基于用戶屬性偏好與時(shí)間因子的服裝推薦研究
2020-07-24 02:11:37周靜何利力
軟件導(dǎo)刊 2020年6期
周靜 何利力


摘要:針對服裝推薦方法推薦精度不高、覆蓋率低,不能充分挖掘用戶潛在興趣的問題,提出一種基于用戶圖像內(nèi)容屬性偏好與時(shí)間因子的服裝推薦(UIACF)算法。通過構(gòu)建深度卷積神經(jīng)網(wǎng)絡(luò),提取服裝圖像中的服裝屬性,并據(jù)此形成用戶屬性向量,將基于用戶屬性偏好的相似度與基于時(shí)間因子的用戶興趣偏好相似度融合,構(gòu)建用戶偏好模型。將其與基于用戶的協(xié)同過濾(UCF)算法、基于項(xiàng)目的協(xié)同過濾(ICF)算法及基于項(xiàng)目偏好的協(xié)同過濾(UCSVD)算法進(jìn)行比較,結(jié)果顯示,UIACF算法準(zhǔn)確率提高14%。該算法為基于用戶的服裝協(xié)同過濾個(gè)性化推薦提供了一種新思路,用戶潛在興趣挖掘效率更高。
關(guān)鍵詞:圖像分類;用戶偏好;協(xié)同過濾;服裝推薦;時(shí)間因子
DOI:10.11907/rjdk.192085開放科學(xué)(資源服務(wù))標(biāo)識(shí)碼(OSID):
中圖分類號(hào):TP301文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1672-7800(2020)006-0023-06
0 引言
隨著網(wǎng)絡(luò)的普及,全民網(wǎng)上購物的電子商務(wù)時(shí)代已然到來。淘寶、京東等電子商務(wù)平臺(tái)提供越來越多的服裝選擇,但是信息超載問題也隨之而來。現(xiàn)有搜索技術(shù)無法滿足消費(fèi)者服裝個(gè)性化需求。因此既能解決信息超載問題又能提供個(gè)性化服務(wù)的個(gè)性化推薦技術(shù),引起了相關(guān)研究者關(guān)注。Lin等在既有研究的基礎(chǔ)上,提出一種基于用戶需求偏好因素之外的需求因素的用戶模型;王安琪等結(jié)合服裝搭配的四季色彩理論與計(jì)算機(jī)視覺技術(shù),提出一種判斷優(yōu)化模型,但是沒有考慮用戶之間的關(guān)系;周捷等將灰色關(guān)聯(lián)分析法和主觀賦權(quán)、客觀賦權(quán)相結(jié)合,實(shí)現(xiàn)了服裝型號(hào)準(zhǔn)確推薦,但是應(yīng)用場景比較單一;楊天祺等利用深度學(xué)習(xí)進(jìn)行服裝圖片識(shí)別和搭配推薦,但忽略了用戶歷史偏好,僅考慮了數(shù)據(jù)庫中的搭配。
