一種考慮句子結(jié)構(gòu)的移動客服對話文本建模方法
2020-07-04 20:28:28鐘建
現(xiàn)代信息科技 2020年3期
關(guān)鍵詞:智能化
摘? 要:隨著機(jī)器學(xué)習(xí)和深度學(xué)習(xí)方法在各個領(lǐng)域的發(fā)展和運用,越來越多的行業(yè)開始探索本行業(yè)的智能化發(fā)展之路,利用海量的數(shù)據(jù),結(jié)合人工智能的優(yōu)勢,優(yōu)化業(yè)務(wù),如何使用海量的數(shù)據(jù)是智能化的關(guān)鍵。在海量的數(shù)據(jù)中,文本是一個龐大群體,不同類型的文本由于其本身結(jié)構(gòu)的不同,在處理方面也有不同的策略。因此,針對移動客服對話文本的特點,文章提出了一種考慮句子結(jié)構(gòu)的文本建模方法。
關(guān)鍵詞:海量數(shù)據(jù);智能化;建模方法
中圖分類號:TP391.1? ? ? 文獻(xiàn)標(biāo)識碼:A 文章編號:2096-4706(2020)03-0033-03
Abstract:With the development and application of machine learning and deep learning methods in various fields,more and more industries begin to explore the intelligent development of the industry,using massive data,combining the advantages of artificial intelligence,optimizing business,how to use massive data is the key to intelligent. In the massive data,text is a huge group. Different types of text have different strategies in processing because of their own structure. Therefore,according to the characteristics of mobile customer service dialogue text,this paper proposes a text modeling method considering sentence structure.
Keywords:massive data;intelligence;modeling methods
0? 引? 言
現(xiàn)在的大數(shù)據(jù)主要是指圖形圖像數(shù)據(jù)和文本數(shù)據(jù),而對文本數(shù)據(jù)的建模遠(yuǎn)比圖形圖像數(shù)據(jù)要困難。一方面,圖形圖像數(shù)據(jù)本身便是數(shù)值化的數(shù)字,數(shù)字即代表了顏色,而文本數(shù)據(jù)是非數(shù)值化數(shù)據(jù);另一方面,圖形圖像本身具有空間結(jié)構(gòu),這樣的結(jié)構(gòu)也體現(xiàn)在了像素點的位置分布中,但是文本數(shù)據(jù)則沒有清晰的結(jié)構(gòu),如何建模文本數(shù)據(jù)中的結(jié)構(gòu)也是自然語言處理中的一個難點。
1? 傳統(tǒng)文本建模方法
