基于深度學習的刺網與拖網作業類型識別研究
2020-06-10 01:30:40湯先峰張勝茂裴凱洋
海洋漁業 2020年2期
湯先峰,張勝茂,樊 偉,裴凱洋
(1.中國水產科學研究院東海水產研究所,農業農村部東海漁業資源開發利用重點實驗室,上海 200090;2.上海海洋大學信息學院,上海 201306)
我國漁船擁有量大,據2018中國漁業統計年鑒[1]報道,我國近海機動捕撈漁船超17萬艘,作為典型近海捕撈作業方式的刺網和拖網捕撈漁船數占總船數的72.6%。目前捕撈漁船需提前申請捕撈許可證并登記作業類型,但實際作業過程中可能存在不遵守規則情況,導致網具使用比較混亂。違規作業會對漁業資源和海洋生態環境產生不利影響,因此準確的漁船作業識別可為漁船的有效管理帶來幫助。
國內外對于漁船作業監控,主要有以下3種手段:傳統現場監測、基于衛星遙感技術的漁船作業監測和基于漁船監控系統(vessel monitoring system,VMS)的漁船作業監測。傳統的海上巡邏和登臨檢查準確度高,但監控難度大、成本高、風險高、檢查數量有限,在管理上存在局限性。基于衛星遙感技術的漁船監測更多是對燈光作業漁船(燈光圍網、秋刀魚舷提網、魷魚釣和燈光罩網)進行監測[2],監測面較窄,并且遙感影像易受云層的干擾。而VMS能實時記錄漁船的經度、緯度、航速、航向、發報時間等數據[3-4],可以快速獲取大范圍漁船作業信息[5-6],監控系統的船舶定位技術已經比較成熟, 從定位方式來看, 主要有北斗漁船定位、沿海CDMA網絡定位、AIS船舶定位[7]等。以往利用VMS對漁船作業的監測多集中于對已知作業類型漁船不同捕撈作業階段的識別,即區分同種類型漁船捕撈和非捕撈作業階段;識別算法多集中于設置船速或航向閾值、統計推斷、機器學習方法等[8-10],此種方法大部分用來計算捕魚有關的指標,例如捕撈努力量[11]等,難以對未知(即未登記)作業類型的漁船進行監測。以上幾種監測方式和監測算法都存在一定的局限性。目前國內外已有研究將漁船作業識別監測的重點轉移至對漁船軌跡的研究,識別方法多是基于深度學習、機器學習等:HUANG等[12]利用XGBoost的特征工程和機器學習算法作為其兩個關鍵模塊構建了VMS漁船軌跡識別方案,對8種不同的漁船作業方式進行了監測識別;DE SOUZA等[13]針對拖網、延繩釣和圍網漁船分別開發了不同的機器學習算法進行識別;KROODSMA等[14]利用卷積神經網絡(convolutional neural network,CNN)算法將AIS漁船分為7類進行了識別研究[14-15]。
