自然啟發優化面臨的問題與挑戰
2020-07-21 06:30:44楊杰蒲亦非
現代計算機 2020年16期
楊杰,蒲亦非
(四川大學計算機學院,成都610065)
0 引言
許多現實世界的應用涉及目標優化,如成本、能源消耗的最小化,性能、效率和可持續性的最大化。在許多情況下,優化問題存在于高度非線性多模態目標場景,受制于一套復雜的非線性約束,這些問題很難解決。即使現代計算機性能不斷增強,使用簡單暴力破解仍不現實。因此,高效的算法對這類應用至關重要。雖然優化算法種類很多,如基于梯度的算法、內點法、信賴域法等,但大多數都是基于梯度的局部搜索算法[1],這意味著最終解可能依賴于起始點。此外,導數計算代價非常昂貴,一些問題如非連續目標在某些區域可能不具有導數。近期趨勢是使用自然啟發優化,可以分成四個大類:進化算法、生物啟發算法、基于物理/化學的算法和群智能算法。
在過去的幾十年里,出現了各種各樣的群智能算法,包括蟻群算法、粒子群算法、蝙蝠算法、螢火蟲算法、布谷鳥搜索等[2]。這些自然啟發算法往往是全局優化器,使用多個相互作用的代理來生成搜索空間中的搜索行為。這類全局優化器通常簡單、靈活,高效,在許多應用和案例研究中得到了證明[2]。在過去的三十年中,自然啟發優化已經取得了顯著的進展,并出現了各種各樣的應用。
盡管自然啟發優化的有效性和流行度很高,但仍然存在許多問題。第一,還沒有找到開發與探索之間的平衡。第二,還沒有統一的數學框架來對這些算法進行分析,深入了解它們的穩定性、收斂性、收斂速度和魯棒性。第三,自然啟發算法中參數的取值會影響算法的性能,但什么是最佳參數取值或設置方案以及如何調優這些參數以獲得最佳性能尚不明確。第四,這些算法的對比研究主要基于數值實驗,很難證明這種比較是否公平。分析自然啟發算法面臨的問題和未來的研究方向,很有必要。
1 問題
1.1 多未必佳
自然啟發優化首要問題是決定是改進當前社區發現的方法,或是尋找新的啟發來源。最近,圍繞基于隱喻的方法的爭議尚未就社區在該領域應采用的策略達成任何共識,也沒有阻止越來越多的基于所謂的創新自然啟發的優化技術的出現。令人遺憾的是,這類文獻爆發的部分原因是對該領域的實際需求缺乏看法。然而,就如何從理論上(新穎性、特性)和經驗上(比較方法、基準問題)評估新算法這一問題不能達成共識,那么就絕對不可能分清良莠。建議重新開始該領域的工作,著重整個自然啟發優化的基礎范例,這有助于解決社區中有爭議的問題。
1.2 統一數學框架、符號和描述
不同的經驗觀察和數值模擬已經闡明,自然啟發優化在實踐中表現出色,但我們很少理解為什么它們在給定的條件下對給定類型的問題有效。盡管在理論分析方面取得了一些進展,但迫切需要使用更系統的方法(理想情況下,一個大類別使用一個統一的框架)來分析自然啟發算法,以便從數學上深入了解它們的工作機制,評估其性能,幫助解決為給定的問題集選擇合適的算法的難題。最近提出的理論研究似乎對分析和理解群智能算法很有希望,例如使用網絡科學來表征群智能算法[3]。
圍繞新舊自然啟發算法之間的類比已經進行了很多討論,如和聲搜索和進化策略;粒子群優化與螢火蟲算法;蟻群優化和智能水滴。通過統一描述算法的語義可以避免分歧,新算法的提出也可以利用這種統一描述方式。大量新自然啟發算法被提出證明了采用標準符號的重要性,標準符號關注新算法操作符的領域無關性描述以及啟發式和元啟發式的設計模式。
這種標準化無隱喻的詞匯將防止社區混淆當今廣泛使用的模糊數學公式和新算法的真實機制。例如,通過無隱喻描述,一個候選解可以被明確地標識,而不是用雞蛋、水滴或蜂巢來指代。文獻[4]將不同蜂群算法的隱喻解碼為標準化優化術語,強調了符號唯一性的重要性。除了評估算法之間的異同之外,該標準化過程還可以帶來其他好處,例如提高模塊化和啟發式組件的可重用性,更好地檢測非必要算法復雜性的可能來源以及使結果更直接、更可靠、可復現。描述標準化的透明宣言在多年前就已發布[5],但至今仍未在此方向上產生任何重大進展。
1.3 參數調優
對于擬牛頓法等傳統算法,單個參數的調優具有嚴格的數學基礎[1]。而對于自然啟發算法,調優主要是根據經驗或通過參數研究[6]。一個具有m 個參數pm=(p1,p2,…,pm)的算法可以用以下形式表示:
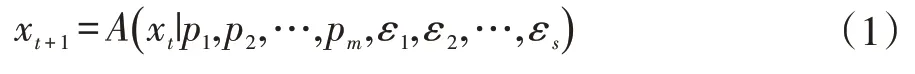
