人工智能中數據集的分類、獲取與處理
2020-07-18 16:18:48高宏旭曹大軍
科學大眾 2020年5期
高宏旭 曹大軍
摘 要:文章重點探討了人工智能中數據集的分類、獲取與處理方法。從人工智能的概念、本質與要素出發,深入闡述了數據集對人工智能的重要意義,按照研究領域對數據集進行分類,以圖像數據集為例討論數據集的獲取方法,對若干典型圖形數據集進行分析、總結,進而闡述數據集處理方法。其中,詳細介紹了數據標記方法,以期為即將從事人工智能研究的人員提供方法指引與技術方案。
關鍵詞:人工智能;數據集;分類;處理
人工智能(Artificial Intelligence,AI)是研究、開發能夠模擬和擴展人類智能的理論、方法、技術及應用系統的一門全新技術科學[1]。AI的本質是對人類智能的模擬與擴展,賦予機器人類的思考能力。自20世紀50年代開始,AI依次經歷了符號處理、字符號法、統計學法、集成方法等發展階段,已經從單一智能系統模擬進入到混合智能研究階段。AI的研究領域包括:語音識別、圖像識別、自然語言處理、專家系統、仿生設備等,其理論和技術日益成熟,應用范圍不斷擴大。未來,AI帶來的科技產品將會是人類智慧的“容器”。
從技術方案看,AI對給定數據集進行訓練,形成研究對象的模型輸出。算法、算力、數據是AI的三大要素[2]。(1)算法是核心,是指導數據進行學習訓練并形成模型輸出的方法,本質是程序化的機器學習方法,可分為監督式學習算法和非監督式學習算法;目前,很多學習算法已經開源,訓練其中的關鍵參數即可獲得研究對象的AI學習算法。(2)算力為動力,包含GPU在內的各種高速計算機、服務器等設備,或者某些通用大數據平臺,成為AI算力的首選。(3)數據是燃料,其數量和質量直接影響AI算法的最終訓練結果。只有有針對性地選擇適合相關研究領域的數據,形成有效的訓練數據集合,才能達到理想的訓練結果。
數據集對人工智能的實現具有重要意義,為人工智能學習算法訓練提供數據采集、標注等服務,已經成為近年來人工智能研究的熱點之一。本文著重介紹人工智能中數據集的分類、獲取與處理方法,為工程應用提供技術指導。
1 ? ?數據集的分類與獲取
根據研究領域的不同,AI涉及的數據集(見圖1)大致可以分為3類:語音數據集、圖像數據集、文字數據集[3]。其中,面向智能語音處理領域的數據集合統稱為語音數據集,面向圖像識別領域的數據集合統稱為圖像數據集,面向文字識別等領域所選擇的為文字數據集。
在實際研究中,對于某類數據集可以依據研究場景進行細化分解。例如,圖像數據集可以細分為場景數據集、行人檢測數據集、人臉圖像數據集、交通工具數據集等[4]。圖像數據集可以自行通過傳感設備采集相關信息后構建,或者通過網絡搜索工具下載后構建,亦可以從已建立的各類數據庫獲取部分信息后構建且更為便利。下面介紹幾種常見的圖像數據集。
1.1 ?場景數據集
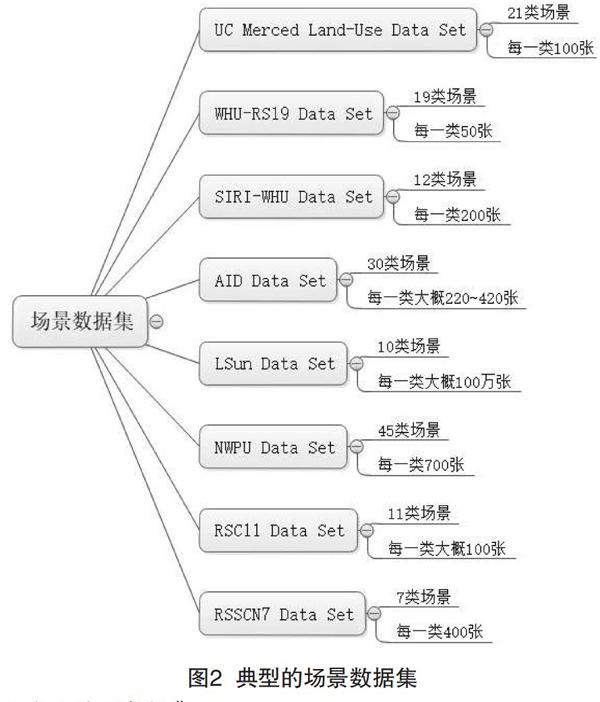
(1)比較出色的場景數據集是LSUN Dataset,由加州大學伯克利分校于2015年發布,提供10個場景類別和20個類別,共計約100萬張標記圖像,以閃電式內存映射數據庫(Lightning Memory-Mapped Database,LMDB)格式存儲,涵蓋家居、教室、會議室等多種場景。
(2)比較優秀的場景數據集是UC Merced Land-Use Dataset,由UC Merced計算機視覺實驗室于2010年發布。UC Merced Land-Use Dataset包含21類場景,每一類場景含100張圖像數據。
