大麥SBP轉錄因子的鑒定與表達分析
2020-08-03 08:35:12趙甜甜劉夢迪王艷芳趙彥宏董紅霞
麥類作物學報 2020年1期
關鍵詞:結構
蔡 倩,趙甜甜,劉夢迪,王艷芳,趙彥宏,馬 臣,董紅霞
(1.魯東大學生命科學學院,山東煙臺 264025;2.魯東大學農學院,山東煙臺 264025)
轉錄因子(transcription factor,TF)是一類能與DNA分子特異結合并通過激活或抑制下游靶基因的轉錄來調節基因表達的蛋白分子[1]。SBP(squamosa promoter binding protein)家族是植物特有的轉錄因子,具有編碼DNA結合結構域的保守核苷酸序列,能夠在mRNA轉錄水平上調節基因表達[2]。SBP轉錄因子通常含有約80個氨基酸殘基高度保守的SBP結構域,且基本具有相同的結構特點[3]。該SBP結構域包含2個鋅指結構(Zn1和Zn2)與1個高度保守的核定位信號(nuclear localization signal,NLS)。其中鋅指結構能伸入DNA溝中識別并結合在squamosa啟動子上;C端是核定位信號區域[4],能引導SBP蛋白進入細胞核行使功能[5]。
Klein等[6]首先在金魚草中發現了SBP基因,隨后在越來越多的植物中鑒定出SBP基因,如擬南芥[7]、水稻[8]、葡萄[9]、蘋果[10]、玉米[11]、高粱[12]、毛竹[13]等。SBP轉錄因子的功能涉及植物生長發育的許多方面:擬南芥中的2個SBP基因SPL3和SPL8分別影響植株的成花和花粉囊的發育[5];SPL9和SPL15缺失導致擬南芥營養生長時期葉原基形成間隔期變短、花序結構分支增多[14];玉米SBP轉錄因子的lg1基因發生突變導致植株不能形成正常形態的舌葉和葉耳組織[15-16];在水稻生殖生長階段,過量表達OsSPL14可促進穗分支,提高籽粒產量[17-18]。
大麥是重要的禾本科作物之一,其總產量和種植面積位居全球第四[19],集飼用、啤用和糧食作物于一體。大麥作為麥類作物研究的模式植物,在遺傳、育種以及基因組等方面的研究已取得了顯著的進展[20],國際大麥全基因組測序同盟于2012年完成了大麥全基因組序列的測定[21],為大麥進行生物信息分析研究奠定了基礎。雖然大量研究報道了多種植物SBP轉錄因子的鑒定與功能分析,但關于大麥SBP轉錄因子的研究仍然較少。本研究擬采用生物信息學方法鑒定大麥全基因組的SBP家族基因,分析該家族成員基因的序列特征、染色體位置分布及其結構等,構建大麥、水稻和擬南芥SBP蛋白的進化樹,并利用公共數據庫中的RNA-seq數據對該家族成員在不同組織的表達模式進行研究,為大麥SBP家族的深入研究及其重要基因的功能研究提供依據。
