基于Multi-TWE模型的短文本分類研究
2020-07-04 02:27:37王云云張云華
智能計算機與應用 2020年3期
王云云 張云華


摘要:針對目前詞向量無法解決短文本中一詞多義的問題,提出融合詞向量和BTM主題模型的Multi-TWE多維主題詞向量模型。將BTM模型訓練得到目標詞與相應主題進行不同方式的連接,形成多維主題詞向量來表示多義詞詞義,最后將Multi-TWE模型應用于短文本分類,提出基于Multi-TWE模型的短文本分類方法,與SVM、BTM和Word2Vec分類方法進行對比實驗,實驗結果表明本文提出的短文本分類方法在平均F1值上比前三種方法分別提升了3.54%、11.41%和2.86%。
關鍵詞: 短文本分類; 一詞多義; BTM主題模型; 詞向量
【Abstract】 Aiming at the current problem that word vectors cannot solve the problem of polysemy in short texts, a Multi-TWE multi-dimensional topic word vector model combining word vectors and BTM topic models is proposed. The BTM model is trained to connect the target word with the corresponding topic in different ways to form a multi-dimensional topic word vector to represent the meaning of the polysemous word. Finally, the Multi-TWE model is applied to short text classification, and a short text classification method based on the Multi-TWE model is proposed. Compared with the SVM, BTM, and Word2Vec classification methods, the experimental results show that the short text classification method proposed in this paper improves the average F1 value by 3.54%, 11.41%, and 2.86% compared with the previous three methods, respectively.
【Key words】 ?short text classification; polysemy; BTM topic model; word vector
0 引 言
短文本是人們生活信息口語化在互聯網上的體現。顧名思義,短文本字數少、篇幅小,導致在分析短文本時,很難準確地分析出短文本的語義信息,并且有不少的詞語具有多種詞義和詞性,會根據不同的使用場景表達出不同的語義[1],這更加劇了短文本分析的難度。