此外,WHU-RS19 Dataset提供19類場景的圖像數據信息,每一類約含50張圖像;SIRI-WHU Dataset包含12類場景,每一類場景含200張圖像;RSC11 Dataset包含11類場景,每一類場景含100張圖像;AID Dataset包含30類場景,每一類場景包含220~420張圖像數據。不同場景數據集提供的圖像資源比較如圖2所示。
1.2 ?行人檢測數據集
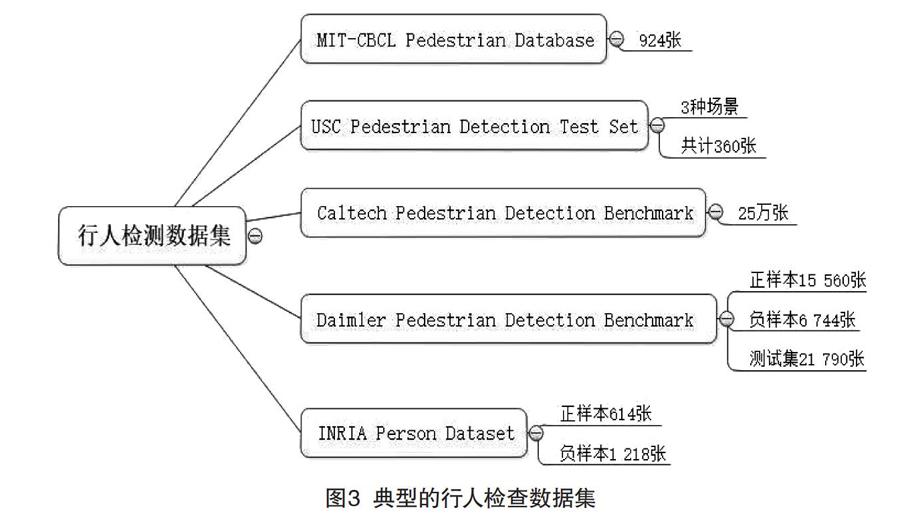
行人檢測數據集比較典型的有:加州理工學院(California Institute of Technology)的Caltech行人數據庫、麻省理工學院(Massachusetts Institute of Technology)的MIT行人數據庫、南加利福尼亞大學(University of Southern California)的USC行人數據庫、戴姆勒行人檢測標準數據庫、INRIA行人數據庫[4-5]等,其中包含的行人數據集情況如圖3所示。
(1)Caltech行人數據庫,是目前規模較大的行人數據庫,采用車載攝像頭拍攝,以30幀/秒的速度記錄了約10 h左右的行人視頻,圖像分辨率為640×480。其中,對137 min視頻約250 000幀圖像進行了標注,使用了350 000個矩形框,標注了2 300個行人。
(2)MIT行人數據庫:包含924張行人圖片,所有拍攝圖片只含正面和背面兩個視角,每張圖片中行人肩到腳的距離約80像素,圖片分辨率為64*128;無負樣本,未區分訓練集和測試集。
(3)USC行人數據庫:包含根據拍攝角度和行人重疊與否劃分的3組數據集,分別命名為USC-A,USC-B和USC-C。其中,USC-A包含來自網絡的205張圖片,記錄了313個正面或背面視角拍攝的站立行人,行人間相互無遮擋;USC-B包含來自CAVIAR視頻庫的54張圖片,記錄了271個多角度行人,行人間存在相互遮擋;USC-C包含來自網絡的100張圖片,記錄了232個多角度行人,行人間相互無遮擋。該數據庫采用可擴展標記語言(eXtensible Markup Language,XML)存儲圖片標注信息。
(4)INRIA行人數據庫,是目前應用最廣泛的一類靜態行人數據庫,分為訓練集、測試集兩部分。其中,訓練集包含正樣本614張,記錄了2 416個站立行人,負樣本1 218張;測試集包含正樣本288張,記錄了1 126個站立行人,負樣本453張。圖片主要來源于網絡,可用OpenCV讀取和顯示。
1.3 ?人臉數據集
比較典型的有哥倫比亞大學公眾人物臉部數據庫、香港中文大學的大型人臉識別數據集、Multi-Task Facial Landmark (MTFL) Dataset,BioID Face Database - FaceDB,Labeled Faces in the Wild Home (LFW) Dataset等[6],如圖4所示。其中,MTFL Dataset從互聯網上收集了12 995張人臉照片;BioID Face Database-FaceDB包含1 521張人臉灰度照片;LFW Dataset包含超過13 000張多角度人臉圖像。3種數據集的基礎數據均來源于網絡。
為促進人臉識別算法的研究和實用化,美國國防部發起一項人臉識別技術(Face Recognition Technology,FERET)項目,通過采集1 000多位不同年齡志愿者的不同表情、光照、姿態的照片,構建了包含10 000多張面部圖像照片的通用人臉數據庫,并開發了通用的人臉識別測試標準,以提升人臉識別的精度。
2 ? ?數據集的處理方法