1 材料與方法
1.1 數據來源
從UniProt蛋白數據庫(https://www.uniprot.org)下載獲得52 397條大麥蛋白序列;從PlantTFDB數據庫(http://planttfdb.cbi.pku.edu.cn/)獲得水稻和擬南芥SBP蛋白序列及其相應的基因序列;從EnsemblPlant數據庫(http://plants.ensembl.org/Hordeum_vulgare/Info/Index)獲得大麥RNA-seq表達數據。
1.2 大麥SBP家族的基因鑒定與定位
利用HMMER軟件并基于SBP家族蛋白特征文件PF03110(下載自Pfam數據庫),從已下載的52 397條大麥蛋白序列中預測屬于SBP家族的大麥蛋白序列;同時,用PlantTFDB中的Prediction工具從這些已下載大麥蛋白序列中預測大麥SBP蛋白序列;將二者共同預測出的SBP蛋白作為候選的大麥SBP。然后,利用在線數據庫SMART(http://smart.embl-heidelberg.de/)對候選大麥SBP蛋白結構域進行鑒定,進一步確定大麥SBP蛋白,排除不含SBP結構域的序列。利用BLAST搜索工具,從EnsemblPlants數據庫(http://ensemblgenomes.org)和Phytozome數據庫(https://phytozome.jgi.doe.gov/)中檢索每個大麥SBP蛋白對應的基因序列和CDS序列以及所在基因組位置。
1.3 大麥SBP蛋白理化性質分析與蛋白結構預測
利用在線軟件Protparam(https://web.expasy.org/protparam/)預測大麥SBP蛋白的基本理化性質(包括分子量MW、等電點pI、平均親水系數GRAVY、不穩定系數與脂肪系數等);利用在線軟件SWISS-MODEL(https://swissmodel.expasy.org/)預測大麥SBP蛋白的三維結構。
1.4 大麥、擬南芥和水稻SBP家族系統發育樹的構建
基于大麥、擬南芥和水稻的SBP家族蛋白序列,運用MEGA 7.0軟件進行多序列比對,并通過鄰接法(neighbor-joining method,NJ)構建系統進化樹Bootstrap設為1 000次。
1.5 基因結構分析與蛋白保守基序分析
