代維模式下的配電設(shè)備運維管理
2013-11-16 06:27:38程武平
中國新技術(shù)新產(chǎn)品 2013年19期
程武平
(深圳供電局有限公司,廣東 深圳 518031)
配電網(wǎng)與用電用戶直接相連,具有設(shè)備數(shù)量大、分布廣泛和影響直接的特點,如果維護不到位發(fā)生故障,直接影響用戶的用電,如福田局曾在2011年發(fā)生了兩起環(huán)網(wǎng)柜發(fā)凝露放電故障影響大片用戶。因此在有限的人力下高效維護好配電設(shè)備顯得十分重要。
1 配電設(shè)備運維現(xiàn)狀
配電設(shè)備現(xiàn)狀:目前深圳福田區(qū)共有電房2888間,分布在63平方公里土地上;另外深圳仍處于快速發(fā)展期,福田區(qū)共有43個工地涉及電纜電纜管道,需要專人去巡視檢查,防止外力破壞。
運維人員現(xiàn)狀:因業(yè)務(wù)原因并無專職的設(shè)備巡視運維人員,按實際可折算為5人專門負責(zé)巡視設(shè)備。如果4人每天巡視20個電房(含箱變或戶外環(huán)網(wǎng)柜),1人負責(zé)每天巡視4個黑點,所有公用設(shè)備的巡視周期為5月,無法滿足“定期巡視每月至少一次”的規(guī)定;所有黑點的巡視周期為2周,無法及時了解施工狀況和作出防外力破壞提醒。
運維現(xiàn)狀:目前福田設(shè)備運維工作的代維模式是,每年給予一筆固定的資金,由代維人員自行維護,但存在以下問題:①是無巡維標準,代維人員按經(jīng)驗和理解去巡維;②無考核制度,代維部門不擔(dān)心被考核扣錢,隨意執(zhí)行;③無專職巡視、維護人員,起初的巡視維護人員在后來往往被抽走情而又未及時補充人員巡視維護,導(dǎo)致巡維工作斷斷續(xù)續(xù)。
2 配電設(shè)備運維模式
2.1 組織架構(gòu)
成立由配電部主任、設(shè)備專責(zé)和各轄區(qū)的設(shè)備專工組成的設(shè)備小組。配電部主任定思路和方向,由設(shè)備專責(zé)牽頭各班設(shè)備專工,制定設(shè)備巡維細則、巡維策略和考核制定等,并在設(shè)備專責(zé)的監(jiān)督下,各班設(shè)備專工負責(zé)各班的設(shè)備巡維工作的開展(包括計劃、抽查)。與此對應(yīng),代維公司也成立相關(guān)的小組。
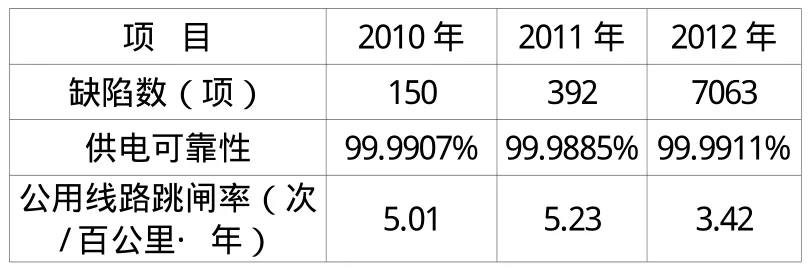
表1 近3年巡視消缺和關(guān)鍵指標
2.2 制度保障
為保障設(shè)備巡維工作的持續(xù)開展,福田局制定了符合實際的巡視消缺管理工作細則,進一步細化了工作職責(zé)、工作要求等方面的內(nèi)容。
2.3 執(zhí)行方式
2.3.1 明確巡視標準與方法
針對現(xiàn)狀中存在的無巡視標準的問題,福田局制定了適合福田實際的巡視表單,通過表單來規(guī)范巡視內(nèi)容、巡視標準,并對設(shè)備專工和代維人員開展理論講解和現(xiàn)場演示雙結(jié)合的培訓(xùn)。
表單共4份,分別是戶 外環(huán)網(wǎng)柜巡視表單、配電室(箱式變)巡視表單、臺架巡視表單、防外力破壞巡視表單;表單按照打鉤原則設(shè)計,巡視所需要關(guān)注的全部內(nèi)容全部列在表單中,提醒巡視人員逐項檢查,并且這項項目遵循“由遠至近、由上到下和有內(nèi)而外的順序,方便巡視人員只需沿一個方向進行即可。
2.3.2 摸家底,明確巡視對象
在明白巡視標準和方法后,就必須告訴代維人員巡視的對象有哪些。按設(shè)備臺賬導(dǎo)出清單,由設(shè)備專工帶領(lǐng)代維人員走一遍,通過實操,讓代維人員明白兩點:①對象有哪些,在哪里;②如何巡視檢查。此外,在這個過程中,設(shè)備專工對各個設(shè)備的狀況有一個全面的了解和評價,便于下一階段巡視計劃的科學(xué)制定。
