基于標準時序生成的科研熱點預測及加速方法
2020-09-02 04:23:22韓英昆齊達立
山東電力技術 2020年8期
馬 艷 ,韓英昆 ,齊達立 ,劉 科
(1.山東電力研究院,山東 濟南 250003;2.國網山東省電力公司電力科學研究院,山東 濟南 250003)
0 引言
科技情報對國家、社會、企業的戰略、計劃的制定以及實施都發揮了重要作用。科研熱點預測是科技情報領域較新的應用需求。科研工作者、科研項目管理者在選題、立項必須有一定的前瞻性,即立足于當前科學技術現狀與社會發展情況,對未來可能產生的新理論或者產生應用價值的新技術做出判斷[1-2]。
按照研究主體,科研熱點預測分為對網絡文章和學術文獻的研究。PageRank算法是由Google提出的較為經典的網絡文章熱點預測算法[3]。基于文本分析的網絡文章熱點預測也取得了較好的效果[4]。
在沒有引入機器學習算法以前,對學術文獻的熱點預測嚴重依賴于本領域高級專業人員通過文獻查閱與市場調研的方法確定。比如,根據科學引文索引數據庫對論文的文獻分類分別統計每個分類中的論文數量,用數字來說明文獻科研熱點集中在哪些領域;還可以根據文獻分類分別統計每個分類中的研究作者數量,用客觀的數值來表明科研熱點的研究熱度所在和科研力量集中點[5]。
近年來,利用機器學習技術對學術文獻進行科研熱點的預測分析得到普遍關注[6]。2003年著名的LDA(Latent Dirichlet Allocation)算法在 pLSI基礎上被提出[7],既是一種文檔主題生成模型,又是一個包含詞、主題和文檔三層結構的貝葉斯概率模型。LDA是一種非監督機器學習技術,可用來識別大規模文檔集或語料庫中潛藏的主題信息。
然而,國內外目前建立的科研熱點預測模型,從應用效果上分析還存在以下問題:1)當一個新的理論與技術誕生后,其關聯應用領域還需要大量的工作去發掘。2)科研領域中,科研熱點詞匯數量巨大,每種熱點呈現的走勢不盡相同,基于標準的機器學習模型擬合熱點走勢準確率不高。
因此,亟須設計一種考慮時序關系的科研熱點預測算法和系統,可對未來一段時間的科學研究熱點較為快速準確地預測出來,輔助科研工作者及科研項目管理者的工作。
1 科研熱點預測與推送框架
目前,每種科研熱點呈現各種各樣的時序走勢。以某熱點科研詞匯的點擊量為例,其隨著時間變化的趨勢完全不同,如圖1所示。不同的時序走勢,導致標準機器學習算法在直接使用時預測準確度不高。這就須設計一種可適應多樣時序趨勢的預測模型和框架。
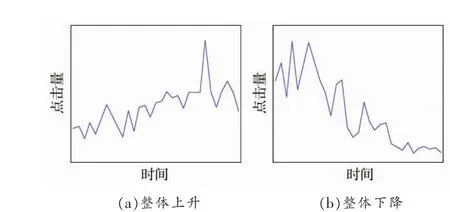
圖1 科研詞匯的點擊量時序趨勢
基于上述問題,提出一種基于標準時序生成的科研熱點預測框架,使得用戶可以及時獲得未來一段時間科研熱點主題預測推薦。框架分為5個模塊,如圖2所示,包括時序數據爬取模塊、熱點數據標記模塊、時序聚類模塊、熱點預測模塊、預測加速模塊。
時序數據爬取模塊利用爬蟲技術在科技新聞網站、文獻數據庫爬取科技信息文章;熱點數據標記模塊負責標記1個周期的所有熱點關鍵詞,并且生成關鍵詞的歷史時序數據;時序聚類模塊負責對熱點時序進行聚類,并且根據聚類結果生成標準熱點時序;熱點預測模塊負責對各關鍵詞的權重TF-IDF時序進行檢測,找出熱點關鍵詞;預測加速模塊負責對熱點預測任務進行加速。

圖2 科研熱點預測與推送框架
2 科研熱點預測過程
基于上述框架,給出基于標準時序生成的科研熱點預測方法的實施過程,如圖3所示。
