基于動態路由序列生成模型的多標簽文本分類方法
2020-08-06 08:28:08王敏蕊袁自勇
計算機應用 2020年7期
王敏蕊,高 曙,袁自勇,袁 蕾
(武漢理工大學計算機科學與技術學院,武漢430063)(*通信作者電子郵箱gshu418@163.com)
0 引言
文本分類是自然語言處理領域的重要問題之一,傳統的監督學習方法大多假設數據樣本是單標簽形式的,即一個樣本對應一個類別標簽,但現實生活中,往往并不如此理想,一個數據樣本通常會表達極其復雜的多重語義。與單標簽不同,多標簽樣本給一個樣本標注多個標簽,從而更加準確、有效地表達單標簽所不能表達的復雜語義關系。多標簽文本在日常生活中十分常見,例如:一條新聞可能同時包含“華為”“5G”“通信技術”等多個主題,一條微博可能同時標注“明星”“綜藝”“搞笑”等多個標簽,因此,研究多標簽文本分類對挖掘具有豐富語義的現實世界文本對象具有重要的意義。
多標簽的傳統分類方法包括二值分類(Binary Relevance,BR)方法、分類器鏈(Classifier Chain,CC)等。BR方法不考慮標簽之間的相關性,但由于其簡單而應用廣泛。CC 方法考慮每一個標簽與其他所有標簽之間的關系,將多標簽學習問題轉化為一組有序的二分類問題,其中,每個二分類器的輸入都要基于之前分類器的預測結果。傳統多標簽分類方法中文本特征的提取往往需要人工干預,容易帶來噪聲,同時又非常耗費人力。近年來,深度學習方法在單標簽文本分類任務上取得了非常好的成績[1-3],但國內外基于深度學習的多標簽文本分類模型尚處于研究階段,針對現有深度學習模型挖掘標簽相關性效果差問題,有學者提出將多標簽文本分類問題看作標簽序列生成,并取得了較好效果[4-6]。對于多標簽文本分類,每個樣本對應的標簽集都可以看作一個標簽序列,為文本進行多標簽標注可以看成標簽序列生成,而循環神經網絡(Recurrent Neural Network,RNN)及其變體已應用于各種序列建模任務中。文獻[5]中首次將多標簽文本分類看作序列生成任務,序列生成模型(Sequence Generation Model,SGM)中Decoder 使用RNN 的變體長短期記憶(Long Short-Term Memory,LSTM)神經網絡,基于已經預測的標簽產生下一個標簽,這種順序結構由于考慮了標簽之間的相關關系,從而獲得了更好的多標簽文本分類效果。但是由于其序列性,容易造成累計誤差。針對以上問題,本文受到膠囊網絡中的動態路由(Dynamic Routing,DR)思想啟發,將序列生成模型和動態路由方法結合,增加動態路由聚合層,克服序列生成中的累積誤差缺陷,并將其應用于多標簽文本分類。本文的主要工作如下:
1)將序列生成模型與膠囊網絡中的動態路由思想結合,設計了一種基于動態路由的解碼器結構。這種解碼器結構能減弱序列生成模型中累積誤差的影響,其中,優化的動態路由算法能提升語義聚合效果。