完成此階段后,已經(jīng)具備代維人員獨立開展工作和考核的基礎(chǔ),即可開展第二階段工作,既代維人員巡視、消缺,設(shè)備專工等抽查考核。
2.3.3 按策略巡維
⑴按評價結(jié)果安排巡視計劃
在摸家底過程中,各班組設(shè)備專工根據(jù)實際情況對轄區(qū)內(nèi)的各設(shè)備狀況進行了評價,評價共分四個等級,分別為每年一巡、半年一”、每月一巡和每周一巡,設(shè)備狀況越差,巡視頻率越高。按照這個評價結(jié)果進行巡視計劃的安排,保證將注意力集中在狀況較差的設(shè)備上,保證巡視的針對性、有效性和及時性。
每周一上午,設(shè)備專工將巡視計劃連同六位數(shù)的隨機巡視編號一同發(fā)放至代維人員手上。代維人員拿到本周巡視計劃后,按計劃巡視,并將巡視編號填入現(xiàn)場設(shè)備巡視記錄表中,以便后期抽查。
⑵按比例進行巡視抽查
在代維人員巡視后第二周內(nèi),由設(shè)備專工按照30%的比例安排抽查計劃,并結(jié)合代維人員反饋的巡視結(jié)果對上周巡視對象進行復(fù)查,重點檢查兩點:①是否到位(通過巡視編號檢查);②是否全部發(fā)現(xiàn)缺陷隱患。如果以上兩項中有一項為“否”,則本單巡視視為不合格。
⑶反饋消缺結(jié)果,按比例抽查
代維的另一部分人員在巡視后組織消缺,并將消缺結(jié)果反饋至各班組的設(shè)備專工.設(shè)備專工初步判斷消缺是否合格,并按30%的比例制定消缺抽查計劃,現(xiàn)場檢查消缺是否完成,并將檢查結(jié)果納入到考核指標中。
2.4 考核制度
完善考核制度,包括制定考核指標及其計算方法、將考核指標納入到代抄代維合同中,在實際操作中按合同進行考核。考核的指標主要從供電可靠性出發(fā)制定,包括中壓故障引起的停電時戶數(shù)、低壓故障引起的停電時戶數(shù)等,按照影響程度大小進行扣分,最終影響代維費用的支付程度,與維護單位的直接利益掛鉤,直接驅(qū)動相關(guān)單位提高巡視、消缺的質(zhì)量。
由于在2012年巡視消缺工作執(zhí)行到位,全年共進行40次考核,其中18次不達標,且其中15次集中在上半年,下半年巡視消缺質(zhì)量得到了提高。
3 結(jié)論
我們分別從發(fā)現(xiàn)缺陷數(shù)量、供電可靠性和中壓設(shè)備故障情況進行比較,如表1所示。搶修費用2011年到2012年降幅達33%。由此可看出,在完善代維管理模式之后,巡視消缺工作的積極性得到了極大的提升,公用線路的跳閘率也有了顯著的下降。只要繼續(xù)堅持和完善這個模式,配網(wǎng)的設(shè)備運維工作將越來越高效。
[1]朱卓.有關(guān)配電設(shè)備運行維護的探討[J].中小企業(yè)管理與科技,2010(04).
[2]樊越.侯殿萍.有關(guān)配電設(shè)備運行維護的探討[J].黑龍江科技信息,2011(03).
猜你喜歡
中國特種設(shè)備安全(2022年6期)2022-09-20 02:52:28
童話世界(2020年10期)2020-06-15 11:53:22
當代陜西(2019年9期)2019-05-20 09:47:40
經(jīng)濟技術(shù)協(xié)作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年11期)2018-08-04 03:26:08
影劇新作(2017年4期)2017-03-22 05:47:21
中國衛(wèi)生(2016年2期)2016-11-12 13:22:24
工業(yè)設(shè)計(2016年12期)2016-04-16 02:52:00
設(shè)備管理與維修(2015年12期)2015-04-09 06:57:00
消費者報道(2014年7期)2014-07-31 11:23:57
