一種基于CNN/CTC的端到端普通話語音識別方法
2020-07-27 12:10:17潘粵成劉卓潘文豪蔡典侖韋政松
現代信息科技 2020年5期
潘粵成 劉卓 潘文豪 蔡典侖 韋政松

摘? 要:為了實現離線狀態較高正確率的中文普通話語音識別,提出一種基于深度全卷積神經網絡CNN表征的語音識別系統的聲學模型,將頻譜圖作為輸入,在模型結構上參考了VGG模型。在輸出端,該模型可以與連接時序分類完美結合,從而實現整個模型的端到端訓練,將聲波信號轉換成普通話拼音序列。語言模型則采用最大熵馬爾可夫模型,將拼音序列轉換為中文文本。實驗表明,此算法在測試集上已經獲得了80.82%的正確率。
關鍵詞:卷積神經網絡;中文語音識別;連接時序分類;端到端系統
中圖分類號:TN912.34;TP399 ? ? ?文獻標識碼:A 文章編號:2096-4706(2020)05-0065-04
An End-to-End Mandarin Speech Recognition Method Based on CNN/CTC
PAN Yuecheng1,LIU Zhuo1,PAN Wenhao1,CAI Dianlun2,WEI Zhengsong1
(1.School of Automation Science and Engineering,South China University of Technology,Guangzhou? 510641,China;
2.School of Mechanical and Automotive Engineering,South China University of Technology,Guangzhou? 510641,China)
Abstract:In order to achieve Mandarin speech recognition with higher accuracy in offline state,we come up with an acoustic model of a speech recognition system based on deep full convolutional neural network(CNN). We choose the spectrogram of acoustic signals as input. As for the structure of the model,we refer the VGG model. At the output end,the model can be perfectly combined with the connectionist temporal classification (CTC). We realize the end-to-end training of the entire model using this method,and the acoustic signal is directly converted into a Mandarin Pinyin sequence. Our language model uses the Maximum Entropy Markov Model to convert Pinyin sequences into Chinese text. Our experiments show that this algorithm has achieved 80.82% accuracy on our test set.
Keywords:convolutional neural network;Chinese speech recognition;connectionist temporal classification;end-to-end system