2)利用所提出的解碼器結構,構建了基于動態路由的序列生成模型(SGM based on DR,DR-SGM),并將DR-SGM 應用于多標簽文本分類。該模型能通過其順序結構捕捉標簽相關性,從而提升多標簽分類效果。
3)將本文模型在三個多標簽文本數據集進行測試,實驗結果表明,本文模型性能優于7個基準模型。
1 相關研究
多標簽文本分類任務一直是自然語言處理領域一個十分重要卻又富有挑戰性的任務。多年來,國內外學者在多標簽文本分類領域投入了大量研究。多標簽文本分類,顧名思義,即是對具有多個標簽的文本樣本進行標簽預測,它相對于單標簽文本分類更加復雜。現有的多標簽文本分類方法可劃分為傳統方法和深度學習方法,綜述如下:
按照解決策略準則,傳統機器學習方法中將多標簽分類分為問題轉化和算法適應兩類。問題轉化方法指將多標簽問題轉化為一個或一組單標簽問題,從而運用已有的單標簽算法解決,如標簽冪集(Label Powerset,LP)[7]、分類器鏈[8]等。算法適應方法指通過改進現有單標簽算法以完成多標簽學習任務。例如:Osojnik 等[9]設計了一種基于流式多目標回歸器iSOUP-Tree 的多標簽分類方法;李兆玉等[10]為每個訓練樣本的近鄰集合計算其近鄰密度和近鄰權重,提出了一種基于引力模型的多標簽分類算法;劉慧婷等[11]設計了基于去噪自編碼器和矩陣分解的聯合嵌入多標簽分類算法Deep AE-MF。
基于深度學習模型的多標簽文本分類模型尚處研究階段,并沒有很完整的體系分類,但已經有學者取得了一些成果:Baker 等[12]設計了一種基于卷積神經網絡(Convolution Neural Network,CNN)架構的標簽共現的多標簽文本分類方法;Kurata 等[13]提出了一種新穎的基于標簽共現神經網絡初始化方法;Shimura等[14]提出一種針對短文本多標簽文本的分層卷積神經網絡結構,該方法利用類別之間的層次關系解決短文本數據稀疏問題;Yang 等[15]提出了一種可以“重新考慮”預測的標簽的深度學習框架;宋攀等[16]提出了一種基于神經網絡探究標簽依賴關系的算法執行多標簽分類任務;Liu等[17]針對極端多標簽文本分類中巨大的標簽空間引發的數據稀疏性和可擴展性,考慮標簽共現問題,提出了專為一種多標簽學習設計的新的卷積神經網絡模型;He 等[18]將標簽關聯、缺失標簽和特征選擇聯合起來,提出一種新的多標簽分類學習框架;Banerjee 等[19]將多標簽文檔按層次劃分,制定了一種新的基于遷移學習的分類策略HTrans。序列生成思想應用于多標簽文本分類已有部分成果:Chen 等[4]提出通過將CNN 與RNN組合以捕捉全局和局部文本語義,并通過RNN 輸出標簽序列;Yang 等[5]首次提出將序列生成思想應用于多標簽文本分類;Qin等[6]延續序列生成思想,構建新的訓練目標,以便RNN能發現最佳標簽順序。