利用GSDS 2.0(http://gsds.cbi.pku.edu.cn/index.php)軟件依據CDS序列和相應的基因序列分析大麥SBP基因內含子-外顯子結構;利用MEME(http://meme-suite.org /tools/meme)軟件分析大麥SBP蛋白家族保守基序,基序長度范圍為10~50個氨基酸殘基,其他參數為默認值。
1.6 大麥SBP家族表達分析
基于已從EBI下載的大麥7個不同組織(萌動胚、幼苗、5 dpa穎果、15 dpa穎果、0.5 cm幼穗花序、1 cm幼穗花序和節間)的RNA-seq表達數據,利用大麥SBP基因的FPKM值表示基因的表達豐度,使用Matrix2png繪制基因表達熱圖。
2 結果與分析
2.1 大麥全基因組SBP家族基因的鑒定及染色體位置
利用HMMER軟件與PlantTFDB數據庫中的Prediction工具從52 397條大麥蛋白序列中預測獲得28個大麥SBP候選蛋白;利用在線數據庫SMART對候選 SBP轉錄因子逐條進行結構域鑒定,共獲得22個大麥中具有SBP蛋白典型結構域的序列,將這些蛋白對應的基因依次命名為HvSBP1~HvSBP22(表1)。根據大麥基因組信息,HvSBP基因家族定位在6條大麥染色體上(圖1),發現SBP基因在大麥染色體上分布不均勻,Chr6H和Chr7H上SBP基因數目分布最多,分別有7個和6個家族成員;Chr2H、Chr3H和Chr5H各自包含2~3個SBP基因;ChrUn上有1個SBP基因;Chr1H和Chr4H上面沒有發現SBP基因。大多SBP在染色體上成簇分布,每個簇內的SBP基因之間距離都很近。這與許多別的基因家族在染色體上的分布特征非常相似。蛋白理化性質分析顯示,22個大麥HvSBP基因的編碼區長度在549~3 009 bp之間,編碼的蛋白長度為182~1 002個氨基酸;其等電點(pI)在5.46~10.29之間,總平均親水系數(GRAVY)在-0.879~-0.280之間。
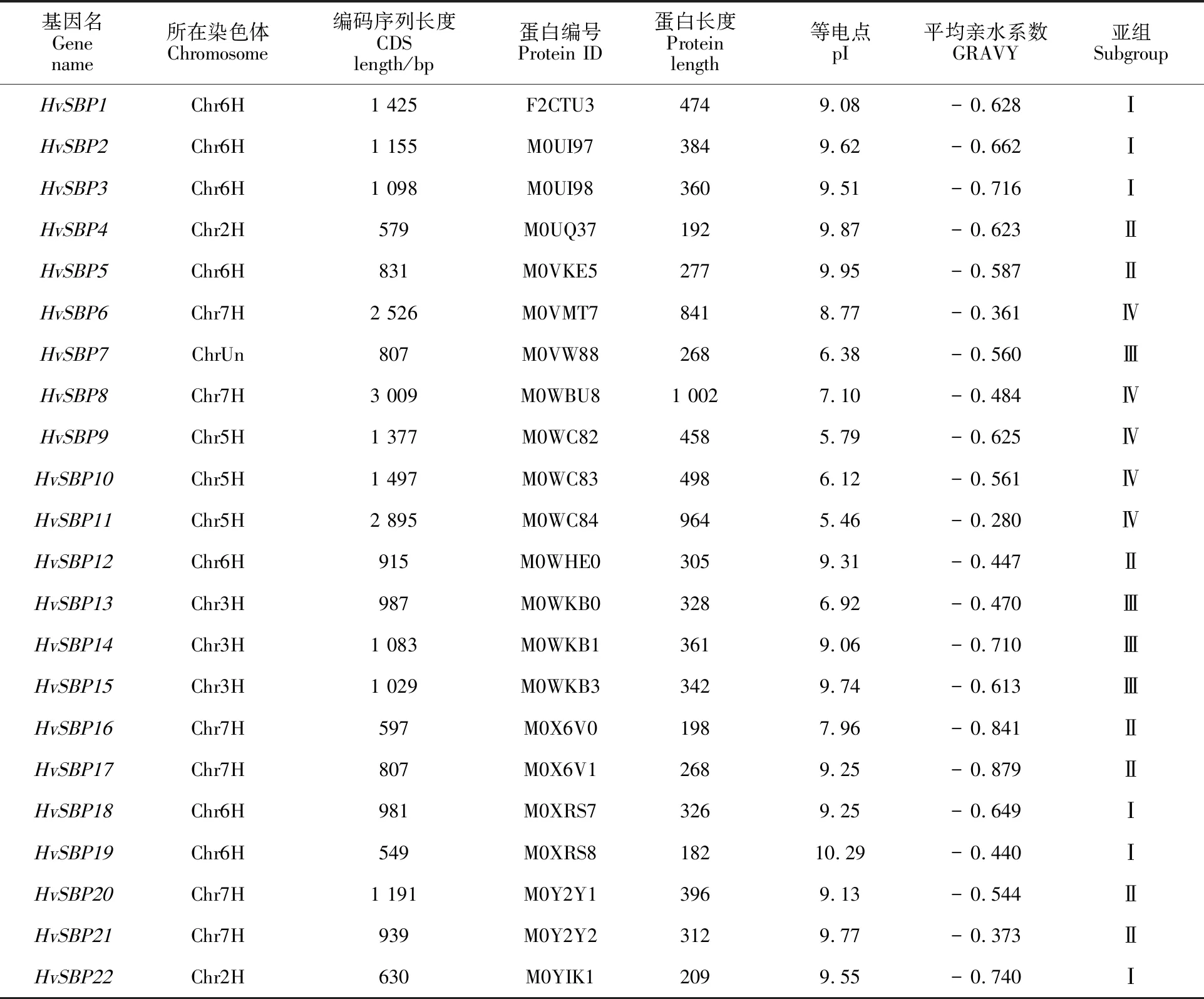
表1 大麥中鑒定出的SBP家族基因Table 1 SBP family genes identified in barley
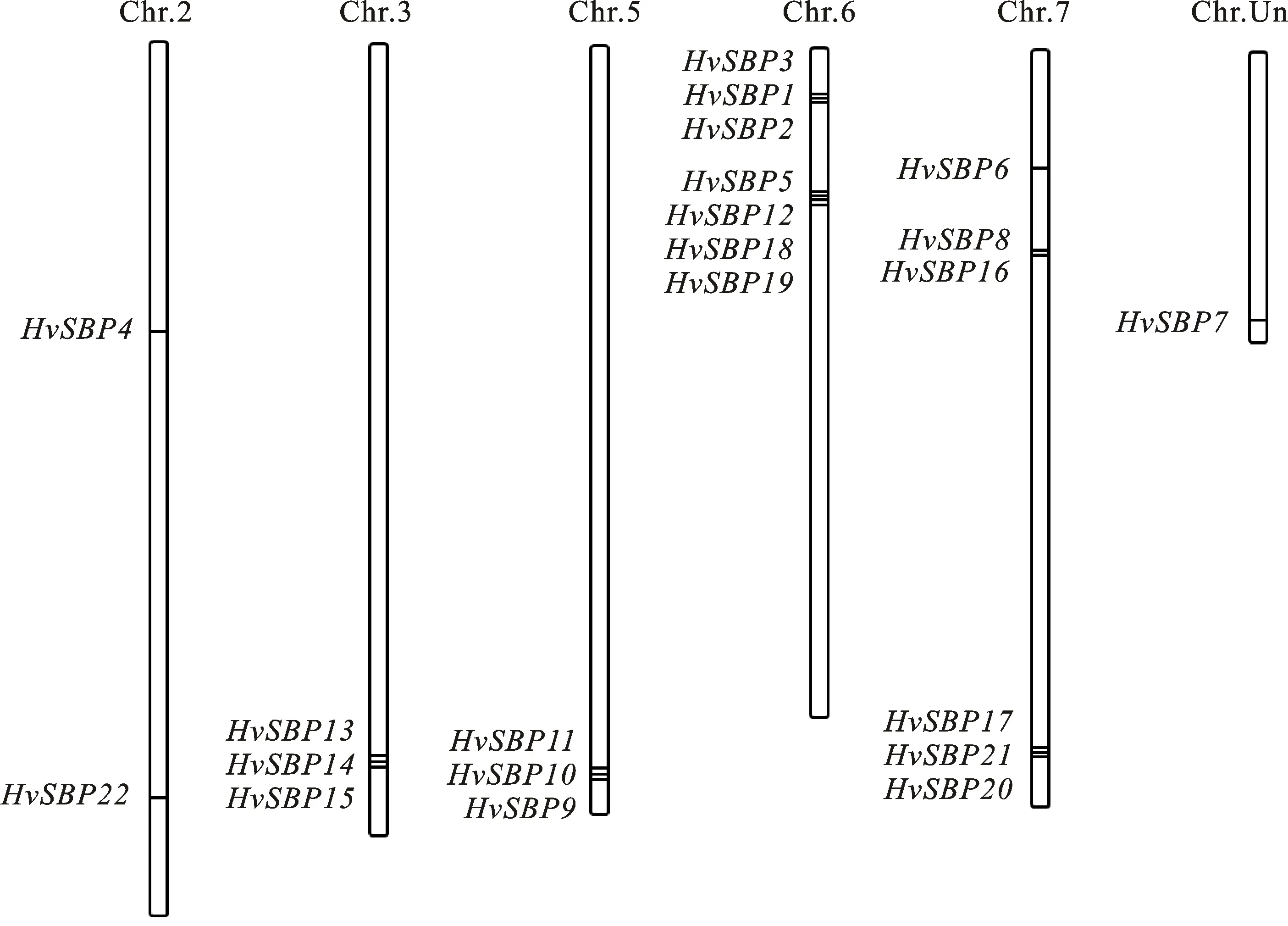
圖1 大麥SBP基因的染色體定位
2.2 大麥SBP基因內含子和外顯子分析