0? 引? 言
近些年,深度學習在人工智能領域取得了無可替代的地位,深度神經網絡逐漸替代了傳統的GMM-HMM模型。為了實現離線狀態正確率較高的中文普通話語音識別,本文提出一種基于CNN表征的語音識別系統的聲學模型,采用CNN/CTC的方法,此算法在測試集上已經獲得了80.82%的正確率。
1? 項目背景
語音識別技術,是讓機器通過語音識別把語音信號轉化為相應的文本信號或者命令的技術[1]。近些年,深度學習在人工智能領域迅速發展,對語音識別也產生了深遠影響,而且已經初步應用于車載系統、手機、搜索引擎、電子商務、機器人等多個領域,深層的神經網絡逐漸替代了傳統的GMM-HMM模型[2]。傳統的語音識別聲學模型通常采用梅爾頻率倒譜系數特征(MFCC,Mel Frequency Cepstrum Coefficient)對GMM-HMM建模,但是MFCC特征具有短時性,容易受環境中噪聲的影響,魯棒性較差,還容易忽略幀間的相關性[3]。
對語音識別而言,傳統的模板匹配方法、統計學習方法已趨成熟甚至出現了瓶頸,而利用神經網絡進行語音識別因其巨大優勢而方興未艾[4]。最近人工智能成為熱門話題,神經網絡的研究得到飛速發展,如何用神經網絡進行語音識別的問題得到一定程度上的解決。常用的深度置信神經網絡(DBN,Deep Belief Network)在語音識別中得到了廣泛的應用[5],在DBN網絡后增加一個輸出層,則形成一個深度神經網絡(DNN,Deep Neural Networks),基于HMM-DNN模型的語音識別系統在識別正確率上較GMM-HMM模型取得了很大的提高[6,7],但基于HMM-DNN模型的語音識別是由聲學模型、語言模型和字典三個模塊組成的,需要語言學知識,導致對一種新的語言搭建識別系統非常困難。卷積神經網絡(CNN,Convolutional Neural Network)提供了一種平移不變性卷積,可以對語音多樣性進行良好的改善,提高搭建語音識別系統的效率。
Graves提出連接時序分類技術CTC(Connectionist Temporal Classification)[8]。CTC是一種用于序列建模的工具,訓練樣本無需對齊,其核心是定義了特殊的目標函數。
文獻[5]提出了一種基于CNN的語音識別方法,本文基于華南理工大學國家級創新創業項目“自學習語音交互系統的研究與開發”的研究,在使用CNN的基礎上在輸出端加入連接時序分類,從而實現整個模型的端到端訓練,在很大程度上降低了構建語音識別系統的難度。
2? 基于CNN/CTC的端到端普通話語音識別方法
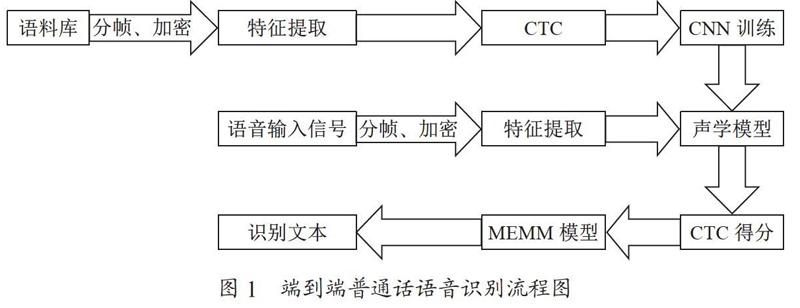
本文的端到端普通話語音識別方法如圖1所示,主要有以下幾個步驟:
(1)特征提取,將普通的wav語音信號通過分幀、加窗等操作轉換為卷積神經網絡需要的二維頻譜圖像信號,即語音頻譜圖;
(2)聲學模型訓練,基于Keras和TensorFlow兩種網絡模型進行訓練;
(3)CTC解碼,在聲學模型輸出中,往往包含了大量連續并且重復的符號,為此,我們需要將連續重復的符號合并為同一個符號,然后再除去靜音分隔標記符,最終得到實際的拼音符號序列;
(4)語言模型轉換,使用MEMM模型,將拼音符號轉換成最終的文本并輸出。
3? VGG網絡結構
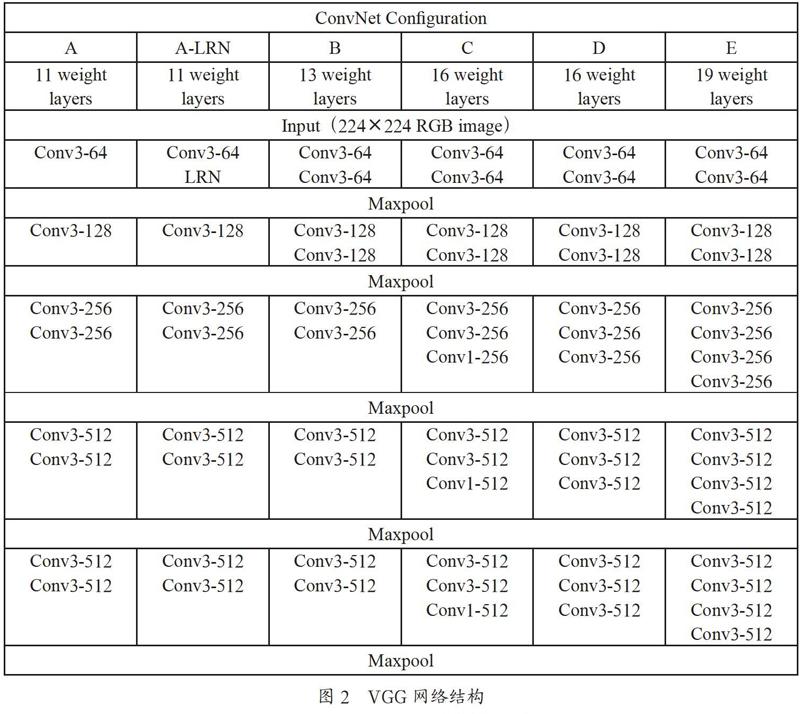
本文在模型結構上參考了VGG模型,VGG網絡結構相比之前的RNN有著更強的魯棒性,并且表達能力非常強,可以看到很長的歷史和未來信息。
VGG包括VGG16和VGG19,它們的網絡深度不同,如圖2所示。
4? 連接時序分類
連接時序分類是在自動語音識別技術中計算損失函數的一種方法。與傳統的聲學模型訓練比較,CTC使用的是端到端訓練,并不需要輸出文字與輸入語音在時間上對齊,只需要給定輸入端和輸出端的序列,CTC輸出的就是序列預測的概率,這種方式在很大程度上降低了構建語音識別系統的難度。其結構如圖3所示。
