基于一致性聚類的在線服務信譽度量
2020-07-13 06:16:36劉艷麗付曉東劉利軍
小型微型計算機系統 2020年7期
劉艷麗,付曉東,2,岳 昆,劉 驪,馮 勇,劉利軍
1(昆明理工大學 信息工程與自動化學院,昆明 650500) 2(昆明理工大學 云南省計算機技術應用重點實驗室,昆明 650500) 3(云南大學 信息學院,昆明 650091)
1 引 言
在線服務是指運用互聯網技術向用戶提供線上服務的方式.隨著互聯網技術的迅速發展和普及,越來越多的設備被接入到互聯網中,使在線服務規模顯著增長.在線服務已廣泛應用于Web服務、電子商務、移動多媒體、電子學習等領域[1].然而在面對許多功能相似或相同的在線服務時,用戶不僅要考慮功能需求,還要考慮非功能需求,即服務質量(Quality of Service,QoS)[2].此外,由于互聯網具有開放性和虛擬性,導致服務提供者可能發布不真實、不客觀的服務信息[3].信譽作為衡量服務QoS的重要指標,反映的是用戶對服務總體的信任程度[4].因此,研究準確、客觀的在線服務信譽度量方法不僅能有效地幫助用戶選擇在線服務也能促使服務提供者改善其服務質量.
用戶與在線服務進行交易后,會根據個人體驗對在線服務進行反饋評分,信譽系統將用戶反饋評分以特定的方式集結起來形成信譽[5].用戶對服務的評分可看成是用戶對服務的分類.例如,用戶對服務{s1,s2,s3,s4,s5,s6,s7}的評分為(1,3,3,1,2,4,2),體現出用戶將服務分為4類,分別為{s1,s4}、{s2,s3}、{s5,s7}以及{s6}.因此基于評分的服務信譽度量本質上是集結各用戶對服務的分類信息獲得用戶群體對服務分類結果的過程.由于用戶具有不同的行為習慣和偏好,其對服務的分類具有明顯的個性化特征.因此,提高用戶對服務分類與最終獲得的信譽之間的一致性是確保信譽度量質量的重要因素.一致性反映的是用戶群體對評價結果達成一致的程度,是測量群體評價意見一致性程度的重要參數[6].現有累加法、均值法等已被廣泛應用的信譽度量方法均未考慮到用戶對服務分類與信譽之間的一致性關系.
隨著互聯網上在線服務數量的不斷增長及類型的多樣化,如何集結用戶對服務的分類合理有效地進行在線服務信譽度量成為亟待解決的重要問題.針對上述問題,本文提出一種基于一致性聚類[7]的在線服務信譽度量方法.該方法將用戶對服務的評分視為用戶對服務的分類,通過聚合所有用戶對服務的分類形成一個最終的服務聚類,使得到的最終信譽度量結果與用戶對服務分類之間的一致性最大且聚類效果較好.首先,考慮到在計算服務分類中的簇間和簇內相似性時需要消耗大量的空間,方法使用二進制組成的位向量來存儲在線服務分類中的每個簇,降低存儲空間的消耗;其次,方法是在服務集群的分類級別上運行的,具有很高的可擴展性;最后,對在線服務的分類進行聚合的過程中,不需要輸入任何參數,自動計算最終聚類中的聚類數量.有效地提高了在線服務信譽的合理性和有效性.
2 相關工作
信譽作為評價服務的重要QoS之一,對服務選擇的決策起著重要作用.近年來,為了研究更加準確、理性的在線信譽度量,國內外學者開展了一系列的工作.目前的在線服務信譽度量方式主要分為基于用戶反饋評分和綜合多種因素對服務信譽的影響[8].
常見的基于用戶反饋評分的在線信譽度量方式有累加法模型、平均法模型、模糊模型、Beta信譽模型等[9],上述方法均以用戶反饋評分為基礎來計算服務信譽,其計算原理簡單,可以快速得到信譽值.例如,eBay使用累加法將用戶對在線服務做出的反饋評分進行累加得出服務信譽值,Amazon使用平均法,以服務獲得的所有反饋評分為基礎求取平均值計算服務信譽.文獻[10]提出了一種基于模糊的大數據處理框架來評估云服務的信任級別,在用戶反饋的基礎上評估服務的信任級別;文獻[11]提出了一種Beta信譽模型,該模型在統計學理論的基礎上結合β概率密度函數和用戶反饋的評分計算在線服務信譽;文獻[12]提出了一種考慮用戶隱私代價的服務選擇模型,其運用模糊邏輯與服務信譽、用戶隱私相結合來計算用戶的隱私代價,從而實現對候選服務的排序.
