QJoin:質量驅動的亂序數據流連接處理技術*
2020-08-02 06:34:04魏星貝李陶深
廣西科學 2020年3期
魏星貝,李陶深,2**,許 嘉,2 ,呂 品,2 ,楊 寧
(1.廣西大學計算機與電子信息學院,廣西南寧 530004;2.廣西高校并行與分布式計算技術重點實驗室,廣西南寧 530004)
0 引言
近年來,隨著數據采集設備的普及,以傳感器網絡[1]、金融服務[2]、網絡監控[3]、航空航天以及氣候監測為代表的重要應用源源不斷地產生數據流,這些數據流亟待分析處理。數據流的產生具有無限性、連續性和快速性,因此數據流的分析處理要求及時性,以保證分析結果的時效性。一條數據流S可以形式化表示為S={s1,s2,s3,…,si,…},其中si表示第i個到達后端分析處理系統的流元組,si.v表示該流元組的值,si.ts表示該流元組的產生時間,稱為該流元組的時間戳。對數據流的分析處理,通常是基于流元組的時間戳語義進行的。例如,手機導航跟蹤用戶移動設備地理位置數據流,就是基于時間順序的最新元組信息,給用戶實時推薦行進的路線。但是,由于網絡延遲、處理器的并行操作或是異步數據流合并等原因[4],使得數據流上流元組不能按其時間戳的先后順序到達后端分析處理系統,導致數據流出現亂序現象。例如在高速公路上,當手機導航上傳數據中心的數據流出現亂序現象時,定位信息會大量遺漏丟失,產生異常跳動的現象,破壞了連接結果的完整性,影響了實時推薦的路線引導建議的準確性。
為了減少亂序的影響,提升連接結果完整性,人們提出了基于緩存的亂序數據流處理方法,即緩存一定已到達的流元組,等待遲來的流元組,換取結果質量的提升。其中,Abadi等[5]提出的K-slack方法就是基于緩存的亂序數據流處理方法的典型代表。該方法通常用一個大小為K時間單位的緩存來存儲已到達的流元組,即每個流元組到達系統后還需等待K個時間單位才能被釋放以繼續處理,釋放按緩存內流元組的時間戳從小至大依次進行。在K-slack方法中,到達的流元組需等待K個時間單位后才被分析處理,有效避免了延遲時間小于K個時間單位的遲到元組對結果質量帶來的負面影響,但仍然會丟失延遲時間大于K個時間單位的遲到元組的連接結果。之后,Babu等[6]和Mutschler等[7]進一步改進了K-slack方法,使緩存區參數K隨數據流延遲大小變化進行動態調整,直到K值等于當前最大的延遲,從而優化了緩存的大小,降低了對遲到流元組的平均等待時間,提高了連接處理的執行效率。近年,Ji等[8-10]基于用戶指定的結果質量指標優化參數K的取值:將連接結果質量定義為連接結果集的召回率,給定用戶指定的結果質量指標,基于連接處理過程中收集的統計數據優化和調整參數K的取值。由于參數K和流元組到達系統后的等待時間相關,該方法在保證結果質量指標前提下盡可能降低了對遲到流元組的平均等待時間。上述方法雖然保證了連接結果在時間域上的有序性,但還是增大了流元組的連接處理時延。楊寧等[11]研究設計一種混合嵌入分布式流處理模塊和分布式批處理模塊的亂序數據流分布式聚合查詢處理技術,該技術通過限制自適應地優化流處理模塊所用的緩沖區大小來降低流處理的查詢處理延遲;利用存儲的歷史流數據,以批處理的方式實現對極其晚到流元組的查詢處理,進而保障聚合查詢結果的最終正確性。