為了進一步研究大麥HvSBP基因結構,基于HvSBP基因對應的基因組序列與CDS序列,利用MEME分析得到各HvSBP基因的外顯子、內含子分布情況(圖2)。HvSBP9、HvSBP10和HvSBP11外顯子和內含子數量最多,有11個外顯子和10個內含子;其次是HvSBP8,有10個外顯子和9個內含子;其他18個HvSBP基因的外顯子數介于1~6之間。第Ⅳ組中的各基因 (HvSBP6、HvSBP8、HvSBP9、HvSBP10和HvSBP11)的外顯子數最多,介于6~11。研究還發現,不同組的HvSBP基因結構不同,而同一組內的基因往往具有相似的基因結構。各基因之間不僅在外顯子和內含子數量上存在差異,而且在外顯子與內含子的長度上也存在著明顯的差異。這也直接導致了各基因對應的CDS序列長度的差異(549~3 009 bp)和編碼的蛋白長度的差異(182~1 002 aa)。HvSBP19基因的CDS序列最短,僅為549 bp,其對應的蛋白序列也最短,僅為182個氨基酸殘基;HvSBP8基因的CDS序列和蛋白序列最長,其長度分別為3 009 bp和1 002個氨基酸殘基(表1)。

黃色柱狀為外顯子,黑線為內含子,藍色為上游的5′UTR或下游的3′UTR。
2.3 大麥SBP蛋白結構域的鑒定和保守基序分析
通過對大麥22個SBP蛋白進行多序列比對,分析其序列保守結構域,結果(圖3)顯示,除了5個HvSBP蛋白(HvSBP7、HvSBP13、HvSBP15、HvSBP16和HvSBP21)外,其余17個大麥HvSBP蛋白都具有完整且典型的SBP結構域。一般包含約80個氨基酸殘基,具備2個鋅指結構(Zn1和Zn2)和核定位信號(NLS)。Zn1和Zn2分別為C3H(C-C-C-H)和C2HC(C-C-H-C)類型;Zn2和NLS之間存在4個氨基酸的重疊。 HvSBP7、HvSBP13、HvSBP15和HvSBP16蛋白具有Zn2和NLS結構,但缺少Zn1結構;另外,HvSBP13、HvSBP15和HvSBP16蛋白中Zn2保守序列不完整,缺少了3~5個氨基酸。 HvSBP21蛋白則具有典型的Zn1結構,但缺少Zn2和NLS結構,卻又包含Zn2的保守氨基酸序列(CQQCS)。
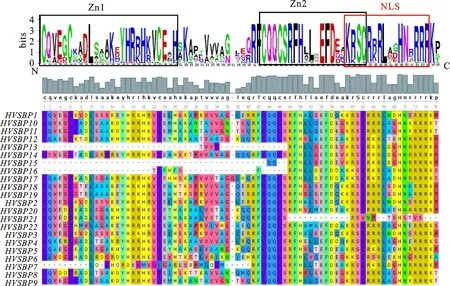
圖3 大麥SBP蛋白的多序列比對分析
用MEME對大麥22個SBP家族的氨基酸序列進行保守基序(motif)掃描,得到HvSBP轉錄因子蛋白質保守序列的結構特征圖,即motif分布圖(圖4)。結果顯示,在HvSBP轉錄因子蛋白中總共找到了4個保守的motif基序,其中motif2處在第一個鋅指Zn1的位置,motif3包含了Zn2結構的前半部分,motif1包含了Zn2結構域的后半部分和核定位信號NLS結構域。這3個motif正好組成了SBP結構域。