綜上所述,深度學習方法被越來越多地應用于多標簽文本分類領域,序列生成模型是多標簽文本分類中一次成功的嘗試,但其標簽序列生成過程中容易產生累積誤差,嚴重影響時間靠后的標簽生成,從而降低標簽標注準確率。本文主要針對這個不足展開研究工作。
2 基于動態路由的RNN序列生成模型
多標簽文本指一個實例被多個標簽標注的文本,多標簽文本分類問題的目標是為每個未分類文本樣本標注合適的類別標簽。形式化地描述為:
假設文本樣本空間X={x1,x2,…,xm},對應包含n個類別的標簽空間Y={y1,y2,…,yn},現有多標簽文本訓練集D=,多標簽分類任務的目的就是利用訓練集D學習到一個分類器C:X→2Y。對于每一個樣本xi,都有一個標簽集合Yi與之關聯[20]。
為更好探究標簽之間的相關性,本文構建了一種基于動態路由的RNN 序列生成模型(DR-DGM),以取得更好的多標簽文本分類效果。
2.1 面向多標簽文本分類的序列生成模型
序列生成模型Seq2Seq(Sequence to Sequence)是一種Encoder-Decoder結構,最早應用于機器翻譯任務中,并在當時取得了巨大成功。其主要思想是通過深度神經網絡將原始輸入的可變長序列映射到另一可變長度的序列中。其中,使用的深度神經網絡通常是RNN,常用的有LSTM 神經網絡和門控循環單元網絡(Gated Recurrent Unit,GRU)。Seq2Seq 模型結構如圖1所示,主要包括三部分:
1)編碼器(Encoder):讀取原始語言序列,將其編碼成為一個固定長度的具有原始語言信息的向量。
2)中間狀態變量:對所有輸入內容的集合。

圖1 序列生成模型結構Fig.1 Architecture of sequence generation model
3)解碼器(Decoder):根據中間狀態變量,得到解空間的概率分布,最終生成輸出可變長序列。
受序列生成模型啟發,有學者創新性地將多標簽分類問題看作標簽序列生成問題。在Encoder 層使用雙向長短期記憶(Bi-directional Long Short-Term Memory,Bi-LSTM)神經網絡+Attention 結構捕獲語義信息,在Decoder 層的每一時刻都進行一次標簽序列生成,預測的標簽集合由各個時刻生成的標簽組成。
序列生成模型利用LSTM 順序地生成標簽以捕獲標簽之間的相關性,但也是由于其順序結構,上一時刻的輸出對下一時刻的標簽生成具有重要影響,如果上一時刻包含錯誤信息,那么下一時刻的標簽輸出大概率也是錯誤的。為了盡可能將上一時刻的正確信息傳導下去,本文受膠囊網絡[21-22]啟發,使用動態路由聚合解碼器結構中的信息,以提升文本語義信息傳遞的聚合效果,從而更好地降低錯誤信息的疊加。
2.2 基于動態路由的解碼器結構及動態路由算法優化
為解決傳統卷積神經網絡無法捕捉圖像特征位置相對關系的缺點,膠囊網絡[21]應運而生。在文本處理中,膠囊網絡中的動態路由過程能捕捉部分-部分、部分-整體的位置信息[22],也能更好地聚合文本語義信息[23]。本文將動態路由過程應用于序列生成模型的解碼器結構中,具體結構如圖2所示。
