雙網絡模型下的智能醫療票據識別方法
2020-06-18 05:50:30鄭祖兵盛冠群唐新功李長晟
計算機工程與應用 2020年12期
鄭祖兵,盛冠群,,謝 凱,唐新功,文 暢,李長晟
1.長江大學 電工電子國家級實驗教學示范中心,湖北 荊州434000
2.長江大學 電子信息學院,湖北 荊州434023
3.油氣資源與勘探技術教育部重點實驗室(長江大學),武漢430100
4.長江大學 計算機科學學院,湖北 荊州434023
1 引言
隨著現代社會醫療水平的提高,每天有大量醫療票據需要錄入計算機存儲與處理。傳統方式為人工將票據中數據錄入計算機,其成本高、效率低,票據錄入工作任務重、強度大,極易導致錄入人員疲勞致使工作出錯。醫療行業迫切需要一種自動票據識別錄入方法。
在票據識別領域:Wei等[1]提出了通過集成稀疏編碼和矢量量化(VQ)技術開發的緊湊型MQDF分類器,在沒有精度損失的情況下實現了低存儲空間的手寫漢字分類;Song等[2]提出了應用圖像濾波的銀行票據單號識別方法,對彩色紙幣圖像進行圖像增強處理,應用模式匹配方法對單號信息進行準確地提取;謝文彬等[3]通過建立一種基于結構特征的分類器,根據票據中每個單號的結構特征值,能對發票單號進行分類識別;薛峰[4]提出了一種針對銀行票據的自動識別系統,用以提取票據中部分信息。目前國內外學者對于票據識別的研究較少,上述票據識別方法只能識別票據中部分信息(如票據單號),無法完成對全部信息的提取識別,且現階段票據識別方法均是針對標準的打印字體,其字體規范、無斷點、易于辨認,而醫用針式打印機打印出字符筆畫含有斷點、分辨率低,如圖1所示,現有的方法難以準確識別此類不規范的字體。

圖1 針式打印字體效果圖
在深度學習領域:Yang等[5]從實例感知分割角度提出了一種端到端場景文本檢測器IncepText,并引入了可變形的PSROI池化層來處理面向多向的文本檢測,解決了場景文本中的寬高比、比例和方向不確定造成的識別精度低的問題;Zhu等[6]提出了滑動線點回歸(SLPR)方法,以檢測自然場景中的任意形狀的文本;Dai等[7]提出了面向多向場景的神經網絡文本檢測方法,在特征提取過程中結合了多級網絡的特征,使得模型具有更精細的特征表達;Zhang等[8]提出了一種新的基于軌跡的激進分析網絡(TRAN),利用字符的固有結構特點,首先識別自由基并同時分析基團之間的二維結構,然后通過基于內部自由基的分析來識別漢字;李偉山等[9]以Faster-RCNN算法為基礎,對候選區域網絡(RPN)結構進行了改進,提出了一種“金字塔RPN”結構來解決井下行人檢測存在的多尺度問題,同時算法中加入了特征融合技術,將不同卷積層輸出的特征圖進行融合,增強煤礦井下模糊、遮擋和小目標行人檢測的性能;史凱靜等[10]提出一種基于FasterRCNN的前方車輛檢測方法,能準確定位與識別出不同交通環境場景下的前方車輛。上述方法應用神經網絡于字符、圖像識別領域,能實現快速準確的識別,雖然識別目標受環境的影響較大,但神經網絡模型具有較強的魯棒性,模型均能維持穩定較好的識別效果。
目前國內外尚無成熟的醫療票據處理系統,且傳統票據識別大多采用模板匹配方法,靈活性差;深度學習的應用廣泛,基于深度學習的目標檢測研究較為深入,傳統的神經網絡目標檢測方法基于單網絡進行物體的定位與識別,對于簡單且類別數較少的分類任務,單網絡方法能減小網絡的參數量和復雜度,但對于復雜背景下的多目標檢測任務,如字符識別任務,其需要進行大規模的定位與識別,單網絡的同一參數值既難以描述位置信息又難以描述類別信息,且普通的淺層網絡難以實現此類復雜需求,隨著網絡層數的加深,網絡的參數量呈幾何倍數增加,當參數量過大、層數過深時導致網絡龐大、難以訓練。
基于以上分析,本方法將深度學習與票據識別相結合,提出了基于FasterRCNN與深度卷積神經網絡的雙網絡模型針式打印字體醫療票據識別方法,分步實現定位與識別,避免了因網絡層數過深導致的梯度消失或梯度爆炸的問題,針對票據中的全部信息進行準確識別。此外,本文還提出了自適應學習策略與新型票據矯正方法以提高雙網絡模型的性能。
2 雙網絡模型票據識別方法
本文采用FasterRCNN與深度卷積神經網絡相結合的雙網絡模型進行票據中字符的定位識別。層數較深的神經網絡模型在訓練的時候容易出現梯度消失(gradient vanishing problem)或梯度爆炸(gradient exploding problem)的問題,且隨著網絡層數的增加變得越來越明顯,這是因為深度神經網絡在反向傳播的過程中,根據鏈式求導法則[11],梯度會隨著反向傳播層數的增加而呈指數衰減或增長趨勢,從而導致梯度消失或梯度爆炸。在復雜特征多分類任務上,本文方法通過使用雙模型來降低網絡深度。