除了K-slack方法以外,人們在數據流亂序處理方法中還運用了基于標點元組的方法和基于推測的方法。基于標點元組的方法是在數據流中插入標志時間進度的標點元組,標點元組后到來的流元組時間戳都比標點元組時間戳大,以此避免錯過對一些遲到元組的處理。例如,心跳機制[12]以及部分有序保證機制[13-14]都是基于標點元組的方法。Mencagli等[15]以多核系統為背景,研究解決亂序流式大數據上的連續偏好查詢(例如Top-k查詢和Skyline查詢)的并行執行問題,采用基于K-slack的緩存技術產生標點元組,并基于標點元組確定亂序數據流發送進度。在基于標點元組的方法中,如果標點元組遲遲不到,那么可能會使得窗口等待閉合的時間延長,不利于實時性要求較高的連接處理操作,嚴重影響查詢處理的效率。基于推測的方法是一種激進的處理方法[16-17],該方法以假設數據流元組是有序到達的為前提,先激進地處理已到達系統的流元組,輸出處理結果,直到后續遲到流元組的到來。僅當確認之前輸出結果不正確時,該方法才進行結果撤回,利用存儲的歷史數據重新計算和輸出結果。基于推測的方法加快了亂序數據流的處理效率,常用于處理亂序事件流,實現對復合事件的實時檢測,但由于需存儲大量的歷史數據,增大了內存開銷,且遲到元組頻繁出現可能導致錯誤結果連續撤回,增大連接開銷。
一些研究人員從時間維度、外形輪廓和結構變化上的相似性等3個角度,對基于時間關聯性的數據流相似性進行研究。Aghabozorgi等[18]利用大量數據流的統計量對數據流進行宏觀上的比對,聚類比較了數據流的不同階段或不同的數據流之間相似性。Mukhoti等[19]對數據流提取模糊關聯模式用以預測事件。Jacques-Silva等[20]討論了Facebook如何基于歷史數據構建分布式計算環境下亂序流式大數據的流元組延遲估計模型,并基于該估計模型和用戶對系統處理單元的處理延遲的需求生成一定精度的標點元組,從而權衡單處理單元的處理延遲和連接查詢的結果精度這兩個重要指標。朱睿等[21]針對數據流上的連續Top-k查詢設計了哈希過濾器,可以有效過濾不可能成為查詢結果的亂序流元組,從而降低對亂序流元組的等待時間。許嘉等[22]提出了一種基于EMD距離的數據流分布式相似性連接技術(EMD-DDSJ),該技術基于數據局部性特征增強了連接算法對不相似直方圖元組對間EMD計算的過濾性能,提高了各連接計算節點的執行效率;通過一種基于反饋的負載均衡策略,有效提升EMD-DDSJ技術的整體執行性能。
為了降低亂序數據流的平均連接處理時延,滿足用戶及時性需求[23],本研究提出了質量驅動的亂序數據流連接處理技術(簡稱QJoin)。該技術將通過緩存一定量的歷史數據并采用對稱連接的策略實現對到達系統流元組的即時處理并輸出連接結果,以期顯著降低流元組的平均處理時延,提高連接處理的速率;基于用戶指定的結果質量指標來優化內存使用量,降低平均內存開銷。最后,基于真實數據集對QJoin技術進行實驗驗證,以說明該技術的有效性。
1 方法描述
1.1 QJoin的設計思想
