基于ConvLSTM雙通道編碼網絡的夜間無人車場景預測
2020-09-04 04:01:08孫韶媛劉訓華顧立鵬
紅外技術 2020年8期
關鍵詞:特征
李 想,孫韶媛,劉訓華,顧立鵬
(1.東華大學 信息科學與技術學院,上海 201620;2.東華大學 數字化紡織服裝技術教育部工程研究中心,上海 201620)
0 引言
場景預測[1-2]是根據已知視頻序列預測下一幀或幾幀圖像,讓無人車提前進行決策,降低了因決策不及時發生交通事故的風險。現如今,場景預測研究可見光領域較多,夜視領域很少,但夜間場景下的場景預測、駕駛決策等技術在無人車研究技術中占有重要的地位[3-4]。紅外圖像相比于可見光圖像[5],缺少色彩信息、清晰度低、紋理細節特征少等特點,使得無人車對夜間周圍環境進行準確感知并及時做出行為決策的難度比白天更大[6]。
目前場景預測算法主要分為兩種:有監督場景預測和無監督場景預測。有監督場景預測,T.C.WANG等人[7]利用視頻序列及其語義圖序列、光流圖和多個雙通道網絡得到了長時間的高清預測圖像。J.T.PAN等人[8]利用語義圖的語義信息、首幀圖像以及光流圖實現了圖像的較準確預測。以上兩種方法都是基于語義圖的標簽信息以及光流法進行分辨率的提升,此類網絡得到的預測圖像清晰度較高,預測的未來幀數較多,但計算量大,預測速度慢。無監督場景預測,Lotter等人[9]基于卷積長短時記憶(convolutional long-short term memory,ConvLSTM,)提出了一個預測編碼網絡,將圖像的預測誤差進行前向傳播,實現了自然場景下的視頻預測。該網絡較好地捕獲了動態信息,預測速度比較快,但預測圖像清晰度低,預測未來幀數少。
無人車駕駛決策最重要的是實時性和準確性[10],有監督場景預測預測速度慢,實時性達不到,無監督學習雖實時性可以實現,但預測圖像清晰度低,預測幀數少。本文結合文獻[7]的雙通道思路和文獻[9]的動態信息提取思路,兼顧實時性和準確性,提出了基于ConvLSTM 的雙通道編碼夜間無人車場景預測網絡。針對紅外圖像的特點,以及場景預測所需要獲取的信息,利用兩個子網絡對紅外圖像分別進行編碼;將兩個子網絡得到的特征進行融合后輸入到解碼網絡中,得到預測圖像;最后將預測圖像輸回網絡中,繼續預測下一幀,實現多幀預測。該網絡具有端到端的特點,實現了較高的準確性、較好的實時性以及多幀預測。
1 網絡結構
1.1 基礎網絡
本文所提出的基于ConvLSTM 的雙通道編碼夜間無人車場景預測網絡包括卷積神經網絡、卷積長短時記憶網絡、殘差網絡和反卷積網絡。
1.1.1 卷積和反卷積神經網絡
卷積神經網絡[11](convolutional neural network,CNN)在圖像處理中有著出色的表現,利用卷積層提取圖像的特征,將高維特征映射為低維特征,實現分類等任務。反卷積網絡與卷積網絡操作相反,是將低維特征映射為高維特征或圖像,主要用于語義分割和圖像生成等領域。這兩種網絡的一大特性是權值共享,大大減少了參數量,提高了計算速度。
1.1.2 卷積長短時記憶網絡
長短時記憶[12](long-short term memory,LSTM)網絡是目前最常用的一種循環神經網絡,它在很多涉及時序性的領域,例如語音識別、視頻分析、序列建模等都取得了很好的成果,原始的LSTM 對時序數據處理很好,但在空間數據上存在冗余;而ConvLSTM恰好彌補了這一點,不僅具有LSTM 的時序建模能力,還能像CNN 一樣刻畫局部特征,減少了空間上的數據冗余,最終可以獲取時空特征。