本文在已有研究的基礎(chǔ)上,對傳統(tǒng)基于用戶的協(xié)同過濾算法進(jìn)行改進(jìn),將服裝圖像屬性內(nèi)容與時(shí)間因子相結(jié)合,提出一種改進(jìn)的基于用戶偏好的服裝個(gè)性化推薦技術(shù)。首先進(jìn)行基于服裝圖像內(nèi)容的屬性識(shí)別,由于服裝屬性特殊性,加入三元組網(wǎng)絡(luò)以滿足細(xì)粒度識(shí)別屬性的要求;其次,建立用戶服裝屬性向量,根據(jù)用戶評(píng)分服裝與服裝屬性包含關(guān)系,構(gòu)建用戶關(guān)于服裝圖像內(nèi)容的屬性偏好,并計(jì)算基于用戶屬性偏好的用戶相似度;然后,融合關(guān)于時(shí)間因子的興趣度變化,構(gòu)建最終的用戶偏好模型,實(shí)現(xiàn)服裝推薦;最后,將本文UIACF算法與傳統(tǒng)基于用戶的協(xié)同過濾(UCF)算法、基于項(xiàng)目的協(xié)同過濾(ICF)算法以及基于項(xiàng)目偏好的協(xié)同過濾(UCSVD)算法在準(zhǔn)確度和挖掘用戶興趣度兩個(gè)方面進(jìn)行比較,驗(yàn)證算法有效性。
1 相關(guān)工作
1.1 基于用戶的協(xié)同過濾個(gè)性化推薦
經(jīng)過幾十年的研究和發(fā)展,個(gè)性化推薦方法系統(tǒng)積累了多種不同類型、各具特點(diǎn)的推薦算法。個(gè)性化推薦方法主要包括基于內(nèi)容的推薦方法、基于協(xié)同過濾的推薦方法、混合推薦方法、基于知識(shí)的推薦方法、基于數(shù)據(jù)挖掘的推薦方法以及基于人口統(tǒng)計(jì)學(xué)的推薦方法等。由于基于協(xié)同過濾的個(gè)性化推薦算法考慮了所有用戶和物品的交互信息,且更偏向于挖掘用戶潛在需求,所以基于協(xié)同過濾的推薦算法應(yīng)用廣泛,其主要思想是根據(jù)與相似的鄰居對項(xiàng)目歷史行為的評(píng)分情況,預(yù)測目標(biāo)用戶對項(xiàng)目的態(tài)度。比較成熟的應(yīng)用包括預(yù)測電影、日用消費(fèi)品和電子類等方面,服裝推薦系統(tǒng)有其特殊性,目前并不成熟,仍處于探索階段,面臨諸多挑戰(zhàn)。
基于用戶近鄰的協(xié)同過濾算法主要思想是通過尋找與目標(biāo)用戶相近的用戶,并利用近鄰用戶評(píng)分信息進(jìn)行推薦。基于用戶近鄰的協(xié)同過濾算法的目標(biāo)是尋找到與目標(biāo)用戶偏好相近的用戶,即近鄰用戶。
用戶相似度計(jì)算主要采用3種方式,分別是余弦相似度、修正余弦相似度和皮爾遜相關(guān)相似度。實(shí)際生活中用戶有不同的評(píng)分標(biāo)準(zhǔn),因此一般采用基于皮爾遜相似度的用戶相似性,如式(1)所示。
其中sim(u,v)表示用戶u、v相似性,S表示用戶u、v共同評(píng)分項(xiàng)目集合,ru,i、rv,i表示用戶u、v對項(xiàng)目i的評(píng)分,ru和rv表示用戶u、用戶v對各自評(píng)分項(xiàng)目的平均評(píng)分。
其次是近鄰選擇,近鄰選擇會(huì)對最終推薦結(jié)果產(chǎn)生很大影響,為了不影響推薦效率和推薦結(jié)果準(zhǔn)確性,通常采用K近鄰和閩值過濾。K近鄰指選取前k個(gè)最相似的近鄰用戶,閾值過濾則設(shè)置了一個(gè)固定閾值,選擇相似度大于該值的近鄰用戶。