其中,ε1,ε2,…,εs是s 個不同的隨機數,可以來自不同的概率分布。這些隨機數一般都是迭代選取的。因此,算法調優主要是跟這m 個參數有關,可以把公式(1)簡化成以下形式:

原則上,我們應該使用調優好的算法(或沒有任何參數的算法)來調優新算法。但如果我們使用算法B對算法A 進行調優,算法B 最初是如何調優的?因此,關鍵問題是如何正確地調優未知算法。
如果參數數量很多,暴力調優可能非常耗時。此外,調優好的算法對一種類型的問題有效,不能保證其對另一種類型的問題也有效。算法的參數設置可能同時依賴于算法和問題,而且沒有理由不在迭代過程中改變參數。事實上,一些研究表明,參數的變化可能是有利的。例如,自適應差分進化算法似乎比其基本版本性能更高[7]。調優算法的一種方法是將參數調優視為一個雙邊過程,從而形成一個自調優框架[8],使算法可以調優自身。但這仍然是一個非常耗時的方法。
如何優化指定算法的參數,使其在給定問題集上達到最佳性能?或者說,如何改變或控制這些參數,以最大限度地提高算法的性能?自然啟發算法的參數調優問題,尚需研究。
1.4 合適的基準測試
對于任何一種新自然啟發算法,使用基準函數來對比測試新算法與其他算法的性能非常重要。這樣的基準測試可以讓研究人員更好地了解算法的收斂性、穩定性、優點和缺點。然而,關鍵問題是應該使用什么基準。
在目前的文獻中,基準測試實踐似乎使用了一組具有不同屬性的測試函數(如振型、可分性和最優局域性)。但是這種基準在實踐中并沒有太大的用處。這些測試函數通常在常規域上是無約束的或帶有簡單約束的,而實際應用中的問題可能有許多復雜的非線性約束,并且域可以由許多孤立的區域或島嶼構成。因此,在測試函數表現良好的算法不一定在實際應用中表現良好。
為了正確地驗證算法,測試和驗證應該包括具有不規則域、受到各種約束的測試函數。例如下面這個看起來很簡單的二維函數f(x,y):

定義域為:
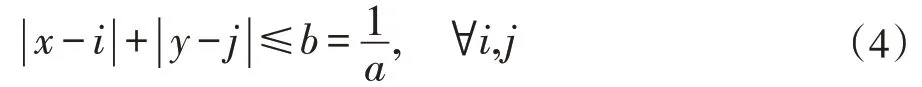
其中i,j都是整數,N=100 ,a=10 。該函數有4(N+1)2個局部峰,但在四個角有4 個最高峰。其定義域由4(N+1)2=40401個獨立區域構成。
根據無免費午餐定理[9],沒有一個通用的工具可以用來解決所有或至少絕大多數的優化問題。算法A 解決某些問題的能力優于另一個算法B,那么還有一些其他問題B 會優于A。在實際解決問題時,我們總是關注一組特定的問題,而不是所有的問題。因此,使用有限的算法集和有限的函數集進行基準測試成為一個零和博弈問題[10]。此外,最近的研究似乎表明,免費午餐可能存在,特別是對于持續優化[11]、多目標優化[12]或協同進化[13]。因此,什么類型的基準測試是有用的?免費午餐存在嗎?在什么條件下存在?這些問題仍需研究。
1.5 合適公平的性能指標
比較算法性能時,應采用合適、公平的指標。在目前的文獻中,比較研究主要關注準確性、計算量、穩定性和成功率。
驗證準確性比較好的做法是,對于給定的問題,將算法獲取的最優解與已知最優解或其他已被驗證表現優秀的算法的最優解進行對比。顯然,這取決于算法的停止條件,即使是無效的算法,運行時間足夠長也可以獲得足夠好的結果。因此,為了公平起見,所有算法應使用相同的計算量。
驗證計算量,目前大多采用固定精度,將函數調用或求值的數量作為計算成本的度量進行比較。函數求值的次數越少被認為越好。
自然啟發算法的結果不是完全可重復的,需要多次運行才能獲得有意義的統計數據。因此,一些研究人員使用在最終迭代中獲得的最佳目標值,以及它們的平均值、標準差和其他統計數據。這可能會提供有關算法的更完整描述。雖然標準差越小可能表明算法更穩定,但也可能與所考慮的問題有關,此外,算法中使用的初始化總體和概率分布的方式也有可能影響標準差結果,盡管尚不清楚初始化如何確切地影響最終結果。
還有一個用于比較的指標是成功率。多次運行(Nr)算法,可能存在Ns次找到最優解的情況,則成功率是顯然,這取決于“成功”的定義。對于函數f(x),已知其最優解x*和最小化目標fmin(x*),成功可以由解達到滿意的誤差界|x-x*|≤δ或|f(x)-fmin|≤δ來定義。但是,搜索域相對平坦與否,會使得標準非常不同。
大部分文獻使用一種或多種性能指標,但尚不清楚上述性能指標是否真的公平。我們仍需思考,要公平比較所有算法,最合適的性能度量是什么?是否有可能設計一個統一的框架來公平而嚴格地比較所有算法?
