一種結合改進Z-S細化算法的書法字雙層檢索方法
2020-07-09 22:13:09邵榮堂李婕鞏朋成張正文
現代信息科技 2020年2期
邵榮堂 李婕 鞏朋成 張正文
摘? 要:為了高效地識別利用數字化書法作品,文章提出一種改進的Z-S書法字細化算法,結合全局特征與局部特征進行雙層索引。首先,利用這種改進的Z-S算法提取單像素無毛刺的書法字圖像骨架信息,然后對書法字骨架的GIST全局特征進行初步篩選排序,結合書法字圖片局部特征進行二次索引排序,將兩種排序結果進行加權計算,得到檢索結果。所有的特征數據均使用自學習哈希算法進行二進制編碼,索引的過程采用加權海明距離計算的方法。試驗結果表明,該方法所需的檢索時間相較于骨架相似性檢索方法所需時間減少了約50%,相對于自適應書法字圖像匹配與檢索算法,在查全率和查準率上提升了近10%,提高了大數據量書法字檢索的效率。
關鍵詞:細化算法;全局特征;局部特征;自學習哈希;二進制編碼;加權海明距離
中圖分類號:TP391.43? ? ? ?文獻標識碼:A 文章編號:2096-4706(2020)02-0007-04
Abstract:In order to effectively recognize and utilize digital calligraphy works,this paper proposes an improved Z-S calligraphy word refinement algorithm,which combines global features and local features for double-layer index. First of all,the improved Z-S algorithm is used to extract the skeleton information of a single pixel and burr free calligraphy image,then the GIST global features of the calligraphy skeleton are preliminarily selected and sorted,combined with the local features of the calligraphy image,the secondary index sorting is carried out,and the two sorting results are weighted to get the retrieval results. All feature data are binary coded by self-learning hash algorithm,and the process of index is calculated by weighted Hamming distance. The experimental results show that the retrieval time of this method is about 50% less than that of the skeleton similarity