結合分層和ADMM 的高光譜圖像解混方法
2020-08-31 01:39:40房森焦淑紅
應用科技 2020年3期
關鍵詞:實驗
房森,焦淑紅
哈爾濱工程大學 信息與通信工程學院,黑龍江 哈爾濱 150001
高光譜遙感成像技術是在多光譜遙感成像技術的基礎上發展而來的,高光譜遙感的出現可以稱得上是遙感技術的一場革命。高光譜成像傳感器單位照射面積比較大,因此混合像元[1?2]現象在高光譜圖像中普遍存在。混合像元的存在是影響遙感圖像分類精度和目標探測效果的重要原因。光譜解混是處理混合像元的主要技術,目的就是了解混合像元內參與混合的成分以及它們各自所對應的比例,是一種更精確的分類技術。由于線性混合模型(linear mixing model, LMM)[3?5]具有物理意義明確且使用簡便,在多數的光譜解混方法中均使用LMM 對高光譜數據進行建模。該模型潛在假設一種地物種類可以用一條單一的光譜曲線完全表示,對光譜變異(spectral variation, SV)[6?7]現象考慮不周。為了應對光譜變異,使用一種擴展 的 線 性 混 合 模 型(extended linear mixing model,ELMM)[8]對高光譜數據進行建模。
文獻[9]提出了一種基于分層的高光譜解混技術,通過分層的思想,把復雜的問題分解成若干層計算,以此降低總的計算量。乘子交替方 向 法(alternating direction method of multipliers,ADMM)[10]是一種求解優化問題的計算框架,適用于求解分布式凸優化問題。ADMM 通過分解協調過程,將大的全局問題分解為多個較小、較容易求解的局部子問題、并通過協調子問題的解而得到大的全局問題的解。本文提出了一種將分層解混算法和ADMM 優化算法相結合的高光譜解混算法,該算法同時利用了分層算法和ADMM 的特點,并利用模擬數據和真實數據對該算法進行實驗。
1 擴展的線性混合模型
ELMM 主要用于克服由光照條件以及地形變化引起的SV,而且同時保持了LMM 的特點,并證明了該模型的有效性。傳統的線性混合模型表達式為
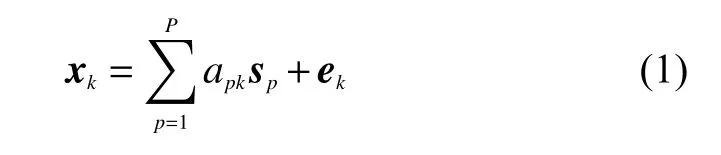
式中: xk表示第k 個像元,是一個向量,維度和光譜圖像的波段數相等;P 表示高光譜圖像中總的端元種類; sp表示第p 個端元,維度和像元的相同, apk表示第p 個端元在第k 個像元中所占的比例; ek表示噪聲,維度也和像元相同。將式(1)運用到整幅圖像則可以將其寫成矩陣形式:
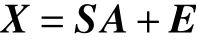
考慮到實際場景中存在SV,可以將一種映射關系作用到端元向量上,那么式(1)可以重新寫為
這種映射關系表示成 fpk,作用到對應的端元上就表示端元產生了變異,傳統的LMM 在描述高光譜數據時具有的特殊優點,同時考慮SV 和LMM時,令 fpk=ψksp,則式(2)可以重新寫為
式(3)只是通過一系列不同的非負縮放因子ψk在像元層面上進行縮放以表示因光照條件或地形因素引起的SV。在實際情況下,通常需要考慮到每種物質所產生的變異。因此可以將式(3)寫為
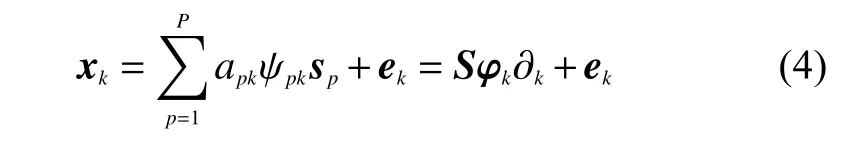
式中: ψpk是取決于具體地物種類和像元的縮放因子; φk∈RP×P是一個對角矩陣,對角線上的元素是P 個端元的縮放因子,其中縮放因子也可以用Ψ ∈RP×N表示,該矩陣與豐度矩陣大小相同。對于整幅圖像來說,式(4)可以寫成:
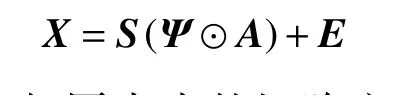
式中 ⊙表示2 個相同大小的矩陣之間逐項進行相乘。這就是ELMM 的矩陣表示,當所有的縮放因子 ψpk等于1 時,該模型將退化為傳統的LMM。
2 分層解混算法和ADMM 算法
Roberts D 等[11?13]提出的多端元高光譜解混算法不是針對每個像元采用固定的端元集,而是為每個像元迭代生成與之最為匹配的端元集,該算法解混精度較高,但是需要窮盡列舉光譜庫中端元的所有組合,所需的計算量也非常大。基于分層的高光譜解混算法,是將復雜的問題化解成若干個層面進行計算,以此來降低計算的復雜度。ADMM 是一種求解優化問題的計算框架,適用于求解分布式凸優化問題。
2.1 基于分層的高光譜解混算法
分層的解混思想[1]是在第一層的計算中可以根據得到的豐度系數,確定該像元中所包含的地物種類以及所對應的地物種類中最佳的類內端元,并選擇出豐度系數最大的那類地物所對應的端元。在接下來的計算中以該端元為基準進行多端元組合。
假設高光譜圖像對應的地物種類為3 種,且每種地物所包含的類內端元分別為3 種、2 種、2種,記為 M1,1、 M1,2、 M1,3、 M2,1、 M2,2、 M3,1、 M3,2,則對應的端元集表示為E={M1,1,M1,2,M1,3,M2,1,M2,2,M3,1,M3,2}。