基于用戶反饋評分的信譽度量方法未考慮服務質量、社交網絡關系等其他因素對服務信譽的影響[13].為此,文獻[14]基于QoS相似度計算服務信譽,并由低到高對其進行排序,從而實現對Web服務的信譽評估;文獻[15]基于用戶屬性的細度化提出了一種信譽度量方法,在不考慮用戶身份的前提下,用戶可以通過評價其他用戶的屬性來提高評價的信任度;文獻[16]提出了一種新的信譽度量機制,它將用戶的序數偏好聚合到信譽中.首先根據序數偏好定義服務之間的優勢關系;然后基于服務對的優勢關系構造一個有向無環圖;最后從圖中找出服務的排序.
上述研究雖然從多個方面對在線服務進行了信譽度量,但未考慮到將用戶對服務的評分視為用戶對服務的分類時用戶對服務分類與信譽之間的一致性關系,導致在對分類進行聚合時會出現具有不同類別的聚類結果,聚類效果較差,不符合大部分用戶的偏好,降低了服務信譽的穩定性和準確性.另外,如果用戶對服務的反饋評分被操縱,則根據用戶反饋評分得到的在線服務信譽度量結果也能被輕易改變.考慮到以上研究中存在的不足,本文提出一種基于一致性聚類的在線服務信譽度量方法.該方法是將所有用戶對服務的分類結果進行聚類得到服務信譽的一個過程,在該過程中充分考慮了用戶對服務的分類與信譽之間的一致性關系,使最終聚類的每個簇中的服務最大程度的相似,而不同簇中的服務相似性最小,從而使在線服務的真實性能得到客觀地反映.最后,通過實驗驗證了本文方法的有效性和客觀性.
3 問題描述
本文主要研究如何把所有用戶對服務的分類進行聚合,最終形成一個服務聚類,并且使最終聚類獲得的服務信譽與所有用戶對服務分類之間的一致性達到最大,實現基于一致性聚類的在線服務信譽度量.
3.1 問題定義
為了研究所有用戶對服務的分類結果與信譽之間的一致性關系問題,本文給出以下相關定義:
定義1.U={ui|i=1,2,…,m}為用戶的有限集,S={sj|j=1,2,…,n}為在線服務的有限集.其中,m表示用戶個數,n表示在線服務個數.
定義2.R=[rix]m×n為用戶-服務評分矩陣,rix表示第i個用戶對第x個在線服務的評分.當rix=riy時,表示用戶ui把服務sx和sy歸為同一類;當rix=N/A時,表示用戶ui未對服務sx進行評分,即用戶ui未對服務sx進行分類,即用戶對服務的分類可以是不完整的.
定義3.矩陣R中的每行表示用戶ui對在線服務集S的分類,用向量ri=(ri1,ri2,…,rin)表示.集合cip={sx∈S|rix=p}表示用戶ui把在線服務集S中的服務sx放在等級為p的簇中.集合Ci={ci1,ci2,…,cih}為用戶ui把在線服務集S分為h個等級簇的集合.集合C={Ci|,i=1,2,…,m}為所有用戶U對服務集S分類中的簇集合.
定義4.將所有用戶對服務的分類進行聚合,得到一個最終聚類.最終聚類中的每個簇用集合c*q={sy∈S|q=N},其中q是經過多數投票后服務sy所在的簇標簽,為自然數.最終聚類用集合π*表示,即π*={c*1,c*2,…,c*g}且1≤g≤h.
定義5.由用戶對服務的分類得到的最終聚類用π*表示,π*中服務集S的信譽評級用向量rz=(rz1,rz2,…,rzn)表示,rz1,rz2,…,rzn分別表示服務s1,s2,…,sn的信譽級別,且rz1,rz2,…,rzn可由聚類中服務的評分計算獲得.
定義6.在線服務分類中的簇間相似性ECS表示在一對服務簇
(1)
式(1)中,sim(sx,sy)是在線服務sx和sy在給定所有用戶對服務分類C中被分配給相同簇的次數.ECS值越小,表明服務簇cip和cjk之間的相似性越小,分離性越大.
定義7.在線服務分類中的簇內相似性ICS表示在服務簇cip內服務對象的相似程度[17].其定義如下:
(2)
3.2 舉例說明
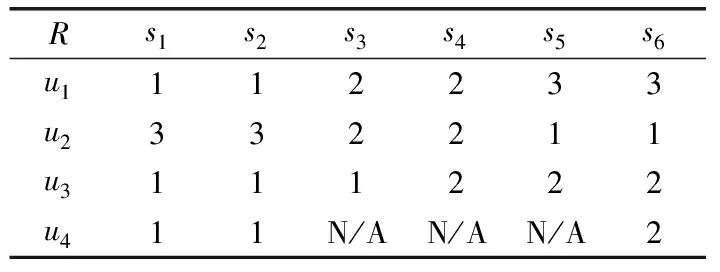
例1.假設有4個用戶U={ui|i=1,2,…,4}共同對6個在線服務S={sj|j=1,2,…,6}進行評分,評分矩陣R=[rix]4×6,如表1所示.其中表中的評分表示了用戶對服務的滿意程度,我們采用電子商務評價機制中常用的1-5的評分等級來表示很不滿意、不滿意、一般、滿意、很滿意.rix=N/A表示用戶與服務未進行交互.