目前深度學習方法發展迅速[15],可以將特征工程自動化,相比HUANG等[12]和DE SOUZA等[13]使用的機器學習方法,CNN無須研究手動設計特征。目前利用CNN算法對北斗VMS漁船軌跡數據進行監測的研究較少,本文提出一種利用CNN對刺網和拖網漁船軌跡進行識別分類的方法:首先利用航次提取方法提取出每艘漁船具體的航次信息,根據提取的航次信息將原始VMS數據進行劃分,根據每個劃分的數據里的經緯度點數據,批量畫出每個航次的軌跡點圖,以此生成刺網和拖網航跡圖庫;將刺網和拖網航跡圖輸入到深度卷積神經網絡模型中,根據大量的圖片訓練、學習和驗證,以此得到區分拖網作業和刺網作業的深度學習模型。
1 材料與方法
1.1 研究實驗流程
研究實驗整體流程如圖1所示。
1.2 數據來源
刺網和拖網的北斗船位數據來源于北斗民用分理服務商,北斗VMS數據信息主要包括漁船的ID、經緯度、時間等信息,空間分辨率約為 10 m,時間分辨率約為 3 min。研究使用浙江省北斗VMS 2017年數據,其中包括刺網作業船1 566艘,拖網作業船2 504艘,漁船作業類型均為登記作業類型。根據本文航次圖生成方法共生成刺網航跡作業圖11 912張,拖網航跡圖11 488張。
1.3 航次劃分方法與航跡圖生成
1.3.1 航次劃分方法
航次是漁業生產管理中常用的統計量,漁船按照約定的捕撈計劃從出發港到返回港為一個航次。漁船出海作業過程中,船載北斗終端發送漁船ID、船位經緯度、時間等信息,位置點記錄的時間間隔約為3 min,每個航次由一系列時間序列船位點組成。首先按0.1°×0.1°把中國海岸線劃分到每個格網中,生成格網信息圖層,然后將格網圖層與海岸線圖層疊加,兩者相交的格網即為港口格網,將省、地區、縣行政區劃圖層與港口格網中心點圖層疊加,計算出港口格網中心點經度和緯度,格網所屬的行政區劃為離中心點最近的行政區劃。將漁船軌跡線與港口格網相疊加,相交的點即為漁船的出發港和返回港,根據出發港船位點和返回港船位點來提取出具體的每個航次信息[16]。
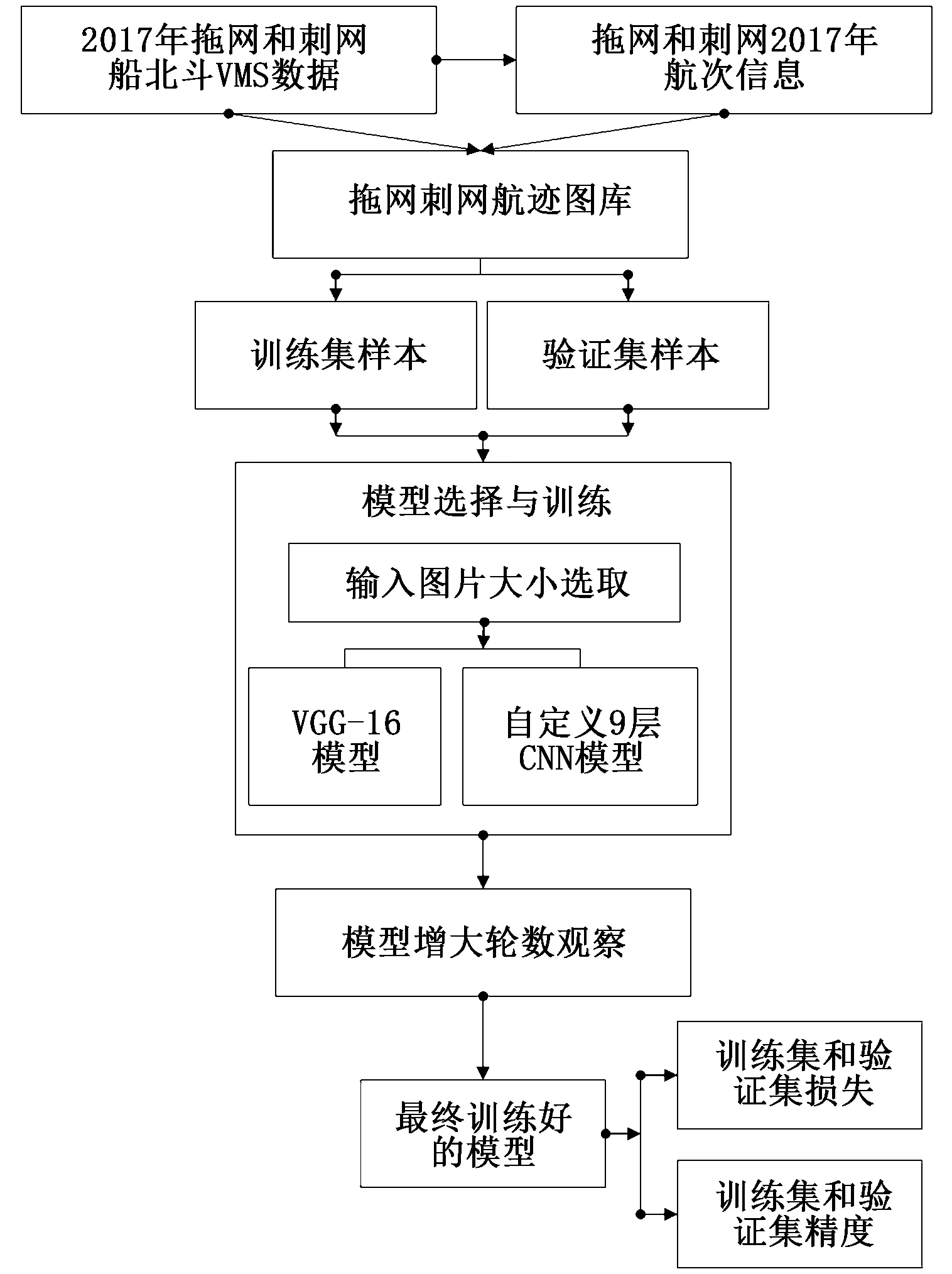
圖1 研究實驗流程圖Fig.1 Research experiment flow chart
圖2為漁船航次示意圖,格網中心點為港口。圖2中有2個航次,分別是航次1和航次2。航次1從港口格網A出發,經過海上捕撈作業,在港口格網C返港;航次2從港口格網D出發,經過海上捕撈作業,在港口格網D返港。
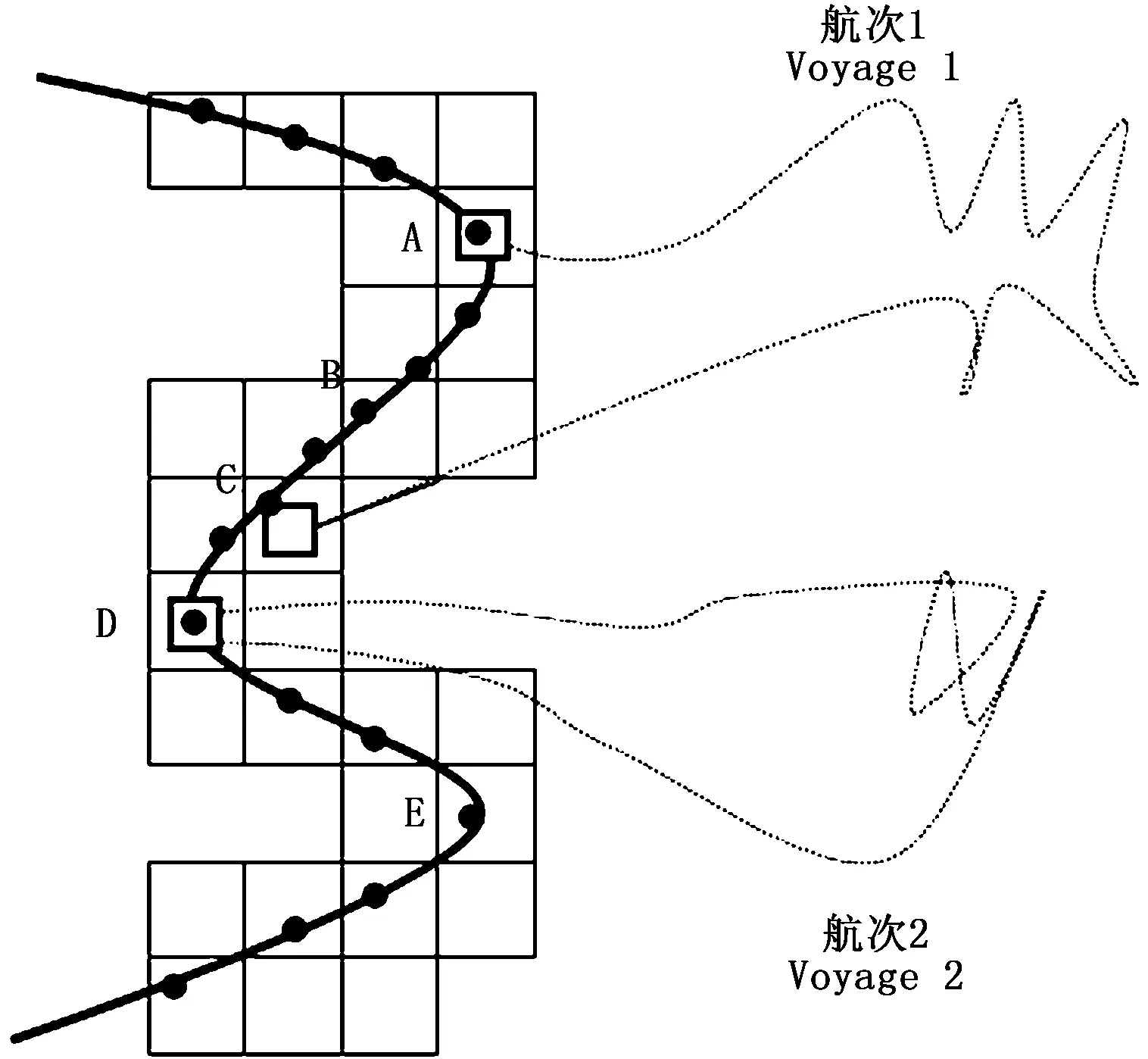
圖2 漁船航次示意圖Fig.2 Schematic diagram of fishing boat voyage