圖2 使用雙網絡模型進行票據識別算法原理圖
本方法只需標記不同區域的類別與位置就能生成文本定位訓練集,字符識別訓練集由程序基于字體文件自動生成,數據集制作難度低、工作量小。
利用雙網絡模型進行票據識別的算法流程如圖2所示,主要分為:(1)構建文本定位網絡模型;(2)構建字符識別網絡模型;(3)票據圖像處理與基于雙網絡模型的票據識別。
2.1 文本定位網絡模型
2.1.1 票據數據集制作
醫療票據中的信息分為出廠印刷內容和后期打印內容。在構建票據識別系統時,固定格式的出廠印刷內容預先導入數據庫,識別階段只需處理后期打印的醫療信息。本方法預先采集了3 000張具有完整信息的醫療票據圖像用以制作數據集,根據票據的版面信息標定文本位置并標注所屬類別,如圖3,以生成用于文本定位網絡訓練的票據訓練集。

圖3 文本位置標定示意圖
2.1.2 構建文本定位網絡
文本定位模塊采用基于VGG16[12]的FasterRCNN,其包含13個卷積層,如圖4,適中深度的卷積層既能保證網絡有足夠的參數擬合字符的深層次特征,又避免了網絡過深引起的網絡難收斂的現象。

圖4 基于VGG16的FasterRCNN中的卷積層
FasterRCNN使用候選區域網絡(Region Proposal Network,RPN)來生成檢測目標的建議框,較傳統的選擇性搜索(Selective Search)建議框生成算法性能更優。RPN能學習預測建議框A與真實標記框G之間的差異,通過對建議框微調得到輸出框G′,如圖5,從而準確預測文本的位置。

圖5 建議框位置回歸示意圖
針對票據中字符位置、大小不固定的特點,本方法對FasterRCNN網絡結構做出了改進,使用多個1×1,3×3的卷積核來代替傳統的3×3固定大小的卷積核,如圖6,多尺度卷積核可有效融合圖像不同尺寸的相鄰區域的特征,大卷積核提取圖像的全局性特征,小卷積核提取圖像的局部特征,使網絡捕獲圖像特征的能力更強,模型的文本檢測能力大幅提升。

圖6 多尺度卷積核示意圖
2.1.3 網絡訓練與測試
在網絡訓練過程中,將票據訓練集作為網絡的輸入,記網絡的輸入為?(Ai),平移量為(tx,ty),尺度因子為(tw,th),學習率為λ,網絡需要學習的參數為w,則損失函數[13]表示為(*表示x,y,w,h):

網絡的優化目標為:

則網絡通過反復迭代,利用誤差的反向傳播來更新網絡參數w*。
本文提出了基于inv學習策略[14]改進的自適應學習策略(adaptive learning rate),其規定了網絡在第iter次迭代時的學習率lriter可表示為:

其中,baselrgamma power均為人工設定值,baselr為網絡初始學習率,gamma為控制曲線下降的速率,power為控制曲線在飽和狀態下學習率可達的最低值,iter表示網絡當前迭代次數。
自適應學習策略的優勢在于學習率在每次迭代時都會有細微變化,當loss下降時學習率會減小,而當loss上升時學習率會增大,由于隨機梯度下降法[15](Stochastic Gradient Descent)在更新參數時不一定會按照正確的方向進行,自適應學習率能在loss上升時增大學習率,較大的學習率有利于跳出局部最小值,到達全局最低點,從而使網絡能更快地找到梯度下降最快的方向。選取的參數:gamma=0.01,power=0.75。
當網絡進行了15000次反復迭代時,誤差小于1×10-3,此時認為網絡已經擬合,停止網絡訓練。利用測試集測試網絡性能,模型能對字符所在位置進行精準的標注。
2.2 字符識別網絡模型
2.2.1 字庫數據集制作
本方法采用國標一級字庫和醫療術語字庫共4 200類字符,通過程序自動生成字庫圖像,并聯合高斯模糊、腐蝕等多種圖像處理方法處理字庫圖像,模擬針式打印字體,使得用于訓練的字庫數據集最大程度地接近真實票據中的字體,再對字符圖像進行類別標注,生成用于字符識別網絡訓練的字庫訓練集(圖7為算法實現流程圖),貼近真實票據字體的訓練集訓練得到的網絡模型的識別率高。

圖7 字庫數據集的制作流程圖
2.2.2 構建字符識別網絡
字符識別網絡通過增加網絡的層數來增強網絡的學習能力,從而獲得更好的特性表征。網絡采用自適應矩估計(Adaptive Moment Estimation,Adam)優化算法[16],Adam算法綜合考慮梯度的一階矩估計[16](First Moment Estimation)和二階矩估計[16](Second Moment Estimation)來動態調整網絡中每個參數的學習率,設mt與vt分別為梯度一階矩估計與二階矩估計,學習率為η,為防止分母為零設置ε為平滑項,則對于t+1時刻,其參數更新規則可表示為:

Adam優化算法下網絡通常僅需微調其超參數就能擬合,選取的參數為:學習率α=0.001、一階矩估計的指數衰減率β1=0.9、二階矩估計的指數衰減率β2=0.999和參數ε=1×10-8。
字符識別網絡采用“標簽平滑歸一化”(Label Smoothing Regularization)方法[17]對真實標簽進行改造,使其不再是one-hot形式。在one-hot形式下,4 200分類任務中某類標簽的表示形式為:

網絡輸出的預測概率為:

其中,zi為未被歸一化的對數概率,q為樣本的真實類別標簽概率,則交叉熵損失表示為:

訓練目標是最小化損失函數,網絡需要用預測概率去擬合真實概率,因為one-hot中全概率和零概率使得本類別與其他類別的差距達到最大值,當訓練充分時,網絡容易過擬合,最終會造成模型過于相信預測的類別。為防止模型把預測結果偏向于概率較大類別上,“標簽平滑歸一化”方法將零概率替換為一個較小的數ε,將全概率替換為較接近的數1-ε,而使得網絡不會完全貼近訓練數據,從而降低了網絡過擬合的風險。
2.2.3 網絡訓練與測試
在網絡訓練階段,將票據訓練集作為網絡的輸入,采用“Xavier”方法[18]初始化網絡權重,使得網絡參數能獲得一個合適的初值以利于網絡中傳遞信息的流通。設定權重初始化的范圍為[-a,a],“Xavier”方法需使得網絡每一層輸出的方差盡量相等,則方差為:

設第k層網絡有n個參數,則采用“Xavier”方法會將參數初始化為內的均勻分布。
當網絡進行了10 000次反復迭代時,誤差小于1×10-4,此時認為網絡已經擬合,停止網絡訓練。利用測試集測試網絡性能,模型能對字符進行準確的分類。
2.3 票據識別
票據識別的流程如圖8所示。
2.3.1 票據校正
本文設計了的新型票據校正方法,其算法流程如圖9所示。

圖8 票據識別流程圖

圖9 票據校正方法流程圖
Roberts算子定位邊緣精度高,但其抗噪聲能力弱,而在票據的邊緣檢測過程中,票據中字符、折痕、污漬、拍攝時產生的噪點等都可能成為噪音而干擾票據邊緣的檢測。在進行邊緣檢測之前先采用高斯濾波對圖像進行平滑處理,濾除噪音。記σ為正態分布的標準差,參數σ決定了平滑程度,則對于圖像中任意一點(x,y),二維高斯濾波的如公式(8)所示:

對于降噪后的圖像,采用Roberts算子檢測圖像中票據的邊緣。最后對圖像中票據邊緣所在的直線進行霍夫變換(Hough Transform),將原始票據圖像的邊緣直線映射為參數空間的一個點。于是笛卡爾坐標系中的直線檢測問題轉換為在極坐標下尋找對應數量的曲線的交點的問題,如圖10,由交點在極坐標系中的位置可求得票據的傾斜角度。

圖10 霍夫變換檢測邊緣結果圖
2.3.2 檢測定位
本方法使用FasterRCNN模型進行文本定位,將預處理后的票據圖像輸入網絡,模型將定位出不同類別字塊的位置信息,根據文本定位結果對票據圖像進行切分,實現了票據圖像中的待識別的文本與無關背景的分離。由于文本的定位功能由FasterRCNN模型單獨實現,因此對于不同類型的票據的識別,無需重構整個系統,只需采集少量票據訓練網絡進行微調,就能遷移至不同類型的票據的識別,模塊化的設計增強了系統的靈活性。
2.3.3 文本分割與處理
對字塊圖像進行顏色分割[19],只保留后期打印內容,進行平均法灰度化與閾值法二值化處理,獲得清晰的字符輪廓。
進行基于垂直投影直方圖的字符分割,按照投影的間隔切分字塊為單字符圖像,如圖11所示。

圖11 垂直投影切割示意圖
2.3.4 字符識別
利用字符識別網絡模型對單字符圖像進行識別,該網絡學習了針式打印字體的深層特征,網絡的參數量足夠龐大,因此即使字符類別數較多,在不同參數學習到不同目標的特征的情況下,網絡仍然能準確地進行數千類字符的分類。因為在文本定位階段保留了票據原始的版面信息,所以識別結果仍可按照票據版面中的個人信息、金額等進行結構化分類存儲于數據庫之中。
3 實驗與結果分析
雙網絡模型的具體應用方法如圖12所示,分為離線部分與在線部分,離線部分通過GPU運算服務器進行模型的訓練,在線部分通過醫院端采集發票信息,上傳至服務器后進行識別,識別結果傳回醫院端顯示。
3.1 實驗運行平臺
本實驗采用的硬件平臺及軟件平臺見表1所示。