4.1? 前向算法
前向變量為α(t,u),表示t時刻在節點u的前向概率值,其中u∈[1,2U+1]。
初始化:
α(1,1)=
α(1,2)=
α(1,u)=0,?u>2
遞推關系:
α(t,u)=
其中,f(u)=
4.2? 后向算法
初始化:
β(T,U′)=1
β(T,U′-1)=1
β(T,u)=0,?u α(1,u)=0,?u>2 遞推關系: β(t,u)= 其中,f(u)= 4.3? 取對數 ln(a+b)=lna+ln(1+elnb-lna) 4.4? 最大似然函數 CTC的損失函數使用最大似然函數: L(S)= L(x,z)=-lnp(z|x) 根據前后向變量,可求得: p(z|x)= 從而得到: L(x,z)= 4.5? BP訓練過程 表示t時刻輸出k的概率, 表示t時刻對應輸出節點k在做softmax轉換之前的值: 考慮:t時刻經過k節點的路徑。 其中B(z,k)表示節點為k的集合。 考慮:α(t,u)β(t,u)=, 其中X(t,u)表示所有在t時刻經過節點u的路徑。 則: 得到損失函數對? 的偏導數: 同時可以得到損失函數對? 的偏導數: 后續可以使用BPTT算法得到損失函數對神經網絡參數的偏導[9]。 5? 最大熵馬爾可夫模型 最大熵模型是在已經先驗分布的前提下求解特征函數f(x,y)的最優概率分布P(y|x)。模型如圖4所示。 5.1? HMM模型 HMM模型表達式如下: P(X)= 其中,Y為狀態序列,X為觀測序列,p(yi|yi-1)為從yi-1到yi的條件概率分布,p(xi|yi)為狀態yi的輸出觀測概率,初始概率為P0(y)。顯然,HMM依賴已知的概率分布和歷史經驗來實現決策,但實際上能提供的訓練數據是少量且稀疏的,我們不可能知道所有的數據分布情況。所以需要接下來介紹的MEMM來解決在數據稀疏的條件下估計未知x,y的條件概率這個問題。 5.2? MEMM模型 MEMM模型表達式如下: i=1,2,…,T MEMM用p(yi|yi-1,xi)來代替HMM中的p(yi|yi-1)和p(xi|yi),根據先前狀態和當前觀測預測當前狀態。每個分布函數pyi-1(yi|xi)都是一個服從最大熵分布的指數模型。MEMM在限定條件下求解最優條件概率,在訓練過程中使特征多項式fi(x,y)收斂于λi,并求解此時的xi與yi-1的正則化因子,在此解碼過程中直接求得條件概率p(yi|yi-1,xi)。[10]
6? 結果及分析
為了檢驗基于CNN/CTC的端到端普通話語音識別方法的有效性,我們使用此方法訓練出聲學模型,實驗中使用了清華大學THCHS-30中文語音數據集、Free ST Chinese Mandarin Corpus數據集、AISHELL-1開源版數據集、Primewords Chinese Corpus Set 1數據集、aidatatang_200zh數據集、MagicData數據集。其中訓練語音625 000句,驗證集語音2 000句。由于連續語音識別結果為一連串的詞語,所以我們可以使用詞錯誤率(Word error rate,WER)作為一個評測標準,詞錯誤率與系統性能成反比。
本實驗使用的CNN網絡輸入層為200維的特征值序列,一條語音數據最大長度為1 600,約為16 s;隱藏層包括10個卷積層、5個池化層、1個Reshape層、2個全連接層,卷積核大小為3×3,池化窗口大小為2;輸出層維度為神經網絡最終輸出的每一個字符向量維度的大小,激活函數使用softmax;CTC層使用loss作為損失函數,實現連接性時序多輸出。
從表1中數據可以得出,文中基于CNN/CTC的端到端普通話語音識別方法在驗證集上詞錯率為19.18%。文獻[11]中給出的基于卷積神經網絡算法的語音識別算法在THCHS30數據庫上測試錯率在22.19%~23.68%之間,相比之下,本文加入CTC層后詞錯誤率下降3.01%~4.50%左右。
