最小局部方差優(yōu)化初始聚類中心的K-means算法
2020-07-24 02:11:37王世其張文斌蔡潮森李建軍
軟件導(dǎo)刊 2020年6期
王世其 張文斌 蔡潮森 李建軍


摘要:針對傳統(tǒng)K-means算法隨機選取初始聚類中心導(dǎo)致聚類結(jié)果隨機性大、優(yōu)劣不定的缺點,通過定義局部方差,利用方差反映數(shù)據(jù)密集程度的特性,提出一種基于最小局部方差優(yōu)化初始聚類中心的K-means算法。該算法選取數(shù)據(jù)集中局部方差最小的點作為一個初始聚類中心,并利用數(shù)據(jù)信息更新數(shù)據(jù)集,直到選到k個初始聚類中心,實現(xiàn)初始聚類中心優(yōu)化。基于UCI數(shù)據(jù)集與人工數(shù)據(jù)集進行實驗,與傳統(tǒng)K-means算法及最小方差優(yōu)化初始聚類中心的K-means算法進行性能比較。實驗結(jié)果表明,基于最小局部方差優(yōu)化初始聚類中心的K-means算法具有良好的聚類效果和很好的魯棒性,且聚類時間較短,驗證了算法有效性和優(yōu)越性。
關(guān)鍵詞:聚類;K-means算法;初始化聚類中心;局部方差;密集程度
DOI:10.11907/rjdk.192061 開放科學(xué)(資源服務(wù))標識碼(OSID):
中圖分類號:TP312文獻標識碼:A 文章編號:1672-7800(2020)006-0196-05
0 引言
針對K-means算法隨機選取初始聚類中心容易得到局部最優(yōu)解的缺點,眾多學(xué)者提出優(yōu)化初始聚類中心的方法改進傳統(tǒng)K-means算法,這些方法主要可分為3類:①基于樣本空間密度的初始聚類中心優(yōu)化,有時有較好的聚類結(jié)果,但該法依賴于參數(shù)選擇,可能會因選取到噪聲點或參數(shù)選取不當(dāng)造成聚類效果差;②全局K均值聚類算法,雖有良好的聚類結(jié)果,但因算法復(fù)雜,聚類時間過長;③基于最小方差選擇初始聚類中心,該方法不依賴參數(shù)選取,且多數(shù)情況聚類效果良好,在聚類效果和時間上優(yōu)于前面兩種方法,但在某些情況下聚類效果較差,因此在聚類效果和時耗上還有提升空間。
僅基于方差選擇初始聚類中心的算法不依賴參數(shù)類型且復(fù)雜度較低,但該類方法以全局方差作為衡量數(shù)據(jù)密集度的指標值。全局方差計算采用來自于不同類的全部數(shù)據(jù)計算,因此,不同數(shù)據(jù)點全局方差大小比較意義并不明顯。本文定義局部方差,選擇某數(shù)據(jù)點附近的局部數(shù)據(jù)計算方差,基于局部方差最小優(yōu)化初始聚類中心,提出最小局部方差優(yōu)化初始聚類中心的K-means算法,以期縮短時耗、提升聚類效果。
1 算法改進
1.1 算法原理
選取初始聚類中心時需保證兩點:①K個初始聚類中心距離盡量遠;②每個初始中心附近數(shù)據(jù)點盡量密集。基于這些前提,文獻利用方差反映數(shù)據(jù)密集程度的特性,提出基于最小方差初始化聚類中心的K-means算法。全局方差定義為用所有數(shù)據(jù)信息反映某一數(shù)據(jù)點附近數(shù)據(jù)的密集程度,但由于這些數(shù)據(jù)屬于不同的類,因此該定義有不合理之處;文獻通過去掉每個選取到的聚類中心周圍平均距離內(nèi)的點,實現(xiàn)數(shù)據(jù)集更新,即認為數(shù)據(jù)集中每個點的地位等同,但該觀點并不客觀,當(dāng)中心選取到離群點時,以該方式更新數(shù)據(jù)集會產(chǎn)生很大問題。