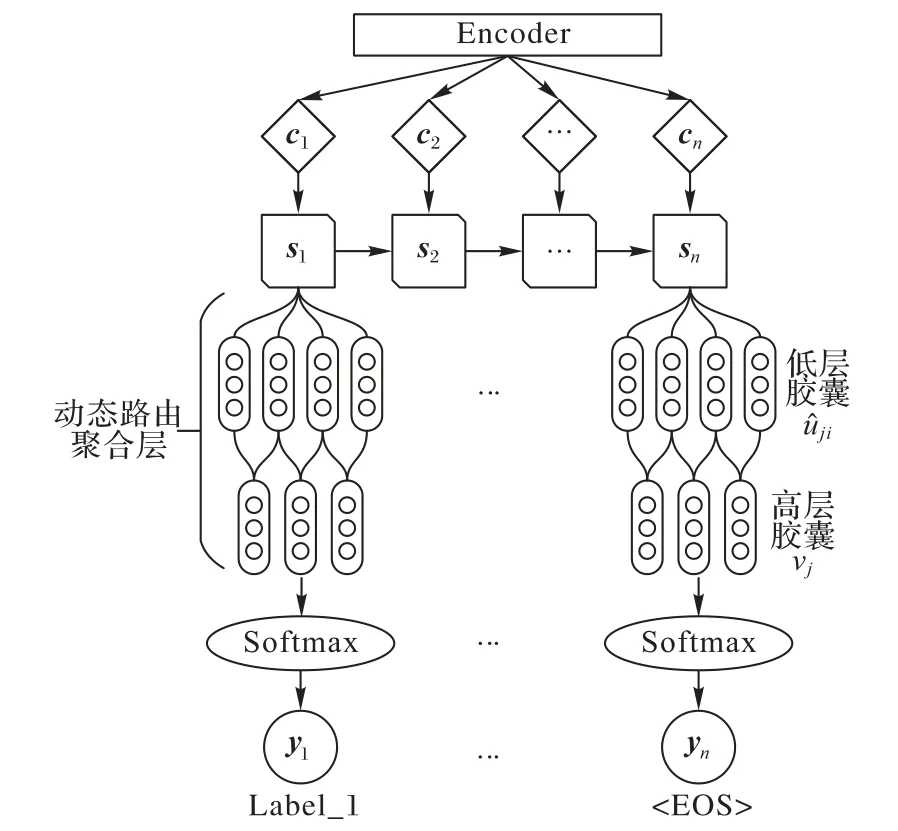
圖2 基于動態路由的解碼器結構Fig.2 Decoder based on dynamic routing
圖2中省略了Encoder層和中間語義變量ci∈{c1,c2,…,cn} 的詳細內容,在計算得到Decoder 層隱含變量si∈{s1,s2,…,sn}后,將其輸入動態路由聚合層(具體的路由優化算法如算法1 所示),最后輸出到Softmax 層進行分類并得到解空間的標簽概率分布,每一時刻的輸出為解空間中概率最大的標簽。其中,標簽的預測以<EOS>標志為結束。此外,動態路由聚合層的參數是全局共享的,這樣能減弱累積誤差產生的影響。
同時,本文探索了兩種策略以優化動態路由的聚合效果。首先,為解決動態路由過程中的類別分布稀疏問題,本文使用sparsemax代替動態路由中的softmax[24],如式(1):
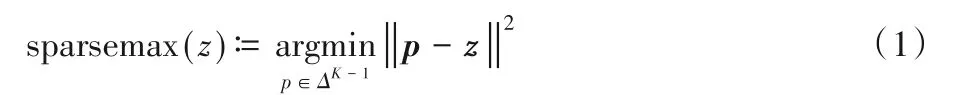
其中:ΔK-1?{p∈RK|1Tp=1,p≥0},表示(K-1)維單形,從RK到ΔK-1的映射能夠更有效地將實際權重向量轉化為概率分布。sparsemax 將輸入向量的歐氏距離投影轉化為概率單形,這種投影方法使得sparsemax 更適用于類別稀疏的情況。其次,為加強低層膠囊到高層膠囊的連接強度,引入高層膠囊權重系數wj(j表示第j個高層膠囊),wj是高層膠囊vj的模(具體計算方法參見算法1中描述),并用于修正下一次低層膠囊對高層膠囊的連接強度,在迭代過程中提升對分類結果有重要影響的膠囊權重。
依據以上兩點改進,設計動態路由優化算法如算法1 所示。其中,squash表示非線性激活函數[21]。
算法1 動態路由優化算法。

綜上所述,本文將膠囊網絡中的動態路由算法進行優化,然后將其與解碼器結構融合,構建了如圖2 所示的基于動態路由的解碼器結構。
2.3 DR-SGM架構
利用2.2 節所提出的解碼器結構及優化的路由算法,設計基于動態路由的RNN序列生成模型框架(DR-SGM),如圖3所示,其中D/R 膠囊圖標具體細節即圖2 所展示內容。模型主要由以下幾個部分組成:
1)輸入層。對原始文本進行預處理,然后使用word2vec詞嵌入技術將其轉換為數字表示的詞向量,模型的輸入為多個詞向量組合得到句子向量。
2)Encoder 層。假設輸入的句子中含有m個單詞,向量化后該句子可表示為(e1,e2,…,ei,…,em),其中ei表示該句子中第i個詞對應的詞向量。Encoder 層使用Bi-LSTM+Attention機制,具體計算過程見式(2)~(5):

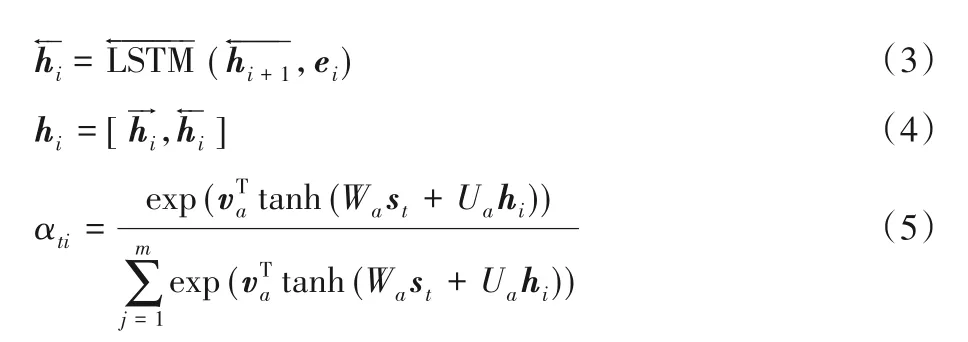
其中:hi表示第i個單詞對應Enocder 層中的隱含狀態,它由i時刻前向LSTM和反向LSTM聯結而成;αti表示在t時刻,Attention 機制為第i個單詞分配的權重;Wa、Ua、都是權重系數。