表1 實驗運行平臺配置
本實驗的流程如圖13所示。
3.2 網絡參數設定
3.2.1 不同學習率對測試準確率的影響
本實驗利用現場采集的票據圖片,測試了不同學習率下模型的識別準確率,見圖14,學習率太大會導致梯度爆炸或者震蕩劇烈,學習率太小會導致參數更新緩慢且難以找到梯度下降最快的方向,依據實驗結果,網絡采用的學習率為0.001,使模型的識別準確率最高。
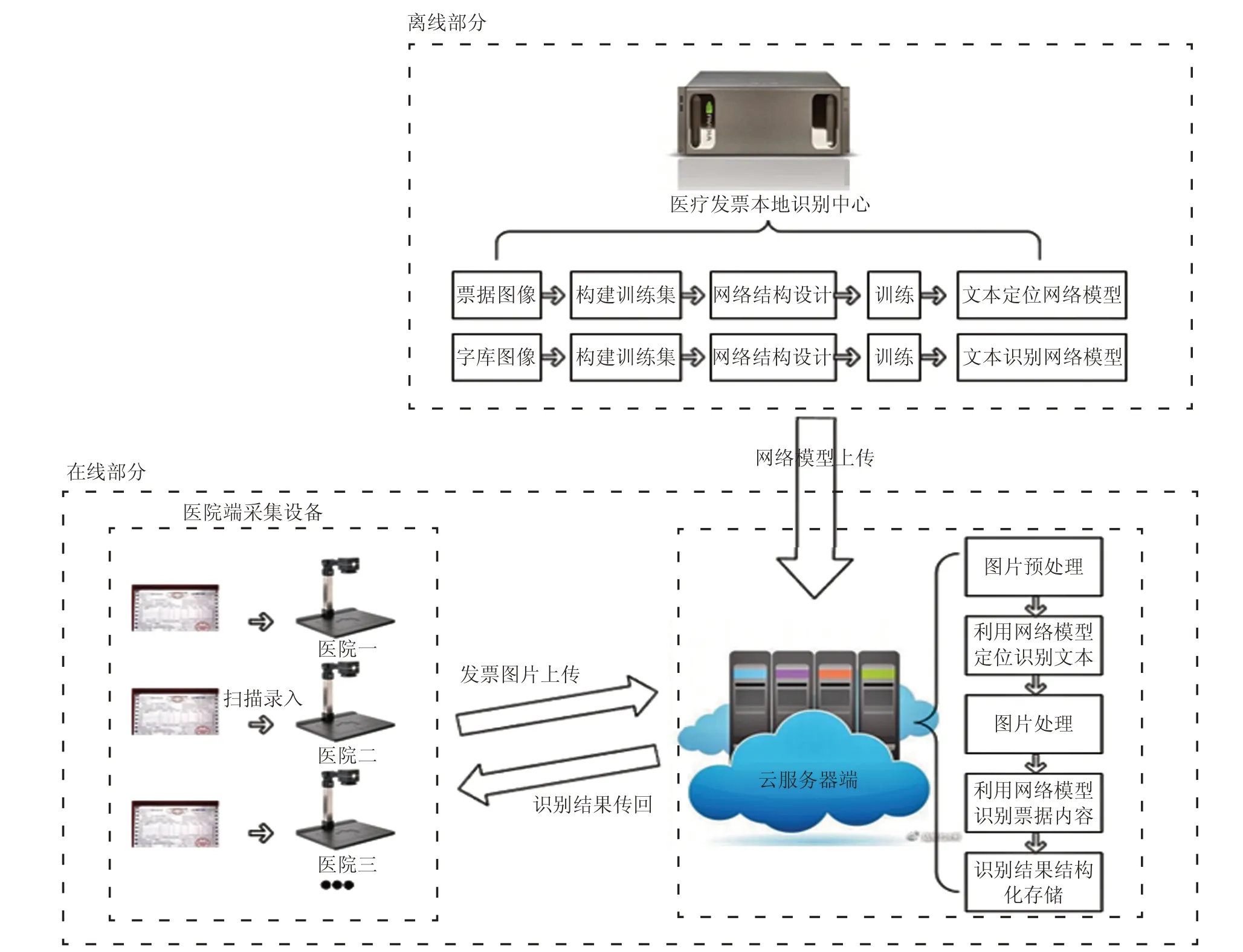
圖12 具體應用方法圖

圖13 實驗流程圖

圖14 不同學習率下的模型測試正確率
3.2.2 不同激活函數對網絡收斂速度的影響
ReLU函數[20](公式(9))在輸入x為正數的時候,不存在梯度飽和問題,且只存在線性關系,而Sigmoid函數[21](公式(10))和Tanh函數[22](公式(11))都存在指數關系,在前向傳播與反向傳播過程中,ReLU函數速度也是最快的。實驗測試了不同激活函數對網絡收斂速率的影響,見圖15,根據實驗結果,本方法采用了使網絡收斂最快的ReLU激活函數。

圖15 不同激活函數對網絡收斂速度的影響

3.3 不同校正方法效果對比
圖16所示為幾種不同算子的票據邊緣檢測效果對比結果。可以看出Roberts算子在邊緣檢測方面的效果更好,邊緣輪廓更明顯,結合本文對票據邊緣精確檢測的需要,選用Roberts算子來檢測圖像中票據的邊緣。

圖16 不同邊緣檢測算子的檢測效果對比圖
實驗將本文圖像校正方法、旋轉投影法[23]和Radon變換法[24-25]進行對比分析,結果見表2,其中,以水平方向為標準位置,數值為正表示校正后的順時針角度誤差,反之為逆時針誤差。