1.3.2 航跡圖生成方法
根據提取的每個2017年浙江省北斗VMS拖網和刺網所有航次信息,將原始VMS數據劃分為每個航次數據;根據每個航次數據里的經緯度數據,依次生成每個航次的航跡圖。航跡圖生成流程如圖3所示(圖中為拖網航跡圖生成流程示例,流程圖中使用的航次和船位數據圖片不代表最終使用的數據,僅提供數據格式和過程示意),航跡圖為每個航次的所有船位經緯度點的軌跡點圖。將不清晰、數據點太少和航次不完整的圖人工觀察剔除掉,共生成刺網航跡圖11 912張,拖網航跡圖11 488張,圖片高×寬為288像素×432像素(以下統一簡寫為432×288),以此形成拖網和刺網的航跡圖數據庫。
1.4 深度卷積神經網絡
CNN通過監督學習,能夠直接從原始圖像中識別出圖像特征[17-18]。CNN[19]模型一般由卷積層、池化層、全連接層、Softmax分類層等堆疊組成[20],可根據需要自定義不同層的結構和組成。卷積操作用于特征提取,卷積核相當于一個過濾器,提取我們需要的特征。卷積運算具體公式如下:
式中,m的取值范圍為(0,m),n的取值范圍為(0,n),i、j為卷積核w的尺寸;f為激活函數;b為附加偏執量;Yconv為其輸出。
池化層 (pooling)可以看作是模糊濾波器, 起到二次特征提取的作用,其中最常用的是最大池化(maxpooling)。最大池化具體公式如下:
fpool=Max(xm,n,xm+1,n,xm,n+1,xm+1,n+1)
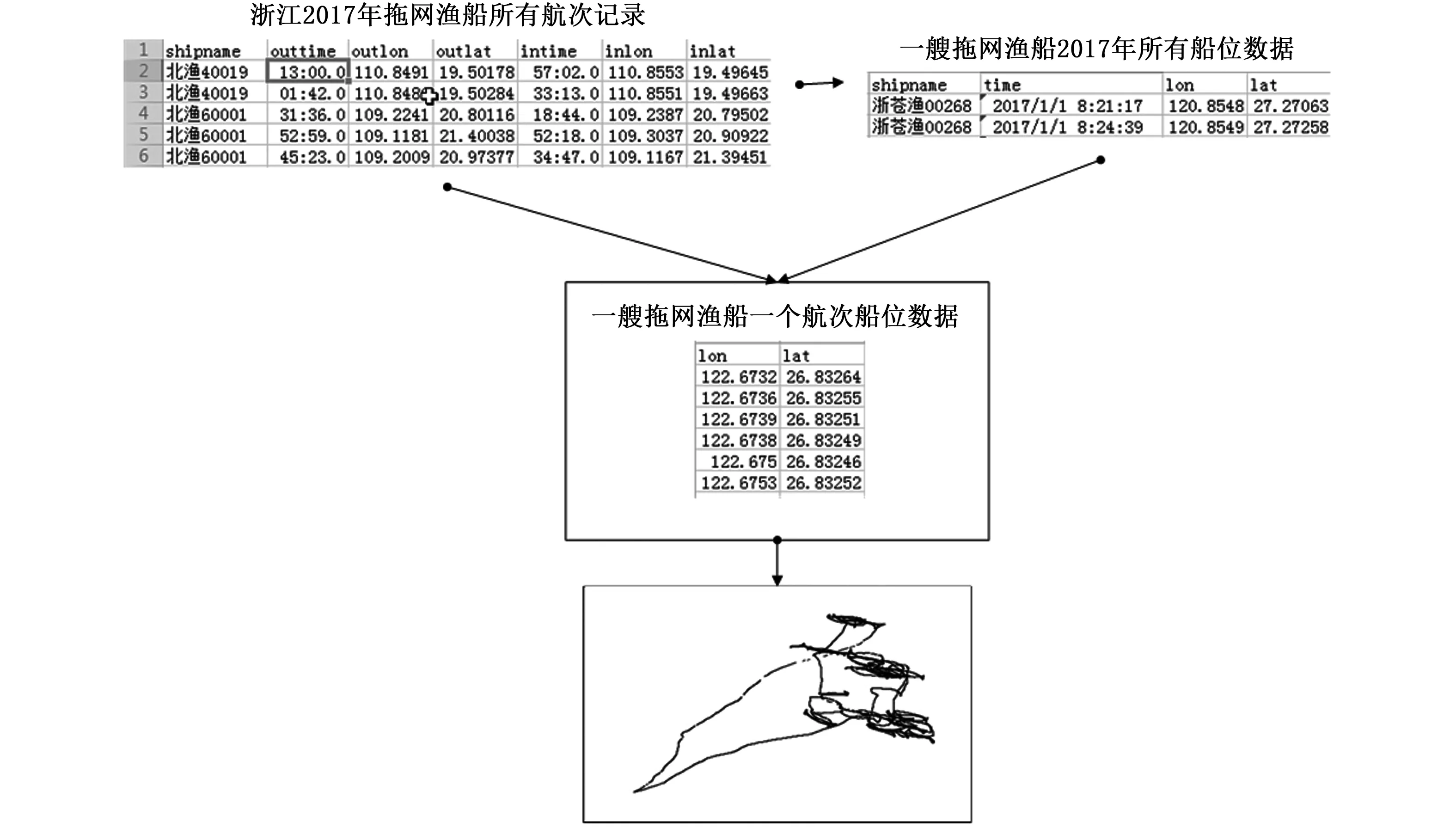
圖3 航跡圖生成流程示意圖Fig.3 Schematic diagram of fishing boat voyage track
fpool為最大池化后的結果。
ReLU 激活函數能夠加快大型網絡訓練速度,并且為常見框架提供了實現方案,使用非常便捷[21]。模型所選擇的激活函數基本上都是 ReLU 激活函數,其函數表達式為:
f(x)=max(0,x)
在全連接層之前,卷積神經網絡卷積層和池化層所提取的特征仍處于局部抽取的層面,要想正確分類, 必須將局部信息進行展開,因此在最后一個池化層之后緊接一個全連接層,將池化層的特征綜合起來并利用Softmax分類器進行分類[22]。Softmax函數表達式為:
Softmax函數類似于概率分布,輸出結果總和為 1,每個節點得到的結果代表某種可能性概率[21]。
2 結果與分析
2.1 模型設計與搭建