3)中間語義層。每一時刻的中間語義向量ct由Encoder層中隱含狀態hi計算得到,其計算公式如式(6):

4)Decoder 層。t時刻Decoder 層的隱含向量st首先由中間語義向量ct計算得到,公式如(7)。
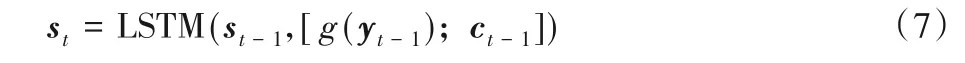
其中:g(yt-1)代表概率分布yt-1中最高概率標簽的全局嵌入[5]。
然后將隱含向量st輸入動態路由聚合層,即圖3中的D/R膠囊圖標。

其中,DR代表動態路由過程,具體內容見2.2節。
5)輸出層。輸出層在每一個時刻都會輸出一個標簽概率分布yt,每次取最高概率標簽作為當前時刻的“標簽序列生成”,yt的計算公式如下:

其中:Wo、Wd和Vd是權重系數;It是為了保證不預測重復標簽的掩碼向量;f是非線性激活函數[5]。
由圖3可知,DR-SGM 模型在SGM+GE(SGM+Global Embedding)模型[5]的基礎上進行了改進,首先,使用sparsemax和迭代權重w優化動態路由策略;然后,添加動態路由層,使用優化的動態路由算法改進解碼器結構,以強化語義聚合效果,捕獲文本關系,削弱因順序結構造成的累積誤差;最后,在以上工作的基礎上,構建基于動態路由的序列生成模型。
算法2 基于DR-SGM的多標簽文本分類算法。
輸入 多標簽文本數據集(x(n),y(n))(n=1,2,…,N),訓練輪數r;

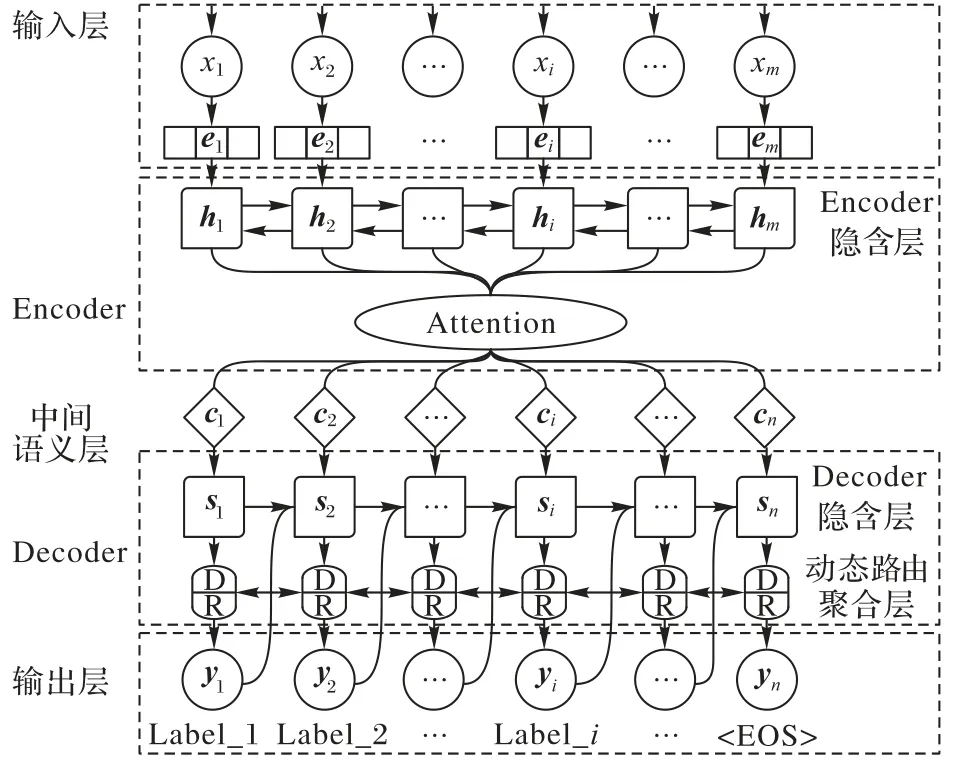
圖3 基于動態路由的RNN序列生成模型(DR-SGM)架構Fig.3 Architecture of RNN sequence generation model based on Dynamic Routing(DR-SGM)
3 基于DR-SGM的多標簽文本分類算法
利用DR-SGM 模型,設計多標簽文本分類算法如算法2所示。首先對文本進行去停用詞、分詞,將其轉化為詞向量后進行本地結構化存儲。句子轉化為詞向量矩陣后輸入DRSGM 模型,通過Encoder 層得到各個時刻的中間語義向量ci,再計算出Decoder 層隱含向量si,轉化為膠囊向量后作為動態路由優化算法的輸入,進行三次路由迭代。最后通過Softmax輸出標簽序列。輸出層在每個時刻的輸出中選擇輸出標簽序列中最大概率的標簽加入預測標簽序列,以<EOS>為序列生成結束標志。每次訓練完成后,在測試數據集上驗證模型分類效果,對模型參數進行迭代更新,共享動態路由層參數,并通過Adam優化器優化神經網絡。
4 實驗設置
4.1 數據集
本文采用RCV1-V2、AAPD 和Slashdot 作為實驗數據集:公開數據集RCV1-V2 是路透社公布的新聞數據集,包含804 414 篇新聞,共103 個主題;AAPD 數據集是arxiv 網站的論文摘要數據集,包含55 840 個論文標題和摘要,共54 個主題;Slashdot 是一個社交網絡數據集,包含24 072 個文檔,共291個主題。數據集的具體信息如表1所示。