表1 用戶-服務評分矩陣表
Table 1 Ratings matrix of user-service
Rs1s2s3s4s5s6u1112233u2332211u3111222u411N/AN/AN/A2
在本文中,將用戶對服務的評分視為用戶對服務的分類,即針對同一在線服務集,用戶將評分相同的在線服務歸為同一類,由此得出所有用戶對在線服務的分類.由表1可見,對于6個在線服務,用戶u1將服務s1~s6分成3類,即s1和s2、s3和s4、s5和s6.以此類推,u2把服務分成3類,u3把服務分成2類.由于用戶不一定對所有服務進行評分,所以用戶u4只對服務s1,s2,s6進行了評分,把服務分成2類.上述分類可用圖1表示.
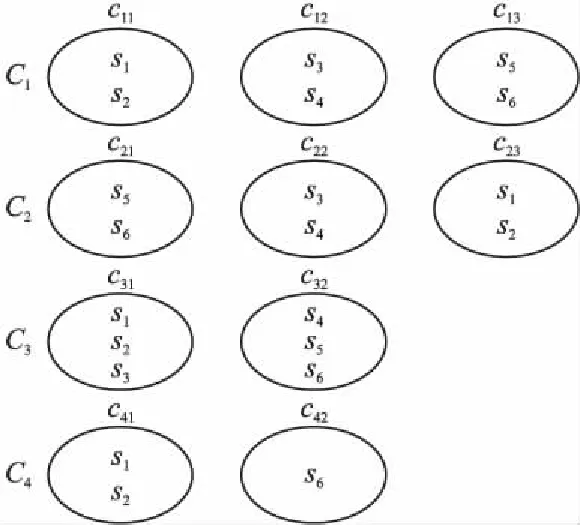
圖1 多個用戶對在線服務的分類
傳統的在線服務信譽度量未考慮到用戶對服務分類與信譽之間存在的一致性關系問題.例如,通過均值法計算用戶對服務評分的平均值得到的信譽向量為ravg=(1.5,1.5,1.67,2,2,2).從ravg中可看出服務s1~s6被分成3類,且認為s4,s5,s6屬于同一類.然而表1中所有用戶對服務s4,s5,s6的評分不相同,認為s4與s5,s6不在同一類別中.使用均值法會使原本不在同一類別的服務被分到相同類別中,導致最終得到的信譽與所有用戶對服務分類之間的不一致性較大,缺乏合理性.此外,如果將用戶u1對服務s6的評分降低至1分,則發現通過均值法計算服務s6的信譽降低至1.5分,且其他服務的信譽未發生改變,這大大降低了服務s6的信譽等級,使其具有較差的抗操縱性.因此,本文提出了一種基于一致性聚類的在線服務信譽度量方法,有效地避免了因未考慮用戶對服務分類與信譽之間的一致性關系導致的在線服務信譽等級劃分不合理的問題,同時還提高了方法的抗操縱性.
4 基于一致性聚類的服務信譽度量
由于目前的在線服務信譽度量方法均未考慮到信譽結果與用戶對服務分類之間的一致性關系,導致通過用戶-服務評分計算得到的服務信譽準確性較低.因此,本文提出了一種基于一致性聚類的在線服務信譽度量方法.方法將用戶對服務的評分視為用戶對服務的分類,根據在線服務中的簇內和簇間相似性建立基于相似性的最小成本生成樹(Similarity-based Minimum-cost Spanning Tree,SMST)[18],從具有最小權重值的邊開始,對SMST進行切割產生多種可能的聚類.然后通過一致性質量函數[19]來搜索所有可能的聚類以找到具有更好整體質量的最終聚類π*,使最終聚類π*擁有緊湊性最強和分離性最大的簇.
定義8.一致性質量函數.本文中用一致性質量函數φ來評價聚類πi的好與壞.定義如下:
(3)
(4)
其中,listmax是得到的一列值中的最大值,listmin是得到的一列值中的最小值.運用公式(4),通過變換在[0,1]范圍內所有用戶對服務分類中的ICS和ECS值,減少了在計算簇內和簇間相似性的過程中大值和小值對計算結果的不利影響.
獲得的最終聚類π*的一致性質量函數φ必須滿足:
(5)
從式(5)可以看出聚類π*擁有最好的整體質量,使最終聚類π*中的簇內相似性最大,簇間相似性最小.其服務信譽度量結果相對于所有用戶對服務分類的結果來說盡可能多地一致.
4.1 基于位向量的在線服務簇表示
本文采用的一致性聚類方法在聚合所有用戶對服務的分類形成一個最終聚類的過程中,考慮到隨著互聯網的快速發展,在線服務數量不斷增加,將導致在計算所有用戶對服務分類之間的簇內和簇間相似性時需要占用很大的存儲空間.因此,為了節省空間用由二進制組成的的位向量來存儲在線服務中的每個簇[17].其中,每個簇中服務的存在由1表示,服務的缺失由0表示.每個用戶對在線服務的分類表示與在線服務集|S|的大小一樣長.