retrieval method. Compared with the adaptive calligraphy image matching and retrieval algorithm,the recall and precision of this method are improved by nearly 10%,and the efficiency of large amount of data calligraphy character retrieval is improved.
Keywords:thinning algorithm;global feature;local feature;self-learning hash;binary encoding;weighted Hamming distance
0? 引? 言
書法是極富中華文化的一種文字美的藝術表現形式,然而書法字因其多樣的“造型”而難以通過OCR識別[1],其難點在于,書法字主要通過運用筆畫的扭曲來營造美感,由此導致筆畫變形、不平不直,不同書寫風格的筆畫連接方式也與印刷體完全不同。
本文提出了一種改進的書法字雙層檢索方法,首先,采用一種改進的Z-S書法字細化算法,能夠快速獲得筆畫更加平滑、毛刺更少的書法字骨架;提取訓練集書法字骨架圖像的全局特征與訓練集原始書法字圖像局部特征,將特征值通過哈希算法進行二進制處理,將這些二進制數值存儲為特征數據庫;其次,采用由粗到精的檢索方式,與原始書法字圖像的局部特征與書法字骨架圖像的全局特征進行索引,提高識別的準確率;最后,采用自學習哈希算法,將得到的全局和局部特征值轉換為二進制編碼,加權自學習哈希算法可以在將特征進行二進制處理的同時進行加權計算特征之間的海明距離,使返回的結果更加準確,并提高檢索的速度,增強書法字檢索的可用性。[2]
1? 系統框架
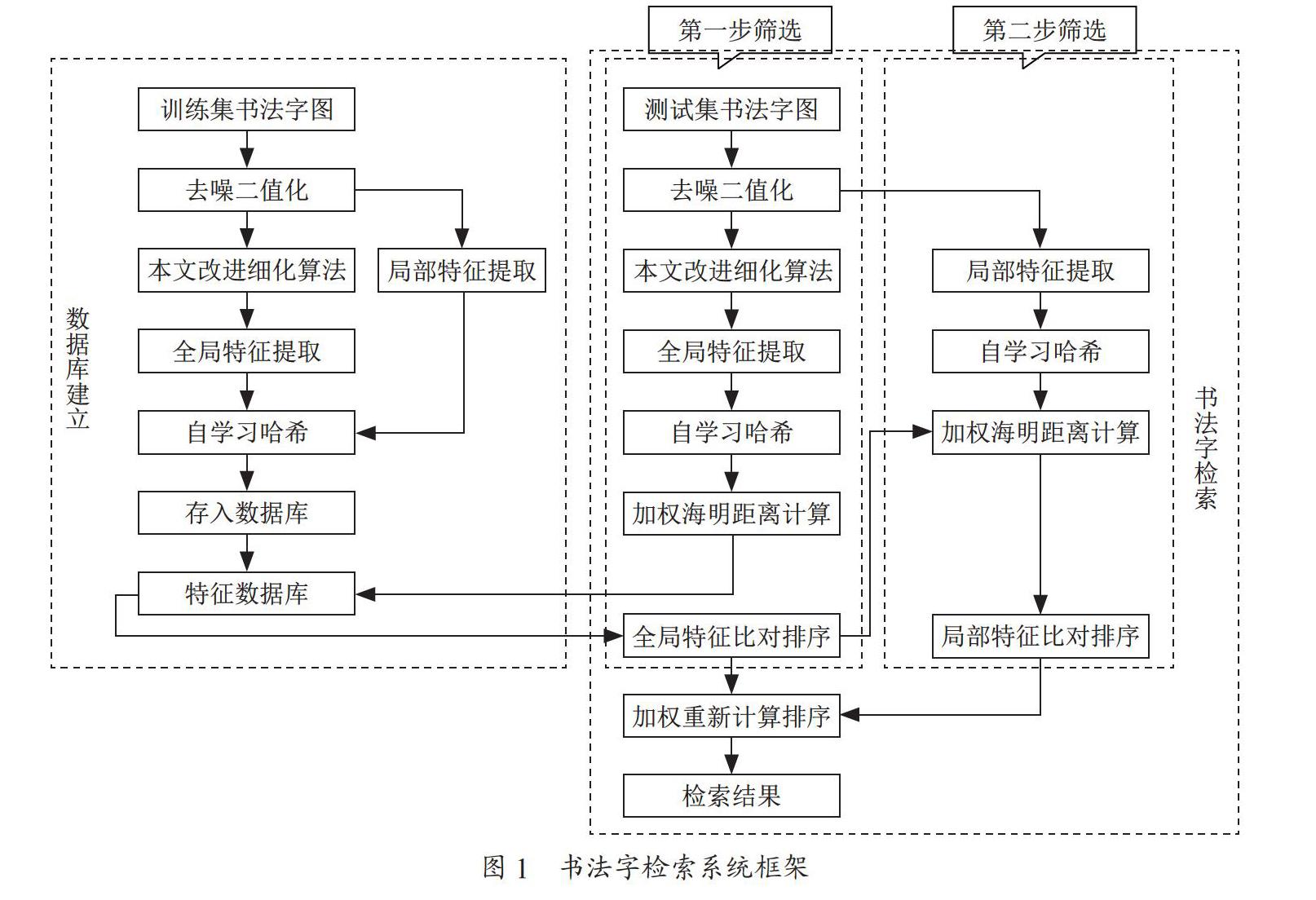
本文提出的整個系統框架如圖1所示,主要分為兩步,第一步是建立完備的特征數據庫,第二步是構建完整的書法字檢索流程。
特征數據庫的建立首先將訓練集的書法字圖像進行歸一化去噪二值化等預處理,本文利用一種改進的書法字細化算法對訓練集書法字進行處理,將得到的細化圖像進行全局特征的提取,然后利用自學習哈希算法對得到的數據進行二進制編碼并儲存,最后將預處理后的圖像進行局部特征的提取,并將得到的數據同樣進行二進制編碼并儲存。最終將兩種特征的數據組合儲存為本文提出的特征數據庫。
書法字檢索部分采用由粗到精的方法,首先將測試集書法字圖像進行與測試集相同的預處理,利用一種改進的書法字細化算法對預處理后的圖片進行處理,并提取出細化圖像的全局特征和預處理后圖像的局部特征,并將得到的特征進行二進制編碼,并與特征數據庫進行索引。由于特征向量之間的海明距離可以用來表示數據的相近程度,所以首先通過加權海明距離計算得到全局特征的比對排序結果,并將得到的結果與測試集局部特征再進行一次加權海明距離計算,得到局部特征的比對排序結果,將兩種特征的檢索結果進行重新加權計算,得到最終檢索結果。
2? 一種改進的Z-S書法字細化算法
2.1? 傳統的Z-S快速并行細化算法