最后利用確定的近鄰用戶預(yù)測目標(biāo)用戶對物品的評(píng)分。常用預(yù)測方法是均值中心化。該方法主要考慮用戶的不同評(píng)分標(biāo)準(zhǔn),通過評(píng)分均值與評(píng)分偏移兩種方式消除用戶因?yàn)樵u(píng)分標(biāo)準(zhǔn)造成的偏差,如式(2)所示。
1.2 服裝圖像屬性分類
傳統(tǒng)服裝屬性分類是基于文本分類,利用中文自然語言處理技術(shù)并根據(jù)商家提供的文本描述提取服裝屬性,一般包括中文分詞(CWS)和停用詞去除兩個(gè)部分。中文分詞任務(wù)是將一系列的句子劃分成一個(gè)個(gè)詞語,停用詞去除指去除沒有實(shí)際意義但又出現(xiàn)次數(shù)很多的詞語。但是,服裝電子商城中的文字描述往往僅包含一部分屬性,而且文字描述一般受主觀影響,無法完整準(zhǔn)確地表達(dá)多元化服裝圖像內(nèi)容。因此基于圖像內(nèi)容的服裝屬性分類被提出。
近年來深度學(xué)習(xí)在計(jì)算機(jī)視覺領(lǐng)域取得了突破性進(jìn)展,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)成為圖像領(lǐng)域研究熱點(diǎn),在目標(biāo)檢測、圖像分類及圖像檢索等任務(wù)中表現(xiàn)優(yōu)異,所以本文選用卷積神經(jīng)網(wǎng)絡(luò)提取服裝圖像屬性分類。卷積神經(jīng)網(wǎng)絡(luò)是一種端到端的網(wǎng)絡(luò)結(jié)構(gòu),主要由輸入層、卷積層、池化層和全連接層組成,優(yōu)點(diǎn)是局部區(qū)域感知與權(quán)值共享,常用深度模型有VGG-NET、GooZle-Net和ResNet等。卷積層輸人為:
其中,a(l)是第一層卷積核,b(l)為偏置,式(4)中G(·)為激活函數(shù),使用激活函數(shù)以避免梯度消失。
池化層主要用于降低特征維數(shù),最大池化和平均池化是較常用的兩種方式,全卷積層用于輸出。
2 模型構(gòu)建
面對服裝電子商務(wù)網(wǎng)站上大量的服裝圖片信息,用戶往往難以選擇,如果服裝圖片內(nèi)容能夠吸引用戶注意力,則用戶購買可能性也會(huì)增大,銷量將隨之提升。因此,服裝圖片中的服裝屬性對用戶的影響非常重要。同時(shí),用戶對服裝的興趣并不是一成不變的,受季節(jié)、潮流改變購物興趣的行為十分常見,所以本文分別對基于用戶服裝圖像內(nèi)容屬性偏好與基于時(shí)間因子的用戶興趣偏好進(jìn)行研究,最后將兩者融合。
2.1 基于圖像內(nèi)容的服裝屬性提取