為了應對具有不同數量的在線服務分類,我們利用投票機制來組合分類結果,從而引出服務之間相似性的新度量[20].考慮到不同服務很可能共同存在于不同服務分類中的同一簇中,因此將同一簇中服務對的同時出現作為其關聯的投票.在獲得用戶對服務分類的基礎上,通過統計不同服務在所有用戶對服務分類中被分配給相同簇中的次數得出共同關聯矩陣(Co-association Matrix,SM),并基于SM計算所有用戶對服務分類中的簇間和簇內相似性.
定義9.共同關聯矩陣為SM=[smxy]n×n,smxy表示服務sx和sy被分配給相同簇的次數.則:
smxy=votesxy/m
(6)
式(6)中,m為用戶數量,votesxy是服務對(sx,sy)被分配給所有用戶對服務分類中的相同簇的次數,即sx∈S,sy∈S.然后將分類中服務對同時出現在相同簇中的次數映射到|S|×|S|的共同關聯矩陣中.最后根據得到的SM進一步計算在線服務中的簇間相似性和簇內相似性.
4.2 簇間和簇內相似性計算
在對獲得的所有用戶對在線服務分類進行聚合時,考慮到不同服務在分類中的相似程度不同,可以運用兩個非常著名的無監督客觀測量指標:簇間相似性和簇內相似性來實現對分類中的在線服務進行簇間和簇內相似性計算.在根據公式(1)和公式(2)進行相似性計算時,需要知道服務sx和sy同時出現在相同簇中的次數sim(sx,sy).由于本文中是運用SM來統計分類中服務sx和sy同時出現在相同簇中的次數,因此sim(sx,sy)=smxy.則在線服務分類中的簇間相似性計算如下:
(7)
在線服務分類中的簇內相似性計算如下:
(8)
根據例1中給出的在線服務分類,分別運用公式(7)和公式(8)計算分類中的ECS和ICS.由于ECS的計算是利用服務對象級別的信息來提供非常準確的分類級別信息,所以此時得到的ECS值非常有效.
由于本文中的信譽度量是將所有用戶對服務的分類進行聚合得到一個聚類的過程,所以可以將在線服務分類中的ECS和ICS擴展為聚類πi的簇間相似性和簇內相似性.
定義10.聚類πi的簇間相似性定義如下:
(9)
定義11.聚類πi的簇內相似性定義如下:
(10)
式(10)中,ICSC(πi)值越大,表示πi的簇越緊湊.
4.3 基于用戶對服務分類與信譽之間的一致性尋找最終聚類
為了使用戶對服務分類結果與信譽之間的一致性達到最大,我們需要尋找具有緊湊且分離良好的簇的最終聚類.本文方法在不輸入任何參數的情況下,以最小生成樹的形式組織所有用戶對服務的分類來處理分類聚合問題,因為它不僅可以保留原始的所有用戶對服務的分類信息,而且是稀疏圖,處理復雜度低.對于獲得的SMST,它有d-1條邊和最多d個不同的簇,其中d是輸入的所有用戶對服務分類中的總簇數.然后從SMST中具有權重值最小的邊開始對其進行切割產生多種可能的聚類[21].為了從多個可能的聚類中獲得擁有簇內相似性最大和簇間相似性最小的最終聚類π*,則必須找到一個一致性質量函數φ(πi),使其滿足公式(5),用于確定具有更好整體質量的最終聚類π*.本文方法雖然不能保證產生的最終聚類是全局最優的,但通過實驗結果表明采用本文中的算法產生的最終聚類較好.
本文方法中的最小成本生成樹是由無向加權圖G獲得的.首先,根據SM獲得服務分類中的簇間和簇內相似性;其次,用無向加權圖G表示輸入的所有用戶對服務分類之間的關系.在圖G中,每個頂點V代表所有用戶對服務分類中的一個簇,每條邊E代表分類中簇之間的關系,每條邊上的權重W代表所有用戶對服務分類中相應簇之間的ECS值.其定義如下:
定義12.G=(E,V,W)為無向加權圖.其中E={(cip,cjk)|(cip,cjk)∈C}為圖G中無向邊集合,V={cip|cip∈Ci}為圖G的頂點集合,W={ECS(cip,cjk)|(cip,cjk)∈C}為V的權重集合.
然后在圖G上運行普里姆(Prim)算法[22],考慮到邊緣頂點之間的差異性和邊緣權重值W具有反比關系,因此在圖G上運行普里姆(Prim)算法時,以圖中的某一頂點為起點,逐步尋找與之相連的各頂點之間擁有高相似度即最大權重值W的邊,通過使用高相似度值表示低差異性成本來構建SMST.最后,基于SMST來尋找最終聚類.本文的一致性聚類算法如算法1.
