基于元路徑異構網絡嵌入的姓名實體消歧方法
2020-07-14 04:57:48王建霞張玉璇許云峰
河北科技大學學報 2020年3期
王建霞 張玉璇 許云峰


摘 要:為了解決大型學術數據庫中重名作者的歧義消解問題,提出了基于元路徑異構網絡嵌入的姓名實體消歧模型。使用大型在線學術搜索系統DBLP上的公開數據集,首先抽取學術出版物的作者信息、標題和會議期刊名稱等特征屬性,再利用word2vec模型工具生成的特征屬性詞嵌入輸入到GRU網絡中進行訓練,構造出一個PHNet矩陣網絡進行隨機游走操作,從而捕捉不同類型節點之間的關系,最后進行相似節點的劃分,完成姓名消歧工作。實驗結果顯示,新方法的精確度為0.865,召回率為0.792,F1值為0.815。基于元路徑的異構網絡嵌入模型的精確度、召回率等指標都優于對比模型。因此,所提出的模型在提高大型學術數據庫的消歧精準度方面具有良好的應用前景。
關鍵詞:自然語言處理;計算機神經網絡;實體消歧;網絡嵌入;異構網絡
中圖分類號:TP311.13 文獻標識碼:A
doi:10.7535/hbkd.2020yx03005
Disambiguation method of name entities embedded in meta-path
heterogeneous networks
WANG Jianxia, ZHANG Yuxuan, XU Yunfeng
(School of Information Science and Engineering, Hebei University of Science and Technology, Shijiazhuang, Hebei 050018, China)
Abstract:
In order to solve the problem of disambiguation of duplicate authors in large academic databases, a name entity disambiguation model based on meta-path heterogeneous network was proposed. Based on the public data of the large online academic search system DBLP, the author information, title, name of conference journal and other characteristic attributes of academic publications were extracted first. Then the characteristic attribute words generated by the word2vec model tool were embedded into the GRU network for training, so that a PHNet matrix network for random walk operation was constructed to capture the relationship between different types of nodes and finally similar nodes were divided to complete the name disambiguation. The experimental results show that the accuracy of the method is 0.865, the recall rate is 0.792, and the F1 value is 0.815.The meta-path-based heterogeneous network embedding model is superior to the comparison model in terms of accuracy and recall rate. Therefore, the proposed model has a good application prospect in improving the accuracy of disambiguation of large academic databases.