在22個大麥SBP蛋白中,有17個蛋白全部包含motif1、motif2和motif3,并且其排列順序都為motif2-motif3-motif1;只有HvSBP21中不包含motif1,其余21個HvSBP都包含motif1;HvSBP7、HvSBP13、HvSBP15和HvSBP16中不包含motif2;HvSBP16只包含motif1;另外,有10個HvSBP蛋白中出現了另外1個保守基序motif4,它出現在SBP結構域上游或下游。同一組的HvSBP蛋白一般具有相似的motif分布。通過motif分析可知,每個HvSBP蛋白保守的3個motif正好處于SBP結構域,表明SBP特征序列是這些HvSBP蛋白中最為保守的區域。

圖4 大麥SBP蛋白的比對分析
保守的蛋白序列往往能形成保守的蛋白結構,保守的結構往往又是其行使特定功能的重要保證。從大麥SBP蛋白的三維結構的預測結果(圖5)可以看出,這些蛋白中具有典型的鋅指結構與和核定位信號結構。雖然這些蛋白的三維結構存在一定的差異,但由于其存在共同的保守基序,使得它們的三維結構具有SBP家族的共同蛋白結構特征。
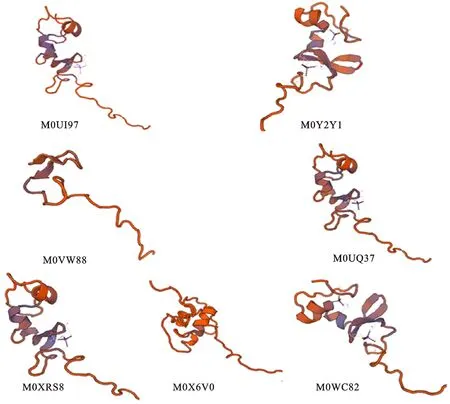
圖5 大麥SBP蛋白三維結構
2.4 大麥SBP基因的表達分析
研究HvSBP基因的時空表達模式有助于了解其潛在的功能。本研究利用從EnsemblPlant數據庫中下載的大麥RNA-seq數據,對大麥各HvSBP基因在不同發育階段的各組織(萌動胚、幼苗、幼穗花序(0.5 cm與1.0 cm)、穎果(5 dpa與15 dpa)和節間中的表達進行了分析,并根據其表達的FPKM值繪制了基因表達譜熱圖(圖6)。從圖6可以看出,22個HvSBP基因在不同發育階段的各組織中的表達有明顯的差異。HvSBP8、HvSBP9、HvSBP10、HvSBP11和HvSBP16在萌動胚、幼苗、幼穗花序(0.5 cm與1.0 cm)和穎果(5 dpa與15 dpa)和節間中均具有較高的表達量,其中HvSBP8和HvSBP16的表達量最高;HvSBP1~4和HvSBP6基因則僅僅在個別組織(幼穗花序和節間等)中具有較高表達水平;其他12個HvSBP基因則在大麥各組織中的表達量極低,甚至不表達。總之,HvSBP基因的表達主要集中在幼穗花序(1.0 cm和0.5 cm)、穎果 (5 dpa)和節間中,其中在幼穗花序(1.0 cm)表達量最高。這就說明HvSBP基因與大麥開花發育密切相關。
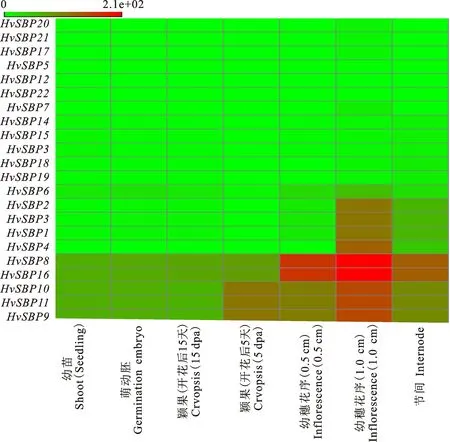