卷積神經(jīng)網(wǎng)絡(luò)通常處理單任務(wù),但由于本文需要提取服裝圖像多種分類下的不同屬性,且某些屬性之間存在關(guān)聯(lián)性,比如風(fēng)格與顏色、材質(zhì)有關(guān),如果分解為多個(gè)單分類下的屬性進(jìn)行提取,不但會(huì)忽略各個(gè)分類之間的相關(guān)性,而且會(huì)增加網(wǎng)絡(luò)訓(xùn)練復(fù)雜度,所以本文采用多任務(wù)學(xué)習(xí)的服裝圖像屬性提取。多任務(wù)學(xué)習(xí)可相互影響,一個(gè)任務(wù)可以利用另外一個(gè)任務(wù)的信息得到優(yōu)化,從而提高整個(gè)模型精確性。
結(jié)合多任務(wù)學(xué)習(xí)的卷積神經(jīng)網(wǎng)絡(luò)模型,其詳細(xì)結(jié)構(gòu)如圖l所示。服裝圖像多屬性分類任務(wù)共享淺層卷積網(wǎng)絡(luò)和權(quán)值參數(shù),全連接層連接各子任務(wù)的全連接層和分類器。
由于服裝包含如扣型、拉鏈等諸多細(xì)節(jié),其圖像具有特殊性,需考慮服裝細(xì)節(jié)位置,由于一些屬性特征可能是服裝邊緣信息決定的,所以為了更好利用服裝邊緣信息,本文在卷積層之間引入特征金字塔。卷積神經(jīng)網(wǎng)絡(luò)低層特征一般是高維特征,高層特征是低維特征。為了使特征維度統(tǒng)一,本文采用反卷積方法,將后一層卷積層進(jìn)行反卷積操作,使前后兩層特征和依次往前疊加,生成整張圖片的最終特征表示。
另一方面為了學(xué)習(xí)到細(xì)粒度的服裝圖像屬性分類,實(shí)現(xiàn)服裝屬性精細(xì)分類,本文結(jié)合Triplet Loss和Softmaxloss兩種損失函數(shù)以實(shí)現(xiàn)細(xì)粒度分類。Triplet Loss三元組損失函數(shù)需要輸入3個(gè)樣本構(gòu)成三元組,分別是參考樣本(AnchorSample)、正樣本(Positive Sample)和負(fù)樣本(Negative Sample)。Triplet Loss損失函數(shù)的目標(biāo)是使AnchorSample和Positive Sample之間的距離最小,使NegativeSample之間的距離最大。本文Triplet Loss損失函數(shù)公式定義為:
其中,p表示樣本圖像,q+表示正樣本圖像,q-表示負(fù)樣本圖像,d(p,q+)表示樣本和正樣本間的歐式距離,d(p,g-)表示樣本和負(fù)樣本間的歐式距離,T表示特定閾值。
結(jié)合Softmax損失函數(shù)之后,整個(gè)網(wǎng)絡(luò)損失函數(shù)表示如式(6)所示。
L=λLtriplet+(1-λ)Lsoftmax(6)
其中Ltriplet表示triplet學(xué)習(xí)相關(guān)損失,Lsoftmax表示Soflmax分類相關(guān)損失,又表示比例。
2.2 用戶屬性偏好模型構(gòu)建
根據(jù)基于圖像內(nèi)容的服裝屬性分類算法得到服裝圖像的屬性值,將服裝測試庫中的服裝進(jìn)行編號(hào),每件服裝以向量的形式展現(xiàn),如式(7)所示。
Kn=(x1,x2,x3,x4,x5,…,xi) (7)