Keywords:natural language processing; computer neural network; entity disambiguation; network embedding heterogeneous network
現今,人們檢索學術論文主要依賴學術搜索引擎,如Google Scholar、百度學術、DBLP(DataBase systems and logic programming)等。這些大型學術數據庫共同面臨的一個具有挑戰性的問題是作者姓名的歧義消解,即通過作者的姓名來準確識別現實世界中的人。這一問題的解決對于DBLP這樣的大型數據庫圖書館尤為重要。DBLP是Schloss Dagstuhl-Leibniz信息學中心和特里爾大學的聯合服務機構。Schloss Dagstuhl是一家“gemeinnutzige GmbH”,是被德國法律所允許的一個非盈利慈善組織,是為了增進世界計算機科學界的學術信息交融而成立的。Schloss Dagstuhl主要進行數字方法和論文書目元數據處理等研究。DBLP在處理計算機科學數據的同時,還提供計算機學術論文所涉及到的論文作者的相關屬性。除了公共領域所提供的論文數據外,DBLP不會向任意第三方公開論文的私密數據,并且DBLP用戶的行為也不會被系統跟蹤,與此同時,DBLP不會使用用戶的任何數據進行廣告宣傳。總之,DBLP就是一個僅僅提供計算機學術界科學會議和期刊論文出版記錄的大型學術數據庫。
本文針對DBLP數據庫的重名作者消歧問題進行以下研究。
2.1 論文信息預處理
本文使用的DBLP數據信息包括論文的標題、作者、出版物名稱、年份和id編號等信息。由于數據信息中存在噪音數據,所以首先需要進行預處理。預處理過程依次對論文信息進行去噪處理,包括去掉特殊字符串,去掉標點符號及特殊符號,去掉多余空格和換行符,去掉停用詞等,然后提取需要的信息歸納到一起。
以歧義人名Bo Liu(見圖1)為例,該人名下的出版物論文為124篇,根據論文標題的內容可知,Bo Liu名下有研究神經網絡的論文,也有研究基于圖挖掘算法等研究方向的論文,再依據organization可粗略看出,有從屬于清華大學、北京科技大學和暨南大學等的Bo Liu,甚至很多Bo Liu并未顯示其所屬研究機構。這樣有歧義的人名,本試驗一共使用了109個,其中出版物數量最多的是Wen Gao數據集,其包含484條出版記錄。
在預處理工作中,將109個XML格式的生數據集處理為5個TXT文件,分別為paper_author.txt,paper_author1.txt,paper_conf.txt,paper_title.txt和paper_word.txt。圖2為paper_title.txt部分文本內容,其中包含內容為出版物論文id以及論文標題,其中論文標題經過處理,將其統一使用小寫字母表示,并且去掉了標題中的多種符號。對于論文標題的處理有助于后續生成paper_word.txt文檔,該文檔保留的內容如圖3所示,即是論文id以及去掉預設的諸多停止詞(例如,at,based,in等)。每一詞都另起一行,與論文id成行。另外3個文檔內容不再贅述,都是與出版物論文id的結合。
2.2 訓練基于GRU的編碼器學習深層語義表示
該部分進行的是基于GRU的深度表示學習,應用gensim庫中的word2vec模型生成出版物標題的詞嵌入,訓練單詞向量時維數=100。嵌入向量的維數定義batch大小為128,嵌入大小為64,學習率為0.001。
GRU即Gated Recurrent Unit,是LSTM網絡的一種的變體。試驗發現使用GRU可以使訓練成果得到提升。
更新門和重置門是GRU模型中僅有的2個門,具體結構如圖4所示。
圖4中的更新門用zt表示,重置門用rt表示。其中用于控制之前時刻的狀態信息被帶入到當前狀態中的程度是更新門的任務,這個值越大,代表前一時刻帶入的狀態信息越多。重置門的作用是調控之前狀態有多少信息被寫入到當前的候選集t,重置門的值越小,代表之前狀態寫入的信息越少。
根據圖4的GRU模型圖,網絡的前向傳播公式如式(1)—式(3)所示。