在數據流的連接操作中,用戶非常關注處理的實時性和準確性,因此必須考慮數據流亂序問題的處理。在處理數據流亂序問題上,基于緩存的方法是最常見的處理方法之一。經研究分析,現有的基于緩存處理亂序方法多以最優結果完整性或最優處理效率為目的,以數據流的整個歷史的最大延遲或者平均延遲作為參考,對緩存大小進行調整,沒有考慮數據流的時間關聯性,忽略了臨近時間段的延遲變化對緩存的影響。現有的方法很少從用戶的角度來綜合考慮結果完整性、存儲開銷、處理效率的有效折中,使得晚到的元組到來后不能即時進行連接處理,增加了數據流平均連接處理時延,導致處理效率不高。
針對以上問題,本研究提出了一種基于質量驅動的亂序數據流連接處理技術QJoin的框架(圖1)。QJoin的設計思想:關注數據流的及時性處理需求,特別是晚到數據流的連接與調度,將基于緩存的方法和對稱連接方法[24]有機結合起來,實現對亂序數據流流元組的即時處理。其技術特點在于:綜合權衡了用戶結果質量與緩存開銷,考慮了數據流上的時間關聯性,基于臨近周期連接處理過程收集統計的數據,優化緩存的大小,更好地實現對數據流的及時性處理。
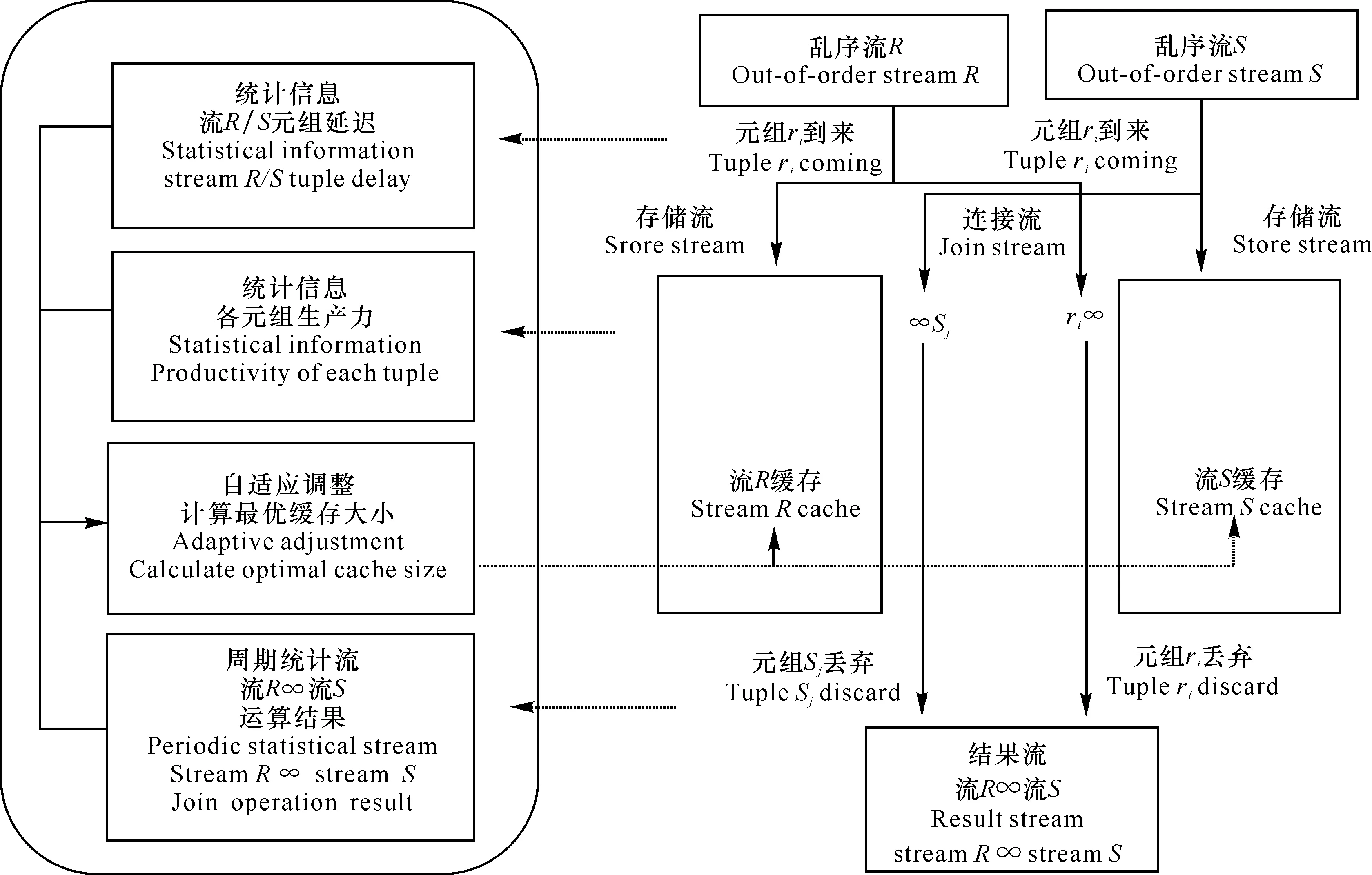
圖1 QJoin的技術框架Fig.1 Technique framework of QJoin
QJoin采取了以下的技術處理手段:
(1)每條數據流的流元組到達系統后,進入存儲流實現在內存中的緩存,同時進入連接流實現和另一條數據流在內存中緩存元組之間的連接處理。以圖1中亂序流R的元組ri(i=1,2,…)為例,當ri到來時,同時進行兩個工作:一是進入存儲流完成在流R緩存中的存儲;二是進入連接流實現和數據流S緩存元組之間的連接處理,直到生成結果流,從連接流中丟棄。亂序流S的元組sj(j=1,2,…)到來時,操作是類似的。
(2)存儲流和連接流對于每個流元組的處理都是即時的。每條流在內存中的緩存都運行一定的過期清理策略,從緩存中刪除過期的流元組。
(3)在進行對稱連接處理的過程中,QJoin技術不斷基于臨近的周期的歷史元組計算用戶指定質量指標,收集統計信息進行估計結果質量,統計信息包括如圖1中各元組延遲和生產力、各周期結果數目,在滿足用戶指定的結果質量的同時,盡可能降低對歷史數據的內存緩存量,從而優化緩存的大小。
1.2 對稱連接方法
QJoin技術采用對稱連接的方式處理亂序數據流連接,同時緩存一定量的歷史數據。假設緩存區大小設定為可以容納住所有需要連接的元組,具體的處理步驟如下:
Step 1:流元組r∈R到達系統后,由存儲流實現在內存中的流R緩存區的存儲,同時由連接流即刻完成r和流S緩存區中落在滑動窗口內的流元組的連接,輸出連接結果,連接流上的元組r丟棄;
Step 2:對于到達系統的流元組s∈S,同樣由連接流即刻完成s和對面流R緩存區中落在滑動窗口內的流元組的連接,輸出連接結果,連接流上的元組s丟棄;
Step 3:流R緩存區和流S緩存區中,當元組數目超出緩存區的大小就會被移出緩存區,進行丟棄。
數據流的延遲定義為當前流上到來的最大時間戳與遲到元組時間戳的差,QJoin利用延遲統計量d,定時將流R緩存區和流S緩存區中滿足x.ts≤T-d的流元組清除,其中x為R流或S流的流元組,T為R流和S流上最大時間戳中的最小值,標記為當前時刻。QJoin技術在對稱連接方法的基礎上,考慮到流上延遲分布與待連接流緩存的關系,元組延遲與結果質量存在關聯性,滿足用戶指定結果質量的同時,自適應調整元組過期,優化內存使用量。