2013年,Mikolov等人[2]提出的word2vec模型,利用上下文語義關系將詞語映射到一個低維稠密的空間,使相似詞語在空間中的距離相近,通過空間位置獲得對應的詞向量表示[3]。Zhu等人[4]在使用詞向量來表示文本向量的基礎上,融合了改進的TF-IDF算法,并利用SVM分類器進行短文本分類。Yao等人[5]使用詞向量來表示新聞標題類短文本,并通過判斷語義相似度來擴展文檔表示。以上研究表明詞向量模型應用在文本表示上的可行性。在使用詞向量進行詞義消歧方面,Niu等人[6]融合了知網的義原信息和注意力機制,實現自動地根據上下文選取合適的詞語詞義的方法,在判斷語義相似度和詞義消歧方面取得了更好的效果。Liu等人[7]提出將詞向量與主題模型相結合,組成主題向量用于詞語消歧。曾琦等人[8]提出了一種將多義詞的不同語義用不同主題來表示,最后訓練多義詞詞向量。深度學習方法中利用詞向量訓練的便捷性與主題模型能挖掘主題語義的這一能力相結合,既能保證準確率又能降低鄰域依賴。本文利用這一復合方法進行一詞多義的研究。
1 相關工作
1.1 BTM主題模型
由于傳統的主題模型是獲取文檔級別的詞共現[9],短文本的數據稀疏性導致傳統主題模型效果不好。針對這一問題,Yan等人[10]提出了BTM主題模型,來進行短文本建模。BTM通過語料級別的詞共現來為短文本建模。設有語料庫L,語料庫L中有一個二元詞組集合|B|,表示語料中所有的詞對,圖模型如圖1所示。
圖1中,b=(bi,bj)表示其中的任一詞對,bi,bj分別表示詞對中的詞語,z表示詞語的主題,K表示主題數目,z∈[1,K],θ表示每篇文檔的主題分布,φ表示不同主題下的詞分布,兩者皆服從狄利克雷分布。α和β分別是兩者的先驗參數。
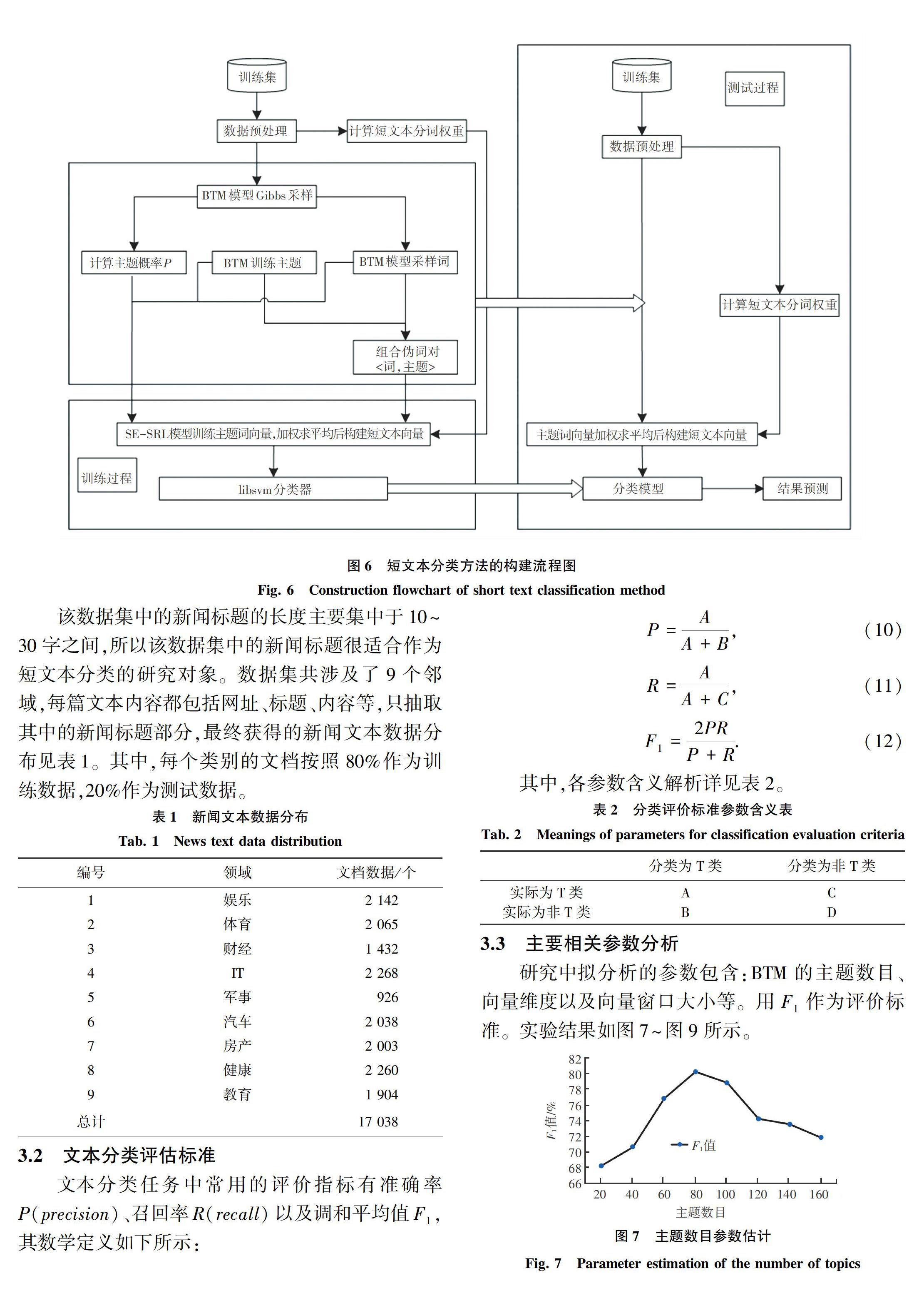
2 基于Multi-TWE模型的短文本分類研究
傳統詞向量模型無法很好地處理漢語中存在的一詞多義問題,主要是因為詞向量模型對于多義詞中各種語義信息的處理不敏感,訓練出的單一詞向量容易混淆多義詞的含義。2015年,Liu等人[7]提出了主題詞向量的概念,即將主題融入到基本的詞向量表示中,并允許由此產生的主題詞向量在不同語境下獲得一個詞的不同含義。
根據上述思想,本文將主題詞向量的概念應用到短文本語義挖掘中,本文的算法使用基于義原信息和注意力機制的SE-WRL詞向量模型來訓練詞向量,該模型使用注意力機制在一定程度上能夠消除多義詞的影響,但由于短文本本身具有的上下文特征稀疏性,SE-WRL詞向量模型在短文本上的應用效果有限。因為BTM主題模型能夠有效地解決短文本的特征稀疏的問題,因而,本文引入了BTM主題模型來進行短文本的語義挖掘,提出了一種Multi-TWE多維主題詞向量算法。
首先對于處理好的短文本語料進行BTM主題模型初始化,通過吉布斯采樣過程獲取詞和主題,利用SE-WRL詞向量模型分別進行向量的訓練,得到不同的主題詞向量,達到詞義消歧的效果,實現文本分類。該算法框架包含MuTWE-1和MuTWE-2這兩種主題詞向量模型,接下來將具體分析MuTWE-1和MuTWE-2這兩個模型算法。
2.1 MuTWE-1主題詞向量模型算法
MuTWE-1模型算法具體的參數推理分為2步,分別是:BTM模型參數推理和MuTWE-1主題詞向量訓練,具體算法流程如圖4所示。首先對BTM主題模型進行參數推理,這里通過使用吉布斯采樣方法抽取詞對b和每個詞對相對應的主題z,[JP2]然后將詞對b和主題詞z組合成偽詞(b,z),融入SE-WRL訓練模型中,最后得到主題詞向量W(b,z)。
分析圖7~圖9后得出:
(1)由圖7得出當主題數在80時F1值取最大值。
(2)由圖8得出詞向量維度在100~160左右最有利,為了平衡各模型,最終將向量維度設置為150,主題詞向量的維度設置為300。
(3)由圖9看出,當窗口大小為大于10 時,窗口長度的增長對于F1值的增長并沒有什么幫助,所以將實驗的最佳向量窗口大小設置為10。
3.4 分類對比實驗