rt=σ(Wr·[ht-1,xt]),(1)
zt=σ(Wz·[ht-1,xt]),(2)
t=tanh(W·[rt*ht-1,xt]) ?? 。??????????????????????? (3)
先利用重置門控rt來獲得“重置”之后的數據ht-1·rt,再與輸入xt進行拼接,之后再經過一個tanh激活函數來處理數據,將其放縮到-1~1的范圍內。此時的包含了輸入數據xt。式(3)對t的操作與LSTM的選擇記憶階段類似,可以理解為記憶了當前時刻的狀態。
在更新記憶階段,使用了式(2)得到的更新門控zt進行遺忘和記憶2個操作。更新表達式見式(4)。
ht=(1-zt)*ht-1+zt*t。(4)
式中:zt(門控信號)的區域是0~1,若記憶下的數據越多,則門控信號越逼近1,遺忘的數據越多則越逼近0;(1-zt)*ht-1是對原本隱藏狀態進行的選擇性遺忘;(1-zt)作為遺忘門,用來遺忘ht-1中一些不緊要的內容;zt*t是對包含當前節點信息的t進行選擇性“記憶”。
yt=σ(Wo·ht)。??? (5)
需要說明的是,[]用來代表有2個向量相連,*是Hadamard Product,代表操作矩陣中對應的元素相乘,此時要求2個相乘矩陣是同型的,+表示矩陣加法操作的進行,σ為sigmoid函數,利用sigmoid函數能夠將數據處理為0~1范圍內的數值,從而來充當門控信號。激活函數tanh能夠幫助調節流經網絡的值,而且tanh函數的輸出值一直在區間(-1,1)內。
在輸出層中,計算loss使用的是softmax的交叉熵(labels和logits)+平均值。
2.3 構造一個PHNet并生成隨機游走
使用基于元路徑的隨機游走操作來捕捉不同節點間的關系,即通過論文標題、論文作者、論文發表期刊,構建PHNet(異構網絡)矩陣。本文所構建的異構網絡中的節點類型只有論文一種,關系類型為3種(合著作者、共同標題、共同發表期刊)。在一個PHNet中,2個論文節點之間可以通過多個無向關系進行連接,由這些無向關系連接的節點序列可以看作是從論文到論文的表述。受網絡嵌入DeepWalk和Metapath2Vec方法的啟發,利用隨機游走策略和跳躍圖模型學習網絡節點表示。本文提出了一種元路徑和關系權值引導的隨機游走策略,用于加權異構網絡上的采樣路徑。
元路徑通過異構關系捕獲節點間的相關性,在異構網絡嵌入中得到了廣泛的應用。本文在采樣路徑上考慮了PHNet中關系的權值,從直觀上看,兩個節點之間的關系值越大,它們之間的相似性就越大。在每一步游走中,當游走到一個鄰居時,連接當前節點到鄰居節點的關系值越高,就越有可能對該鄰居進行采樣。具體來說,本文依次選擇PHNet中的一個論文節點作為路徑的第一個節點,生成一個長度為100的元路徑,然后選擇最后一個節點作為另一條元路徑的第一個節點。每個隨機遞歸采樣網絡中的節點,都會生成一條由論文節點引導的長路徑,直到滿足固定長度,最后生成的結果輸入到WMRW.txt文檔中,如圖5所示。
2.4 基于元路徑異構網絡嵌入
當前進行網絡研究應用較多的是同構網絡。若要把基于同構信息網絡的方法用在異構信息網絡中,需要將異構網絡映射為同構網絡,或者忽略節點間的連接信息,只是上述這2種方法都將會產生信息丟失的情況。因此,直接在異構信息網絡上進行數據挖掘的方法是非常必要的。由于在異構信息網絡中節點的連接是通過不同的語義意義,從而提出最好充分利用異構信息網絡的網絡模式期盼。網絡模式即是了解信息網絡的元結構,能夠對網絡的檢索和數據挖掘進行指導,對于分析和理解網絡中對象和關系的語義意義大有幫助。簡單而言,就是一種基于元路徑的方法。元路徑就是在網絡模式上加以定義的路徑,代表了在2個對象類型之間的關系,同時能夠定義實體之間新的或現存的關系。
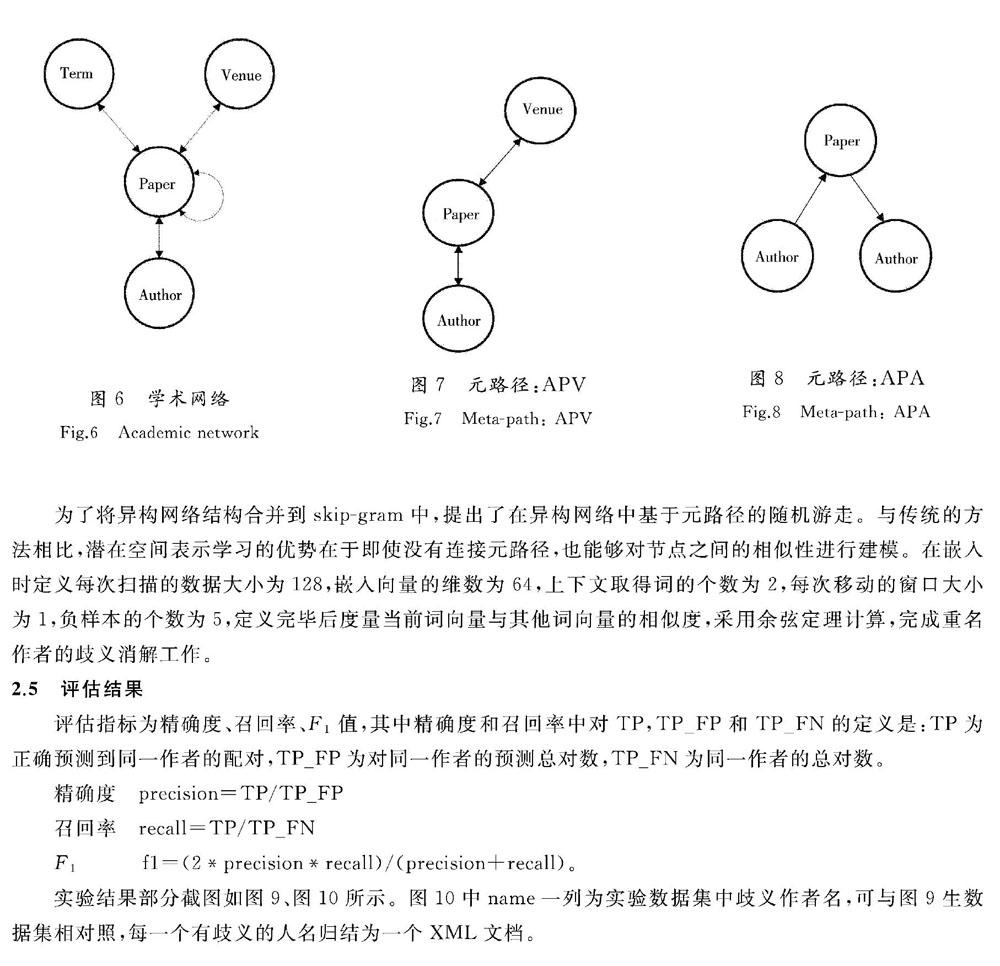
現實世界中普遍存在著異構信息網絡,本文選用的DBLP數據集是非常經典的異構網絡,包含了4類實體:Paper,Venue,Author,Term。對于每篇論文,它都有一組4類實體的連接。此網絡也包含了一些論文的信息,即論文之間有論文引用的論文集合。圖6—圖8為學術網絡與元路徑示意圖。