在自然語言處理的眾多任務(wù)中,文本分類一直是比較熱門的研究領(lǐng)域,具有很廣的應(yīng)用場景,如情感分類、醫(yī)療數(shù)據(jù)分類。在深度學(xué)習(xí)方面,我們對文本數(shù)據(jù)的建模通常都是基于文本本身,即僅僅使用文檔數(shù)據(jù)本身的字信息或詞信息,通過字向量或詞向量的組合,將文本表示為二維張量。這樣的建模方法因其通俗易懂、實現(xiàn)簡單成為最常見的建模方法。但是這種建模方法有一個顯著的缺點,那就是忽略了文本本身的結(jié)構(gòu)信息,它將每個句子對文本特征提取以及對文本分類或其他任務(wù)的貢獻(xiàn)都看作是一樣的。如果文本的句子間確實沒有明顯的結(jié)構(gòu)關(guān)系,這樣的方法是合適的,因為這些句子在文本中是等價的。但是如果文本中的句子間存在明顯的結(jié)構(gòu)關(guān)系,不同句子在文本中的地位不一樣時,不考慮句子結(jié)構(gòu),直接使用文檔粒度的方法對文本進(jìn)行建模顯然是不合理的。在移動客服對話文本中,由于文本數(shù)據(jù)具有“問答式”的句式特點,因此沒有采用上述常用的文本建模方法。針對移動客服文本數(shù)據(jù),我們提出了一種考慮句子結(jié)構(gòu)的文檔建模方法。
從文本的數(shù)據(jù)特點來看,由于數(shù)據(jù)是由客服對話錄音翻譯而來,因此數(shù)據(jù)本身具有很強(qiáng)的結(jié)構(gòu)信息。我們將一次客服錄音的文本當(dāng)作一篇文檔,其中每篇文檔都由多個“問句,答句”的句子對構(gòu)成。通常情況下,問句大多由客服代表提出,根據(jù)問句的內(nèi)容,消費者會進(jìn)行相應(yīng)的回答,我們把客服代表兩個問題之間的所有文本當(dāng)作消費者對前一個問題的回答。用A代表客服代表的問句,B代表消費者的答句,文本數(shù)據(jù)格式即形如AiBjAi+1的對話記錄,我們將Bj看作對Ai的回答,與Ai+1無關(guān)。客服代表的問句A大多具有一定的行業(yè)規(guī)范性和順序性,問句中包含的許多信息是不可以忽略的,這些信息包含了消費者可能會關(guān)心的問題,如“網(wǎng)絡(luò)信號如何”“網(wǎng)絡(luò)速度如何”“流量使用情況如何”等等。而在消費者的答句B中,通常都有一些蘊含答案的詞匯,如“網(wǎng)速太慢”“沒有信號”“網(wǎng)絡(luò)太差”“服務(wù)太差”“換號轉(zhuǎn)網(wǎng)”等等。因此,在對消費者情緒及行為進(jìn)行分析的任務(wù)中,問句A雖然沒有答句B重要,但是也同樣不可忽略。建模句子的結(jié)構(gòu)信息尤其必要。
其實在自然語言處理問題中,這樣記錄字、詞或句子結(jié)構(gòu)信息也是一種常用的做法,比如谷歌在2018年10月發(fā)布的模型BERT[3]中,就是用到了字的位置信息,這樣的位置信息對其任務(wù)效果的提升也起到的一定的作用。常用位置信息的建模也大多和BERT模型中的方法一樣,但是這個方法對句子建模則不適用。一方面,結(jié)構(gòu)信息只有兩種:“問句”和“答句”,在建模文本中,這兩個信息值在不斷地重復(fù);另一方面,結(jié)構(gòu)信息不像傳統(tǒng)的位置信息關(guān)注字句的順序,而是關(guān)注句子的性質(zhì)。因此無法使用類似BERT上傳統(tǒng)的position embedding方法來建模移動客服對話文本,但是基于這樣的建模思想,我們提出了針對對話序列的句子建模方法。
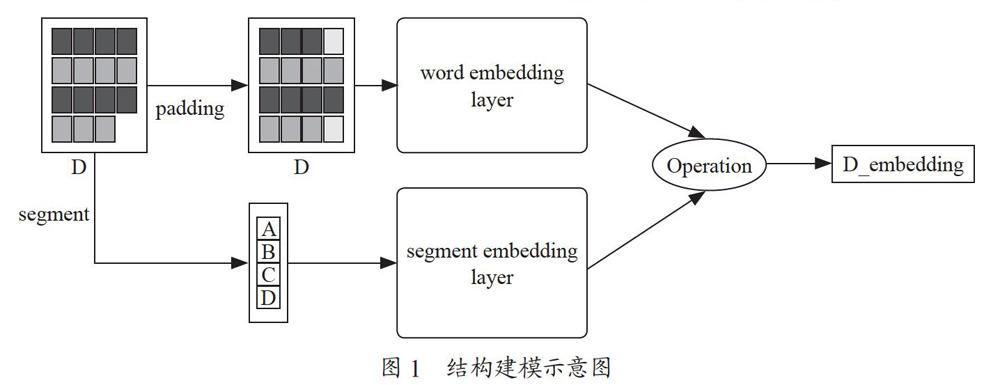
傳統(tǒng)的文本建模通常包含以下步驟:(1)文本序列化,即將文本轉(zhuǎn)化為數(shù)值;(2)文本向量化,即文本的embedding進(jìn)行表示,將文本表示為一個多維的張量,以此豐富文本的信息;(3)將文本張量放入模型中,進(jìn)行文本特征學(xué)習(xí)以及下游任務(wù),如分類。我們提出的建模方法的主要貢獻(xiàn)就在于在文本向量化的過程中,不僅僅將字或詞進(jìn)行向量化,還編碼了每個字或詞的屬性信息,即對該句是問句還是答句也進(jìn)行了區(qū)分。這樣保留了文本的結(jié)構(gòu)信息,這樣的信息體現(xiàn)了整篇對話文檔中不同句子的重要性。相對于將問句和答句平等對待的文檔粒度的文本建模方法,我們提出的建模方法是基于句子粒度的,符合常識,更加符合文本數(shù)據(jù)的特點。以單篇文檔為例,我們的建模方法過程如圖1所示。