由于在對稱連接中,只要連接流上元組到來就可以與對面的緩存內元組即時連接,所以即使是因存在亂序問題而導致元組遲到的現象,只要其待連接的元組還在對面緩存區中,就可以有效地完成連接操作,保證了處理的及時性和結果的完整性。因此,緩存區的大小設定受到對面連接流上遲到元組的影響,需要儲存這些遲到元組待連接的元組。
1.3 亂序數據流連接結果質量
QJoin技術中,使用結果召回率作為處理亂序數據流的質量標準。結果召回率是實際連接得到的結果數目占本應該連接得到的理想結果數目的百分比[25]。QJoin技術考慮用戶對連接處理結果的及時性需求,允許用戶指定一個用戶周期P,以P周期的結果召回率來替代整個流歷史的結果召回率。同時,由于數據流元組間的時間關聯性,用最新的P周期歷史來計算結果召回率,可敏銳地捕捉到結果召回率的變化,以幫助后續的亂序流處理操作得到更好的結果質量。
在QJoin中,假設用戶給定了周期P,則周期P內實際的流連接質量為召回率QP:
(1)
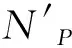
QJoin中用戶可以指定結果質量(召回率),表示為Quser,要求P周期內求得的召回率QP滿足:QP≥Quser。
1.4 基于用戶質量的緩存自適應
1.4.1 緩存自適應調整
在QJoin中,需要緩存足夠大,能包含窗口內所有應到來的元組時,必須考慮到延遲元組的影響:需緩存的元組包括落在窗內的元組和窗外的遲到元組,即緩存大小與窗內元組和元組延遲分布有關。QJoin技術在用戶指定質量要求下,自適應調整緩存大小,方法如下:使用一個大小為周期P的大滑動窗口,滑動步長為自適應周期L,從流上第一個P周期結束時刻起,利用最近的L周期歷史元組特性,進行下一個L周期的緩存估計設置,即當大窗口每滑動一次,前進L周期,基于最近的L周期歷史進行一次緩存自適應調整,要求L 在每一次緩存自適應調整中,需要滿足目標函數。設R流與S流的占用的緩存分別為x、y,求出對應的(x,y),使流占用的總緩存M(x,y)盡可能小的目標函數如下: minM(x,y)=x+y, s.t.QL(x,y)≥QL, 0≤x≤X, 0≤y≤Y, (2) 其中,M(x,y)為總緩存大小,是R流緩存大小x與S流緩存大小y的和。當數據流的流速一定時,x與y受存放時間的影響。存放時間就是元組過期前在緩存中的時間,決定元組何時過期移出內存,受元組的延遲d與窗口w大小影響。當窗口大小固定,存放時間的變動只受元組的延遲影響,保存時間增加d時間單位時,延遲為d的元組就可進入存儲流參與連接,因此設流R的流速為Vr,緩存x與R流延遲dx的關系可以表示為x=(dx+w)×Vr,同理,流S的流速為Vs,緩存y與S流延遲dy的關系可以表示為y=(dy+w)×Vs,緩存問題可以轉化為時間問題。 QL(x,y)為最近L周期歷史下,R流緩存大小設置為x與S流緩存大小設置為y時的結果質量,QL為基于P周期內用戶要求質量求得的L周期的質量期望(具體求解見1.4.2),X為受R流當前最大延遲與窗口大小影響的最大緩存,Y為S流受當前最大延遲與窗口影響的最大緩存。 