為了將異構網絡結構合并到skip-gram中,提出了在異構網絡中基于元路徑的隨機游走。與傳統的方法相比,潛在空間表示學習的優勢在于即使沒有連接元路徑,也能夠對節點之間的相似性進行建模。在嵌入時定義每次掃描的數據大小為128,嵌入向量的維數為64,上下文取得詞的個數為2,每次移動的窗口大小為1,負樣本的個數為5,定義完畢后度量當前詞向量與其他詞向量的相似度,采用余弦定理計算,完成重名作者的歧義消解工作。
2.5 評估結果
評估指標為精確度、召回率、F1值,其中精確度和召回率中對TP,TP_FP和TP_FN的定義是:TP為正確預測到同一作者的配對,TP_FP為對同一作者的預測總對數,TP_FN為同一作者的總對數。
精確度 precision=TP/TP_FP
召回率 recall=TP/TP_FN
F1 f1=(2*precision*recall)/(precision+recall)。
實驗結果部分截圖如圖9、圖10所示。圖10中name一列為實驗數據集中歧義作者名,可與圖9生數據集相對照,每一個有歧義的人名歸結為一個XML文檔。
3 實驗結果分析
本文使用DBLP數據集進行實驗,有歧義的人名為101個,論文出版物有7 585篇,其中包含的節點特征有作者id,作者名以及出版物的詳細信息。詳細信息包含:論文標題、出版年份、作者(論文所有的作者)、出版期刊、出版物id、作者所屬單位。因較多人的所屬單位信息為空白,所以該特征屬性在本次消歧任務中不作為側重點。本次實驗整理數據側重于利用論文標題、作者集合、出版物期刊名稱、出版年份和id編號等特征屬性進行消歧操作。
為了驗證本文所提出方法的消歧性能,將其與另外4種方法進行比較,這4種方法包括:DeepWalk,LINE,Node2Vec和PTE,都是目前最先進的頂點嵌入方法。為了公平起見,所有這些方法都使用相同的數據來實現姓名消歧。
DeepWalk:DeepWalk是近期所提出的一種網絡嵌入方法。在給定論文合作關系的情況下用來捕獲與關聯文檔集合中的一對人員之間的協作,并采用均勻隨機游走的方法來獲取其鄰域的上下文信息進行文檔嵌入。
LINE:LINE不再采用隨機游走的方法,它在圖上定義一階相似度和二階相似度,對節點的信息進行了補充,從而得到更豐富的節點嵌入。
Node2Vec:和DeepWalk近似,Node2Vec為實現文檔嵌入設計了一個有偏差的隨機游走過程。
PTE:預測性文本嵌入框架的目標是捕獲詞-詞、詞-文檔和詞標簽之間的關系。可是,該種方式不能捕捉文檔間的連接信息。
表1顯示了本論文所提出的方法與對比方法在處理多個不同人名姓名歧義消除方面的性能(表1用于DBLP數據集)。在表1中,列1為需要消歧的作者姓名,第3列—第6列為各種方法的F1值。F1值表示各種方法給定姓名數據集下的消歧性能。最后一列顯示了本文所提出的方法相較于對比方法的改進水平。
表1表明,本文方法相較于對比方法的總體改進比較大。PTE的表現很差,因為它沒有將相關的結構信息整合到實驗中。DeepWalk的方法忽略了邊緣權值,這一點恰恰在異構學術網絡中是非常重要的。這幾種基于嵌入的對比方法都不能利用多個網絡信息來處理消歧任務,本論文的模型利用了這一點,提出了基于元路徑異構網絡嵌入實現姓名消歧的方法,這可能是該方法優于現有的基于網絡嵌入方法的一個重要原因。
4 結 語
筆者提出了一個有效解決作者姓名消歧問題的框架。該框架對DBLP數據集中有待消解歧義的作者姓名的數據集進行了預處理操作,利用word2vec模型進行嵌入,再輸入到GRU網絡中進行訓練,根據節點間的關系構造了PHNET網絡,最后基于元路徑異構網絡嵌入實現姓名消歧。該方法所提出的表示學習方案比其他現有的網絡嵌入方法能更有效地將屬于同名作者的文檔進行消歧處理。實驗結果驗證了該方法的可行性和有效性。
本研究雖實現了預期目標,但是在組合不同類型的特征屬性(如利用文本信息的語義信息和離散特征)來學習有待消歧作者論文的有效表示方面仍有進步空間。在未來的工作中,將嘗試把此方法應用于分布式計算系統,進一步提高大型學術數據庫的消歧速度和效果。
參考文獻/References:
[1] DENG H, KING I, LYU M R. Formal models for expert finding on DBLP bibliography data[C]//Eighth IEEE International Conference on Data Mining. [S.l.]: [s.n.], 2008: 163-172.