構建深度卷積神經網絡的結構和方法非常多,不同的網絡模型在公開數據集以外的圖片分類任務中表現并不一定相同,模型中可對比的參數和調整的地方也非常多,不同的結構設計和方法選擇會影響分類的效果,本文選擇使用網絡結構比較復雜的VGG-16模型與相對簡單的自定義10層CNN模型作實驗,同時僅對圖片輸入大小做篩選實驗。
2.1.1 自定義的10層CNN結構
自定義的10層CNN網絡由3個卷積層、兩個池化層(maxpooling層)、兩個dropout層、一個flatten層、兩個全連接分類層(dense層和softmax層)組成。其中卷積層均采用 3×3 的卷積運算,前兩個卷積層的核數量均為32,第三個卷積層的核數量為64;池化層均采用2×2 的卷積運算,第一個池化層卷積核數量均為32,第二個池化層的卷積核數量為64。為防止過擬合,模型采用 dropout 正則化。本文選擇添加速率值等于0.5 的 dropout層用以防止過擬合,最后使用2標簽softmax分類層,自定義CNN網絡結構見圖4所示。
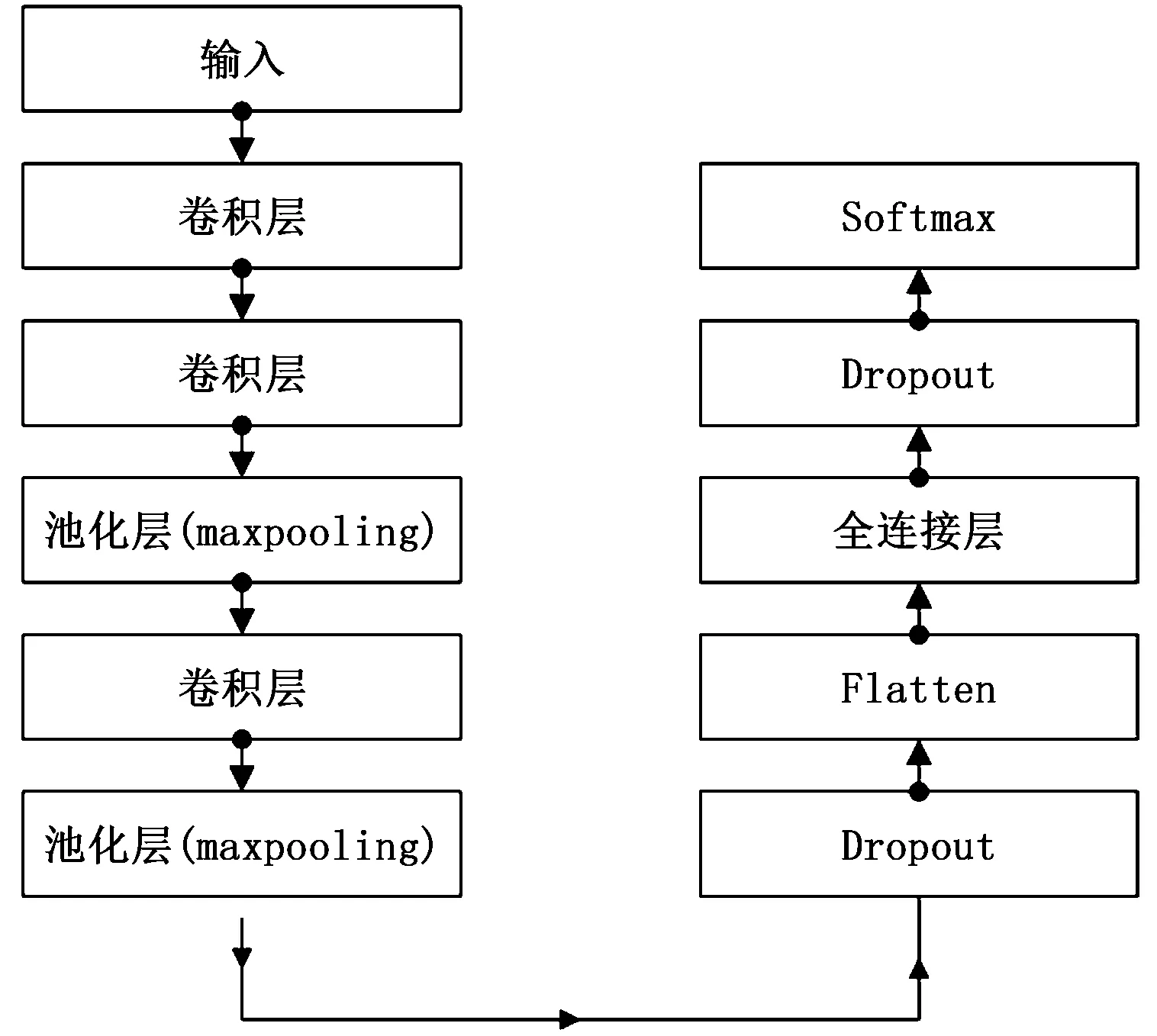
圖4 自定義CNN模型結構示意圖Fig.4 Schematic diagram self-defined CNN
2.1.2 調整后的VGG-16結構
遷移學習即將網絡中每個節點的權重從一個訓練好的網絡遷移到一個全新的網絡里,VGG-16網絡權重由ImageNet訓練而來,具備較強的深度特征學習能力[23]。本文研究的數據集較小,數據跟ImageNet數據相似度不高,為使VGG-16更符合本文數據要求,又避免訓練整個網絡,減少網絡訓練時間和提高網絡訓練效率,研究使用遷移學習和模型微調的方法,在編譯和訓練模型之前將網絡凍結第二層到最后一層,同時重新定義密集連接分類器,用2標簽Softplus分類器替換原有的Softmax分類層,最后使用Adam優化器優化網絡。調整后的VGG-16刺網和拖網航跡圖識別流程框架如圖5所示。
2.2 圖片集預處理
根據1.3.2航跡圖生成方法生成拖網和刺網航跡圖。圖6~圖7為刺網和拖網航跡作業軌跡示意圖。
圖片在訓練前首先會把每張圖片的每個像素值乘以放縮因子1/255,把像素值放縮到0和1之間,將所有的圖片統一歸一化為模型指定大小(圖8中的示意圖已統一處理成224×224大小);因數據集較小,實驗利用Keras的內置ImageDataGenerator圖像增廣技術在模型訓練時來隨機擴充數據集。本文在不影響圖片語義的基礎上選擇2種方式對數據集擴充:1)將圖片進行錯切變換,即讓點的x坐標(或者y坐標)保持不變,而對應的y坐標(或者x坐標)則按比例發生平移,且平移的大小和該點到x軸(或y軸)的垂直距離成正比,錯切變化系數設置為0.2;2)將圖片隨機放縮到寬/高×(0.8~1.2)范圍內;通過以上操作實現對圖像的增廣。圖8為同一張圖片進行以上操作效果圖。