為更確切地反映數(shù)據(jù)點附近的數(shù)據(jù)密集程度,本文重新定義數(shù)據(jù)點局部方差,并改變數(shù)據(jù)集更新方式,利用每個數(shù)據(jù)點附近的局部數(shù)據(jù)信息衡量該點數(shù)據(jù)密集度,提出最小局部方差優(yōu)化初始聚類中心的K-means算法。首先,計算所有數(shù)據(jù)點局部方差,選取局部方差最小的點作為第一個初始聚類中心,并計算距該點最遠的點與該點之間的距離dismax,半徑取dismax/K,刪除以該點為圓心的圓域內(nèi)的點,再計算每個數(shù)據(jù)點局部方差,選擇第二個初始聚類中心,第二次更新數(shù)據(jù)集時,選取的半徑為dismax/(K-1),循序往后,直到選擇到K個初始聚類中心。
1.2 基本概念
假設(shè)待聚類的含n個數(shù)據(jù)點的s維數(shù)據(jù)集W={x1,x2,…,xn},其中xi=(xi1,xi2,…,xis)T,將其劃分為K個類簇W1,W2,…,WK,K個類簇中心分別記為C1,C2,…,Ck,進行以下定義。
定義1 樣本數(shù)據(jù)xi,xj之間的歐氏距離為:
1.3 算法步驟
1.3.1 初始聚類中心選擇
(1)選取首個初始聚類中心時,k=l,根據(jù)定義1~4計算數(shù)據(jù)集中每一個樣本局部方差,在數(shù)據(jù)集w中選擇局部方差最小樣本x1將其作為第一個類簇初始聚類中心C1。令:
否則,得到K個初始聚類中心C1,C2,…,Ck,轉(zhuǎn)至初始劃分構(gòu)造流程。
(3)轉(zhuǎn)步驟(2)。
1.3.2 初始劃分構(gòu)造
(1)遍歷數(shù)據(jù),按照定義1定義的距離,將每個數(shù)據(jù)劃分到最近中心點所在的類中。
(2)計算每個類簇的坐標均值并作為新的中心點。
(3)根據(jù)定義4,計算誤差平方和E。
1.3.3 數(shù)據(jù)點再分配與聚類中心更新
(1)遍歷數(shù)據(jù),按照定義1,將每個數(shù)據(jù)劃分到最近中心點所在的類中。
(2)計算每個類簇的坐標均值,作為新的中心點。
(3)根據(jù)定義4,計算誤差平方和E'。如果|E'-E|<10-10,即聚類中心不再變化,則結(jié)束算法,輸出聚類結(jié)果;否則,令E=E,并轉(zhuǎn)至初始聚類中的選擇流程。
綜上所述,相較于傳統(tǒng)K-means算法,本文算法改變了選取初始聚類中心的方式,后續(xù)聚類過程相同。
2 聚類算法性能指標
(1)聚類誤差平方和。它是所有數(shù)據(jù)點到所屬類中心的距離平方和,通常作為迭代停止的準則。一般來說,聚類誤差平方和越小,聚類效果越好,聚類準確率越高。
(2)聚類時間。聚類算法運行時間越短,算法越好。
(3)聚類準確率。計算聚類準確率需知道數(shù)據(jù)點真實類型,聚類準確率越高,聚類效果越好。
(4)蘭德系數(shù)。蘭德系數(shù)定義式為:
其中n是數(shù)據(jù)集的數(shù)據(jù)點個數(shù),a表示在真實類中同類且在聚類結(jié)果中同類的數(shù)據(jù)對數(shù),b表示在真實類中異類、且在聚類結(jié)果中異類的數(shù)據(jù)對數(shù)。蘭德系數(shù)取值范圍為[0,1],越接近于l,聚類效果越好。