表2 在不同票據圖像狀態下的校正結果
本文設計的校正方法選取Roberts算子檢測邊緣,為霍夫變換提供了清晰的邊緣直線,使得變換結果中峰值明顯。由表2可知,本文校正方法的校正效果比傳統方法更精準。
3.4 模型性能分析
利用現場采集的50張票據測試本方法性能,測試結果如表3所示。
文本定位網絡使用了多尺度的卷積核,其能學習目標不同粗細粒度的特征,使得定位時不會遺漏目標;網絡中PRN層利用卷積神經網絡提取特征并生成目標建議框,經過充分訓練后其參數學習了目標的深層特征,更能貼合實際數據,能在復雜環境下精確定位目標,由表3可知,定位精度達98.6%;文本定位網絡采用的自適應學習率策略,能夠根據loss的變化動態地調整學習率的大小,合適的學習率使得網絡迅速找到梯度下降最快的方向,并且一定程度上避免了網絡陷入梯度的局部最小值情況的出現,因此,網絡訓練所需的時間大幅降低。

表3 待識別文本定位正確率
字符識別網絡采用了深度卷積神經網絡,其參數量大,大量參數能夠準確擬合到字符的深層次特征,網絡采用“Xavier”方法初始化權重,使得網絡在初始狀態就具有較合適的初始權重,節省了通過反復迭代調整權重所需的時間,網絡訓練時的速度有明顯提升;“標簽平滑歸一化”方法使得網絡在充分貼合訓練數據的同時避免了過擬合,因此網絡可以充分訓練以學習到每個字符的特征,使得識別精度維持在較高水平;上述傳統的方法只利用了圖像的淺層特征,由表4可知,本方法的字符識別精度較傳統方法提升了約3%~8%;由于神經網絡只需通過對輸入圖像進行數學計算可直接得到最終結果,由表5可知,本方法識別速度優于其他方法。由于文本定位網絡幾乎能定位出所有字符,且字符識別的精度較高,由表7可知,在正常情況下本方法的字符識別召回率達92.7%。

表4 與傳統字符識別方法的精度對比
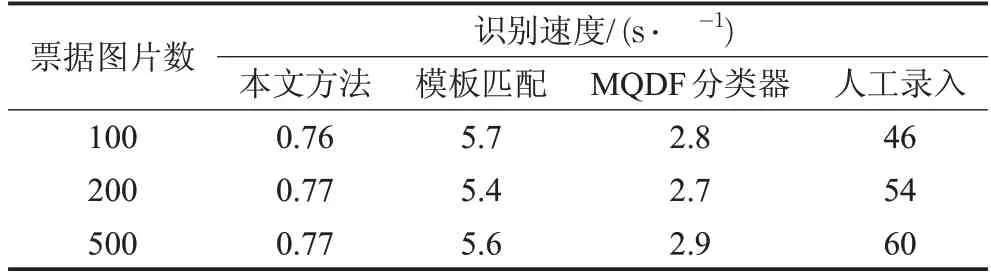
表5 與傳統字符識別方法的速度對比
訓練數據集中不可能包含各種干擾下拍攝的票據圖片,而在實際應用過程中,部分票據表面存在折痕與污漬,票據圖像曝光不均衡,票據中字符打印內容相對于規定位置有不同程度的偏離,可見在實際過程中輸入網絡的數據攝動較大,如表6、表7所示,在不同的干擾環境下,票據識別的準確率浮動不超過2.4個百分點,召回率穩定維持在90%以上,當輸入的信息發生有限范圍的變化時,神經網絡仍能維持穩定的輸入、輸出關系,這是由于雙網絡模型聯合了兩個網絡模型分別實現定位與識別,而定位與識別模型均利用了圖像的深層特征,數據的攝動被分散到兩個模型上,因此輸入數據的攝動對于結果的影響被限定在一定量的較小的程度上,使得網絡具備較強的泛化能力與魯棒性,并且由于數據攝動的影響被分散,使得單個網絡模型的性能不會受到太大的影響,最終使得疊加的雙模型識別精度高。

表6 在不同環境下的識別準確率

表7 在不同環境下的識別召回率
4 結束語
本文詳細地描述了雙網絡模型下的票據識別方法,并通過實驗驗證了該方法的有效性。實驗結果表明,本方法識別準確率可達95.4%,召回率達92.7%,識別速度達0.76 s/張,且模型具有較強的泛化能力。醫療票據識別系統搭建在高性能的GPU云端服務器上,任何具備圖像錄入功能的可聯網設備均可作為客戶端,實現了成本控制下的醫療票據識別。下一步的工作方向主要將為研究通用票據檢測系統,以實現不同行業不同種類的票據的識別。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