[2] HUANG Zhixing, YAN Yan, QIU Yuhui, et al. Exploring emergent semantic communities from DBLP bibliography database[C]//International Conference on Advances in Social Network Analysis and Mining. [S.l.]: [s.n.], 2009: 219-224.
[3] FRANCESCHET M. Collaboration in computer science: A network science approach[J]. Journal of the American Society for Information Science and Technology, 2011, 62(10): 1992-2012.
[4] KIM J, KIM H, DIESNER J. The impact of name ambiguity on properties of coauthorship networks[J]. Journal of Information Science Theory and Practice, 2014, 2(2): 6-15.
[5] CAVERO J M, VELA B, CACERES P. Computer science research: More production, less productivity[J]. Scientometrics, 2014, 98(3): 2103-2111.
[6] SHI Quan, XU Bo, XU Xiaomin, et al. Diversity of social ties in scientific collaboration networks[J]. Physica A: Statistical Mechanics and Its Applications, 2011, 390(23/24): 4627-4635.
[7] REITZ F, HOFFMANN O. Learning from the past: An analysis of person name corrections in the DBLP collection and social network properties of affected entities[J]. Social Network Analysis and Mining, 2013,6: 427-453.
[8] 余傳明,林奧琛,鐘韻辭,等.基于網絡表示學習的科研合作推薦研究[J]. 情報學報,2019,38(5):500-511.
YU Chuanming, LIN Aochen, ZHONG Yunci, et al. Research of author name disambiguation based on network embedding[J]. Journal of the China Society for Scientific and Technical Information, 2019, 38(5): 500-511.
[9] GARFIELD E. British quest for uniqueness versus American egocentrism[J]. Nature, 1969, 223(5207): 763-763.
[10]LEY M. DBLP: Some lessons learned[J]. Proceedings of the VLDB Endowment, 2009, 2(2): 1493-1500.
[11]KIM J. Evaluating author name disambiguation for digital libraries: A case of DBLP[J]. Scientometrics, 2018, 116(3): 1867-1886.
