礦山設備預測性維修大數據分析系統的建設
2020-08-15 13:28:34王曉云
科技創新導報 2020年17期
王曉云
摘? ?要:本文介紹了大數據分析系統概念及在礦山設備預測性維修中的應用,形成一套符合應用實際的礦山設備預測性維修大數據分析系統,其中包括前端數據采集、中層數據傳輸與存儲(狀態監測)、后端數據分析及系統優化(故障診斷、狀態預測、維修決策)等。預測性維修以“相似學模型(Similarity Based Modeling - SBM)”的大數據設備診斷技術為基礎,結合設備故障的歷史和現狀,參考運行環境及其它同類設備的運行情況,采集數據、挖掘建模,對設備運行情況進行綜合判斷分析,提前判斷設備內部可能出現故障和異常的情況,確定預測隱患的發展趨勢,提出防范措施和治理對策,進而延長設備使用時間,降低成本、提高產能。
關鍵詞:大數據分析? 預測性維修? 相似性建模算法? 數字化雙胞胎
中圖分類號:TD67? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻標識碼:A? ? ? ? ? ? ? ? ? ? ? ?文章編號:1674-098X(2020)06(b)-0006-04
近年來,國務院印發了一系列政策措施推進大數據發展,其中包括《關于深化“互聯網+先進制造業”發展工業互聯網的指導意見》中提到“開發工業大數據軟件,聚焦重點領域,圍繞生產流程優化、質量分析、設備預測性維護、智能排產等應用場景,開發工業大數據分析應用軟件,實現產業化部署”。礦山設備預測性大數據分析系統的建設是以“降本增效”為目標,以實現傳感器、設備和生產系統的自動化和智能化為手段,在數據監測、可視化、基本統計計算、超限報警的基礎上,更好地利用收集的數據,基于相似性算法,針對每臺設備進行模型數據訓練,建立每一臺設備專有的數據模型,利用大數據分析結果預測性診斷設備潛在故障,達到提升安全保障、減少設備非計劃停機、提高維修效率、降低維修成本、提高設備運用效率的結果。
1? 大數據分析概念
1.1 大數據分析概論
大數據的特殊之處主要體現于:體積、速度、質量。其中體積是指由于數據格式的多樣化造成的數據存儲指數級增長;速度與數據的變化率有關;質量體現在數據的多種格式存儲,這種情況下,應該考慮如何處理各種格式的數據[1]。
大數據分析主要遵循三個基本概念。
(1)大數據分析是宏觀數據分析,需要通過充分觀察所有收集數據整體的本質、特征、屬性及規律,而非通過樣本圍觀觀察,否則將切斷數據和現象之間的聯系,無法實現大數據分析的目的。
(2)在大數據時代,面對大量數據的挑戰,知道什么比知道為什么更重要。大數據分析在數據采集的基礎上,通過不同算法將數據進行清洗、分析,最終實現數據挖掘和預測分析。
(3)大數據分析偏向于發現事先不知道的新模式及目前未知的相關性,通過利用可能發現的新模式及未知相關性探索即將發現的事件本質,過程中時間和成本的意義將重于所謂準確的結果。
1.2 大數據分析應用
1.2.1 數據挖掘
大數據分析的理論核心就是數據挖掘。數據挖掘即從數據獲取到深度學習,通過機器深入數據內部去挖掘價值。其中本文大數據分析系統中數據收集匯總后采用的算法是相似性建模算法。
1.2.2 預測性分析
預測性分析及利用數據挖掘的結果做出預測性判斷。預測性維修系統結合大數據分析結果形成動態的報警限值,對設備狀態進行預判。