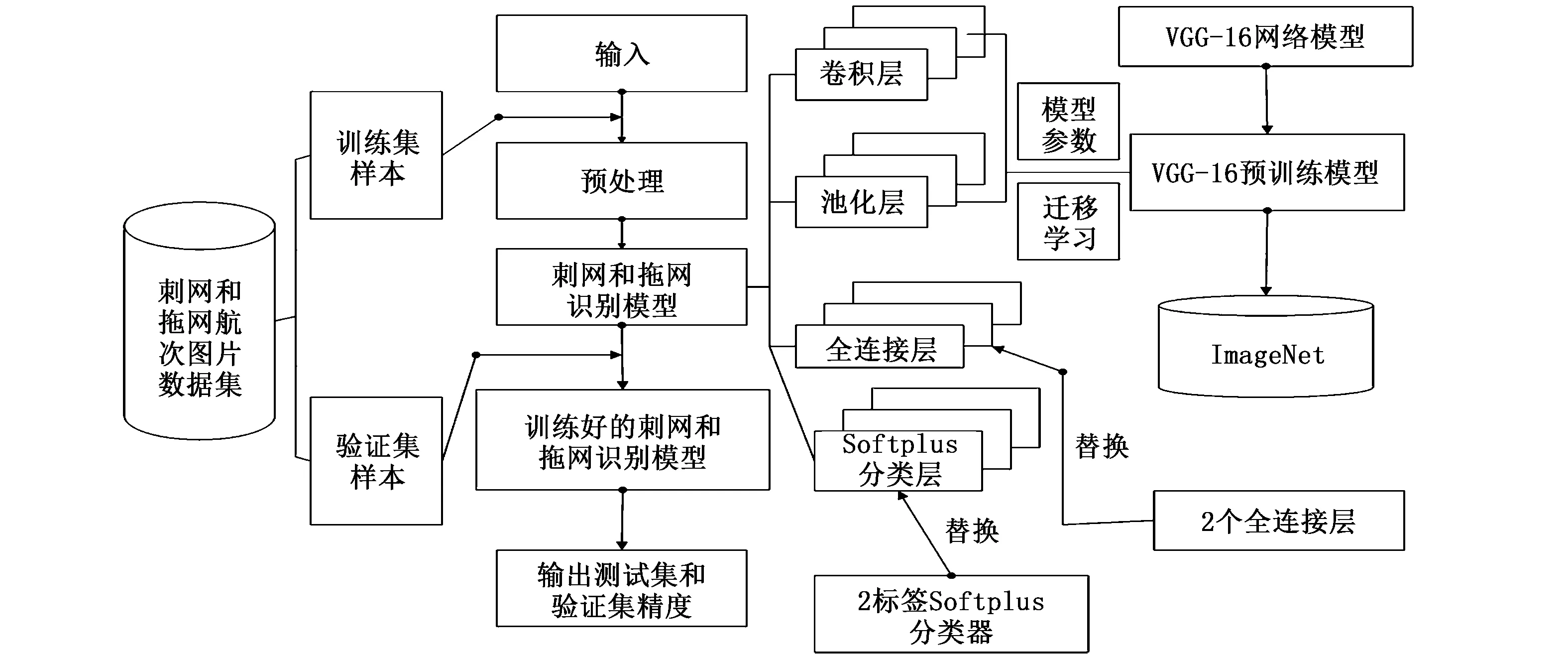
圖5 VGG-16刺網和拖網航跡圖識別框架Fig.5 VGG-16 gill and trawl track picture identification frame
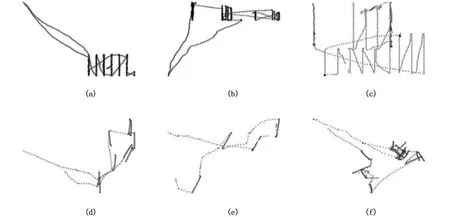
圖6 刺網航跡圖 Fig.6 Gill track 注:a、b、c:定置刺網;d、e、f:流刺網Note:a, b, c: set gillnet ;d, e, f: drift gillnet
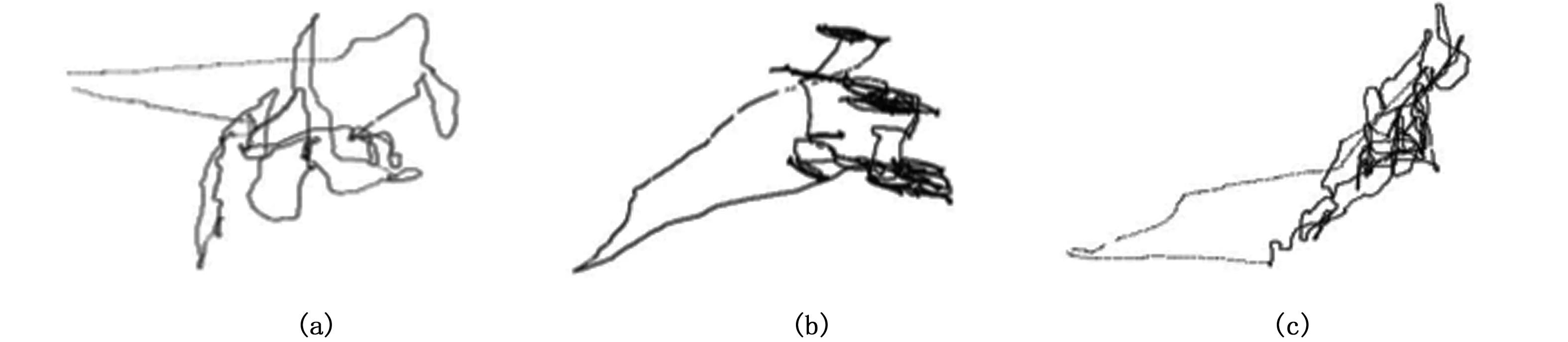
圖7 拖網軌跡圖Fig.7 Trawl track注:a、b、c: 拖網Note:a, b, c: trawl net
2.3 訓練精度和損失
實驗在ubuntu16.04操作系統下搭建Keras框架進行,使用NVIDIA Tesla v100加速訓練網絡。將數據集劃分為訓練集和驗證集,訓練集由刺網9 999張航跡圖、拖網9 436張航跡圖組成;驗證集由刺網1 911張航跡圖、拖網2 142張航跡圖組成,在訓練集上訓練模型,在驗證集上評估模型。本文的實驗過程順序為:1)對輸入圖片大小進行選取;2)對自定義的10層CNN和調整過后的VGG-16做比較,選取較優的模型;3)增大輪次epoch(即訓練的輪數),觀察模型能達到的精度是多少,即模型在迭代多少輪可以達到最優的精度。因輪數(epoch)設置過大訓練時間太長,并且模型初實驗在第10輪左右時就已經達到87%的準確率,故在實驗1)、2)步驟中將epoch設置為100,確定模型結構和圖片輸入大小后,再將epoch調大觀察。
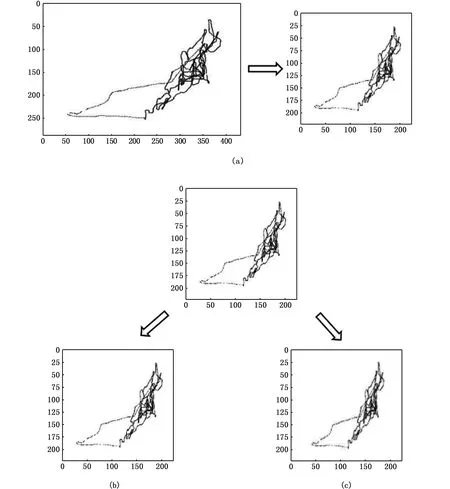
圖8 圖片增廣操作效果圖 Fig.8 effect picture after image augmentation 注:a. 432×288原圖歸一化為224×224效果圖; b. 歸一化為224×224的圖片進行系數為0.2的錯切變換; c. 歸一化為224×224的圖片進行系數為0.2的放縮Note: a. original 432×288 picture normalized to 224×224; b. 224×224 picture after shear transformation by coefficient 0.2; c. 224×224 picture after zoom by coefficient 0.2