1.4.2L周期用戶質量期望 (3) 1.4.3L周期受緩存影響的質量QL(x,y) 當數據流的流速V一定時,L階段受緩存容量影響的實際質量QL(x,y)轉化為受R流延遲dx與S流延遲dy影響的質量QL(dx,dy): (4) 其中,Nprod(dx,dy)為L階段內受R流延遲dx與S流延遲dy影響產生的結果數目,NL為L周期理想狀態應該產生的結果數目。Nprod(dx,dy)受到選擇度sel(dx,dy)與交叉連接的結果數N×(dx,dy)的影響,計算公式為 Nprod(dx,dy)=sel(dx,dy)×N×(dx,dy)。 (5) 下面分別給出L階段內交叉連接數Nx(dx,dy),選擇度sel(dx,dy)的求解過程。 1)Nx(dx,dy)的求解 L時間段交叉連接數目,是L時間段內到來的R流元組與其對應的S流窗內所有元組的連接數Nx(dy)和此時S流元組與其對應的R流窗內元組的連接數Nx(dx)的和。交叉連接數Nx(dx)的求解方式與交叉連接數Nx(dy)的求解方式類似,這里以流R的交叉連接數Nx(dx)求解為例。 設窗口大小為w,對于任意輸入元組r∈R,只有對應的S流元組s滿足|r.ts-s.ts|≤w時,才能進行連接,則對元組r而言,其交叉連接數是S流窗內元組數目|W′s|。因此L周期內,若已知數據流R的平均流速Vr,可求輸入的R流元組數目,對每個R流元組對應的S流窗內元組數,可求出流R的L階段交叉連接數Nx(dy): N×(dy)=Vr×L×|W′s|, (6) 其中,|W′s|受延遲dy影響,由實際情況可知,緩存越大,窗口內遲到元組被連接上的數目越多,然而緩存中輸入流元組越新的地方,元組遲到的可能性越大,因此通過對窗口w進一步切割,設置基礎窗b[21]來計算受遲到元組影響的窗口內元組數目。 為了更清晰地描述遲到元組對窗口內元組的影響,需先求出遲到元組t的延遲分布特性。設隨機變量D表示元組粗粒度的延遲,g表示實際的延遲粒度,當delay(t)∈[0,g],令D=0;當delay(t)∈(g,2g],令D=1;當delay(t)∈(2g,3g],令D=2;余下的依次類推。設fD(d)為隨機變量D的概率密度,表示為fD(d)=P[D=d],d=1,2,3,…,是延遲為D=d的元組出現的概率。設基礎窗大小為b時間單位,將大小為w的窗口被分成n個小窗口,以S流窗舉例,S流窗內元組數目相當于n個小窗口內元組數目的和,每個小窗口的元組數目W′s是由平均流速VS和基礎窗大小b及落入到基礎窗的元組概率的積決定的,計算公式如下: (7) L周期的本來應該產生的結果數NL同樣是選擇度sel與交叉連接數N×的積,計算公式如下: NL=sel×N×, (8) 其中,交叉連接數N×表示在最理想狀態,當緩存能包含所有遲到元組的情形下,可能得到的交叉連接數N×,選擇度sel同樣放在后面講具體細節。對L階段內交叉連接結果數N×: N×=N×(Maxdx)+N×(Maxdy), (9) 其中,Maxdx表示為在R流上最大的延遲,Maxdy表示為S流上最大的延遲,N×(Maxdy)和N×(Maxdx)分別是理想狀態下R流與S流交叉連接數目,求解方式類似。以流R的交叉連接數目N×(Maxdy)為例,設窗口大小為w,若已知數據流R的平均流速Vr,可求出在L周期輸入的R流元組數目,每個R流元組對應的S流窗內元組數在理想狀態下包括所有實際落在當前窗口內的元組與遲到元組,因此L階段內流R的交叉連接數目N×(Maxdy)表示為 N×(Maxdy)=Vs×L×Vr×(w+Maxdy)。 (10) 2)sel(dx,dy)的求解 選擇度是符合相似度函數的實際連接次數占所有參與連接的實際連接次數的百分比,基于最近的L周期內延遲與元組產出結果的關系來求得。在最近L周期內,當元組t輸入時,統計延遲delay(t),元組的連接數N′(t)和元組的結果數N(t)。受延遲dx和dy影響的最近L階段的選擇度計算如下: sel(dx,dy)= (11) 同理,理想狀態下的選擇度可認為是受最大延遲的影響,最近L階段的理想選擇度計算如下: sel(Maxdx,Maxdy)= (12) 假設有兩條亂序數據流R和S,QJoin技術中緩存自適應調整的偽代碼為 算法1 QJoin技術中的緩存自適應調整算法 輸入:自適應間隔L、基礎窗口大小b、窗口大小w、延遲增加的粒度g、相似函數的閾值θ、流R中當前最大延遲流Maxdx、流S中當前最大延遲Maxdy、每個元組的連接數目、每個元組的連接結果數目、每個P-L周期實際連接結果數目、從用戶指定質量Quser得到的L周期質量期望QL、流R的流速Vr、流S的流速Vs 輸出:(x,y),其中x表示R緩存大小,y表示S緩存大小 Begin 1dx=0;dy=0; //對元組延遲的初 始化 2while(dy<=Maxdy)do//將延遲查找范圍限制在當前歷史流上最大延遲內 3while(dx<=Maxdx)do 4if(QL(dx,dy) 5elserecord(dx,dy); 6dy=dy+g; 7foreach(dx,dy) in record(dx,dy)do 8x=(dx+w) *Vr; //計算緩存的總使用量 9y=(dy+w) *Vs; 10M(x,y)=x+y; 11if(getMin(M(x,y)) //比較所有記錄值 12return(x,y); End. 在上述算法中,每個自適應周期結束后對緩存進行一次調整,其中1-6行是利用延遲特性與質量的關系,求出所有可以滿足L周期質量期望的需要緩存元組的延遲。如果緩存了小于等于該延遲值的元組后得到的結果質量滿足L周期的質量預期QL,就記錄下來,否則就增大一個g延遲粒度。第7-12行是利用延遲與緩存的關系,返回適宜的緩存。通過比較計算得到的所有記錄值,求出使總緩存值最小的R流緩存x,S流緩存y。QJoin技術中,考慮了緩存的最理想情況,即延遲最大的元組都可以在緩存中找到所有需要連接的元組,這時得到的召回率是L周期內理想情況召回率;此外,還考慮了最近L周期召回率與緩存之間關系,使用用戶質量指標和統計量采樣,得到更合理的緩存,以降低緩存開銷。 本實驗使用一臺CPU 3.1 GHz、16 G內存、500 G硬盤的PC設備進行試驗測試。操作系統是Windows 10,所有代碼用Java語言編寫。實驗數據集包括2段球賽訓練數據D1和D2,源于一場足球比賽數據[1],由德國紐倫堡體育足球場上的傳感器系統采集。該數據包含兩條數據流(R流和S流),分別由足球上的傳感器和運動員身上的傳感器采集。數據集中每個元組包含信息(sID,ts,location),其中sID用于區分R流和S流,ts表示元組時間戳,location是運動員們在球場的位置信息。具體信息如表1。 