其中n表示第n件衣服,xi表示第i個(gè)屬性。如果某服裝商品包含某一服裝屬性,則設(shè)置為1,否則設(shè)置為0,由此得到所有服裝商品向量表示集合。
本文結(jié)合用戶對服裝商品的評(píng)分及服裝具有的屬性信息,構(gòu)建每個(gè)用戶的用戶一屬性矩陣。表1展示了部分用戶一服裝評(píng)分矩陣。表2展示了服裝一屬性包含矩陣。
表1、表2顯示了不同用戶對不同服裝的評(píng)分和被評(píng)價(jià)的服裝是否包含某一屬性,表2中0表示包含該屬性,1表示沒有該屬性。根據(jù)上述關(guān)系,用戶對屬性的偏好程度為:
ru,p表示用戶u對屬性p的偏好程度,Ip表示用戶u的評(píng)分商品中包含屬性p的集合,ip表示項(xiàng)目是否包含屬性p,包含為1,不包含為0。得到用戶屬性的偏好值后,根據(jù)式(9)可以計(jì)算出用戶間的相似度。
2.3 基于時(shí)間因子的用戶興趣模型構(gòu)建
興趣會(huì)隨時(shí)間發(fā)生變化,因此本文使用logistic權(quán)重函數(shù)作為時(shí)間因子函數(shù),對評(píng)分實(shí)現(xiàn)加權(quán),降低時(shí)間過久的數(shù)據(jù)評(píng)分權(quán)重,增加近期數(shù)據(jù)評(píng)分權(quán)重,logistic權(quán)重函數(shù)為:
tu,i表示用戶u項(xiàng)目i的評(píng)分時(shí)間和用戶u第一次對項(xiàng)目i評(píng)分的時(shí)間之差。Logistic權(quán)重函數(shù)隨著tu,i的增大而增大。加入時(shí)間權(quán)重后,用戶平均評(píng)分為:
2.4 融合用戶屬性偏好與時(shí)間因子的模型構(gòu)建
將基于時(shí)間因子的用戶興趣相似度與基于服裝圖像內(nèi)容用戶屬性偏好的相似度融合在一起。通過參數(shù)θ進(jìn)行加權(quán),θ的取值根據(jù)實(shí)際情況發(fā)生變化,融合后的相似度表達(dá)式為:
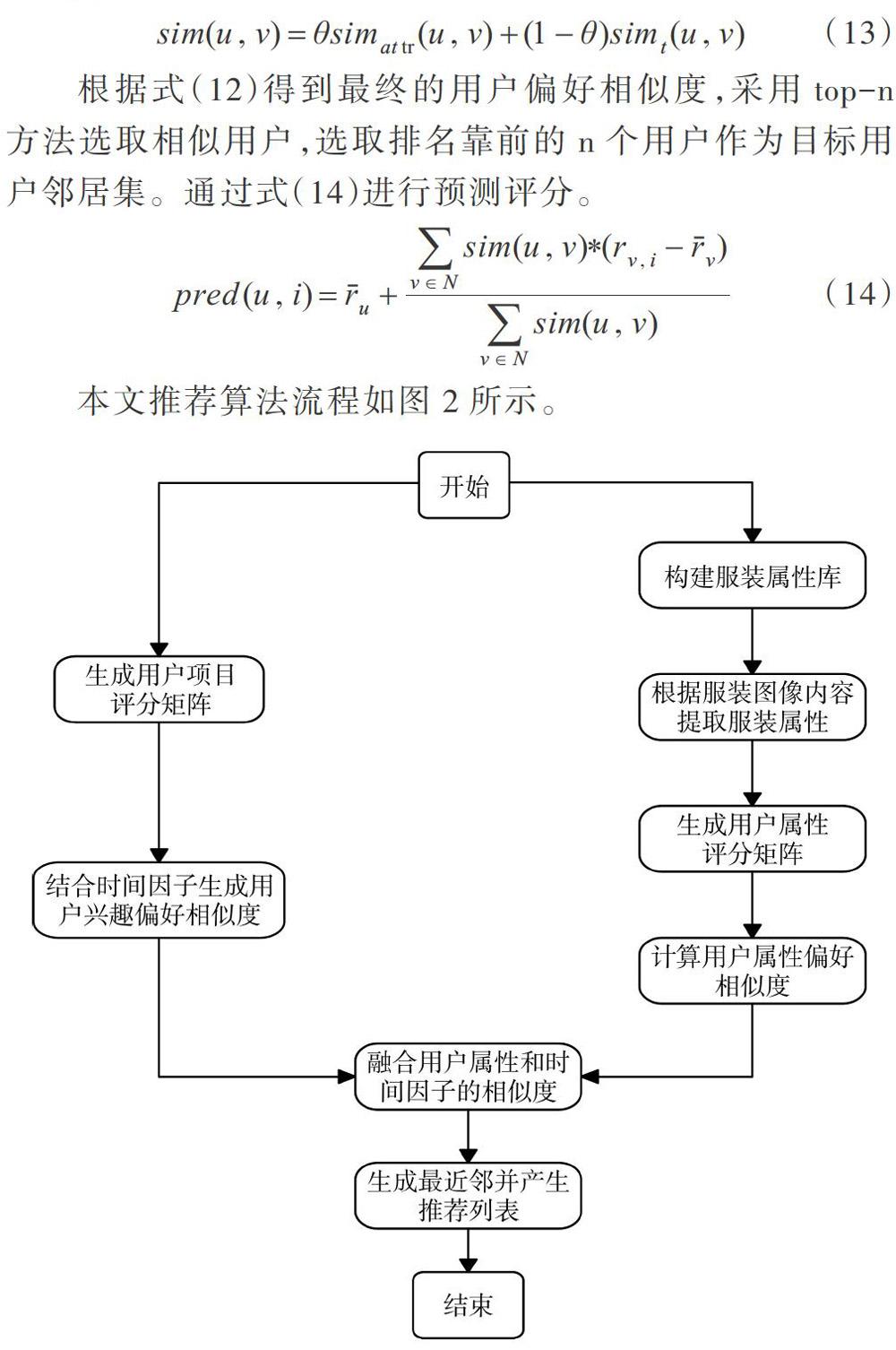
sim(u,v)=θsimattr(u,v)+(1-θ)simt(u,v) (13)
根據(jù)式(12)得到最終的用戶偏好相似度,采用top-n方法選取相似用戶,選取排名靠前的.個(gè)用戶作為目標(biāo)用戶鄰居集。通過式(14)進(jìn)行預(yù)測評(píng)分。
3 實(shí)驗(yàn)及性能分析
3.1 數(shù)據(jù)采集與處理
服裝產(chǎn)業(yè)發(fā)展到現(xiàn)代,服裝種類根據(jù)不同標(biāo)準(zhǔn)可劃分為多種,比如根據(jù)風(fēng)格可以劃分為休閑、復(fù)古、性感、優(yōu)雅、時(shí)尚等,根據(jù)面料可以劃分為純棉、真絲、麻、化纖等,根據(jù)類型可以劃分為襯衫、衛(wèi)衣、外套等,由于服裝屬性多樣化和不確定性,課題組邀請服裝行業(yè)的專家,根據(jù)不同分類共確定了常見的8種分類及480種屬性。表3展示了部分屬性。