算法1.一致性聚類算法
輸入:輸入所有用戶對在線服務的分類U
輸出:最終聚類π*
1.G:=(E,V,W); //初始化加權圖
2.V:= ?; //頂點集
3.E:= ?; //邊緣集
4.W:= ?,W?E→; //邊緣權重函數
5.FOR ALLCi∈CDO
6.FOR ALLcip∈CiDO
7.V=V∪cip;
8.FOR ALLcip∈VDO
9. FOR ALLcjk∈V,i≠j,p≠kDO
10.E:=E∪(cip,cjk);
11.W:=W∪(E,ECS(cip,cjk));//邊緣頂點之間的差異性和W值具有反比關系
12.SMST:=Prim′s_Algorithm(G);
13.π*:=find_final_clustering(SMST);
14.RETURNπ*;
本文采用的一致性聚類算法的核心是尋找最終聚類的過程.對于獲得的SMST,從SMST上具有權重值最小的邊開始對其進行切割并產生元聚類,每個元聚類都是樹的連通分量.為了在切割SMST產生的多個聚類中找到最終聚類π*,下面給出了尋找最終聚類過程的算法,如算法2.
算法2.尋找最終聚類
輸入:基于相似度的最小成本生成樹(SMST)
輸出:簇號h
1.初始化空列表:ics,ecs,nics,necs,φ,π;
2.h:= 0; //存儲邊緣的編號
3.REPEAT
4.h:=h+1;
5. 從SMST中刪除最小加權邊
6.πMC是SMST的元聚類,每一個連接組件都是元聚類;
7.πh:=majority_voting(πMC);//多數投票
8.icsh:=ICSC(πh);
9.ecsh:=ECSC(πh);
10.UNTILSMST中有一些邊;
11.nics:=normalize(ics);
12.necs:=normalize(ecs);
13.FORi= 1 tohDO
14.φi:=icsi-ecsi;
15.max_index:=maxi(φ);
16.RETURNπmax_index;
由算法2可知,在SMST中每切割一次SMST,相連接的服務簇之間會變得彼此更相似,使該聚類中的服務在所有用戶對服務分類中共同存在同一類中多次.然后,在聚類上執行多數投票表決[23],統計服務出現在每個類別中的次數,每個在線服務僅分配給最常存在的一個類別,以產生非重疊的最終聚類,提高了聚類的服務信譽級別劃分的合理性.最后,對每次切割產生的聚類運用公式(3)計算其一致性質量函數φ(πi),再根據公式(5)來尋找具有緊湊且良好分離的簇的最終聚類π*.
從具有權重值最小的邊開始對SMST進行切割,每切割一次產生的聚類運用公式(3)對其進行一致性質量函數計算.在進行ICSC(πi)和ECSC(πi)計算時,為了減少在計算過程中產生的大值和小值對聚類結果準確度的影響,我們運用公式(4)對其進行歸一化處理.具體過程如算法3.
算法3.歸一化處理
輸入:值列表list
輸出:規范化列表normalized_list
1.max:=max(list);
2.min:=min(list);
3.normalized_list:=initialize empty list;//初始化空列表
4.FORi:=start_of(list)toend_of(list)DO
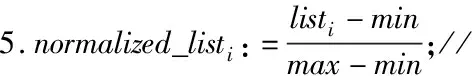
6.RETURNnormalized_list;
本文采用的一致性聚類算法在通過切割SMST尋找最終聚類的過程中需要運行h次.然后在每次計算一致性聚類函數尋找最終聚類的時間復雜度為O(|πi||C|+|πi|2|C|).因此,在運用一致性聚類算法聚合所有用戶對服務的分類得到最終聚類的總體時間復雜度為O(h(|πi||C|+|πi|2|C|)).其中|πi|表示聚類πi中簇的個數,|C|表示所有用戶U對服務集S分類的總簇數,且在大多數情況下|πi|2?|S|,|C|?|S|.
4.4 基于最終聚類的信譽度量
根據用戶對服務的分類與信譽之間的一致性關系獲得最終聚類π*,然后對π*進行信譽計算,進而得到服務集S的信譽等級rz=(rz1,rz2,…,rzn).
首先,根據最終聚類π*計算聚類中每個簇c*q內所有用戶對服務sx評分的平均值avgx,avgx=(r1x+r2x+…+rmx)/m,接著將其簇內所有服務的平均值進行累加再求取平均值作為該簇的信譽值l*q,l*q=(avg1+avg2+…+avgn)/n.然后求出其余每個簇的信譽值,并對聚類π*中所有簇的信譽值L*=(l*1,l*2,…,l*g)進行比較大小,把信譽值最小的簇的簇號賦值為1,即該簇的信譽等級為1.以此類推,聚類中的每個簇都被賦予相應的信譽等級.最后,輸出最終聚類中每個在線服務的信譽等級rz=(rz1,rz2,…,rzn).
