算法,但CK 依然比其他兩個算法高。
5 總結與展望
針對數據不平衡對分類器分類性能影響的問題,本文在原有的算法基礎上從數據層面和算法層面提出了兩種改進,數據層面提出加權SMOTE算法,根據少數類樣本間的相對歐式距離生成更多有價值的少數類樣本,提升分類器訓練效果,算法層面提出加權隨機森林算法,給分類效果更好的決策樹分配更高的投票權重,從而提升隨機森林算法的分類準確性,通過在一系列數據集上的實驗表明,加權SMOTE 和加權隨機森林算法可以提升少數類樣本分類準確率,對不平衡數據集的整體分類效果有顯著的優(yōu)化。但本文改進算法也存在一定的局限性,對不平衡度較高和特征維度較高的數據集分類效果提升不明顯,這是因為在特征維度較高時,歐式距離并不能很好地衡量樣本的空間分布,不平衡度較高時,少數類樣本數量相對較少,類別邊界和中心不明顯,這些會影響到加權SMOTE的權重分配,產生冗余樣本,從而影響分類效果。雖然并不是在所有數據集上都能夠取得顯著的效果,但本文提出的算法為處理數據不平衡分類問題提供了一種可選擇參考的思路。在今后的工作中,會對不同類型的不平衡數據集分類問題進行更加深入的研究。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中華詩詞(2018年11期)2018-03-26 06:41:34
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年8期)2016-10-09 02:11:50
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