表1 數據集特性Table 1 Feature of datasets 本實驗使用的查詢語句為 SELECT * FROMR[2 sec],S[2 sec] WHERE distance(R.location,S.location)<=5 m。 重要參數默認設置值包括用戶指定質量周期P=1 min,自適應調整周期為L=1 sec,基礎窗口大小為b=10 ms,自適應調整粒度為g=10 ms。 為了使結果顯示更清晰明確,實驗中使用連接過程中平均內存開銷作為度量標準。當數據流流速一定時,平均內存開銷越大,可存儲的遲到元組延遲就越大。 首先考察QJoin技術中重要參數設置對內存開銷的影響。為此,分別對用戶指定質量周期P、自適應調整周期L、基礎窗口大小b、自適應調整粒度g進行設定值調整來進行比較實驗,其他條件為默認設置值。圖2為用戶指定最小召回率為Quser=0.90和Quser=0.95,使用數據集合D1時,重要參數設置對算法影響的實驗結果。實驗中使用平均內存開銷(即緩存的元組數目)來顯示實驗的結果。圖2a中觀察到周期P對內存的平均開銷影響并不大,只是在周期P設置為60 s,顯示微小的差異,因此最終周期P默認設置為60 s。圖2b可以清晰顯示出當自適應周期為0.1 s時平均內存開銷更少,實際應用時可以設置自適應周期L為0.1 s。由圖2c中觀察到基礎窗大小b的選取過于細小或者寬大,都會使估計不夠準確,或平均內存開銷增大。由圖2d可觀察到當自適應調整粒度g取10 ms時,平均內存開銷較低。 圖2 不同參數對QJoin技術平均內存開銷的影響Fig.2 Effect of different parameters on the average memory cost of QJoin technology 由于MP-K-slack[7]技術具有典型性,通常被作為相關技術研究的實驗比較對象,因此本研究也是將QJoin技術和MP-K-slack技術進行比較。 1)流元組平均處理時延比較 流元組平均處理時延是所有元組進入系統到最終輸出連接結果的時間間隔平均值。圖3給出了QJoin技術和MP-K-slack技術關于流元組平均處理時延的實驗對比結果。 MP-K-slack技術的處理思路是設置一個K時間單位的緩存,初始值為0,當前流歷史上最大時間戳標注為當前時刻tcurr,每到來一個元組就插入到緩存中,與當前時刻tcurr比較,若大于tcurr,就更新tcurr。當tcurr更新時,做如下兩個操作:1)更新K=max{K,D(x)},其中D(x)=tcurr-x.ts,是元組x的延遲,是上一次tcurr更新時計算得到的;2)將滿足x.ts+K<=tcurr的元組,從緩存中彈出。從工作原理來看,MP-K-slack技術隨延遲分布波動,始終以當前最大延遲作為等待時間,正常元組需要等待較長時間后才能釋放進行連接處理,流元組平均處理時延較長。而本研究提出的QJoin技術中,元組一旦進入系統就開始連接,并快速輸出結果。當用戶要求的召回率超過0.85時,相比于MP-K-slack技術,QJoin技術的流元組處理時延降低了約80%-95%(圖3),原因是MP-K-slack技術必須要緩存元組更久,才能有效處理盡可能多的遲到元組,滿足召回率,而QJoin技術在對稱連接和合理緩存的情形下可以直接參與連接,可以更快地進行流元組的連接,有利于提高系統進行連接處理的處理速率。 