2 挑戰
2.1 效能到效率
全球對能源效率的關注與日俱增,最近創造了所謂的綠色計算概念[14]。在這個規則下的算法以環境可持續性作為設計目標,在它們執行線程的步驟中施加了嚴格的約束。采用此類設計會在資源分配、內存索引或運行時間等方面產生重要的修改。最重要的是,算法的實現方式對其實際效率也有很大影響,這就要求從算法設計的一開始就采用綠色計算。支持綠色計算的良好做法應該是使社區始終對新的算法執行復雜度分析。在任何情況下,對自然啟發算法效率的研究都應該避免報告與算法本身的實現和部署密切相關的度量,例如計時日志或凈內存消耗,這些度量會因非算法事項產生巨大偏差。未來還應推導出算法組件的特征與其預期碳足跡之間的對應關系。
2.2 以人為中心的應用中的自然啟發算法
以人為中心的應用程序,如視頻游戲或虛擬現實/增強現實(VR/AR),目前處于各種場景的前沿,而自然啟發計算可以為之提供前所未有的機器智能水平[15]。這類應用以用戶和機器之間持續交互為特征,要求底層算法具有用于動態適應、增量學習和有限復雜性的卓越能力。盡管存在這些計算限制,自然啟發計算可能給這些應用領域帶來的無數機會:從改進自我定位到優化人群仿真或虛擬對象的操作。例如,VR/AR 中的延遲會受到運動到光子閾值(~20ms)的嚴重限制,這對任何自然啟發優化算法都提出了具有挑戰性的設計約束,畢竟這些算法的設計目的是為了改善用戶體驗或優化來自流服務器的媒體內容的呈現過程。
要勇于在一個巨大的領域中探索未來,釋放出新的有趣的范式,如針對多個不斷變化的問題語句的持續優化(與持續/終身機器學習[16]明確相關),以及自我影響模型(根據預測采取的行動可能會影響隨后的預測結果)。
2.3 自然啟發優化和新興的計算范例
除上述研究途徑外,整個社區都應該密切關注即將到來的新計算范式,從大數據架構下的Map/Reduce模型到短暫計算、億級計算和量子計算。大約十年前,我們沒有預料到計算技術的發展速度會像我們后來目睹的那樣快,開發出了能夠提取、存儲和處理海量數據的數據密集型技術。如今,自然啟發算法的Map/Reduce 實現可用于在大數據平臺上部署[17]。在處理能力方面,類似的趨勢可以在當今的短暫計算[18]和億級計算[19]中看到,它們為擴展復雜的仿生算法提供了有效手段。然而,量子計算仍然處于初級階段,它已經將其適用性擴展到機器學習領域,并預計可在許多其他領域的處理吞吐量方面將獲得驚人的收益,包括機器學習和大規模優化[20-21]。
我們不知道未來還會遇到哪些計算范例,它們將如何影響自然啟發優化方法的設計和部署。然而,我們必須沿著這一領域有價值的方向開展研究工作,為它們的最終到來做好準備。除非我們都認識到這種聯合力量的迫切需要,并就自然啟發優化的真正優先事項達成一致,否則我們將在這一領域毫無進展的漸進式研究道路上徘徊不定,盲目前進。
3 結論與展望
本文分析自然啟發優化目前面臨的問題及今后的研究方向,以利于這些問題得到充分探索。在自然啟發領域,未揭示的范例肯定會繼續促進自然啟發優化的新進展,以不可預見的性能水平和計算效率為特色。現今,研究界有機會拋開誤導性的研究道路,以一種和諧、有原則和科學的方式,共同面對這一領域勢不可擋的未來。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