1)在第一層利用端元集E 對像元 ykpixel進行解混,選出每個地物種類所對應的最大非零系數,假設}確定的地物種類以及類內光譜為{M1,1,M2,1,M3,1,然后分別計算 M1,1、M2,1、 M3,1與之間的光譜角距離,假設光譜角距離最小的端元為 M1,1;
2)在第一層確定的端元集合的基礎上分別與M1,1進行兩端元組合,分別記為{M1,1,M2,1}和 {M1,1,M3,1},然后分別計算與之間的光譜角距離,選擇出光譜角距離的最小值所對應的端元組合,在此處假設為 {M1,1,M2,1};
3)在{M1,1,M2,1}的基礎上與不包含以上2種地物的其他端元進行組合,構造三端元組合,記為{M1,1,M2,1,M3,1}, 然后計算其與之間的光譜角距離;
4)對步驟1)~3)得到的光譜角距離進行排序,將光譜角距離最小所對應的端元組合作為該像元中實際的地物混合,以此端元組合對進行解混計算得到最終的豐度。
2.2 ADMM 尋優算法
ADMM[4]的核心思想是將一個復雜問題分解成一系列簡單的子問題進行求解。ADMM 經常用于求解如下形式的非約束問題:
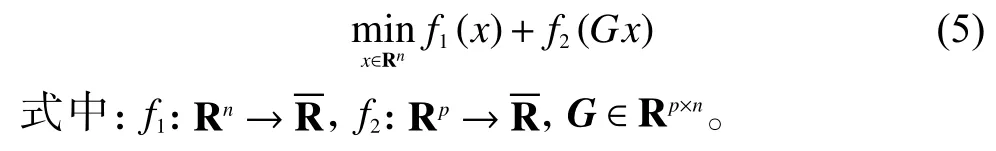
ADMM 方法解決式(5)的步驟如下所示:
1) 令 k=0 , 取 μ>0, u0和 d0;
2) 執行步驟3)~6),直到滿足迭代終止條件;
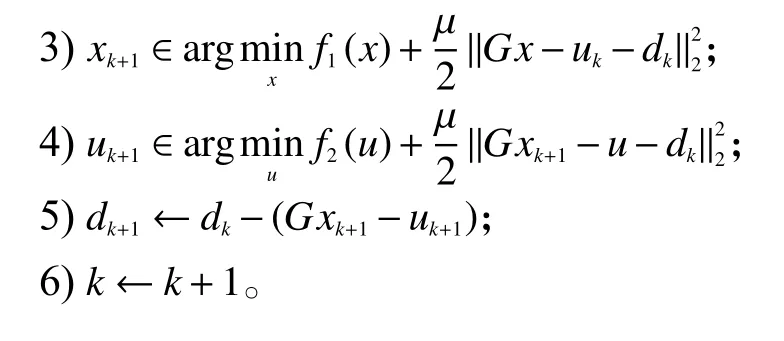
3 合成數據實驗
為了驗證本文所提算法的有效性,分別對合成數據和真實數據進行實驗。在合成數據實驗中,從USGS 礦物光譜庫中選擇Actinolite、Antigorite和Chlorite 的光譜,考慮到光譜變異,分別從這3 種礦物所對應的端元光譜曲線中選取1 條、2 條、2 條,分別記為Actinolite、Antigorite(1)、Antigorite(2)、Chlorite(1)、Chlorite(2),具體的光譜曲線如圖1 所示。
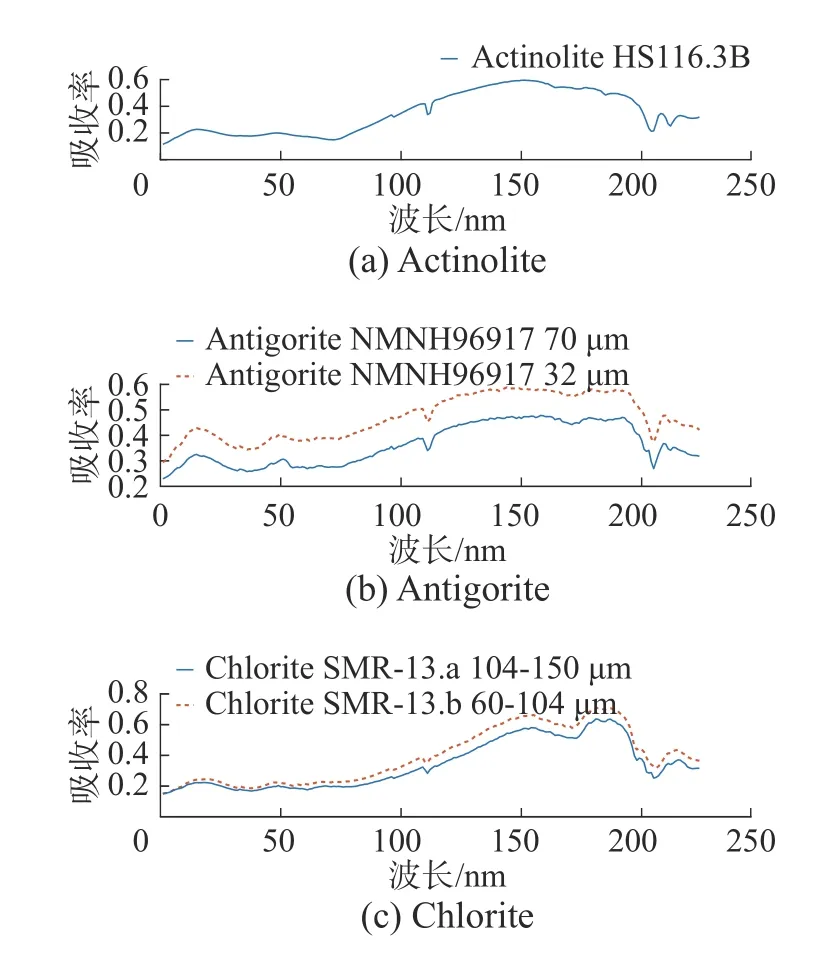
圖1 各種地物對應的端元曲線
利用這5 條光譜曲線合成一幅100×100×224的高光譜圖像,并加入40 dB 的高斯噪聲,合成的高光譜圖像如圖2 所示。