服裝圖像屬性提取實(shí)驗(yàn)中用到的服裝圖像來自于互聯(lián)網(wǎng),由于卷積神經(jīng)網(wǎng)絡(luò)需要大量圖片用于實(shí)驗(yàn),所以共采集30000張服裝圖片,其中24000張用于訓(xùn)練,剩下的6000張用于測試。數(shù)據(jù)集中,80%的服裝圖片來自于電子商務(wù)網(wǎng)站,由于是店鋪圖片,所以這些圖片背景一般不復(fù)雜,人物服裝主體也比較突出,剩下的20%圖像是社交網(wǎng)絡(luò)中有干擾背景和不同光照的圖片。由于服裝推薦的特殊性,網(wǎng)上并沒有比較適合的服裝用戶屬性評(píng)價(jià)數(shù)據(jù)集。因此使用爬蟲等技術(shù)從網(wǎng)上采集了上述服裝圖像數(shù)據(jù)集中1000張圖片的相應(yīng)評(píng)價(jià),以淘寶網(wǎng)為例,用戶在網(wǎng)上購買商品之后,一般會(huì)針對商品進(jìn)行評(píng)價(jià),本文以評(píng)價(jià)數(shù)據(jù)作為用戶對商品的評(píng)分。數(shù)據(jù)集參照MovieLens數(shù)據(jù)集的形式,每一行包括用戶ID、服裝ID、用戶評(píng)價(jià)以及提取到的服裝屬性,由于一些用戶可能沒有評(píng)價(jià),為了避免數(shù)據(jù)稀疏性,所以本文將沒有進(jìn)行評(píng)論的用戶篩選清洗出去,清洗后的數(shù)據(jù)分布如表4所示。本文將服裝商品數(shù)據(jù)集簡稱為數(shù)據(jù)集A。
3.2 服裝屬性分類實(shí)驗(yàn)與性能分析
為了對比不同卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的分類效果,訓(xùn)練了只含有Softmax loss損失函數(shù)的S-CNN網(wǎng)絡(luò)、結(jié)合Softmax和Siamese度量學(xué)習(xí)的SS-CNN網(wǎng)絡(luò)、結(jié)合Softmax和Triplet的ST-CNN網(wǎng)絡(luò)共3種不同結(jié)構(gòu)的網(wǎng)絡(luò),每個(gè)網(wǎng)絡(luò)權(quán)重參數(shù)初始化為高斯分布產(chǎn)生的較小的數(shù)字,偏置為0,訓(xùn)練過程中,學(xué)習(xí)速率初始值設(shè)置為0.01,權(quán)重衰減系數(shù)設(shè)為0.0002。使用分類精確度作為評(píng)價(jià)指標(biāo),分類精確度計(jì)算公式定義為分類正確圖像總數(shù)目k與測試圖像總數(shù)目n的比值,計(jì)算公式為如式(15)所示。
實(shí)驗(yàn)結(jié)果如表5所示。