AI數據處理又稱為AI基礎數據服務,包括:數據采集、數據清洗、信息抽取、數據標注。數據采集即獲取數據集;數據清洗(Data Cleaning,DC)是指對數據重新審查和校驗的過程,包括檢查數據一致性、處理無效值和缺失值等[7];信息抽取(Information Extraction,IE)是從數據集中提取有用信息并按照一定結構形成規范化表征的過程,例如變為信息表格;數據標注(Data Annotation,DA)是借助標記工具對數據集中的某些數據進行標記處理的一種行為,包括圖像標注、語音標注、文本標注、視頻標注等種類,標記的基本形式有標注畫框、3D畫框、文本轉錄、圖像打點、目標物體輪廓線等。數據標注是影響算法訓練的重要環節,成為近年來AI研究的熱點之一。目前,對數據集中數據進行標注處理的方法有兩種:
(1)通過網絡購買標注服務,由第三方平臺按要求進行數據標注;
(2)自行采用標注工具對數據集進行處理,打上合適的標簽。
目前,比較常用的圖形圖像標注工具為LabelImg[8]。該工具為Python語言編寫,在github相關網站下可以找到該工具https://github.com/tzutalin/labelImg,其產生的注釋以PASCAL VOC格式存儲的XML文件,被ImageNet數據集采用;LabelImg亦支持YOLO格式存儲。
另一種圖形圖像標注工具Vatic(Video Annotation Tool from Irvine,California)源自MIT的一個研究項目,支持輸入視頻自動抽取成粒度合適的標注任務,并在流程上支持接入亞馬遜的眾包平臺Mechanical Turk。Vatic具有很多實用特性:第一,簡潔的GUI界面,支持多種快捷鍵操作;第二,基于Opencv的Tracking進行抽樣標注,減少工作量。具體使用時,設定要標注的物體名稱,比如:人臉、行人、車等,然后指派任務給眾包平臺。
Yolo_mark工具對圖像標注,主要應用于使用YOLO V3或V2的算法。此外,還有微軟發布的VOTT圖像標注工具等。
3 ? ?結語
本文主要討論了AI的數據集分類、獲取及處理方法。隨著人工智能的深入發展,算法及算力已不是制約人工智能發展的主要因素,數據集的收集、處理同樣重要,為了快速促進訓練模型的形成,研究者可以考慮使用開源的數據集或者對數據進行自我采集,并通過圖像標注工具,將采集的數據轉換為合格的數據集,便于后續工作的進一步開展。
[參考文獻]
[1]周芃池.人工智能在生物醫療中的發展應用及前景思考[J].低碳世界,2018(2):320-321.
[2]上海艾瑞市場咨詢有限公司.中國人工智能基礎數據服務行業白皮書(2019年)[R].上海:上海艾瑞市場咨詢有限公司,2019:268-310.
[3]周旺,張晨麟,吳建鑫.一種基于Hartigan-Wong和Lloyd的定性平衡聚類算法[J].山東大學學報(工學版),2016(5):37-44.
[4]屈鑒銘.智能視頻監控中的運動目標檢測與跟蹤技術研究[D].西安:西安電子科技大學,2015.
[5]張金慧.基于多尺度方法的行人檢測與跟蹤算法研究[D].成都:西南科技大學,2018.
[6]張翠平,蘇光大.人臉識別技術綜述[J].中國圖象圖形學報(A輯),2000(11):885-894.
[7]陳畇燚.校園網絡行為與流量預測分析研究[D].長沙:湖南大學,2014.
[8]顧廣華,韓晰瑛,陳春霞,等.圖像場景語義分類研究進展綜述[J].系統工程與電子技術,2016(4):936-948.
作者簡介:高宏旭(1979— ),吉林兆南人,工程師;研究方向:人工智能,系統架構設計。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小康(2017年16期)2017-06-07 09:00:59
戲劇之家(2016年19期)2016-10-31 18:38:40
戲劇之家(2016年19期)2016-10-31 18:04:18
中國科技博覽(2016年19期)2016-10-19 12:24:58