為了使實驗結果具有更強的解釋性,對該高光譜數據做特殊安排,前1~8 列為Actinolite、9~16 列為Antigorite(1)、17~24 列為Antigorite(2)、25~32 列為Chlorite(1)、33~40 列為Chlorite(2)、40~45 列為Actinolite 和Antigorite(1)的隨機組合、46~50 列為Actinolite 和Antigorite(2)的隨機組合、51~55 列為Actinolite 和Chlorite(1)的 隨 機 組 合、56~60 列 為Actinolite 和Chlorite(2)的 隨 機 組 合、61~65 列 為Antigorite(1)和Chlorite(1)的隨機組合、66~70 列為Antigorite(1)和Chlorite(2)的隨機組合、71~75列為Antigorite(2)和Chlorite(1)的隨機組合、76~80列為Antigorite(2)和Chlorite(2)的隨機組合、81~85 列 為Actinolite、 Antigorite(1)和Chlorite(1)的隨機組合、86~90 列為Actinolite、Antigorite(1)和Chlorite(2)的隨機組合、91-95 列為Actinolite、Antigorite(2)和Chlorite(1)的隨機組合、96~100 列為Actinolite、Antigorite(2)和Chlorite(2)的隨機組合。將本次實驗與部分約束最小二乘法(constrained least squares unmixing,CLSU)[14]、部分約束最小二乘法的的縮放版本(scaled version of CLSU,SCLSU)、全約束最小二乘法(fully constrained least squares unmixng,FCLSU)[15]、以及基于分層的高光譜解混算法結果的比較,本文提出的方法表示為H-ADMM。具體的實驗結果如圖3 所示,顏色深代表豐度值比較大,顏色淺代表豐度值較小。表1 為各種算法的均方根誤差。
實驗結果從豐度圖來看,本文所提算法H-ADMM 在解混精度上最優,FCLSU 次之,CLSU和SCLSU 最差。從表1 中的均方根誤差來看,HADMM 的結果最好,比分層解混算法要改善許多。由此可知本文提出算法的有效性。