基于圖1,我將從以下幾個方面介紹我們提出的建模方法:文本序列化、segment信息提取、句子embedding表示、segment embedding表示、文本embedding表示。
2? 文本序列化
文本序列化是所有機(jī)器學(xué)習(xí)以及深度學(xué)習(xí)方法的第一步,序列化即使用多維的向量來表示某個字或詞,這個向量或其變換后的向量最終作為模型的輸入。這個序列化的向量即代表了這個文本的所有信息,所以如何得到更好的向量表示是十分關(guān)鍵的問題,這也是眾多學(xué)者的研究領(lǐng)域。傳統(tǒng)的文本表示方法,如基于詞表的one-hot表示、基于統(tǒng)計信息的tf-idf表示都是很常用的序列化方法。one-hot表示由于其向量大小等于詞表大小,詞表大小通常較大,造成了表示向量的稀疏性,而tf-idf表示由于基于統(tǒng)計信息,所以未考慮句子的上下文信息。在深度學(xué)習(xí)領(lǐng)域,word2vec[1]、paragraph2vec[2]、doc2vec[2]都是較常用且效果不錯的方法,尤其是word2vec。針對移動文本數(shù)據(jù),由于數(shù)據(jù)不具有段落結(jié)構(gòu),所以不采用paragraph2vec方法。另外,我們的建模方法需要考慮句子結(jié)構(gòu),而doc2vec方法是不考慮文檔間句子結(jié)構(gòu)的,因此也不使用這個方法來建模,最終我們選取word2vec來建模句子,與使用預(yù)訓(xùn)練的詞向量不同,隨機(jī)初始化詞向量。主要步驟:(1)使用jieba分詞工具對每個問句、答句進(jìn)行分詞;(2)對分詞后的句子進(jìn)行padding對齊,使每句文本長度相等;(3)隨機(jī)初始化每個詞的向量表示,指定向量維度即可。這樣便完成了文本的序列化表示,每個詞都有一個特定維度的向量。
3? segment信息提取
segment信息即指每篇移動客服文本中,哪些是問句,哪些是答句。在建模過程中,使用數(shù)字1代表問句,數(shù)字2代表答句。那么一篇文本的segment信息即為一個二值向量,向量長度為文檔中句子的總數(shù)。直接按行讀取文本中的句子,依次標(biāo)注為1或2,即可得到該文本對應(yīng)的segment二值向量。
4? 句子embedding表示
在文本序列化中,我們介紹了字或詞的向量化,此時每句話都是由一個二維張量表示的,在深度學(xué)習(xí)中,還需要繼續(xù)對該二維張量進(jìn)行特征提取,形成一個特征向量,該特征向量代表這個句子的表示。如何將詞向量整合成句子向量也有很多方式,比如加權(quán)平均、求和等。在本次建模中,我們采用對所有字、詞向量求平均的方式作為句子embedding表示。使用字、詞表示的值表示句子也是目前較為常用的特征提取方式之一。
5? segment embedding表示
在segment信息步驟中,我們構(gòu)建了句子的結(jié)構(gòu)信息,每篇文檔都有對應(yīng)的結(jié)構(gòu)信息向量,由一個二值向量存儲。雖然句子的結(jié)構(gòu)信息已經(jīng)是數(shù)值類型(1、2表示),但是單個數(shù)值表示的特征容易在后續(xù)的提取中失去作用,所以為了保證結(jié)構(gòu)信息這個特征在后續(xù)特征提取中仍然發(fā)揮作用,我們使用多維向量來表示它們,而不是單純的一個整數(shù)值。我們使用序列化文本字和詞的word2vec方法,把句子的結(jié)構(gòu)信息值1、2也隨機(jī)初始化成多維向量。這樣每個句子的結(jié)構(gòu)信息便是一個由浮點數(shù)組成的向量,在后續(xù)的特征提取中,多維的結(jié)構(gòu)信息得以保留。
6? 文本embedding表示