傳統的Z-S快速并行細化算法,為了去除圖像的邊界點并保留骨架的關鍵點,對二值化圖像進行運算處理,第一次運算中被刪除的點是位于東南邊界的像素點和西北角的像素點,第二次運算中刪除的點是位于西北邊界的像素點和東南角的像素點,不斷重復兩次運算過程,直到圖像中的像素點不再發生變化,即視為處理完畢。
傳統Z-S快速并行細化算法處理之后,從上往下并從左往右檢測像素點,當檢測到像素點之后,將該像素點記為P1,并構建P1的八鄰域,點P1的八鄰域圖中Pi(i=2,3,…,9)表示的8個鄰域像素點,像素點的值為0或1。[3]
2.2? 基于Z-S算法改進的單像素化處理算法
傳統的Z-S快速并行細化算法普遍存在的問題是,筆畫在端點與交叉點附近會出現大量的毛刺,影響識別效果,所以在此基礎上,本文提出了一種改進的書法字細化算法。首先檢測圖像像素點的分布情況,當檢測到像素點時,建立目標像素點八鄰域像素的鄰接矩陣,通過判定中心像素點的刪除是否影響骨架的連通性,來刪除不會破壞骨架連通性的像素點,從而實現單像素化處理,經過這樣的處理之后會將交叉點附近與端點附近的毛刺減少。
定義1:檢測八鄰域垂直方向的像素點,若滿足以下四個條件中的任意一種,則刪除中心像素點P1:
(a)P2+P8=2,P7=0或1
(b)P4+P6=2,P3=0或1
(c)P8+P6=2,P9=0或1
(d)P2+P4=2,P5=0或1
定義2:檢測八鄰域水平方向的像素點,若滿足以下四個條件中的任意一種,則刪除中心像素點P1:
(a′)P2+P4=2,P9=0或1
(b′)P8+P6=2,P5=0或1
(c′)P8+P2=2,P3=0或1
(d′)P6+P4=2,P7=0或1
算法1:刪除垂直方向冗余像素點
輸入:通過Z-S快速并行算法得到的骨架圖像,遍歷圖像中的每一個像素點,每個像素點的八鄰域點記為Pi(i=2,3,…,9);
輸出:delete or retain
步驟:
(1)對每一個像素點都建立八鄰域,并將中心像素點記為P1;
(2)判斷像素點P1及其臨近的八鄰域像素點是否滿足定義1中任一條件:
如果假,返回保留;
如果真,則刪除相應的中心像素點P1。
算法2:刪除水平方向冗余像素點
輸入:通過算法1處理后的圖像,遍歷所有像素點,每個像素點的八鄰域點記為Pi(i=2,3,…,9);
輸出:delete or retain
步驟:
(1)對每一個像素點都建立八鄰域,并將中心像素點記為P1;
(2)判斷像素點P1及其臨近的八鄰域像素點是否滿足定義2中任一條件:
如果假,返回保留;
如果真,則刪除相應的中心像素點P1。
在交叉點處被刪除的像素點經過改進處理之后,能夠在保持骨架的連通性的同時,使交叉處多余的像素點被刪除。本文提出的改進后的Z-S算法可以在一定程度上減少細化圖像的形變以及毛刺,使細化得出的圖像“形態”更貼近于毛筆字的原圖。[4]
3? 書法字圖像特征的提取與檢索
3.1? 基于GIST算法的全局特征
本文選取GIST特征算法作為書法字全局特征提取的算法,GIST特征是對Gabor特征的改進與拓展,通過多方向尺度的Gabor濾波器濾波后進行級聯,該特征特點是可以將一張圖片中的信息用低維度的特征向量進行替代。