圖6 大麥SBP基因表達熱圖
2.5 大麥SBP的進化分析
為了分析大麥SBP家族的進化情況,用擬南芥的30個SBP、水稻的27個SBP與大麥的22個SBP家族成員共同構建了系統發育樹(圖7),結果顯示,3個物種的SBP家族成員可分為4個亞組(Ⅰ、Ⅱ、Ⅲ和Ⅳ亞組),每個亞組均含有3個物種的SBP。4個亞組(Ⅰ~Ⅳ)中分別包含6、7、4和5個大麥HvSBP。在染色體上處于同一簇的HvSBP基因進化關系接近,不僅屬于同一進化亞組,而且在進化樹上所處的分枝相鄰,說明同一簇的HvSBP基因進化關系最近,如在Chr6H上分布于同一簇的HvSBP1、HvSBP2和HvSBP3同屬于第Ⅰ亞組,而且進化關系非常接近;Chr7H上分布于同一簇的HvSBP17、HvSBP20和HvSBP21;Chr3H上的HvSBP13、HvSBP14和HvSBP15;Chr5H上的HvSBP9、HvSBP10和HvSBP11。分析HvSBP22/ORUF-104G22540.1、HvSBP4/ORUF 107G16070.1、HvSBP12/ORUF102G05950.1以及HvSBP7/ORUF108G24030.1發現,這4對直系同源基因親緣關系最近,它們全部來自大麥與水稻;在大麥HvSBP基因中也發現6對親緣關系最近的旁系同源基因,分別是HvSBP1/HvSBP3、HvSBP18/HvSBP19、HvSBP16/HvSBP17、HvSBP5/HvSBP20、HvSBP13/HvSBP15以及HvSBP9/HvSBP11,其中4對基因(HvSBP1/HvSBP3、HvSBP18/HvSBP19、HvSBP13/HvSBP15以及HvSBP9/HvSBP11)屬于成簇分布的串聯重復基因。
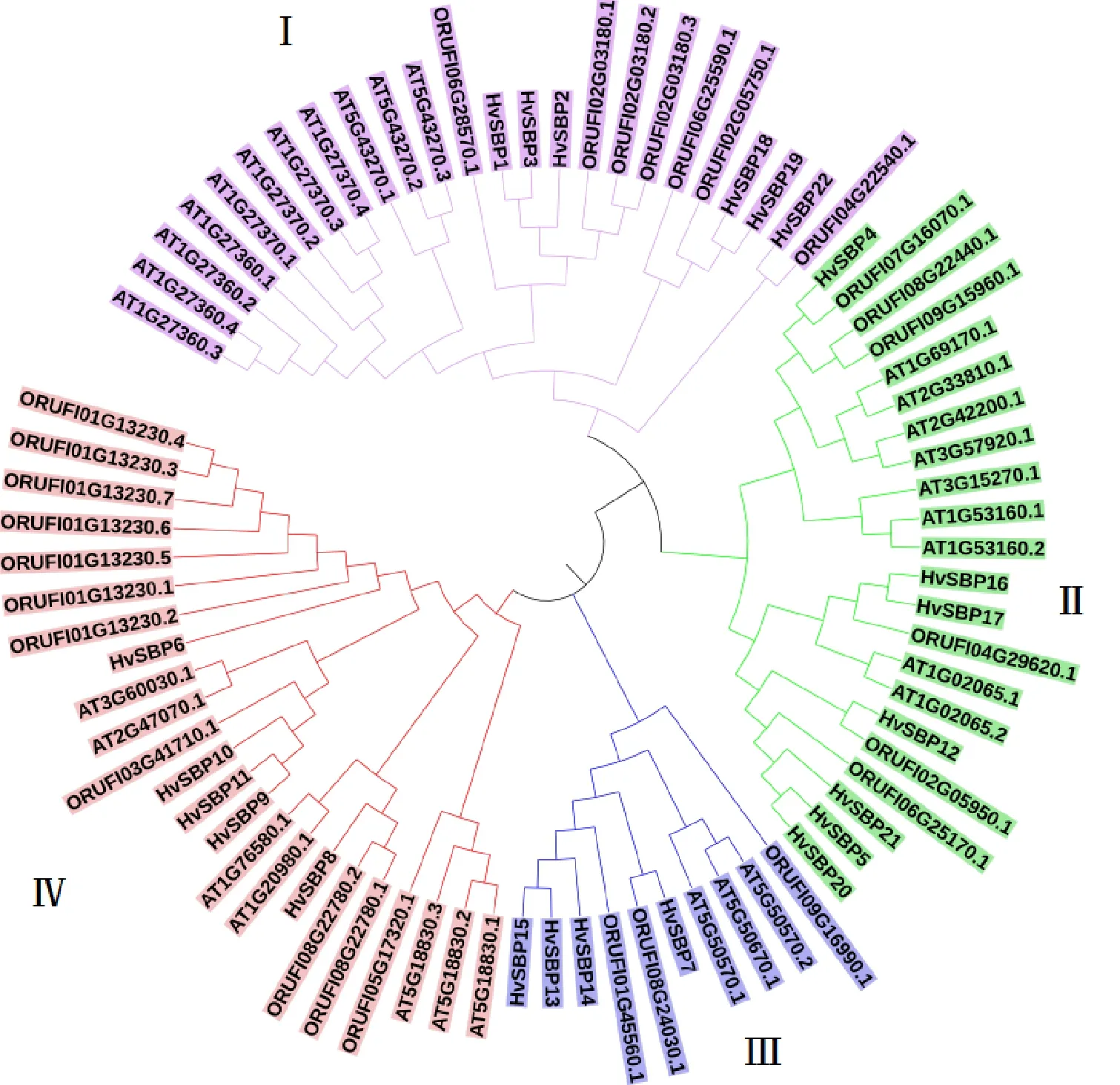
圖7 SBP蛋白的進化樹
3 討 論
高等植物中的轉錄因子有數千種,許多有關逆境脅迫的轉錄因子相繼被克隆[22],轉錄因子的全基因組鑒定及表達模式研究逐漸成為當前植物基因功能研究的熱點之一。SBP基因家族是植物所特有的一類重要轉錄因子,近年來有關SBP基因家族的研究備受重視。目前,利用生物信息學方法從基因組水平對多種植物SBP基因家族成員的功能進行分析,研究結果表明,SBP轉錄因子在調節植物生長發育以及多種生理生化過程中發揮極其重要的作用。大麥基因組測序的完成以及大麥蛋白數據庫信息等的日趨完善為從基因組水平分析HvSBP轉錄因子奠定了基礎。但是,目前有關大麥SBP基因家族的系統研究報道還比較少。