(5)調(diào)整蘭德系數(shù)。為在隨機產(chǎn)生聚類結(jié)果時使指標接近零,提出調(diào)整蘭德系數(shù)(Adjusted Rand Index)。設(shè)ui是聚類得到的類型,vj是真實類型,則對n個數(shù)據(jù)點的K類待聚類數(shù)據(jù)集如表l所示。
其中nij表示屬于ui且屬于vj的數(shù)據(jù)點個數(shù),則調(diào)整蘭德系數(shù)定義式為:
RI值通常較大,即便聚類效果較差,RI值也不會很小,ARI是RI的調(diào)整值,比RI更直觀,取值范圍為[-1,1],ARI越接近于1,聚類效果越好;反之ARI越小,聚類效果越差。
3 數(shù)據(jù)仿真實驗
為檢驗算法有效性,本文利用Matlab編程實現(xiàn)算法,與其它算法進行比較。目前3類改進方法只有第3類基于最小方差選擇初始聚類中心的算法不依賴參數(shù)選取且計算復(fù)雜度不高、聚類效果良好。該類算法特點基本一致,因此本文僅與傳統(tǒng)K-mean算法及文獻算法比較聚類結(jié)果。其中,文獻的算法與本文算法消除了K-means算法隨機性,每次聚類結(jié)果固定;傳統(tǒng)K-means聚類過程是隨機的,同一數(shù)據(jù)集確定的分類數(shù)K的每次聚類結(jié)果不盡相同。
若以聚類誤差平方和大小為衡量聚類優(yōu)劣標準,對同一組數(shù)據(jù)集確定的分類數(shù)K多次執(zhí)行傳統(tǒng)K-means算法,基本上均可得到一組最好的聚類結(jié)果和一組最差的聚類結(jié)果,大多數(shù)改進方法得到的聚類結(jié)果介于這兩組聚類結(jié)果之間。因此利用這兩組結(jié)果比較本文算法和文獻算法的聚類效果。本文對每個數(shù)據(jù)集執(zhí)行100次傳統(tǒng)K-means算法,得到一組最好的結(jié)果和一組最差的結(jié)果,與執(zhí)行100次傳統(tǒng)K-means算法結(jié)果的平均值進行對比。
3.1 UCI數(shù)據(jù)集實驗及結(jié)果比較
本文選取10組不同的UCI數(shù)據(jù)集進行仿真實驗,相關(guān)數(shù)據(jù)集信息如表2所示。
分別用文獻的算法、本文算法與傳統(tǒng)K-means算法計算得到聚類誤差平方和,如表3所示,聚類時間如表4所示。
由表3、表4可以看出在10個UCI數(shù)據(jù)集中,本文算法有9組聚類誤差平方和小于K-means算法平均值,接近于傳統(tǒng)K-means算法的最好情形,其中l(wèi)組Soybean-small優(yōu)于傳統(tǒng)算法最優(yōu)情形,只有l(wèi)組Wine數(shù)據(jù)集聚類結(jié)果較差;而文獻的算法有3組數(shù)據(jù)集Haberman、New thyroid和Balance-scale聚類結(jié)果較差,其余均接近于傳統(tǒng)算法最好情形;傳統(tǒng)K-means算法聚類時間最短,文獻的算法聚類時間最長,本文算法聚類時間介于兩者之間,與文獻的算法聚類時間基本相差一個數(shù)量級。
計算聚類準確率如圖1所示。
計算RI與ARI,結(jié)果如圖2和圖3所示。
首先通過聚類準確率比較,可以看到本文算法聚類準確率大多與傳統(tǒng)算法最好情形一致,其中Soybean-small聚類準確率甚至略高于傳統(tǒng)算法最好情形,New-thyroid和Balance-sacle聚類準確率介于傳統(tǒng)算法最好、最差之間,與較好情形相差不大,只有1組Wine數(shù)據(jù)集聚類準確率較低;文獻算法聚類準確率較低的數(shù)據(jù)集較多,包括New-thyroid、Balance-scale等。數(shù)據(jù)集Haberman聚類誤差平方和較小時聚類準確率反而較低,這可能是因為該數(shù)據(jù)集分類不適用本文采用的相似性準則,因此該組數(shù)據(jù)不作參考。