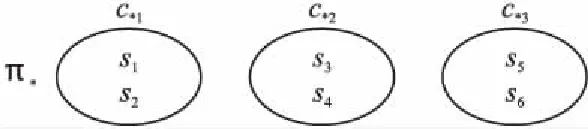
圖2 在線服務的最終聚類
例1中,通過計算得到的最終聚類為π*={c*1,c*2,c*3},如圖2所示.π*中在線服務s1,s2,s3,s4,s5,s6的信譽等級為rz=(1,1,2,2,3,3).因此最終聚類π*的信譽結果最大程度上符合所有用戶對服務的分類C的結果,使最終聚類的服務信譽與所有用戶對服務分類之間的一致性最大.
5 實驗結果與分析
針對以上提出的基于一致性聚類的在線服務信譽度量方法,本部分設計實現了該信譽度量方法并展示了實驗結果,以測試該方法的有效性和效率.
1https://grouplens.org/datasets/movielens/
5.1 實驗環境及數據集
本文方法的開發語言為Java,它提供了對位向量的內置支持以及對位向量的操作.實驗采用Java語言的JDK 1.8軟件開發工具包實現,在一臺配置為Intel Core i5 3.3GHz CPU、8GB RAM的PC機上運行,操作系統為 Windows 10 專業版.
由于本文方法是基于用戶-服務評分值,所以為了更加真實地反應實驗結果,本文實驗采用的數據集為MovieLens1數據集,目前MovieLens數據集被廣泛應用于與服務相關的研究領域.該數據集包含電影1682部,943名用戶以及10萬條左右的用戶對服務的真實評分(1~5),每個用戶參與的電影評分不得少于20部.考慮到用戶不可能參與所有電影的評分,為確保信譽等級劃分的合理性,如果用戶對服務的分類少于兩類,實驗時不將這個用戶對服務的分類加入到聚類中.本文將現在比較流行的3種在線服務信譽度量方法:平均(Average)法、累加(Sum)法以及Beta信譽系統方法[11]作為主要對比方法.實驗驗證了信譽度量結果的合理性和有效性.
5.2 評價標準
本文將基于一致性聚類的在線服務信譽度量問題視為基于用戶對不同服務信譽類別的服務分類的聚類問題,可通過聚類有效性度量來進行最終聚類的質量評估.由于將每個用戶對服務集S的評分視為服務具有的真實類標簽,因此使用最常用的監督評估方法之一:調整后的蘭德指數(Adjusted Rand Index,ARI)[24]即蘭德指數(Rand Index,RI)的改進版本來進行聚類質量評估.本文使用ARI來測量由聚合服務分類得到的最終聚類的信譽結果與所有用戶對服務分類之間的匹配程度,ARI值越大,表明它們之間的匹配程度越大,即聚類結果與用戶對服務的分類結果越吻合,聚類效果越好.因此將具有最大ARI值對應的最終聚類的信譽向量作為服務信譽是合理的.所以,我們用ARI的大小來驗證方法的有效性.具體定義如下:
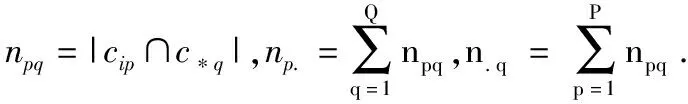
(11)
ARIi取值范圍為[-1,1],值越大意味著聚類結果與用戶對服務的分類結果越匹配,聚類效果越好.當ARIi最大取值為1時,表示用戶ui對服務集S的分類Ci與經過聚合分類得到的最終聚類π*之間完全匹配,聚類效果最好;當ARIi為-1時,表示用戶ui對服務集S的分類Ci與最終聚類π*之間完全獨立,聚類效果最差.
本文中聚合服務分類得到的最終聚類π*與所有用戶U對服務集S的分類C之間的匹配程度用ARI*表示,則:
ARI*=ARI1+ARI2+…+ARIm
(12)
此時,ARI*取值范圍為[-m,m].同樣,ARI*值越大意味著最終聚類的信譽度量結果與所有用戶對服務的分類結果越吻合,聚類效果越佳.
表2 ARI列聯表
Table 2 Abbreviations for ARI

ClassClusterc?1c?2…c?QSumsci1n11n12…n1Qn1·ci2n21n22…n2Qn2·????ciPnP1nP2…nPQnP·Sumsn·1n·2n·Qn··=n
5.3 有效性實驗
觀察公式(12)可知,所有用戶對服務分類與最終聚類的信譽之間的ARI值越大,表示最終聚類的信譽與所有用戶對服務的分類結果匹配度越大,聚類效果越好,得到的信譽度量結果越合理.實驗模擬了在不同用戶數量m(100≤m≤500)和不同服務數量n(10≤n≤50)下,記錄本文方法得到的最終聚類的信譽向量rz、平均法的信譽向量ravg、累加法的信譽向量rsum、Beta法的信譽向量rbeta與所有用戶對服務分類之間的ARI,分別用ARI*,ARIavg,ARIsum,ARIbeta表示,如圖3所示.