本研究基于大麥蛋白數據庫和全基因組測序數據庫等信息,利用三種預測工具(HMMER、PlantTFDB_ Prediction和SMART)共同預測并鑒定出22個大麥SBP基因(HvSBP1~HvSBP22)。該預測結果比單一軟件預測結果更加可靠,但是也增加了非典型大麥SBP蛋白被漏掉的風險。本研究鑒定出的22個大麥HvSBP基因被分為4個進化亞組,分別定位在Chr2H、Chr3H、Chr5H、Chr6H、Chr7H和ChrUn染色體上。除了HvSBP4、HvSBP6、HvSBP7和HvSBP22外,其他HvSBP基因在染色體上都是成簇分布的,屬于串聯重復基因。這種分布特征與已報道的其他基因家族的分布特征類似。
本研究發現,處于同一簇串聯重復的HvSBP基因在序列、基因結構、蛋白保守結構域(motif)、理化性質、基因表達上高度相似,并處于進化樹上最相鄰的分枝上。推測這些位于同一簇的串聯基因是由于在大麥進化過程中染色體的不對稱交換與復制產生的多拷貝基因進化而來的。目前的觀點認為,復制基因在進化中有3種不同的命運:(1)其中的1個基因繼承了祖先基因的功能,而其他拷貝的基因則變成了假基因;(2)其中的1個基因仍然保留了祖先基因原有的功能,而其他拷貝的基因則進化出了新的功能;(3)這些基因被亞功能化(sub-functionalized),它們一起承擔了祖先基因傳下來的基因功能[23-24]。由于本研究鑒定出的處于同一簇的大麥HvSBP基因在各個方面都存在著高度的相似性,他們的表達模式在不同大麥組織中高度一致,推測這些成簇分布的大麥HvSBP基因更加傾向于第3種進化學說。同一基因家族的各個基因一般都來自同一個祖先基因,屬于同源基因,是在進化過程中通過某種方式產生的多拷貝基因逐漸進化而來的。本研究鑒定出不同簇的大麥HvSBP基因之間雖然也屬于同源基因,存在共同的保守區域,但它們在CDS與蛋白的序列及長度、基因結構、保守結構域(motif)、理化性質與基因表達方面卻存在明顯的差異。因此,推測不同簇的HvSBP基因之間在功能上存在一定差異。
進化分析結果顯示,大麥、擬南芥和水稻共79個SBP基因被分為4個進化亞組,每個亞組中都包含3個物種的SBP基因,而且在同一進化亞組中,各SBP基因的親緣關系并不完全是按照物種來區分的。推測在SBP基因家族產生且已分化出了這4個亞組之后,才出現了單、雙子葉植物的分化。前人的研究表明,SBP基因可能起源于綠藻和陸生植物祖先分化之前[25]。從進化樹上可以看出,與大麥HvSBP基因進化關系最近的是水稻的SBP基因。本研究發現的親緣關系最近的4對直系同源基因(HvSBP22/ORUF104G22540.1、HvSBP4/ORUF107G16070.1、HvSBP12/ORUF102G05950.1以及HvSBP7/ORU-F108G24030.1)全部都是來自大麥與水稻。可見,單子葉植物的大麥中的SBP基因與水稻的SBP基因親緣關系比雙子葉植物的擬南芥更近。