從表5中可以看出,只含有Softmax損失函數(shù)的S-CNN網(wǎng)絡(luò)分類精度較低,引入Siamese結(jié)構(gòu)的網(wǎng)絡(luò)分類精確有小幅度提升,而引入Triplet之后的ST-CNN網(wǎng)絡(luò)結(jié)構(gòu)分類精度約有4個(gè)百分點(diǎn)的提高。
表6顯示了使用ST-CNN網(wǎng)絡(luò)分類進(jìn)行服裝圖像屬性提取的結(jié)果。無論是準(zhǔn)確率,還是服裝圖像屬性提取結(jié)果展示,本文屬性提取網(wǎng)絡(luò)均能夠較好地完成屬性提取任務(wù),這也為服裝推薦模型提供了較好基礎(chǔ)。
3.3 服裝推薦實(shí)驗(yàn)與性能分析
3.3.1 評(píng)價(jià)標(biāo)準(zhǔn)
由于推薦系統(tǒng)應(yīng)用的情況不一,所以至今沒有標(biāo)準(zhǔn)的評(píng)價(jià)指標(biāo)。大多數(shù)推薦系統(tǒng)采用的評(píng)價(jià)指標(biāo)是MAE和RSME,但是在實(shí)際情況中,用戶在意的并不是某個(gè)項(xiàng)目給出的評(píng)分值,而是系統(tǒng)是否能夠推薦用戶喜歡的服裝,所以本文考慮準(zhǔn)確率(precision)和召回率(recall)兩種指標(biāo)。
準(zhǔn)確率表示推薦的商品中用戶喜歡的服裝所占比例,召回率表示推薦的服裝中用戶喜歡的服裝占用戶所有喜歡服裝的比例,這兩種方式更能展現(xiàn)推薦的效果。本文主要考慮準(zhǔn)確率,具體公式見式(16)、(17),表7表示公式中參數(shù)的含義。
雖然準(zhǔn)確率和召回率越高越好,但是在特定的情況下,兩者是相互矛盾的。因此,本文采用綜合指標(biāo)C進(jìn)行評(píng)估,G是準(zhǔn)確率和召回率的加權(quán)結(jié)合,其表達(dá)式為:
3.3.2 實(shí)驗(yàn)設(shè)計(jì)與結(jié)果分析
(1)實(shí)驗(yàn)1:θ調(diào)整因子對算法的影響。為驗(yàn)證θ的大小對準(zhǔn)確率預(yù)測的影響,設(shè)步長為0.1,選出性能最好的θ作為本文算法調(diào)整因子。將本文算法UIACF按照不同的θ取值進(jìn)行實(shí)驗(yàn)后的RSME值如圖3所示。
從實(shí)驗(yàn)結(jié)果可以看出,隨著θ的增大,RSME先減小后增大,當(dāng)θ為0.1時(shí),RSME的值最大;當(dāng)θ為0.6時(shí),RSME的值最小。這是由于當(dāng)θ趨向于0.1時(shí),時(shí)間因子產(chǎn)生的興趣變化基本不起作用,只依賴于用戶屬性偏好不能很好表明用戶偏好,隨著θ的增大,時(shí)間因子占得比重越來越大,使得RSME的值逐漸減小。當(dāng)。趨向于1時(shí),完全忽略了時(shí)間因子的影響,從而使RSME又逐漸增大。合理分配。值有利于提高最終預(yù)測結(jié)果的準(zhǔn)確性,本文θ為0.6時(shí),RSME值最小,說明綜合考慮基于服裝圖像屬性偏好的與基于時(shí)間因子的興趣度變化的偏好結(jié)果最好。實(shí)際情況可根據(jù)需要調(diào)整。