2? 礦山設備預測性維修系統建設意義及存在問題
2.1 建設意義
目前大部分設備維修主要以故障維修和計劃性檢修為主。
(1)故障維修,又稱事后維修,如設備發生部分或全部故障后再修理,是一種非計劃性的、純被動的維修方式。這將對正在運行的設備帶來破壞,極大降低設備的生產效率;這種盲目、失控的狀態無法對維修計劃進行安排,將造成備品備件庫存積壓嚴重或急缺無法及時維修。
(2)計劃性檢修,又稱預防性檢修,針對設備的維修間隔期制定維修計劃,按規定的時間間隔進行停機檢修,這樣可以消除可能的和隱藏的故障,預防設備未知的損壞、繼發性毀壞。但是這種維修方式會由于頻繁維修造成維修資源浪費、造成生產和管理的矛盾激化,降低設備可用性或生產效率。
礦山設備預測性維修是基于以上兩種維修方式缺點采用的一種新興的維修方式。在機器運行時,通過采集設備運行相關數據,初步獲取設備狀態信息。對其重要部位進行不間斷的狀態監測和故障診斷,預測設備未來的發展趨勢,提前預測設備故障模式以制定有效維修計劃,確定設備修理時間、內容、方式和必需的技術和物資支持。
這種預測性維修方式包含狀態監測、故障診斷、故障預測、維修決策支持和維修活動。存在以下優點:
①以設備實際狀態為依據,減少可能出現的密集維修,延長了維修周期,提高設備利用率的同時也節約維修費用。
②預先診斷得出潛在故障,有效避免可能爆發的繼發性或突發性的意外事故,保證安全生產同時降低生產損失。
③對維修資源進行宏觀調控,減少備品備件庫存和積壓,大幅降低維修費用。
④提前安排生產維修計劃,最低限度降低維修與生產中存在的設備使用矛盾,優化排產。
2.2 存在問題
由于設備預測性維修要通過狀態監測、故障診斷、故障(狀態)預測進而實現維修決策。但目前設備狀態數據監測手段及能力不足,無法對所有設備的實時數據進行全面采集和分析。
(1)因生產控制設備多數購置時間較早,設備廠家不同,沒有統一的接口規范,造成設備信息采集困難,急需對傳感、控制層進行增補或完善。同時,也沒有統一的監測監控平臺進行采集和集中控制,系統間、設備間的直接溝通和綜合利用還有很大的提升空間。
(2)數據的二次分析和利用不充分。對已經采集到的數據,未能充分的分析和挖掘,不能及時用數據反映和預測生產及設備的實時狀態,無法進行全面準確預測性維修,會在維修中存在事后維修、過度維修或欠維修情況,影響維修效率和成本。
3? 礦山設備預測性維修大數據系統的建設方案
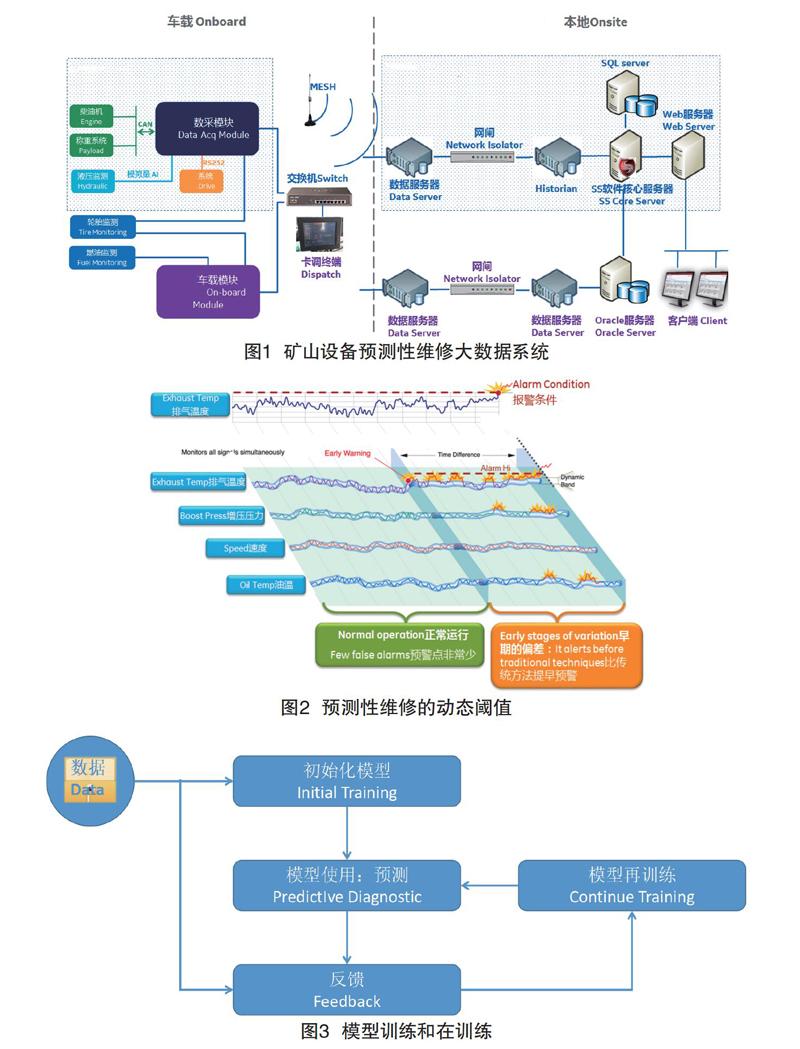
本系統采用“相似學模型”的大數據預測診斷分析技術,對所有采集數據進行實時分析。以MT4400礦用卡車為例(如圖1):預測性診斷將通過柴油機、稱重系統、液壓監測系統、胎壓監測系統、燃油監測系統等多個傳感器提供的數據,集中由數采模塊匯集,獲取每臺設備的歷史數據,進行模型匹配、數據清洗,按照現行工況獲取正常運行數據訓練模型,結合當前狀態及模型訓練結果,并形成動態的報警限值。這樣即使設備沒有滿功率/滿負荷運轉,仍可預判設備異常,在故障早期報警,及時獲得維修維護,避免設備發生不可逆損傷或意外停機[2]。
3.1 數據采集
3.1.1 柴油機的CAN接口數據
通過從柴油機到數據采集模塊的線束改造,以讀取發動機數據,通過數據采集模塊發送到工控機。采集以下7個數據點:坐排前部進氣溫度、機油壓力、柴油機轉速、柴油機力矩、燃油溫度、冷卻液壓力、冷卻液溫度。預期可實現柴油機以下方面的預測性診斷:
(1)渦輪增壓器:增壓不足或機械磨損;
(2)冷卻系統:冷卻損失;
(3)燃油系統:溫度/壓力異常、燃油稀釋(機油/水)問題。
3.1.2 稱重系統的CAN接口數據
新增稱重系統,讀取裝載重量和懸掛壓力。采集以下6個數據點:載重、傾角、左前懸掛壓力、右前懸掛壓力、左后懸掛壓力、右后懸掛壓力。預期可實現以下故障的預測性診斷:
(1)懸掛的壓力異常、泄漏方面的預測性診斷;
(2)結合其他信息可對稱重系統的傳感器故障進行判斷。
此外,稱重系統的數據也作為模型輸入,幫助進行電動輪電氣、制動、輪胎方面的預測性診斷。
3.1.3 輪胎監測系統的網口數據
安裝輪胎監測系統,實現將輪胎檢測系統數據傳輸至卡車工控機。采集以下12個數據點:左前輪胎壓力、右前輪胎壓力、左后輪胎1壓力、左后輪胎2壓力、右后輪胎1壓力、右后輪胎2壓力、左前輪胎溫度、右前輪胎溫度、左后輪胎1溫度、左后輪胎2溫度、右后輪胎1溫度、右后輪胎2溫度。可結合稱重系統數據,對輪胎的漸進性故障進行預測性診斷:
(1)輪胎壓力異常;
(2)輪胎溫度異常。
3.1.4 電傳系統的RS232串口數據
基于串口提供數據,進行線束的改造,通過數據采集模塊讀取數據并傳到工控機。采集以下11個數據點:加速踏板位置、電制動狀態、左后輪馬達速度、左后輪馬達力矩、右后輪馬達速度、右后輪馬達力矩、母線電壓、母線電流、啟動電池電壓、風冷溫度。結合稱重系統、采油機數據,可進行如下診斷:
(1)電動輪的基本監控狀況;
(2)控制柜冷卻。
啟動電池電壓可用于柴油機不能正常啟動相關故障的診斷,包括充電機、皮帶的異常。
3.1.5 液壓壓力的模擬信號
改造卡車上的液壓管路并且安裝油壓、油溫傳感器將數據通過AI接口發送到數據采集模塊。采集如下7個數據點:舉升壓力、轉向壓力、前制動壓力、制動蓄能器壓力、后制動壓力、駐車制動壓力、液壓油溫。可進行壓力相關的預測性診斷:
(1)漏油、壓力損失、轉向異常;
(2)結合卡車工作狀態(柴油機、稱重系統、電氣數據),診斷壓力傳感器本身的故障。
3.2? 數據傳輸與存儲
通過礦區現有的無線網絡將移動設備的數據從卡車工控機上傳送到本地HISTORIAN服務器。通過車載數據采集終端將數據經CAN2.0B總線實時傳送給車載工控機,傳送周期為500ms。在工控機上安裝數據采集器程序,數據采集器程序支持斷點續傳,工控機上的數據采集器通過4G網絡,將工控機上的設備數據,傳送到HISTORIAN服務器上。HISTORIAN實時數據服務器將作為存儲采集的所有實時數據源的核心數據庫,用于檢測分析設備應用狀態。為了實現信息傳輸和網絡運行的安全保障,同時部署單向物理隔離網閘,將卡車生產側的網絡與預測性分析系統進行網絡隔離,有效防范可能發生的內部和外部的非法攻擊。
HISTORIAN對數據的存儲是以文件形式存儲,通過采集、存儲及分發的存儲機制,使歷史數據具有高效、可用及開放的特性,實現數據層級結構化、高壓縮、安全、強健的冗余機制。
3.3 數據分析
預測性維修的關鍵技術在于預測分析技術。本系統采用了相似性建模算法,該算法是一種多參數預測方法,其他建模技術如主成分分析和神經網絡等,在面對品質不高的數據時會很困難。很多建模技術要做大量計算,相似學模型技術在現成的商業化Intel硬件以及普通的微軟軟件的運行環境下,即可根據每隔5~10min的采集數據實現數千個數據點的高級建模。設備的建模被劃分成了多個邏輯模塊,每個模塊包含互相關聯的參數以及進行預測所需要的參數。根據每個模塊,可以預測性地判斷設備性能降低的主要因素,并根據相應的設備組件定位故障。同時系統針對一臺設備、利用其正常工作狀態的多個測點的歷史數據,為每臺設備建立獨立的數據模型。由于使用了來自于多個傳感器的多種數據,可以有效抑制干擾和容錯。