篩選出的22個大麥HvSBP在各個組織中的表達量差異很大,其中,HvSBP8、HvSBP9、HvSBP10、HvSBP11和HvSBP16在所有組織中均明顯的表達,HvSBP1~4和HvSBP6僅在個別組織中表達,其他12個HvSBP基因在所有組織中表達量極低或根本不表達。這暗示了各HvSBP基因的功能在進化中已經出現了明顯的分化。本研究也發現,成簇出現的串聯重復HvSBP基因具有共同的表達模式。基因表達分析還顯示,HvSBP基因主要集中在幼穗花序與穎果中表達,其中1 cm幼穗花序中HvSBP基因表達量最高,且多達10個HvSBP基因在該組織中表達。大麥HvSBP基因在0.5 cm幼穗花序中開始大量表達;當幼穗花序長度達到1.0 cm時,其表達量更高,逐漸達到了峰值;當開花授粉5 d后,HvSBP基因在穎果中的表達量開始下降;開花后15 d的穎果中表達量則進一步下降。由此可見,HvSBP基因在開花期進入表達高峰,隨著籽粒的形成及成熟,其表達量下降。這說明這些HvSBP基因參與了花的發育與調控,這與前人報道一致[7,26]。擬南芥SBP類似基因SPL3等可以調控擬南芥花的發育[27],擬南芥SBP8和SBP14可以調控其花粉的發育[7],進而影響擬南芥產量;玉米中控制花序發育的部分SBP基因與玉米產量密切相關[3]。因此,我們推測在大麥穎果和幼穗花序中大量表達的這些HvSBP基因也可能會在一定程度上對大麥產量產生影響,但還需進一步研究。
猜你喜歡
小獼猴智力畫刊(2023年4期)2023-04-23 08:49:58
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
中學生數理化·高一版(2018年1期)2018-02-10 05:20:03
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
七彩語文·寫字與書法(2016年7期)2016-07-28 21:40:22
七彩語文·寫字與書法(2016年6期)2016-07-15 19:36:34
人間(2015年21期)2015-03-11 15:23:21
現代企業(2015年9期)2015-02-28 18:56:50
