基于網絡文本的廈門形象感知分析
2020-08-25 06:00:14萬英亮
經濟技術協作信息 2020年23期
◎萬英亮
以網絡評論文本為素材,使用網絡爬蟲獲取網絡評論數據,利用長短期記憶網絡(LSTM)建立三分類的情感分析模型,采用文本關聯性分析和依存語法分析對評論中的核心詞與語法進行研究,對廈門的整體形象、吸引要素、負面評價等多個方面進行分析。結果顯示:整體來看游客對廈門的印象總體傾向于積極方面,負面感知很少,游客對廈門的感知比較偏向于自然風景與美食。但吸引要素中,歷史人文景點相對較少提及,作為一座擁有悠久文明的城市,廈門為實現成為文化、人文、文藝之城仍需努力。
一、引言
自1975 年Hunt 首先提出旅游目的地形象,有關目的地形象的研究就隨著科學技術的發展而不斷深入。旅游目的地形象是指旅游者對于目的地的感知之和,學術界普遍將其分為認知形象、情感形象和總體形象三部分。
隨著硬件能力的提升以及數據量的增長,利用網絡文本數據和數據分析工具來對旅游目的地形象進行深入分析成為可能。同時,也為管理者制定優化目的地形象的方案提供了參考依據。
使用網絡評論文本進行情感分析能夠對社會輿情進行預測,這是文本情感分析技術受到重視的原因。人工神經網絡在文本領域的廣泛應用,為文本情感分析的突破提供了可能。2011 年,哈工大推出了中文語言技術平臺(LTP),因其優秀的中文文本處理能力,而使它受到中文自然語言處理研究者的歡迎。
廈門歷史悠久、海天一色,素有“海上花園”的美稱,榮獲“聯合國人居獎”。由于知名度和關注度較高,有關廈門的旅游評價容易抓取,因此選擇廈門為研究對象,利用Python 爬取數據,并將原始數據處理后進行分詞;通過LSTM 進行情感分類;計算網絡評價中關鍵詞的相關性;使用LTP 進行依存語法分析,進而對廈門的總體形象、積極形象、消極形象以及影響因素進行分析,以期確定廈門在游客心中的形象,為廈門旅游的可持續發展提供幫助。
二、研究方法與數據來源
(一)研究方法
1.分詞方法。任何文本都需要經過斷詞處理方可進行分析,但中文斷詞相較于英文斷詞顯得困難許多,因為中文有兩種特色,其一,詞間不用空格分隔、其二,一字可以位于詞首詞中或詞末,也可以單字成詞,這兩種特色使得斷詞結果產生歧義,且很難保證任一結果百分之百準確。
本文使用jieba 分詞處理中文分詞問題。在分詞前,jieba 分詞載入詞典至一前綴樹中,接著對每一語句分詞時,利用詞典生成的前綴樹生成一有向無環圖,該有向無環圖的每一節點代表語句的長度位置、每一條邊代表jieba 分詞查找前綴樹所得可能存在于句中的詞語,而每一條完整的路徑代表可能的分詞方案。
2.關聯性分析。對文本關鍵詞關聯性的分析是挖掘文本信息的一種重要技術。本文對核心關鍵詞相關性進行計算過程中使用了關聯規則,它是形如的邏輯表達式,和為不相交的集合。關聯規則用支持度和置信度來度量關聯的強度,支持度確定規則可以用于給定數據集的頻繁程度,而置信度確定在包含的事務中出現的頻繁程度。支持度和置信度:
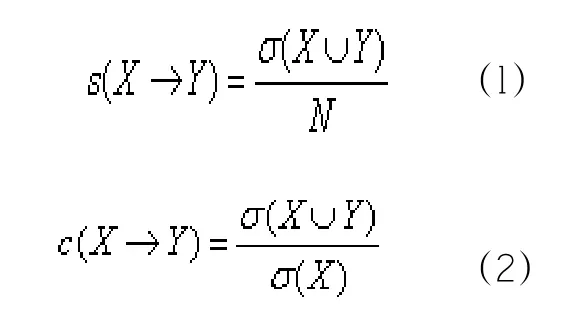
3.依存句法分析。利用分析句中單位間依存關系來確定其句法結構是依存語法分析的核心思想。依存句法分析的依存關系有五條公理,具體如下:
(1)句子中僅含一個獨立成分。
(2)句子中的其它成分都依存于某一成分,每個詞都會有入口。
(3)句子中各成分不能同時依存于兩個及以上的其他成分,即每個單成分不會有兩個入口。
(4)如果成分依存于成分,在句中位置位于和之間,則或直接依存于,或直接依存于和間的某一個成分,這對成分的具體范圍進行約束,避免了交叉。
(5)中心成分(核心動詞)的左右兩面成分相互的不產生依存關系。
4.長短期記憶網絡。長短期記憶網絡在循環神經網絡(RNN)的鏈式結構中加入LSTM 單元,通過不同的門限控制,可以加強模型的記憶能力,解決訓練過程中梯度消失的問題。LSTM 廣泛運用于處理序列信息,在文本分類領域有較好的表現。
(二)、數據來源
本研究以廈門為例,使用Python 對同程網進行評價數據爬取。在爬取過程中將重復、無意義以及包含廣告的評價刪去。共搜集了2014 年1 月1 日至2016 年7 月10日的4010 條游客點評。
三、實證分析
(一)整體形象分析
1.評論數據預處理。在去除原始文本數據中無意義詞和英文字符之后,使用Python 環境下的jieba 庫對文本數據分詞進行處理。將處理后的網絡評價數據用Python 環境下的wordcloud 庫進行處理,得到了游客對廈門評價的高頻詞詞云圖。

圖1 廈門網評詞云
詞云中詞的形狀大小表明了詞語在網絡評價出現的頻率高低。
2.評論數據LSTM 情感分類。將游客對廈門的評論文本按照情感傾向性進行分類,根本上仍屬于文本分類問題,本文將主觀性的網絡評論文本分為積極、中性、負面三種情感傾向。將酒店、旅游以及電影點評網站收集積極到的積極、中性、負面評論各15000 條作為LSTM 情感分類的訓練集,將原始數據作為訓練集通過Python 環境下的gensim 庫進行詞向量化后經LSTM 迭代20 輪。
使用訓練好的模型對測試集文本數據進行情感分類的精度達到0.8742,分類效果很好,表明適合用于對文本情感傾向性的分析。將分類數據同真實得分進行比較,可知使用LSTM 進行網評情感分類結果與真實結果基本接近,并且絕大部分游客對廈門持有積極態度,只有少數游客對于廈門存在一定的負面情緒。
3.評論數據關鍵詞關聯性分析。對網評數據分詞結果的頻率前30 個關鍵詞進行建模,得到關聯規則結果,顯示“鼓浪嶼”支持度僅次于最高的“廈門”,被確認為是次核心詞,說明“鼓浪嶼”最深受來到廈門游客的喜愛。
在游客對于“鼓浪嶼”、“廈門大學”等標志性旅游景點游玩后很有感觸說明網友,且“喜歡”常出現在“廈門”相關的評論中,說明游客對廈門給出的評價主要是正面的。
(二)積極感知因素分析
本文使用依存句法分析對游客積極感知因素進行探索。依存句法分析結果顯示了語句中元素的具體結構,以“廈門風景很好”短句為例:
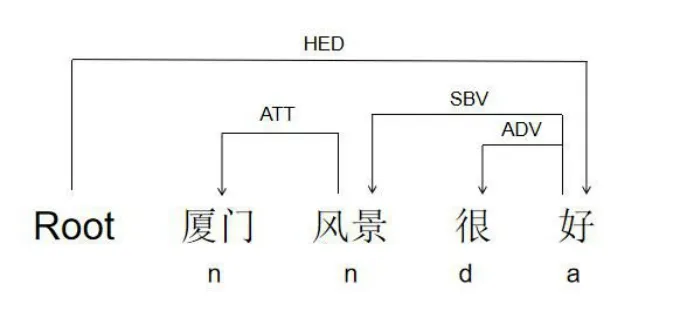
圖2 依存句法分析示例
如圖2 所示,該短句中存在3 組相互依存關系,每組依存關系都有一個核心詞與一個受支配詞組成,圖3 中折線從核心詞指向受配詞。如“風景”和“好”為主謂關系(SBV),,受支配詞為“風景”,核心詞為“好”,短句中的核心詞(HED)為“棒”。通過依存句法分析從游客評論數據中提取廈門特征與情感態度組合,分別繪制出廈門特征、情感詞云圖如下圖所示。