本文利用一組空間分辨率和方向不同的Gabor濾波器對圖像進行濾波(8個尺度,3個方向),然后分割成3×3的網格塊來表示濾波之后的圖像,對每個網格塊進行取均值,構成維度是3×8×3×3=216維的GIST向量。
3.2? 基于SIFT算法的局部特征
對于每張圖像來說,檢測的局部特征點是不同的,單純利用局部特征進行圖像識別會非常耗時,本文先采用全局特征進行識別,然后采用局部特征來進行漢字特征提取。
本文利用SIFT特征算法來進行局部特征的提取,該特征可以依據少量的物體產生大量的特征向量,對于大數據量的特征庫而言,該算法的引入可以提高檢索結果的準確率。[5]
該算法構造DoG尺度空間,使用不同參數的高斯模糊表示不同的尺度空間,檢測在不同尺度空間下都存在的特征點。在每個候選的位置上,通過尺度空間DoG函數進行曲線擬合尋找極值點。基于局部的梯度方向,分配給每個關鍵點位置一個或者多個方向,后續所有的操作都是對于關鍵點的方向、尺度和位置進行變換,以特征點為中心、以3×1.5σ為半徑的領域內計算各個像素點的梯度的幅角和幅值。在每個特征點周圍的鄰域內,在選定的尺度上測量圖像的局部梯度,得到圖像的SIFT特征點。
3.3? 加權自學習哈希高維數據索引算法
特征提取后,本文采用了一種加權自學習哈希算法進行索引,算法采用自學習哈希算法框架將原始數據轉化為二進制編碼并學習得到哈希函數。自學習哈希算法包含兩個學習階段,無監督學習為第一個階段,主要目的在于把原始空間中的高維數據轉成相對較短的二進制編碼。有監督學習為第二階段,把第一階段獲取的所有數據二進制編碼視為標簽,通過機器學習法訓練出多個分類器,查詢數據到來時,通過訓練出來的分類器將查詢數據轉化為二進制編碼。
在檢索方面,因為海明距離可以用來直接計算特征向量之間的距離,用距離的大小表示數據的相近程度,但直接進行海明距離的計算會導致計算距離與真實距離無法明確區分,例如二進制編碼“101”與“001”“111”的海明距離都是1,這樣直接使用海明距離計算來進行檢索就可能出現錯誤的檢索結果。
4? 實驗結果與分析
本文改進的Z-S書法字細化算法相較于其他傳統的骨架提取擁有更少的毛刺和更好的連通性,最大程度上保留了書法字的“形”。在圖像特征方面,選取GIST特征與SIFT特征來分別提取骨架圖像與原始圖像的全局特征與局部特征,在基于GIST特征的全局特征提取時,需提取漢字圖片的骨架信息,這樣在骨架的基礎上進行全局特征提取時,可以避免筆畫大面積粘連帶來的誤操作。本文采用自學習哈希算法對所有特征值進行二進制編碼,該算法可以在簡化數據的同時仍然保留其原始數據的特征,極大程度上減少了特征庫的數據容量大小,加快識別檢索的速度,并在檢索的時候進行加權海明距離計算,并利用得到的距離大小進行排序,最終將基于兩種特征得到的排序結果相結合,重新進行加權計算處理,得到最終索引結果。
4.1? 本文書法字檢索流程
書法字檢索的主要流程分為以下幾點:
步驟1:對測試集樣本進行歸一化去噪二值化等預處理;
步驟2:用本文提出的改進的Z-S書法字細化算法求取骨架;
步驟3:對測試樣本進行特征提取,形成特征庫;
步驟4:求取測試集樣本骨架圖像的全局特征,并求取測試集樣本圖像局部特征;
步驟5:采用自學習哈希算法將步驟4中求得特征值進行二進制處理;