[12]HAZIMEH H, YOUNESS I, MAKKI J, et al. Leveraging co-authorship and biographical information for author ambiguity resolution in DBLP[C]/Advanced Information Networking and Applications (AINA). [S.l.]: [s.n.], 2016: 1080-1084.
[13]HAN H, GILES L, ZHA H, et al. Two supervised learning approaches for name disambiguation in author citations[C]//Proceedings of the 2004 Joint ACM/IEEE Conference on Digital Libraries. [S.l.]: [s.n.], 2004: 296-305.
[14]GILES C L, ZHA H, HAN H. Name disambiguation in author citations using a K-way spectral clustering method[C]//Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL'05). [S.l.]:[s.n.], 2005: 334-343.
[15]MALIN B. Unsupervised name disambiguation via social network similarity[C]//Workshop on Link Analysis, Counterterrorism, and Security[S.l.]: [s.n.], 2005:93-102.
[16]ZHANG Baichuan, AL-HASAN M. Name disambiguation in anonymized graphs using network embedding[C]//Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. [S.l.]:[s.n.], 2017: 1239-1248.
[17]PERZZI B, AL-RFOU R, SKIENA S. Deepwalk: Online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]:[s.n.], 2014: 701-710.
[18]TANG Jian, QU Meng, WANG Mingzhe, et al. Line: Large-scale information network embedding[C]//Proceedings of the 24th International Conference on World Wide Web. [S.l.]: International World Wide Web Conferences Steering Committee, 2015: 1067-1077.
[19]TANG Jian, QU Meng, MEI Qiaozhu. PTE: Predictive text embedding through large-scale heterogeneous text networks[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]:[s.n.], 2015: 1165-1174.
[20]GROVER A, LESKOVEC J. Node2vec: Scalable feature learning for networks[J]. Knowledge Discovery and Data Mining, 2016: 855-864.
[21]PHAM T H, PHAM X K, NGUYEN T A, et al. NNVLP: A neural network-based Vietnamese language processing toolkit[C]//International Joint Conference on Natural Language Processing. [S.l.]:[s.n.], 2017: 37-40.
[22]WU Fangzhao, LIU Junxin, WU Chuhan, et al. Neural Chinese named entity recognition via CNN-LSTM-CRF and joint training with word segmentation[J]. The World Wide Web Conference, 2019: 3342-3348.
[23]甄然,于佳興,趙國花,等.基于卷積神經網絡的無人機識別方法仿真研究[J]. 河北科技大學學報, 2019, 40(5): 397-403.
ZHEN Ran, YU Jiaxing, ZHAO Guohua, et al. Simulation research on UAV recognition method based on convolutional neural network[J]. Journal of Hebei University of Science and Technology, 2019, 40(5): 397-403.
[24]紀志強,魏明,吳啟蒙,等.基于遞歸神經網絡的TVS電磁脈沖響應建模[J]. 河北科技大學學報, 2015, 36(2): 157-162.
JI Zhiqiang, WEI Ming, WU Qimeng, et al. EMP response modeling of TVS based on the recurrent neural network[J]. Journal of Hebei University of Science and Technology, 2015,36(2): 157-162.
收稿日期:2020-03-25;修回日期:2020-05-25;責任編輯:馮 民
基金項目:中國留學基金委地方合作項目(201808130283);中國教育部人工智能協同育人項目(201801003011);河北科技大學校立課題(82/1182108);河北科技大學霧霾與空氣污染防治科研項目(82/1182169);河北省科技支撐計劃項目(17210104D, 18210109D);河北省高等學校科學技術研究項目(ZD2015099);河北省高層次人才資助項目(A2016002015)
第一作者簡介:王建霞(1970—),女,河北臨城人,教授,碩士,主要從事網絡與數據庫、圖像處理方面的研究。
通訊作者:許云峰副教授。E-mail:hbkd_xyf@hebust.edu.cn
王建霞,張玉璇,許云峰.
基于元路徑異構網絡嵌入的姓名實體消歧方法
[J].河北科技大學學報,2020,41(3):233-241.
WANG Jianxia, ZHANG Yuxuan, XU Yunfeng.
Disambiguation method of name entities embedded in meta-path heterogeneous networks
[J].Journal of Hebei University of Science and Technology,2020,41(3):233-241.