首先對輸入圖片大小進行選取,分別對輸入圖片大小為150×150、224×224和438×288的數據集進行迭代100輪,統一使用上述調整后的VGG-16網絡,模型訓練采用批處理方式,batch大小設置為32,不同輸入圖片大小的訓練集精度和損失性能如圖9所示。不同的輸入圖片大小在訓練集的表現有一定的差距,根據精度和損失變化(圖9),可以認為224×224大小的圖片整體上比其他兩種大小的圖片訓練精度要高,并且在剛開始迭代時就能達到比較高的精度。因此實驗把輸入圖片的大小確定為224×224。
本研究涉及的兩種模型中,CNN剛開始迭代精度比VGG-16低,第10輪左右開始CNN的精度要高于VGG-16,在模型損失上也呈現出相同的情況(圖10)。本文設計的CNN和調整過的VGG-16相比,自定義的CNN精度要高于調整后的VGG-16,CNN模型迭代100輪最終的精度為94.07%。故實驗最終選擇自定義的10層CNN模型。
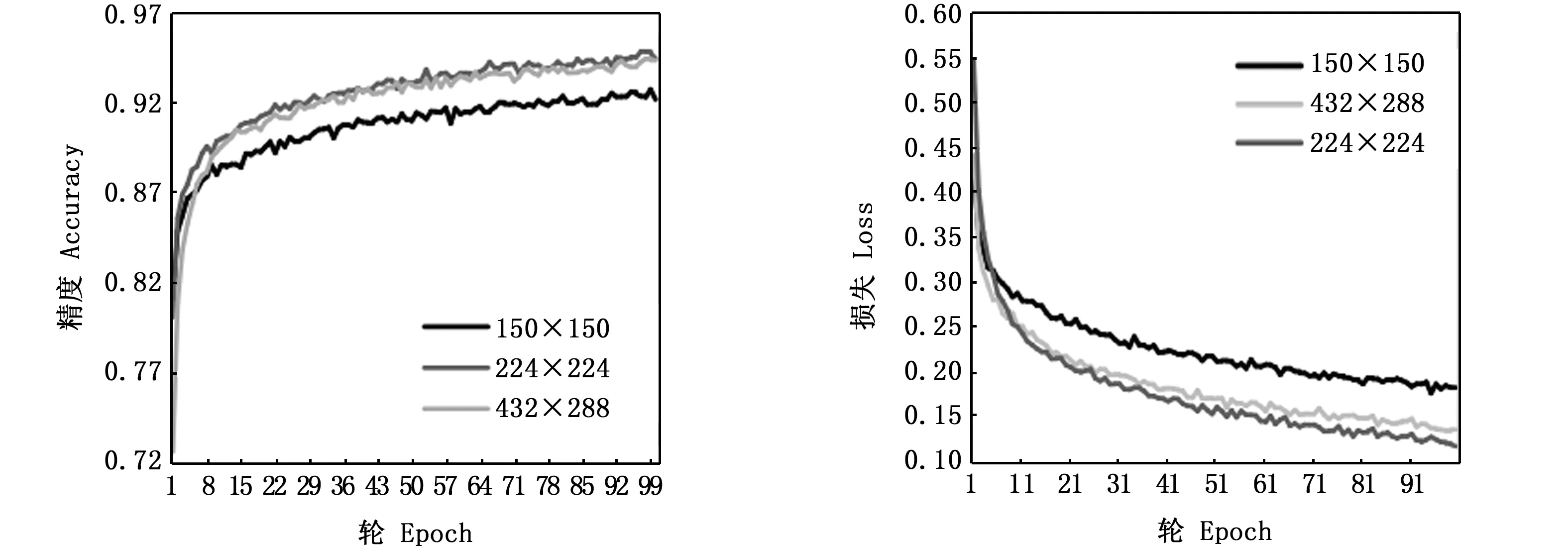
圖9 不同圖片大小訓練集精度和損失Fig.9 Train accuracy and loss of different input image sizes
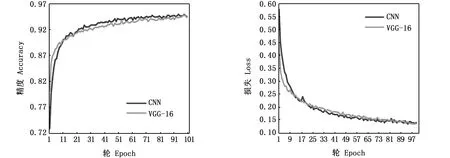
圖10 VGG-16和自定義CNN訓練集精度和損失對比Fig.10 Accuracy and loss comparison of train data between VGG-16 and self-defined CNN
在一定程度上,迭代次數越多,模型的訓練集精度越高(圖11),超過80輪左右,模型驗證集的精度不再繼續提高,損失也開始上升(圖12),所以模型迭代80次便可以停止,迭代80次自定義的10層CNN模型訓練集最終的精度為94.3%,驗證集最終精度為93.6%。
3 討論
3.1 刺網和拖網軌跡特征
刺網大體可分為流刺網和定置刺網。圖6 中(a)(b)(c)為定置刺網,(d)(e)(f)為流刺網。流刺網作業一般先是航行,作業區域軌跡點比較筆直,圖中表現為一段黑且直的直線,放大后可以看到直線的端點有個密集的點。定置刺網和流刺網軌跡點圖的區別為:定制刺網作業區域的軌跡線條一般比流刺網直,直線段更密和黑,放大后直線端點大部分沒有密集的點。相比刺網軌跡點圖,拖網的軌跡點圖沒有突出的特征,拖網的軌跡點圖特征可歸結為:亂、多、密,一般不會形成像刺網一樣簡潔有規律的線條。
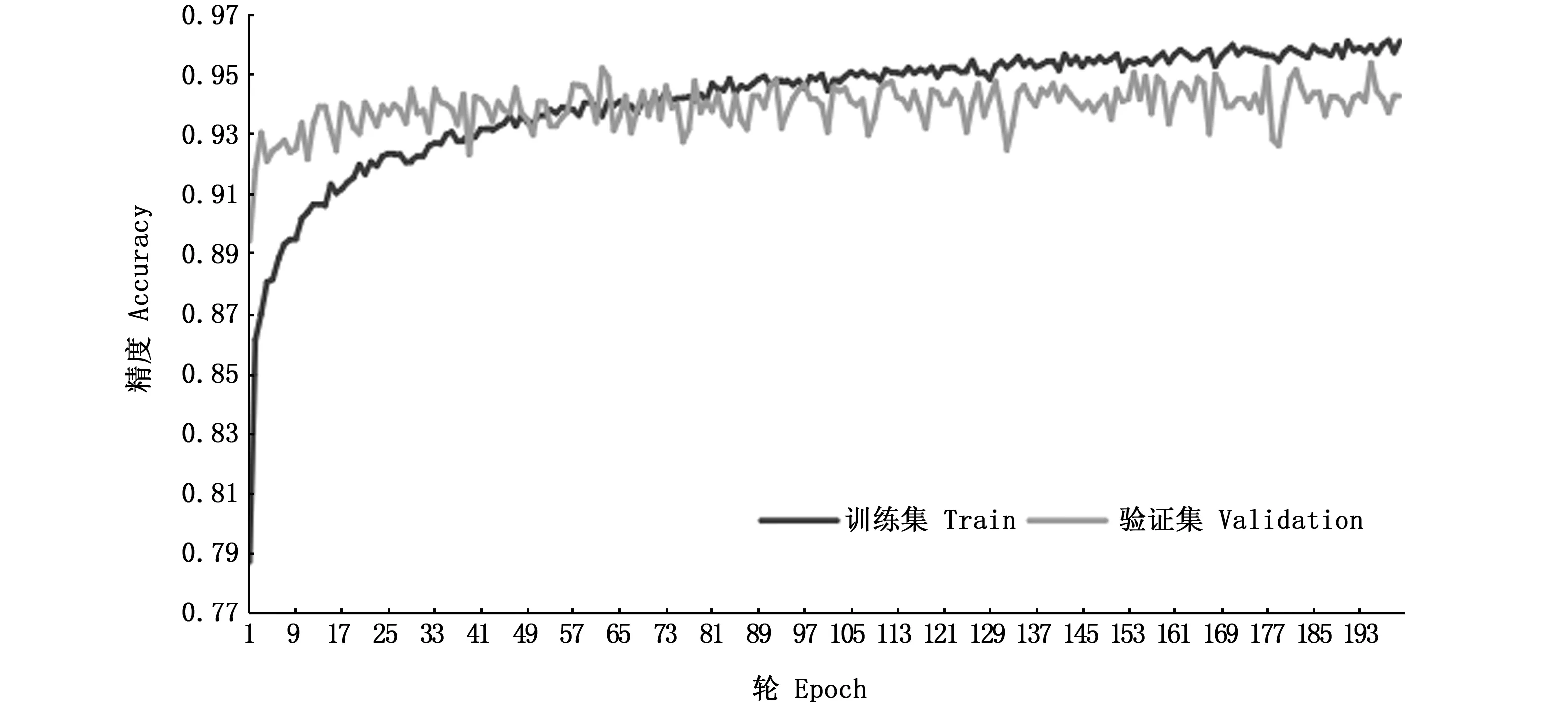