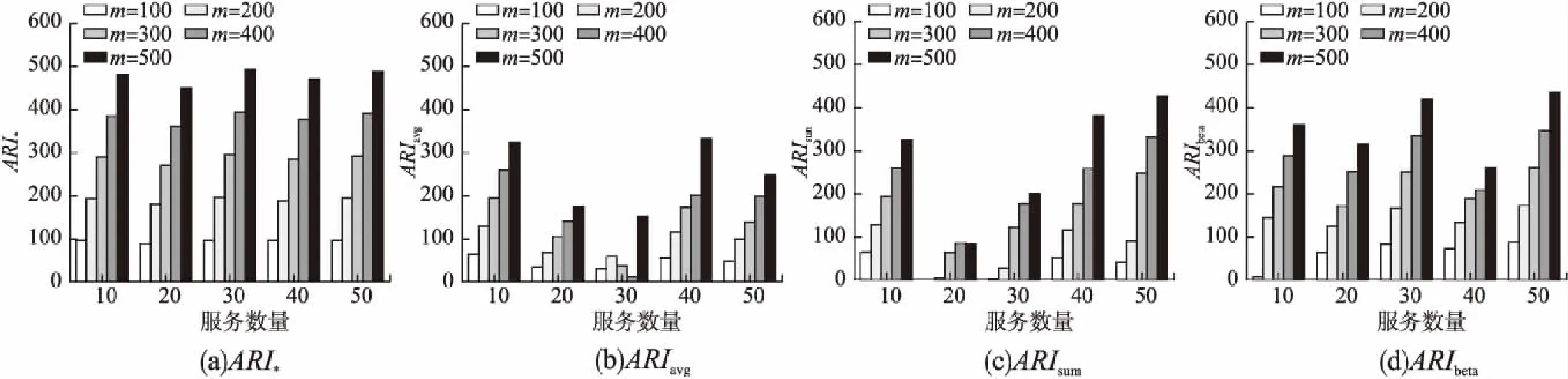
圖3 一致性驗證
由圖3(a)可見,隨著用戶數量和服務數量的增加,ARI*越來越大.說明服務和用戶數量越大,通過本文方法聚合分類得到的聚類結果與用戶對服務分類之間的匹配程度越高,使得到的最終聚類的信譽向量rz與所有用戶對服務分類之間的一致性越大.
由圖3(b)、圖3(c)和圖3(d)可見,ARIavg、ARIsum和ARIbeta并不都隨著用戶數量和服務數量的增加而增加.說明通過平均法、累加法和Beta法得到的信譽度量結果與所有用戶對服務分類之間的匹配度較低,使信譽向量ravg,rsum和rbeta與所有用戶對服務分類之間的不一致性較大.
此外,算法比較記錄了在不同服務數量和用戶樣本規模下ARI*,ARIavg的差值、ARI*,ARIsum的差值以及ARI*,ARIbeta的差值,ARI*-ARIavg如圖4(a)所示,ARI*-ARIsum如圖4(b)所示,ARI*-ARIbeta的如圖4(c)所示.

圖4 信譽度量方法一致性比較
由圖4(a)、圖4(b)和圖4(c)可見,在同樣的服務數量和用戶規模下,ARI*-ARIavg、ARI*-ARIsum和ARI*-ARIbeta的值始終大于0,即ARI*始終大于ARIavg、ARIsum和ARIbeta.雖然隨著服務數量和用戶規模的增大,ARI*與ARIavg、ARIsum、ARIbeta之間的差值在不斷縮小,但始終位于0之上.說明本方法與其他三種方法相比得到最終聚類的信譽向量與所有用戶對服務分類之間的ARI*最大,由此獲得的信譽度量結果與所有用戶對服務分類之間的一致性最大,得到的服務信譽較為合理.
5.4 操縱復雜性驗證
對于隨機選取的某服務,通過對其增加高評分或低評分的用戶數量來進行服務評分操縱,若根據本文方法得到的服務信譽級別無明顯變化,則通過該方法得到的信譽結果抗操縱性較強.為此,隨機選取兩個在線服務s1和s2,用戶數量為500.我們選取不同比例的用戶對服務進行評分操縱,分別為20%,40%,60%,80%,100%.通過分別提高s1的評分至5分和降低s2的評分至1分來觀察這兩個服務的信譽級別變化.Sum法、Average法、Beta法、本文方法分別計算在增加不同操縱用戶比例時在線服務s1和s2的信譽級別,結果分別如圖5(a)和圖5(b)所示.
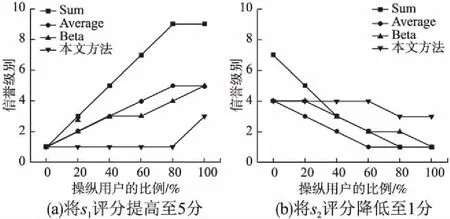
圖5 抗操縱性能驗證
根據圖5(a)所示,隨著操縱用戶比例的增加,Average法、Sum法和Beta法中服務s1的信譽級別在不斷地提高,而根據本文方法得到的服務s1的信譽級別一直保持不變,只有當操縱用戶比例達到100%時,服務s1的信譽級別才提高.說明要對本方法中服務s1的信譽級別進行操縱需要消耗大量成本.