其次是RI值和ARI值的比較,這兩個值相對大小基本一致,綜合來看本文算法對數(shù)據(jù)集Wine、New thyroid聚類的RI和ARI值較小;文獻算法對數(shù)據(jù)集New-thy.roid、Balance-scale的RI和ARI值較小,其余數(shù)據(jù)集兩個算法聚類得到的RI和ARI值較大,接近于傳統(tǒng)算法最好情形。
3.2 人工數(shù)據(jù)集實驗及結(jié)果比較
分別用文獻的算法、本文算法、傳統(tǒng)K-means算法對各組數(shù)據(jù)進行聚類,其聚類誤差平方和與聚類時間如表6、表7所示。
由表6比較3種算法的誤差平方和,本文算法只有兩組較差,即噪聲比率10%和噪聲比率25%的數(shù)據(jù)集,其余組誤差平方和小于100次傳統(tǒng)算法平均值,且基本與傳統(tǒng)算法最好情形相同;而文獻算法對噪聲比率5%、20%、25%的數(shù)據(jù)集聚類結(jié)果較差。兩種算法均對噪聲有很強的免疫性,高噪聲比率不影響聚類效果。
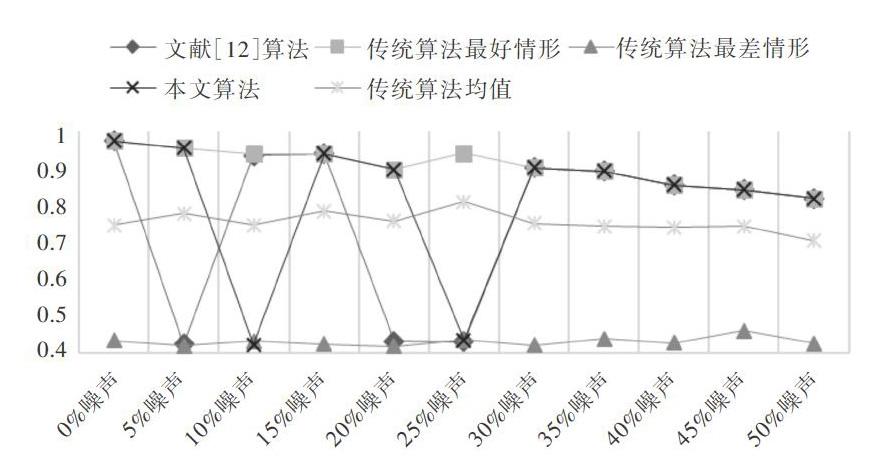
聚類時間與UCI數(shù)據(jù)集結(jié)果一致,本文算法聚類時間介于文獻算法與傳統(tǒng)K-means算法之間,且聚類時間小于文獻算法的1/10。進一步計算3種算法聚類準確率、蘭德系數(shù)RI、調(diào)整蘭德系數(shù)ARI,如圖4-圖6所示。
聚類準確率、RI值、ARI值相對大小基本一致,11組數(shù)據(jù)中,本文算法聚類結(jié)果多數(shù)較好,有9組數(shù)據(jù)聚類準確率達到90%以上,有兩組較差,分別是10%噪聲組和25%噪聲組,其聚類準確率只有50%左右;文獻算法聚類結(jié)果有3組較差,分別是5%噪聲組、20%噪聲組、25%噪聲組,其余組數(shù)據(jù)聚類結(jié)果良好。
同時實驗發(fā)現(xiàn),聚類準確率、RI值與ARI值均隨噪聲比率的增大而減小,但基本保持很高的水平,說明本文算法對數(shù)據(jù)噪聲有很強的免疫性。
綜上所述,本文算法較文獻算法的聚類效果有一定提高,大部分數(shù)據(jù)集的聚類結(jié)果接近傳統(tǒng)K-means算法的最好情形,絕大部分數(shù)據(jù)集聚類效果好于傳統(tǒng)K-means算法平均效果,且對噪聲數(shù)據(jù)有很強的免疫性。同時,在聚類時間方面,本文算法雖不及傳統(tǒng)K-means算法,但與文獻算法相比有大幅改善。
4 結(jié)語
針對傳統(tǒng)K-means算法隨機性引起聚類效果不穩(wěn)定的缺陷,本文提出了一種基于最小局部方差初始化聚類中心的K-means改進算法。UCI數(shù)據(jù)集和人工數(shù)據(jù)集實驗表明,本文算法較文獻算法更快、更有效,與傳統(tǒng)K-means算法相比,不僅提高了算法穩(wěn)定性和平均聚類準確率,而且對噪聲數(shù)據(jù)有很強的免疫性、魯棒性及較快的聚類速度,是一種高效、穩(wěn)定、準確的K-means改進算法。但同時本文算法對個別數(shù)據(jù)集聚類效果不理想,下一步將考慮結(jié)合樣本空間密度進一步擴大算法適用范圍。