圖11 自定義CNN精度Fig.11 Accuracy of self-defined CNN

圖12 自定義CNN損失Fig.12 Loss of self-defined CNN
以上是刺網和拖網理想的軌跡點圖規律特點。剔除的圖片如圖13,包含:a) 航次不完整,即航次軌跡點出現斷層;b) 軌跡點過于稀疏混亂不清晰;c) 沒有特征點的軌跡圖。同時結合以上刺網和拖網的作業特點,剔除可能證業不符、存在問題的圖(即登記作業為拖網,圖片明顯為刺網;登記作業為刺網,圖片明顯為拖網;或明顯既不是刺網也不是拖網的圖)。
3.2 誤差分析
關于數據集,可能存在以下幾點影響模型的最終精度:1)漁具使用混雜。存在改變注冊作業類型的情況,即一艘船在不同的漁汛期使用不同的漁具進行生產,不完全按照注冊漁具生產,使得訓練數據中可能存在記錄是刺網或拖網但實際上是其他漁具作業的情況;2)航次提取存在誤差。航次記錄分為兩種情況,一種是起航、海上作業、返航過程完整,另一種是航次信息不完整,即只記錄了3個階段的某一、兩個階段。航次不完整的原因主要是北斗衛星數據受信號干擾、信道占用、供電不足或斷電等影響,導致船位數據丟失,或者統計時間段出現一些航次被分割到不同時間段,同時航次提取中數據處理不夠精細可能會導致結果有些誤差[24];3)人為剔除數據存在誤差。即批量出圖后需要人為剔除一些質量不佳的圖片數據。1)和2)中的問題可以根據人工剔除圖片操作解決,即只選取數據質量好的航次圖片進行學習訓練,可能存在有些船位點太少使圖片本身反映不出具體是哪種捕撈作業的圖片未被剔除,或存在1)和2)中問題的圖片未被剔除,從而混入模型中影響精度。3)中人工剔除圖片操作的誤差很小,基本不影響本文根據深度學習對刺網和拖網作業分類識別的可行性。
3.3 模型優化
CNN主要的經典結構有很多,不同的網絡在本數據集上的表現可能不同,本文僅討論了兩種網絡,可以嘗試研究其他的網絡,對比分析不同網絡在刺網和拖網分類上的性能。卷積神經網絡中,有大量的預設參數,例如卷積層的卷積核大小、卷積核個數、激活函數的種類、池化方法的種類、網絡的層結構等,可以嘗試改變以上參數,如本文自定義的CNN模型可以嘗試增加或減少相應的層數或改變卷積核大小,VGG-16可以嘗試凍結前k個層,然后重新訓練后面的n~k個層等;也可以改變與訓練有關的參數,如batch的大小、學習率等,后續研究可以根據以上結果對模型進行優化。
3.4 漁船作業類型的分類研究分析