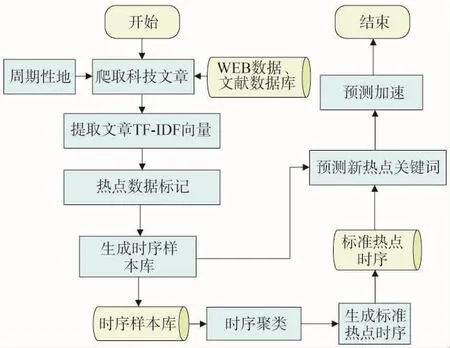
圖3 基于標準時序的科研熱點預測方法流程
2.1 時序數據爬取模塊
時序數據爬取模塊將爬取的文章文本化,設一段時間內抓取的科技信息文章集合為Tt,其中t表示周期序號。基于權重TF-IDF算法獲得Tt的關鍵詞向量,記為 at={bi|i∈Q},Q 為科技詞庫中詞的數量。設ai為詞庫中詞匯分量第i個關鍵詞,bi為對應關鍵詞ai所得權重TF-IDF值。
計算bi的具體步驟為:
1)設tj是 Tt的一篇文章,基于標準 TF-IDF算法獲得tj第i個詞匯的TF-IDF值,設為
2)設tj的下載量或閱讀量為nj,引用量為mj。那其中分別表示該周期內所有文章nj與mj的平均值。
在具體實施過程中,bi的計算可以基于下載量、閱讀量、引用量,也可以基于瀏覽時長、轉發率。
2.2 熱點數據標記模塊
熱點數據標記模塊負責標記一個周期的所有熱點關鍵詞、生成關鍵詞的歷史時序數據,并將這些時序數據加入樣本庫,用以模型訓練。具體方法如下:
1)設置bi的熱點閾值,當bi>時,則標記bi對應的ai為熱點關鍵詞。
2)生成 ai的 權 重 TF-IDF 時 間 序 列 Bi={bi,t,t=1,2,…,n},其中 bi,t表示第 t個周期 bi的值。 bi,t應從歷史數據中獲取。
3)篩選首次熱點出現序列。首次熱點出現序列是指之前關鍵詞ai不是熱點詞匯,而本周期變為熱點詞匯,基于此序列訓練預測模型可以有效感知未來的熱點關鍵詞。設當前周期為t,若bi,t≥且bi,t-1<,則標記Bi為首次熱點出現序列。
4)設 Bi,(t-s+1,t)為首次熱點出現序列的一個截取樣本,Bi,(t-s+1,t)={bi,x,x=t-s+1, …,t-1,t},s 為截取長度,所有的樣本長度固定為s。
5)將該樣本加入樣本集,供時序聚類使用。
2.3 時序聚類模塊
該模塊通過對熱點時序進行聚類[8]生成標準熱點時序。通過聚類一組時序數據生成一個標準熱點時序的示意見圖4。模塊的具體流程如下:
1)對樣本庫的時序數據樣本聚類。
首先,基于動態時間規整算法(DTW)計算兩個時序樣本 Bi,(t-s+1,t)、Bj,(x-s+1,x)的距離,x、t表示起止時間可不同。公式如下:
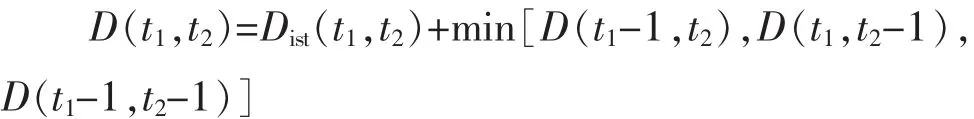
式中:D(t1,t2)為兩個時序分別在 t1周期與 t2周期的DTW 距離;Dist(t1,t2)=|bi,t1-bi,t2|。
其次,基于DBSCAN聚類算法對樣本庫的時序數據樣本進行聚類,設生成的聚類為 Cβ|β=1,2,…,n。
2)生成標準熱點時序,即基于一個時序聚類中所有時序數據樣本計算出一個標準時序,作為該聚類的標準示例。 用 Bβ(t-s+1,t)表示標準熱點時序,其計算公式如下為 Bi在 t周期的值,t=1,2,…,S。S為周期的數量。每個時序聚類對應生成一個標準熱點時序,設Z為生成標準熱點時序的集合,Z={Bβ|β=1,2,…,n}。
3)計算每個聚類中的時序樣本與其標準熱點時序最遠DTW距離。Cβ的最遠DTW距離設為mβ。
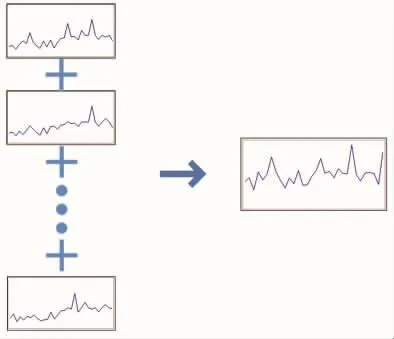
圖4 標準熱點時序生成
2.4 熱點預測模塊
該模塊負責對各關鍵詞的權重TF-IDF時序進行檢測,找出熱點關鍵詞。方法如下:
1)過濾掉過低 bi,t的關鍵詞 ai,以減少檢測數量。設置過濾閾值 γ,若當前周期其中bi表示近s′個周期bi,x的平均值,則認為關鍵詞ai有可能成為熱點關鍵詞,進行檢測。反之,則不進行檢測。
2)設 ai通過第 1)步過濾,則生成 ai檢測序列Bi,Bi={bi,t,t=1,2,…,n}。
過低的γ會導致過多的檢測樣本,預測效率降低;而過高的γ會導致一些熱點關鍵詞被過濾掉,降低熱點關鍵詞查全率。在具體實施過程中,可設置
2.5 預測加速模塊
本模塊負責對熱點預測任務進行加速。在熱點預測模塊,每個關鍵詞都要與每個標準熱點時序進行DTW距離計算,因此其時間復雜度為w·|Z|,其中w為模塊4(熱點預測模塊)步驟1)過濾后關鍵詞的數量,|Z|為Z標準熱點時序的數量。此方法比較耗時,本模塊基于時序特征前置比較的方式,加快預測時間。方法如下:
1)提取每個 Bβ|Bβ∈Z的時序特征。 這些時序特征包括均值、方差、最大值、最小值等,Bβ的時序特征用Vβ表示。
2)初步檢測ai檢測序列Bi與Bβ的距離。提取Bi的時序特征Vi,基于歐氏距離計算Vi與Vβ的距離,若此距離小于閾值v·,則再進行模塊4的熱點預測;若大于v·則放棄Bi與DTW距離計算。
3 性能驗證
本節驗證提出科研熱點預測及加速方法的實驗性能。提出的算法簡稱為PASSG(Prediction and Acceleration based on Standard Sequence Generation);無加速模塊的算法簡稱為PSSG算法,即PSSG算法僅包含前4個模塊。基準算法使用循環神經網絡(RNN)作對比分析,性能指標使用查全率、查準率及預測時間實施評價。

圖5 算法查全率和查準率對比分析
首先,驗證PASSG和RNN算法對不同樣本數量情況下的查全率和查準率,如圖5所示。樣本數據是指隨機抽取熱點關鍵詞的樣本數量。樣本數量分別選定 500、1 500、2 500、3 500。 從圖 5 看出,PASSG算法比RNN算法查全率平均提高25.75%,查準率平均提高28.25%,特別是在樣本數量較大時。RNN方法將所有樣本放入模型進行訓練,然而時序具有多樣性,其用一個樣本擬合,效果不佳。
其次,設置樣本數量為3 500,考察參數γ值對PASSG算法查全率與預測時間的影響,如圖6所示。橫軸為γ大于任意熱點標準時序均值的百分比。從圖中看出,查全率和預測時間都隨著γ的增大遞減。因此,算法需要根據實際需求,折中的設置γ值。當對耗時敏感時,應選擇較高的γ,而對查全率要求較高時,應選擇較低的γ。
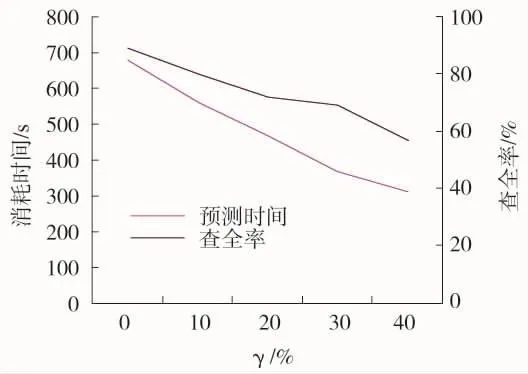
圖6 γ值對查全率與預測時間的影響
最后考察預測加速模塊的性能表現,如圖7所示。設置樣本3 500。PSSG是指不用第2.5節的模塊5進行加速,直接用第2.4節模塊4進行預測。結果表明,使用加速方法的PASSG算法較PSSG算法不僅可以大幅提高預測效率,而且預測的精度損失較小。
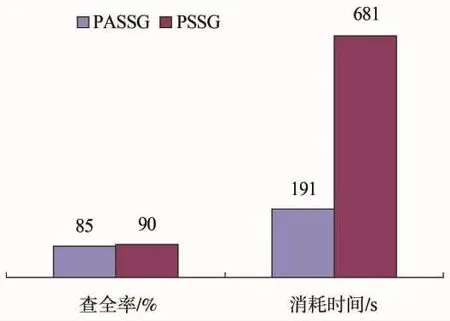
圖7 加速方法查全率和消耗時間性能分析
4 結語
提出一種科研熱點預測及加速框架,該框架基于權重TF-IDF獲取爬取信息的特征向量,兼顧信息的時序變化關系,并基于時序特征前置比較的方式提高預測效率。實驗表明,提出框架和方法不僅具有較高的查全率和查準率,預測時間亦在可接受范圍內,且隨著樣本數量的增大,查全率、查準率和預測時間優勢明顯。