下面來看基于CNN/CTC的端到端普通話語音識別方法的訓練過程。本實驗設置迭代輪數epoch為50,每500步保存一次模型,每次訓練16個數據。圖5為此方法的訓練收斂曲線。
可見,訓練loss最終收斂在20%左右。
驗證數據的收斂曲線
7? 結? 論
通過在CNN的基礎上加入CTC層,大大減少了構建語音識別系統的難度,為實現離線語音識別提供了一種方法,其語音識別正確率達到80.82%。在今后的工作中,擬嘗試加入針對說話人進行識別的功能,做一個說話人識別系統,以解決語音識別系統應用在很多場景時的問題。
參考文獻:
[1] 張德良.深度神經網絡在中文語音識別系統中的實現 [D].北京:北京交通大學,2015.
[2] 林俊潛.基于神經網絡和小波變換的語音識別系統研究 [D].廣州:廣東工業大學,2013.
[3] 鄭文秀,趙峻毅,文心怡,等.一種基于瓶頸復合特征的聲學模型建立方法 [J/OL].計算機工程:1-6(2019-12-16).https://doi.org/10.19678/j.issn.1000-3428.0056278.
[4] 唐美麗,胡瓊,馬廷淮.基于循環神經網絡的語音識別研究 [J].現代電子技術,2019,42(14):152-156.
[5] 王嘉偉.基于卷積神經網絡的語音識別研究 [J].科學技術創新,2019(31):71-73.
[6] DAHL G E,YU D,DENG L,et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition [J].IEEE Transactions on Audio,Speech and Language Processing,2012,20(1):30-42.
[7] SEIDE F,LI G,YU D. Conversational speech transcription using context-dependent deep neural networks [C]//12th Annual Conference of the International Speech Communication Association,2011.
[8] GRAVES A,FERN?NDEZ S,GOMEZ F. Connectionist temporal classification:Labelling unsegmented sequence data with recurrent neural networks [C]// Machine Learning,Proceedings of the Twenty-Third International Conference (ICML 2006),2006:369-376.
[9] GRAVES A. Supervised Sequence Labelling with Recurrent Neural Networks [M]. Berlin,Heidelberg:Springer Berlin Heidelberg,2012:52-81.
[10] KLINGER R,TOMANEK K. Classical Probabilistic Models and Conditional Random Fields [J].Algorithm Engineering Report,2007,2(13):5-6
[11] 楊洋,汪毓鐸.基于改進卷積神經網絡算法的語音識別 [J].應用聲學,2018,37(6):940-946.
作者簡介:潘粵成(1998-),男,漢族,廣西融水人,就讀于自動化專業,本科在讀,研究方向:自動語音識別。