通過上述方法,我們得到了一篇對話記錄的每個句子的向量表示,以及這個句子對應(yīng)的結(jié)構(gòu)信息的向量表示。假設(shè)文本D含有k個句子,詞向量的維度為dim1,結(jié)構(gòu)信息向量的維度為dim2,則對于D文本,有k*dim1大小的文本信息矩陣以及k*dim2的結(jié)構(gòu)信息矩陣。為了得到D的表示,可以采用以下的策略:(1)將句子的文本信息以及結(jié)構(gòu)信息對應(yīng)的句子信息拼接在一起,得到大小為k*(dim1+dim2)的矩陣,這個矩陣即表示文本D;(2)如果dim1=dim2=dim,可以采取信息相加的方式,即得到k*dim大小的矩陣,矩陣對應(yīng)位置的值即為文本信息矩陣和結(jié)構(gòu)信息矩陣值之和,這樣便得到了一篇文檔D的向量表示。
使用同樣的方法,對其他文檔進(jìn)行建模以及表示,最終得到訓(xùn)練數(shù)據(jù),即多個三維張量。假設(shè)其中一個張量大小為N*L*E,其中N代表文檔數(shù)量,L代表詞向量個數(shù),E代表embedding的維度,即dim1+dim2或dim(dim1=dim2時)。
完成文本數(shù)據(jù)的建模后,可以將數(shù)據(jù)張量作為各種不同的深度模型的輸入,在經(jīng)過深度模型的特征提取之后,得到最終用來分類的特征矩陣,再經(jīng)過最后模型的輸出層,便得到了分類結(jié)果。
7? 結(jié)? 論
針對移動數(shù)據(jù)文本,由于文本結(jié)構(gòu)的特殊性,使用傳統(tǒng)的文本建模方式會直接忽略這種結(jié)構(gòu)特征,忽略這一文本中普遍存在的特征明顯是不合理的,因此,針對數(shù)據(jù)的結(jié)構(gòu)特點,我們提出了一種新的建模方法。這種建模方法有效地考慮了移動客服對話文本中問句與答句的結(jié)構(gòu)特點,使得我們可以將文本的結(jié)構(gòu)特征與文本本身的含義結(jié)合在一起,由此可以更加合理地構(gòu)建移動客服對話文本。
參考文獻(xiàn):
[1] MIKOLOV T,SUTSKEVER I,CHEN K,et al. Distributed representations of words and phrases and their compositionality [C]//Advances in neural information processing systems,2013:3111-3119.
[2] LE Q,MIKOLOV T.Distributed representations of sentences and documents [C]//International conference on machine learning,2014:1188-1196.
[3] DEVLIN J,CHANG M W,LEE K,et al. Bert:Pre-training of deep bidirectional transformers for language understanding [J].arXiv preprint arXiv:1810.04805,2018.
作者簡介:鐘建(1969-),男,漢族,四川成都人,高級工程師,碩士研究生,研究方向:移動網(wǎng)絡(luò)的建設(shè)維護(hù)和優(yōu)化。
猜你喜歡
軍事文摘(2022年19期)2022-10-18 02:41:14
建材發(fā)展導(dǎo)向(2021年13期)2021-07-28 07:14:34
建材發(fā)展導(dǎo)向(2021年10期)2021-07-16 07:13:24
印刷工業(yè)(2020年4期)2020-10-27 02:46:02
印刷工業(yè)(2020年4期)2020-10-27 02:45:52
中國儲運(2019年5期)2019-05-15 09:37:40
能源(2018年10期)2018-12-08 08:02:52
汽車觀察(2018年10期)2018-11-06 07:05:08
中國交通信息化(2017年4期)2017-06-06 07:21:52
中國公路(2017年12期)2017-02-06 03:07:25