圖3 依存句法提取廈門特征詞云

圖4 依存句法提取情感詞云
由圖3 可知。特征詞主要有:“廈門”、“鼓浪嶼”、“廈門大學”、“曾厝垵”、“中山路”、“海鮮”、“環島路”、“海灘”、“芒果”、“小店”。對特征詞進一步歸類,可以發現在游客看來,自然風光是廈門最突出的特征。可以說絕大多數的游客就是為了欣賞海島風景而來到廈門的。其次是美食類的詞語:芒果、海鮮,這充分說明飲食是廈門重要的吸引要素。而胡里山炮臺、曾厝垵 、南普陀寺、梵天寺等人文歷史景點無論從詞匯數量還是頻率上都較低。
從圖4 可以看出,游客對廈門的印象以“好吃”、“喜歡”、“清新”為主。游客對于廈門的第一感覺用“好吃”這樣的詞語來形容。可見美食是廈門一個明顯的特征。廈門的特色美食給游客留下的深刻的影響,尤其是經營了數十年的廈門老字號總讓游客們流連忘返。“清新”表達了游客對廈門空氣質量的評價,作為環海城市,徐徐海風是廈門俘獲游客心靈的法寶。
(三)消極感知因素分析
本文對游客的負面評論進行概念化、逐一登錄并提煉,經過三級編碼過程,最終將這些負面評論凝結為5 個核心類屬、16個二級子類。5 個核心類屬分別為旅游體驗、旅游設施、旅游安全、旅游服務與旅游環境。
可以得知,在5 個核心類屬當中,負面評價主要集中在旅游體驗類屬上(71。23%),排在首位。游客普遍認為物品價格虛高、商業化嚴重。除此之外,也有游客提出太多的小店商品相似,十分乏味。另外就是游客太多、環境嘈雜,降低了旅游體驗質量。旅游環境是排名第二的消極感知因素。其中交通問題最為突出,廈門風景優美,但部分景點規劃不佳,道路狹窄,加之游客眾多,時常造成寸步難行的交通環境。此外餐飲企業油污排出;旅游安全方面如小偷很多,要留意自己的隨聲物品;旅游服務方面如店員態度冷淡等負面評論也有出現。
四、結論與思考
隨著大數據時代的到來,如何從非結構化的網絡評論數據中挖掘出游客的觀點以及隱含的語境情感信息,繪制出旅游者角度的旅游目的地形象是新環境下旅游工作者要面臨的挑戰。
本文通過構建LSTM 三分類的情感分析模型,對文本數據進行文本關聯性分析以及依存句法分析,對廈門的認知形象、情感形象、整體形象、吸引要素、負面評價及原因進行探究,可知從認知形象構成要素來看,特色景點和美食為突出的要素,包括鼓浪嶼、廈門大學等標志景點;芒果、沙茶面等地方美食。而歷史人文景點,如胡里山炮臺、曾厝垵、卻較少被游客提及。從形象情感態度來看,游客普遍認為廈門“不錯”、“好吃”、“清新”。說明游客對廈門總體評價比較積極,滿意度較高。游客對廈門的負面旅游體驗主要歸類為旅游體驗和旅游環境兩大方面,其中的商品因素最為突出,游客認為廈門商品價格過貴、道路狹窄、環境嘈雜等。作為一座擁有悠久文明的城市,廈門需要加大對歷史人文景點的重視和開發,并且對游客的負面評價做出及時反饋,這有利于廈門旅游產業的健康和可持續發展。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
小學教學參考(2015年20期)2016-01-15 08:44:38
數學大王·低年級(2014年7期)2014-08-11 16:36:44
語文知識(2014年1期)2014-02-28 21:59:13