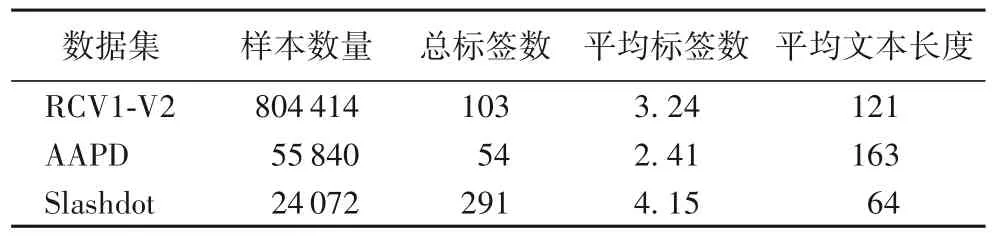
表1 數據集詳細信息Tab.1 Detail of datasets
4.2 評價指標
采用F1 值、漢明損失(Hamming Loss,HL)作為性能評價指標,如式(11)、(12):
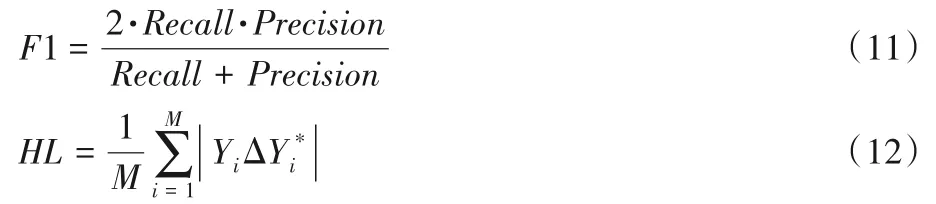
其中:Precision代表準確率,Recall代表召回率,M為樣本數,Yi是真實標簽集合,是預測標簽集合,為樣本預測標簽集合和真實標簽集合的對稱差分。F1 值越大多標簽分類效果越好,而HL是衡量樣本中誤分標簽平均數量的指標,HL越小,誤分標簽數量越少,多標簽分類模型性能越好。
4.3 通用設置
本文實驗基于Tensorflow 框架,使用Numpy、Keras 庫進行開發,編程語言是Python3.6。數據集被隨機洗亂,其中90%作為訓練集,剩余10%作為測試集。詞向量使用預訓練的300 維word2vec 詞向量,不在字典中的低頻單詞用全0 表示。RCV1-V2固定句子長度為500,AAPD 數據集固定句子長度為300,Slashdot 數據集固定句子長度為120,多余截去,不足用0補齊。此外,dropout設置為0.5,學習率設置為0.001,并使用Adam優化器和交叉熵損失函數訓練數據。
5 實驗及結果分析
5.1 基準模型
本文使用以下基準模型與本文構建的DR-SGM 模型進行對比:
1)二值分類(Binary Relevance,BR):BR 算法將多標簽分類任務分解成n個獨立的二元分類問題,每一個二元分類問題對應于標簽空間中的某一特定標簽。
2)分類器鏈(Classifier Chain,CC):CC 將多標簽學習問題轉化為一組有序的二分類問題,其中每個二分類器的輸入都要基于之前分類器的預測結果。
3)標簽冪集(Label Powerset,LP):LP 將多標簽學習問題轉化為多類分類問題進行學習。它將訓練數據集的標簽集合每個不同的標簽子集成為labelset,看作是單標簽分類任務中多類分類問題的不同類別值,然后利用分類器進行求解。
4)CNN-RNN[4]:利用CNN 捕獲全局文本特征后輸入RNN進行局部語義特征捕獲,同時考慮標簽相關性。
5)序列生成模型(SGM)[5]:將多標簽文本分類問題轉換為標簽序列生成問題。
6)SGM+GE(Global Embedding,全局嵌入)[5]:在序列生成模型的基礎上使用Global Embedding。
7)set-RNN(Adapting RNN to Multilabel Set Prediction,自適應RNN)[6]:同樣將多標簽文本分類問題轉換為標簽序列生成問題,提出新的訓練和預測目標,使RNN 能發現最佳標簽順序。