(2)實(shí)驗(yàn)2:不同算法準(zhǔn)確率對比。為了進(jìn)一步驗(yàn)證本文算法準(zhǔn)確性和有效性,利用采集的服裝數(shù)據(jù),將傳統(tǒng)基于用戶的協(xié)同過濾算法UCF、基于項(xiàng)目的協(xié)同過濾算法ICF和基于項(xiàng)目偏好的協(xié)同過濾算法UCSVD作為對比進(jìn)行實(shí)驗(yàn),本文提出的UIACF算法準(zhǔn)確率根據(jù)公式(16)計(jì)算得到,其它3種算法的準(zhǔn)確率由實(shí)驗(yàn)室其他研究人員共同實(shí)驗(yàn)得到,不同算法的準(zhǔn)確率對比如圖4所示。
如圖4所示,隨著用戶近鄰集的增大,準(zhǔn)確率也在升高,當(dāng)N為30時(shí)準(zhǔn)確率達(dá)到最高,但是如果用戶近鄰數(shù)繼續(xù)增大,準(zhǔn)確率卻會(huì)下降,這是因?yàn)楫?dāng)鄰居數(shù)很多時(shí),鄰居集中的用戶相似度不高導(dǎo)致對結(jié)果產(chǎn)生負(fù)面影響。對比其它算法,本文提出的UIACF算法準(zhǔn)確率最多提高14%。
(3)實(shí)驗(yàn)3:不同近鄰數(shù)對算法的穩(wěn)定性影響。考慮到推薦系統(tǒng)需要的穩(wěn)定性和持久性,需排除偶然性因素。將近鄰數(shù)N取值不同情況下得到的準(zhǔn)確率、召回率通過公式(16)-(18)計(jì)算得到準(zhǔn)確率和召回率加權(quán)G的值,G值隨著N的變化情況如圖5所示。
隨著近鄰數(shù)的增加,評(píng)價(jià)指標(biāo)值一直在0.4-0.6之間,波動(dòng)很小,說明本文算法具有良好的穩(wěn)定性。
4 結(jié)語
本文提出了一種融合用戶圖像內(nèi)容屬性偏好、基于時(shí)間因子與用戶興趣偏好的服裝推薦算法,以用戶評(píng)價(jià)和用戶評(píng)價(jià)服裝的屬性偏好作為用戶屬性偏好的體現(xiàn),充分挖掘用戶潛在興趣,使用深度卷積神經(jīng)網(wǎng)絡(luò)提取用戶評(píng)價(jià)服裝圖片內(nèi)容的屬性,避免了人工標(biāo)注屬性的主觀性,且實(shí)現(xiàn)了細(xì)粒度屬性提取,還考慮了用戶興趣度隨時(shí)間的變化,加大了最近時(shí)間的評(píng)分權(quán)重,充分考慮用戶需求,體現(xiàn)了用戶服裝推薦個(gè)性化,也提高了個(gè)性化推薦準(zhǔn)確率。下一步工作將優(yōu)化服裝圖像內(nèi)容提取網(wǎng)絡(luò)結(jié)構(gòu),使網(wǎng)絡(luò)加入更多的屬性分類,考慮更多可影響用戶服裝購買行為的個(gè)性化因素,進(jìn)一步探索服裝個(gè)性化推薦技術(shù)。