捕撈漁船作業種類較多,分類方式根據不同的標準也有多種,本文獲得的VMS數據將漁船作業分為了7種,分別是刺網、拖網、張網、圍網、釣具、籠壺和雜漁具。因獲得的數據不均,差距較大,對于本文3.2中討論的漁具混雜問題,這7種類型數據前期人工處理的難度較高,處理的誤差將會變大,使得訓練集誤差增大,同時其他類型船位點特征不如刺網和拖網船位點特征明顯,利用CNN方法能否對所有的漁船作業類型軌跡圖進行區分識別還有待進一步研究;刺網和拖網作為典型的捕撈作業方式,現有的數據量大且質量較好,后續可通過細致的處理提高數據本身的精度,擴大分類種類,改變全連接層的分類個數,利用本文實驗的模型對幾種不同的作業方式進行識別研究。
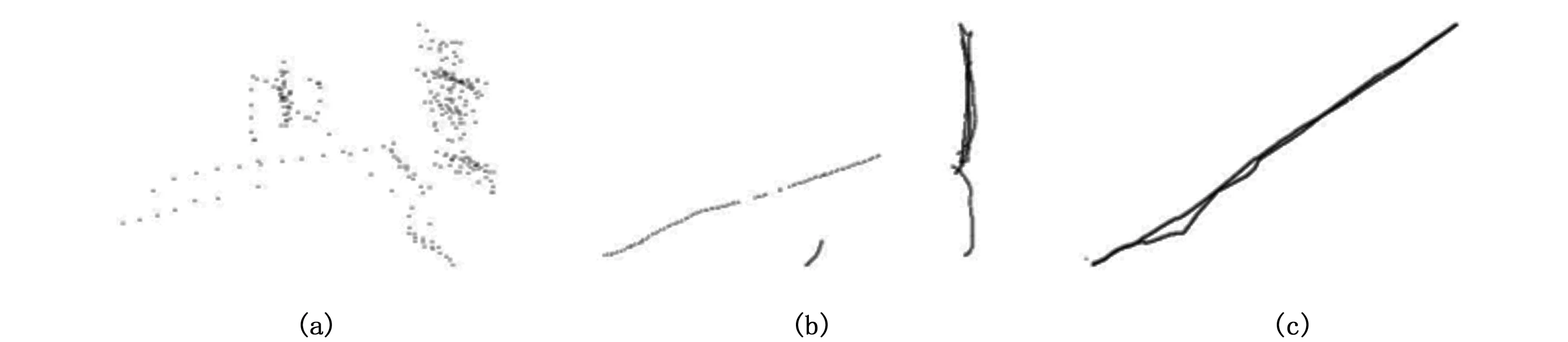
圖13 剔除的航跡圖示例Fig.13 Eliminated track picture注:a. 船位點過于稀疏混亂; b. 航次不完整; c. 沒有特征點Note: a. sparse and chaotic position points; b. incomplete voyage; c. no characteristic point
4 小結
本文根據拖網和刺網北斗VMS數據生成了拖網和刺網多個航次的航跡點圖,然后將航跡點圖輸入到自定義的10層CNN模型以及利用遷移學習和模型微調方法調整后的VGG-16模型中,經過對比實驗,自定義的CNN模型精度整體上要高于調整后的VGG-16模型,最終自定義的10層CNN模型訓練集精度為94.3%,驗證集精度為93.6%,證明了本文方法的可行性,使用深度學習方法對刺網和拖網VMS航跡點識別分類具有較高的準確率,為漁船作業的識別分類提供了新思路,本文僅對兩種作業類型進行了識別研究,后續可細致區分不同作業類型之間的區別,提高研究數據的準確度,對所有的作業類型進行區分識別。北斗VMS可以大范圍快速的獲取漁船信息,現有的研究并沒有完全挖掘出VMS信息的價值,僅集中于對VMS幾種數據進行研究,研究方法尚較固定單一,今后的研究可以改進研究方法和思路,進一步提高數據的準確性,挖掘出VMS數據更多有價值的信息,為漁業發展提供科學有效的參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
學生天地(2020年17期)2020-08-25 09:28:54
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
故事大王(2016年7期)2016-09-22 17:30:08
核科學與工程(2015年4期)2015-09-26 11:59:03
兒童故事畫報(2013年3期)2013-06-24 05:40:30