根據圖5(b)所示,隨著操縱評分數量的增加,Average法、Sum法和Beta法中服務s2的信譽級別在不斷地降低,而根據本文方法得到的服務s2的信譽級別在操縱用戶比例達到60%之前一直保持不變;然后當操縱用戶比例達到80%時,服務s2的信譽級別降低;最后隨著操縱用戶比例的增加直到100%時,服務s2的信譽級別穩定不變.由此可以看出,本文方法得到的信譽度量結果具有更好的抗操縱性.
5.5 性能驗證
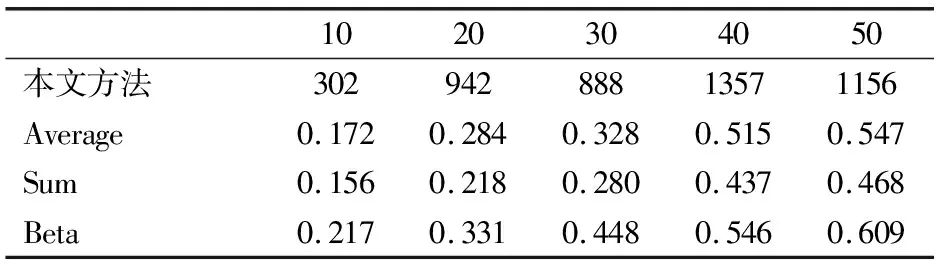
為了測試方法的運行效率,實驗模擬了m(100≤m≤500)個用戶和n(10≤n≤50)個在線服務分別在不同用戶數量和服務樣本規模下進行信譽度量的實驗,并且記錄了每次實驗的運行時間,如圖6所示.此外,還比較了本方法、Average法、Sum法、Beta法在用戶數量為500和服務數量為10~50的規模下的運行時間,如表3所示.
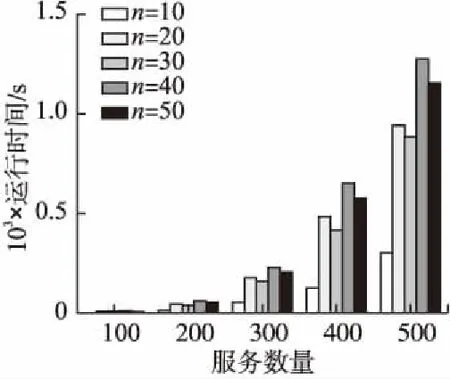
圖6 不同用戶數量和服務規模下的運行時間
觀察圖6可知,方法的運行時間會隨著用戶數量的增加而不斷增加,原因是在服務數量一定時,計算用戶對服務分類中的ECS和ICS的次數會隨用戶數量的增加而增加,導致根據公式(3)和公式(4)計算得到最終聚類的信譽度量結果的運行時間增加.但是在用戶數量一定時,運行時間并不隨服務數量的增加而增加,是因為在計算簇間和簇內相似性時,運行時間只與每對服務出現在相同簇中的次數有關,與服務數量無關.所以本文方法可通過控制用戶數量來有效地提升信譽度量的效率.
表3 不同服務數量在不同方法下的運行時間(單位:秒)
Table 3 Runtime of different services in different methods(unit:seconds)
1020304050本文方法30294288813571156Average0.1720.2840.3280.5150.547Sum0.1560.2180.2800.4370.468Beta0.2170.3310.4480.5460.609
從表3可知,相對Average法、Sum法和Beta法的運行時間而言,本文方法雖然運行時間較長,但通過操縱該方法獲得在線服務信譽度量結果所需的時間要比其他3種方法更長.因此,對本文方法獲得的信譽度量結果進行操縱的難度要遠高于其他三種方法.
6 結 論
本文提出一種基于一致性聚類的在線服務信譽度量方法,以解決由于未考慮到用戶對服務的分類結果與信譽之間的一致性關系導致的最終聚類的服務信譽級別劃分不合理的問題.方法在切割基于相似性的最小成本生成樹時,會產生多種可能的聚類.然后用一致性質量函數來尋找具有更好整體質量的最終聚類,使其簇內的相似性最大,簇間的差異性最大,聚類效果較好.最后基于得到的最終聚類計算其服務信譽,使用戶對服務分類與信譽結果之間的一致性達到最大,提供了一種研究在線服務信譽度量方法的新思路.同時,實驗也驗證了本文方法在進行服務分類聚合時具有較高的的有效性.
本文方法在進行聚類過程中只考慮了用戶對在線服務的評分,未綜合考慮其他因素在聚類過程中對在線服務信譽的影響.因此,下一步將從該方面研究一種使信譽等級劃分更準確的在線服務信譽度量方法.
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