為了驗證本文提出的基于Multi-TWE算法模型的短文本分類方法的有效性,分別選取VSM模型、BTM主題模型和TF-IDF加權word2vec模型作為對比實驗。所有分類方法選用libsvm作為分類器。實驗采用五折交叉驗證來評估各模型分類效果,測試結果見表3。
4 結束語
針對一詞多義問題,本文提出了融合詞向量和BTM主題模型的Multi-TWE多維主題詞向量模型算法并將其應用于短文本分類任務中。再通過實驗對模型中的參數進行了分析,確定了最佳的參數值,最后通過與幾種基準分類方法進行對比實驗,證明了本文提出的短文本分類方法的有效性和可行性。
參考文獻
[1] 張俊. 基于人類認知過程的文本語義理解模型(HTSC)及構建方法研究[D]. 上海:上海大學,2016.
[2]MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in Vector Space[C]//Proceedings of the International Conference on Learning Representations (ICLR 2013). Scottsdale, AZ: dblp,2013: 1.
[3]汪靜. 基于詞向量的中文短文本分類問題研究[D]. 武漢:中南民族大學,2018.
[4]ZHU Lei, WANG Guijun, ZOU Xxiaocun. A study of Chinese document representation and classification with Word2vec[C]// 2016 9th International Symposium on Computational Intelligence and Design (ISCID). Hangzhou, China:IEEE, 2016:298.
[5]YAO Di , BI Jingping , HUANG Jianhui, et al. A word distributed representation based framework for large-scale short text classification[C]// 2015 International Joint Conference on Neural Networks (IJCNN). Killarney, Ireland :IEEE, 2015:1.
[6]NIU Y, XIE R, LIU Z, et al. Improved word representation learning with sememes[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017, 1: 2049.
[7]LIU Y, LIU Z,CHUA T S,et al.Topical word embeddings[C]//Twenty-Ninth AAAI Conference on Artificial Intelligence.Austin, Texas: AAAI Press,2015:2418.
[8] 曾琦,周剛,蘭明敬,等. 一種多義詞詞向量計算方法[J]. 小型微型計算機系統,2016,37(7):1417.
[9]劉良選. 融合文本內部特征與外部信息的主題模型研究[D]. 海口:海南大學, 2016.
[10]YAN X, GUO J, LAN Y, et al. A biterm topic model for short texts[C]//Proceedings of the 22nd International Conference on World Wide Web. New York,USA:ACM, 2013: 1445.