圖2闡述了常規報警方式與預測性診斷的區別。
常規報警方式設置固定的報警條件或報警觸發限值,只有監測到的狀態值超過報警限值時,才會觸發報警。此報警觸發限值的設置不可過低,以免造成過多的誤判斷,報警頻發,引起不必要的停工以及人工檢查;另一方面,限值的設置也不可過高,否則將導致設備已經發生不可逆轉或巨大的損傷。當設備沒有滿功率/滿負荷運轉時,即使設備有損傷,也由于沒有達到觸發條件,無法觸發報警。
針對MT4400礦用卡車的不同子系統有效收集所有數據進行大數據分析進而預測性診斷,現有模型可以涵蓋如下子系統的診斷:
(1)柴油機子系統:渦輪增壓器、空氣過濾器、后冷卻缸、油缸、冷卻系統、潤滑油系統;
(2)懸掛子系統:懸掛、輪胎;
(3)液壓子系統:制動器冷卻、制動器液壓、轉向;
(4)傳動子系統:機械變速器;
(5)電傳驅動系統:電機、傳動裝置、發電機。
3.4 系統優化
系統優化是基于“數字雙胞胎”理論上對設備預測性維修的完善。
“數字雙胞胎”[3]即數字孿生,可以在虛擬數字模型和現實物理對象間建立映像。包括產品數字雙胞胎、生產工藝流程數字雙胞胎、設備性能數字雙胞胎三個階段,以上三項前后形成不斷循環,服務于產品全生命周期。其中設備數字雙胞胎用于故障預測、健康管理及預測性維護,并回饋運行信息用以優化設計、改善產品性能。
在設備使用過程中,各參數都可能發生相應的變化:
(1)系統會根據變化的情況,使用新的歷史數據,對模型進行再訓練:
(2)工作環境條件超出預定范圍,設備負載不再滿足原始設定;
(3)設備出現新的工作狀態,不確定能否在正常的工作條件下健康運行。
根據“數字雙胞胎”的概念,通常在初始模型訓練完成后,在后續的使用過程中繼續模型的維護性訓練,使用新的數據對模型進行再訓練和優化。
4? 結語
大數據分析與預測性診斷維修的完美結合實現了礦山設備預測性維修,這個案例可復制推廣到其他露天煤礦,提升我國露天煤礦設備管理水平,但預測性維修只是大數據應用的冰山一角。實際上,近年來數據集成、數據清洗、數據統計[4]以及各類聚類算法、分類算法、回歸算法、關聯算法、增強算法的衍進,從數據獲取到深度學習全方位提升大數據分析的使用效率、應用領域,下一步可以以國家戰略、市場需求、人民需要為牽引,不斷促進大數據在農業、能源、交通、醫療等領域融合發展,同時與工業互聯網、工業大數據、工業云協同發展,推動制造業數字化、網絡化、智能化轉型[5]。
參考文獻
[1] 景宇.基于大數據分析的農化產品物流網點規劃[D].南京郵電大學,2019.
[2] 鄧筑鑫.預測性維修分析系統在露天煤礦設備上的應用[J].電腦編程技巧與維護,2017(21):91-94.
[3] 華應強,王啟發.抽水蓄能機組數字雙胞胎(運維檢修)研究與實施[J].黑龍江水利科技,2019,47(6):136-138.
[4] 國家工業信息安全發展研究中心.大數據優秀產品案例[M].北京:人民出版社,2017.
[5] 梁棟,張兆靜,彭木根.大數據、數據挖掘與智慧運營[M].北京:清華大學出版社,2018.