步驟6:用全局特征與特征數據庫進行加權海明距離計算,從數據庫中查詢候選字集合,按距離由小到大進行排序;
步驟7:將步驟6求得的數據集合與測試集進行局部特征的加權海明距離計算,得到排序;
步驟8:將步驟6與步驟7中求得的排序進行重新加權運算,得到最終排序后輸出。
4.1.1? 特征數據庫的建立
本文使用CSDNtinymind數據作為訓練集,對每一個書法字圖像進行歸一化去噪二值化等預處理,并利用改進的Z-S書法字細化算法提取書法字骨架。求取骨架圖像的全局特征與原始圖片的局部特征。并將求取得到的特征進行二進制編碼后存入特征數據庫。通過切分大量數字化手寫書法字作品,得到3300個書法字單字的圖片,并將這些圖片進行相同操作存儲作為測試集使用。
4.1.2? 檢索結果
將本文方法檢索結果與骨架相似性算法檢索結果進行對比,本文采取書法字雙層檢索的方法,將全局特征索引得到的結果與局部特征索引得到結果進行加權計算,得到最終的索引排序結果。在經過兩次篩選之后,會使錯誤的信息得到刪除,使識別準確率得到進一步的提升。
4.2? 實驗結果分析
本實驗采用Visual C作為開發平臺,PC配置Intel Core i5-7300HQ四核處理器,16 GB DDR4內存,GTX1050TI獨立顯卡,Windows 10操作系統。
本實驗的主要目的是檢測本文方法的檢索速度,本文利用自學習哈希算法將所有訓練集提取出的特征進行了二值化處理,簡化數據庫的數據容量大小并加快檢索的速率,并在海明距離計算的同時進行加權處理,提高了識別的準確率。
5? 結? 論
試驗結果表明,本文方法在保證檢索效率的同時,明顯提高了識別的準確性,使書法字檢索更具有實用性。本文提出的識別方法在識別速率與準確度上較現有方法有一定程度上的提升,但仍有不足之處,樣本中未包含行書與草書等比較難以識別的字體,草書以及行書等樣本筆畫粘連嚴重并且不易識別,還需在識別階段進行新的探索,在實驗儀器升級的情況下還可考慮增加更多樣本來提高識別的準確率。
參考文獻:
[1] 周一楓,張華熊.抗傾斜的中文文本圖像文件識別技術 [J].計算機系統應用,2019,28(1):32-37.
[2] 吳媛,楊揚,頡斌,等.基于數學形態學的脫機手寫體漢字識別方法 [J].計算機應用,2006(3):622-623+626.
[3] 俞凱,吳江琴,莊越挺.基于骨架相似性的書法字檢索 [J].計算機輔助設計與圖形學學報,2009,21(6):746-751.
[4] 俞凱,吳江琴.書法字快速多層檢索方法 [J].計算機輔助設計與圖形學學報,2011,23(8):1415-1419.
[5] 章夏芬,張龍海,韓德志,等.自適應書法字圖像匹配和檢索 [J].浙江大學學報(工學版),2016,50(4):766-776.
作者簡介:邵榮堂(1995-),男,漢族,湖北黃石人,碩士研究生,主要研究方向:模式識別、圖像處理;李婕(1984-),女,漢族,湖北宜昌人,博士,講師,主要研究方向:計算機視覺;鞏朋成(1982-),男,漢族,湖北宜昌人,講師,博士,碩士生導師,主要研究方向:MIMO雷達、頻控陣列信號處理以及波形設計等;張正文(1965-),男,漢族,湖北團風人,碩士,副教授,碩士生導師,研究方向:陣列信號處理及其應用。