圖2 合成高光譜圖像

圖3 5 種算法解混豐度

表1 均方根誤差
4 真實數據實驗
為了更好地驗證本文算法的性能,真實數據實驗部分采用的是美國印第安納州實驗農田數據。該數據共有16 種地物,圖像的空間尺寸大小為144×144,波段總數為100。由于真實數據地物種類繁雜,在本次實驗中主要考慮圖像中玉米、草和大豆并將其他地物全部作為背景。
考慮到端元變異,玉米、草和大豆中每種地物包含3 條光譜曲線,分別記為玉米1、玉米2、玉米3、草1、草2、草3、大豆1、大豆2、大豆3,背景中包含7 條光譜曲線,分別記為背景1、背景2、背景3、背景4、背景5、背景6 和背景7。鑒于實驗篇幅較大,本文只給出實驗結果如圖4、5 所示。
為了更好地評價這2 種算法性能,還從數據層面對結果進行分析。采用整幅圖像的均方根誤差作為評價標準。所有像元的均方根誤差直方圖如圖6 所示,整幅圖像的均方根誤差如表2 所示。
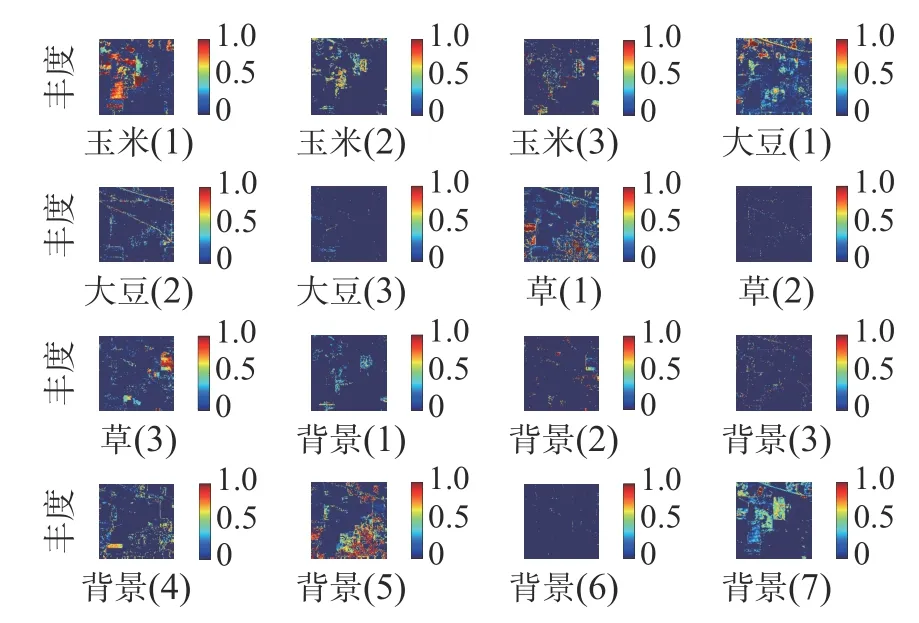
圖4 分層解混豐度結果
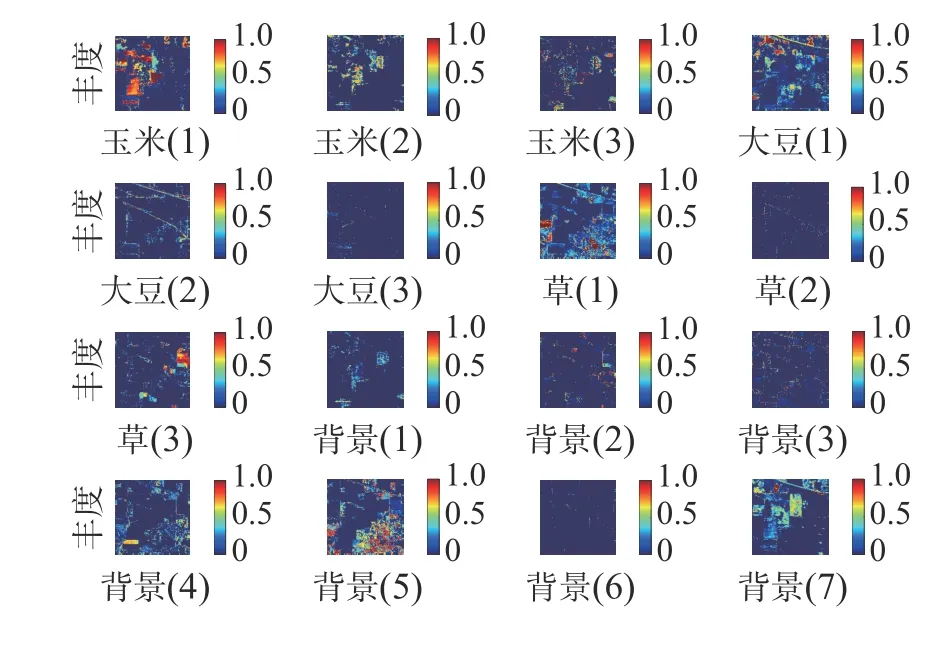
圖5 H-ADMM 解混豐度圖

圖6 2 種算法的均方根誤差直方圖

表2 2 種算法的均方根誤差
從圖6 可以看出,通過H-ADMM 算法的解混結果所得到的所有像元的均方根誤差分布較為集中,且誤差范圍分布較小。從2 種算法的均方根誤差來看,H-ADMM 的均方根誤差要遠小于基于分層的高光譜解混算法,減小了約58.8%。
5 結論
無論從合成數據實驗還是從真實數據實驗中均可以看出,本文所提算法H-ADMM 均優于基于分層的高光譜解混算法。
1)在合成數據實驗中,H-ADMM 在解混豐度圖上明顯好于其他幾種經典的高光譜解混算法,解混后的豐度圖邊界清晰,背景噪聲較小;
2)在真實數據實驗部分,從解混豐度圖上也可以看出H-ADMM 算法對于分層解混算法的優勢,從數據結果上可以明顯看出H-ADMM 要優于分層解混算法。
因此本文所提算法具有一定的優勢。但在以后的研究中,應對H-ADMM 算法進行多種的真實數據實驗,探索H-ADMM 算法中各個參數對解混結果的影響大小,使該算法適應于更多的真實場景。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