其中:1)~3)是傳統機器學習算法,均使用梯度提升決策樹作為基分類器;4)~7)是基于RNN的深度學習模型。
5.2 動態路由膠囊維數實驗及分析
膠囊維數對動態路由過程有重要影響,膠囊維數過少可能無法有效捕捉文本語義,膠囊維數過多可能導致噪聲出現。因此,本文對動態路由的膠囊數對實驗結果的影響進行了探索,結果如表2 所示。在RCV1-V2 和Slashdot 上,低層膠囊數/高層膠囊數為32/16時取得較好效果。而在AAPD 數據集上,低層膠囊數/高層膠囊數為16/8時取得較好效果。就平均文本長度,RCV1-V2 和Slashdot 數據集中文本更短小,可能需要更多的膠囊進行語義信息捕獲。此外,并不是膠囊數越多,性能越優,也出現了膠囊數增多,性能不變甚至下降的情況,這可能是因為多余膠囊捕獲了額外的無關語義信息,從而對計算結果造成負影響。

表2 膠囊數對實驗結果的影響Tab.2 Effect of the number of capsules on experimental results
5.3 模型評估與分析
在RCV1-V2、AAPD 和Slashdot 數據集上,分別利用F1 值和HL兩個性能指標,測試了上述6 個基準模型以及本文提出DR-SGM 模型,實驗結果如表3 所示,“—”表示不可獲取。其中F1值越大,反映模型性能越好,HL則正好相反。
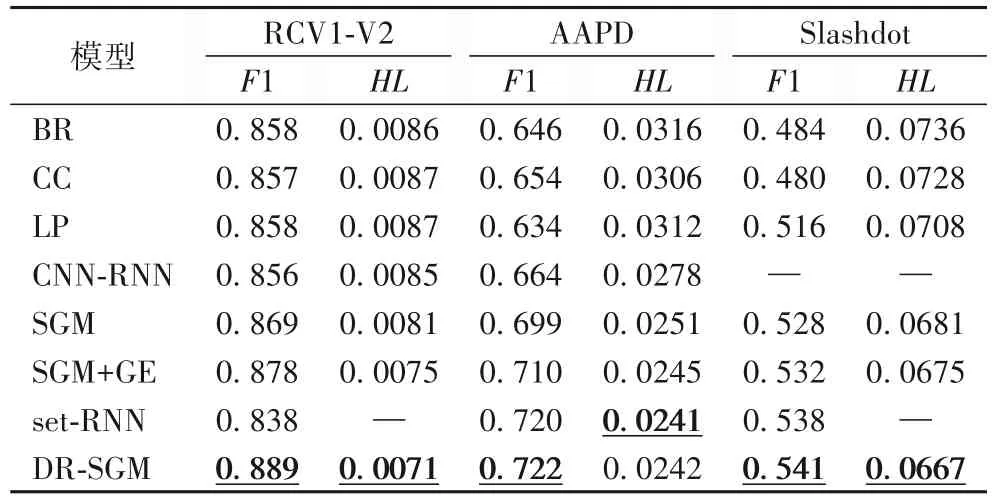
表3 實驗結果Tab.3 Results of experiments
從表3 可以看出(最佳結果在表格中用下劃線標出),在RCV1-V2、AAPD 以及Slashdot數據集上,DR-SGM 模型的大部分評估標準相對于基準模型都取得了最優的效果,只有在AAPD 數據集上,其HL比set-RNN 模型略遜一籌,低了0.4%。然而相對于SGM+GE 模型(在其基礎上改進),在RCV1-V2 數據集上,其F1 值提升了1.25%,HL提升了5.3%;在AAPD 數據集和Slashdot數據集上,其F1值和HL均有一定程度提升。
從實驗結果看,深度學習方法(包括本文提出的DR-SGM以及CNN-RNN、SGM 和set-RNN)相較傳統方法(包括BR、CC和LP 等),無疑有著更加優秀的結果。傳統方法非常依賴于特征工程,而復雜的特征工程往往帶來繁瑣的工作和人工操作錯誤的風險。對于一些復雜的情況,傳統方法由于特征工程的局限常常無法進行處理。而深度學習方法可以自動提取特征,完全消除了特征工程帶來的負面影響。此外,數據集Slashdot、RCV1-V2、AAPD 包含標簽數分別為291、103、54。在各種分類方法下,相對于其他數據集,擁有近三百個標簽的Slashdot分類結果顯然十分不理想,其原因可能是樣本數量與標簽量的不匹配。Slashdot的標簽數量是RCV1-V2的近3倍,AAPD 的5 倍多,但是其樣本量只有RCV1-V2 的約1/30,AAPD 的約1/2,能夠訓練的樣本數量不足以匹配龐大的標簽數,同時文本長度短,能捕捉的語義信息少,因而造成分類評價結果差。