圖3 QJoin技術和MP-K-slack技術的流元組平均處理時延比較Fig.3 Comparision of average tuple processing delay of algorithms QJoin and MP-K-Slack 2)平均內存開銷比較 與MP-K-slack技術相比,在用戶要求召回率越高的情況下,本研究提出的QJoin技術平均內存的開銷較低,存儲使用量明顯降低了約50%-80%(圖4)。原因在于:MP-K-slack技術為了滿足足夠的召回率,必須要緩存阻塞元組更久,就會使更多的元組滯留在緩存區中,特別是在流速較快、延遲較大的遲到元組較多的數據流中(圖4a),而QJoin技術是基于對稱連接的技術,在滿足召回率的情形下只需要合理緩存適量的歷史元組,因此優化效果明顯,對內存的需求更低。 圖4 QJoin技術和MP-K-slack技術平均內存開銷比較Fig.4 Comparison of average memory cost between QJoin and MP-K-Slack 本文研究了質量驅動下的亂序數據流連接處理問題,提出一種質量驅動的亂序數據流連接處理技術QJoin。該技術基于數緩存和對稱連接方法實現對亂序數據流流元組的即時處理,顯著降低了流元組的平均等待時延,提升了基于滑動窗口語義的亂序數據流連接處理的處理速率。采用質量驅動的理念,基于連接處理過程中收集的統計數據優化緩存的大小,使得在滿足用戶指定的結果質量的同時,大大降低了對歷史數據的內存緩存量;利用歷史數據元組緩存,較好地保證了遲到元組的連接處理完整性,從而實現在滿足用戶結果質量要求的前提下盡可能降低了系統內存開銷。與現有的MP-K-slack方法相比,QJoin技術在滿足用戶結果質量的同時,不僅能夠保證較低的數據流流元組處理時延,比MP-K-slack方法最大降低了約95%,還有效降低了內存使用開銷,比MP-K-slack方法最大降低了約80%。
1.5 算法描述
2 結果與分析
2.1 實驗環境設置

2.2 參數設置對內存開銷的影響
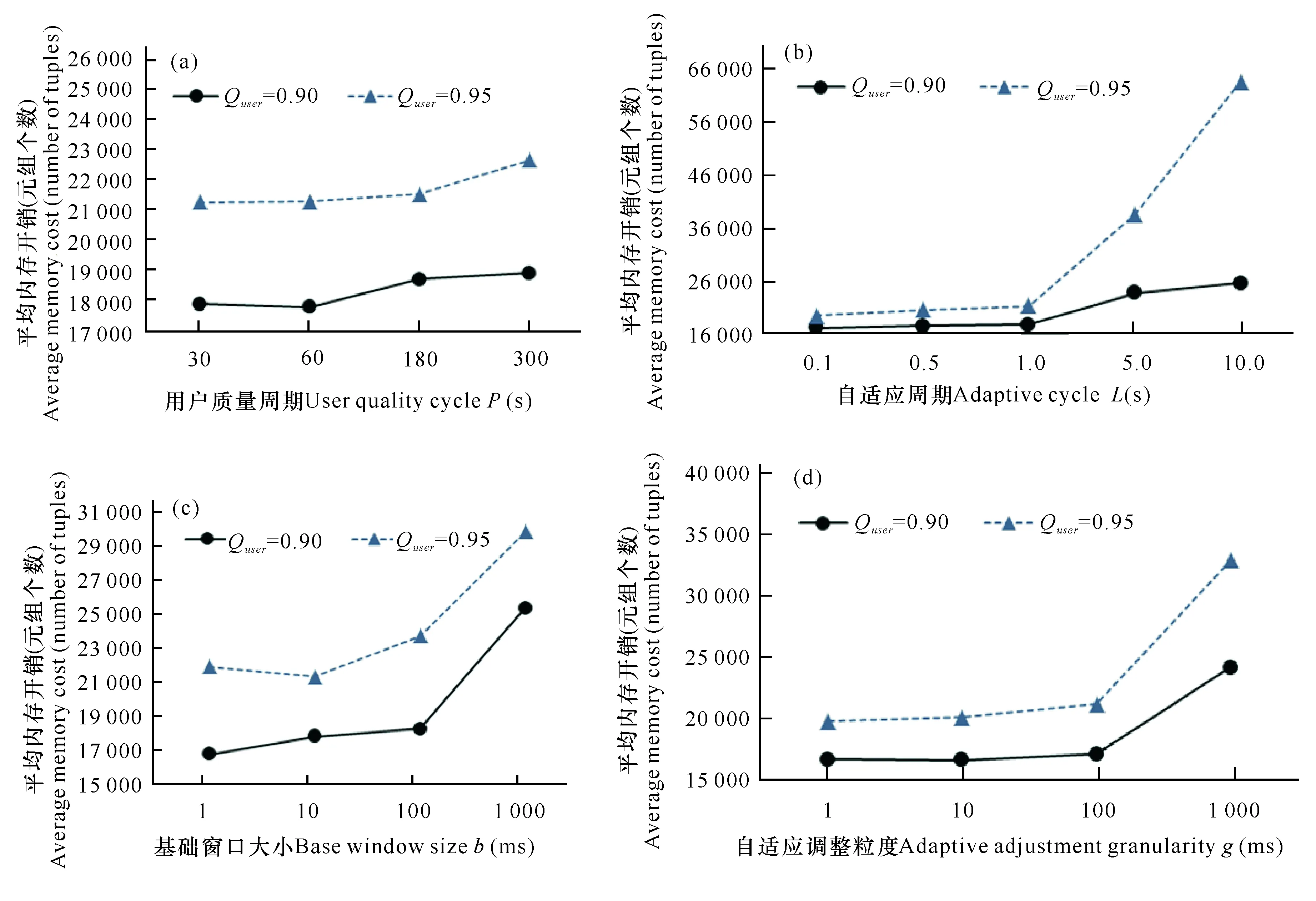
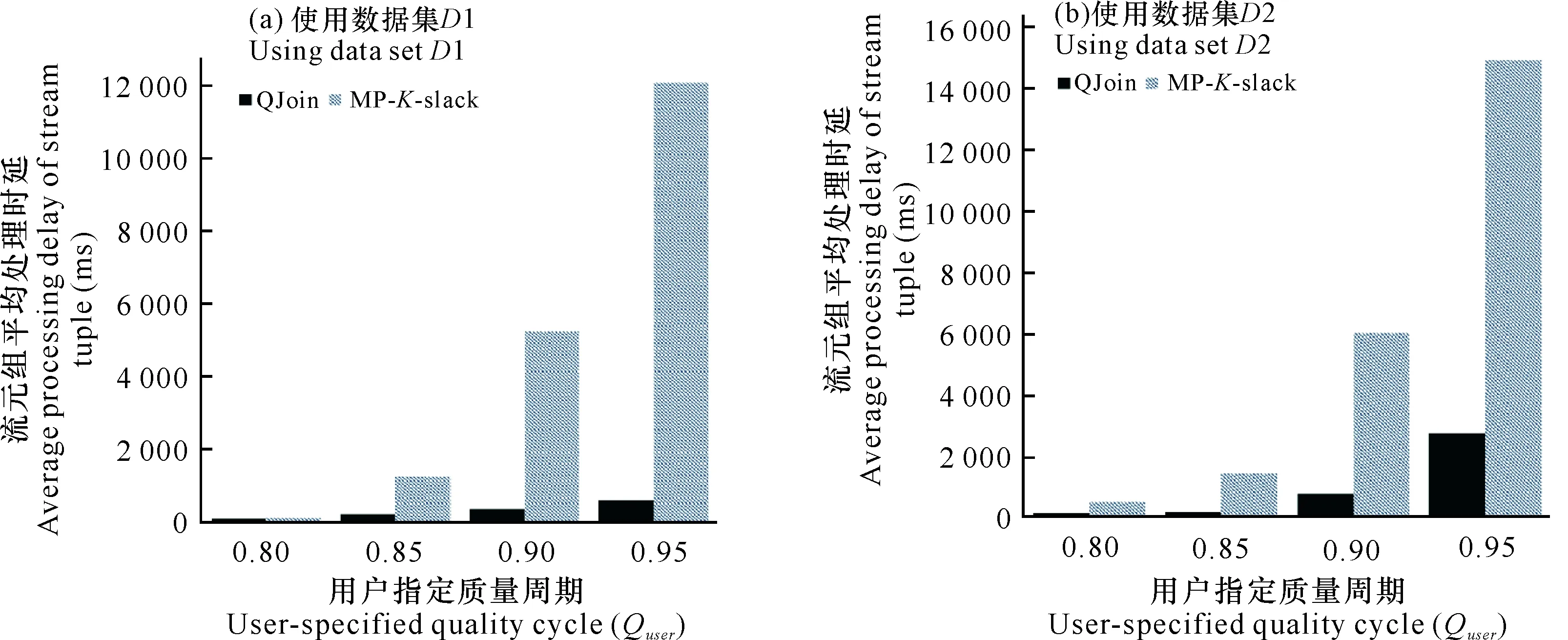
2.3 QJoin技術和MP-K-slack技術性能比較
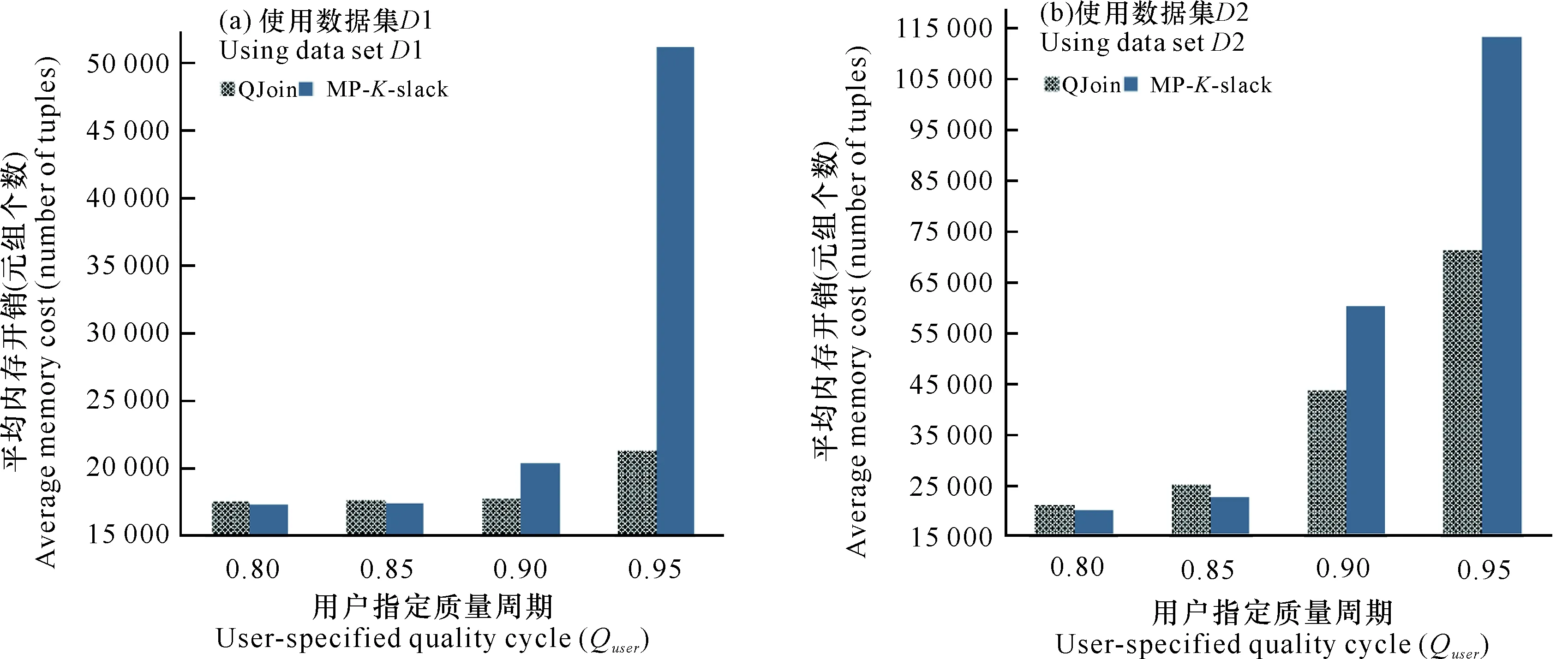
3 結論
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08中學生數理化·中考版(2020年10期)2020-11-27 01:59:48中國生殖健康(2019年2期)2019-08-23 08:12:08商用汽車(2016年11期)2016-12-19 01:20:16商用汽車(2016年6期)2016-06-29 09:18:54商用汽車(2016年4期)2016-05-09 01:23:12Coco薇(2016年2期)2016-03-22 02:42:52汽車觀察(2016年3期)2016-02-28 13:16:26Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56