然而數據集RCV1-V2 的標簽數是AAPD 的約2倍,其分類效果卻明顯優于AAPD 數據集,這可能是因為RCV1-V2 數據集的樣本數更多,大約為AAPD 的15 倍,因此模型能夠學習到的內容更多,從而分類效果更好。由此可見,多標簽文本分類方法對樣本數量的依賴性很大,同時,標簽數量和文本長度也是影響分類效果的重要因素。
就各種深度學習方法而言,由于在多標簽文本分類任務中,標簽相關性是極其重要的信息之一,捕捉標簽相關性對多標簽文本分類具有重大意義,而CNN-RNN模型中并沒有考慮到標簽相關性問題,但DR-SGM模型通過LSTM順序結構處理標簽序列,每一個生成的標簽都充分考慮了之前標簽的信息,從而取得了比它更好的效果;DR-SGM 模型是基于SGM+GE模型進行優化,相對于原始的SGM 模型或SGM+GE 模型都有一定性能上的提升,其原因可能在于,動態路由方法能夠額外捕獲文本中部分-部分、部分-整體的位置信息,同時因為動態路由聚合層共享了全局參數,削弱了前一時刻的文本信息對后面時刻的影響,從而降低RNN 循序結構造成的累積誤差。set-RNN模型通過數學方法修改模型訓練的方法和目標,使其能發現最佳標簽順序,誤分標簽數較少,Hamming Loss指標表現更好,但是,相對于DR-SGM,它在有效捕捉文本語義方面略微遜色,因此F1值結果略遜一籌。
綜上所述,無論是和傳統方法相比,還是和現有的深度學習方法相比,DR-SGM都取得了有競爭力的結果。
6 結語
本文沿用將序列生成模型應用于多標簽文本分類的思想,將多標簽文本分類看作一個標簽序列生成問題,不同于以往的解碼器結構,本文借鑒膠囊網絡思想,將動態路由應用于序列生成中的解碼器結構,構建了DR-SGM 模型。在Encoder層,通過使用BiLSTM+Attention 結構最大限度捕捉語義信息;在Decoder 層,增加了動態路由聚合層聚合文本信息,從而額外捕獲了文本中部分-部分、部分-整體的位置信息,同時通過在全局范圍內共享動態路由參數,在一定程度上減輕了序列生成產生累積誤差的負面影響,而且,在設計的動態路由算法中,為解決路由過程中類別稀疏問題,采用sparsemax 代替Softmax;為加強低層膠囊到高層膠囊的連接強度,引入權重系數w在動態路由過程進行迭代加權。此外,面向多標簽文本分類領域,制定了基于DR-SGM 的多標簽文本分類算法,實驗結果表明,相比7 個基準模型,本文設計的DR-SGM 模型取得了較好的分類效果。
在多標簽文本分類領域,仍然有許多問題值得探索,例如序列生成模型極度依賴標簽順序,而在現實生活中標簽集合是無序的;同時多標簽文本中往往存在大量樣本不均衡的情況,對部分類別標簽樣本的偏向性會嚴重影響分類模型的分類效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