1.1.3 殘差網絡
殘差網絡[13](residual network,ResNet)相比于VGG(visual geometry group,VGG)等網絡多了短跳轉連接(shortcut connection)操作,該操作是將網絡較之前的特征圖疊加到當前特征圖,彌補了由于池化操作丟失信息的缺點,大大提高了后續網絡對特征圖的理解能力,從而提高最終結果的準確度。
1.2 基于ConvLSTM 的雙通道編碼夜間無人車場景預測網絡
本文提出的雙通道編碼預測網絡包括4 個模塊:時間子網絡、空間子網絡、特征融合網絡和解碼網絡。本文所構建的基于ConvLSTM 的雙通道編碼夜間無人車場景預測網絡結構圖如圖1所示。
整個網絡的輸入分為兩部分:前n幀的視頻序列X={X1,X2,…,Xn}和當前時刻圖像Xt。相鄰序列的差分圖像循環輸入到時間子網絡中,提取時序信息;當前時刻圖像Xt輸入到空間子網絡中,提取空間特征;利用特征融合網絡融合得到時空特征,然后輸入到解碼網絡中,得到預測圖像。最后將預測圖像替換Xt,實現多幀預測。
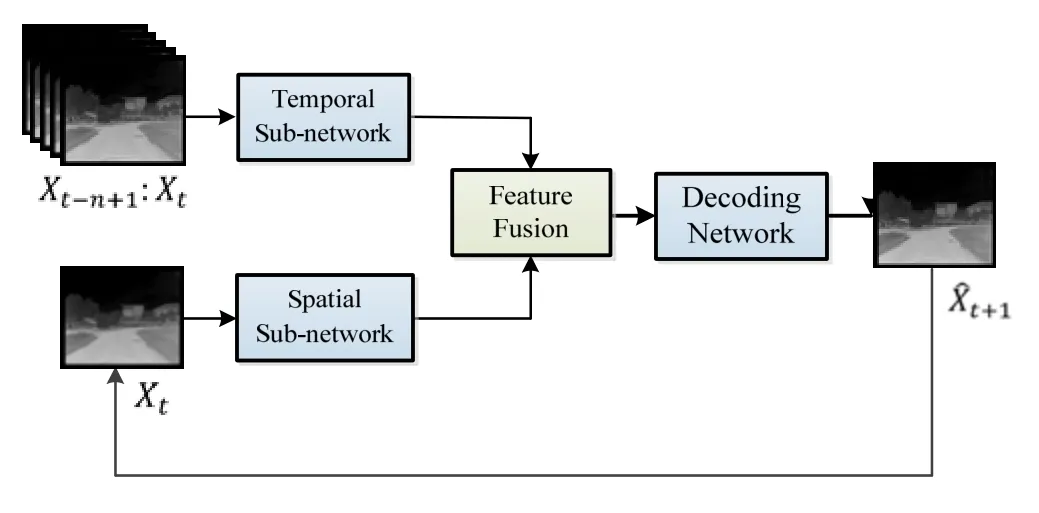
圖1 基于ConvLSTM 的雙通道編碼夜間無人車場景預測結構圖Fig.1 The structure diagram of dual-channel encoding based on ConvLSTM for night scene prediction
1.2.1 基于CNN 和ConvLSTM 的時間子網絡
時間子網絡負責提取視頻序列時序特征,由CNN和ConvLSTM 網絡構成。該網絡輸入是相鄰兩幀的差分圖像,利用CNN 對差分圖像進行特征提取,經池化得到較低維特征圖,減少了輸入ConvLSTM 的參數量,加快運行的速度。ConvLSTM 提取動態信息,得到圖像間的時序信息以及圖像部分空間信息。基于CNN 和ConvLSTM 的時間子網絡結構圖如圖2所示,從左到右分別是紅外差分圖像、卷積池化層、ConvLSTM 和時序特征。圖2是時間子網絡的一個過程,由一系列卷積、池化和一個ConvLSTM 構成,利用3X3 卷積核,提取紅外差分圖像特征,經最大池化操作得到低維特征圖,最后輸入到ConvLSTM 網絡中,提取時序特征。將多幀紅外差分圖像輸入時間子網絡,促使ConvLSTM 對之前信息進行部分遺忘,對當前信息進行記憶,最終學習到紅外視頻序列的時序特征。本文網絡輸入10 幀圖像,即9 張差分圖像,時間子網絡通過9 次學習來提取視頻序列的時序特征。
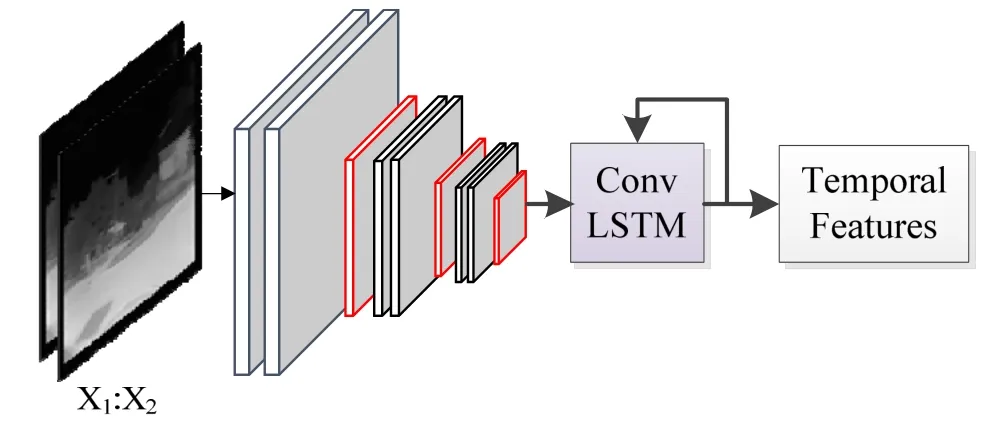
圖2 基于CNN 和ConvLSTM 的時間子網絡結構圖Fig.2 Structure diagram of temporal sub-network based on CNN and ConvLSTM
1.2.2 基于ResNet 的空間子網絡
空間子網絡負責提取紅外圖像的空間信息。考慮到CNN 網絡存在多個池化階段,會丟失部分提取的特征信息,在最后解碼時一些細節不能恢復,影響預測圖像清晰度,因此空間子網絡利用ResNet 網絡進行特征提取。ResNet 網絡增加了shortcut connection操作,即將之前的特征圖與當前的特征圖融合后再進行池化、卷積,這樣處理彌補了池化階段的信息丟失問題,在最后解碼得到的圖像中清晰度會有所提高。基于ResNet 的空間子網絡結構圖如圖3所示,從左到右依次是紅外圖像、殘差層、池化層和空間特征。該子網絡選擇了較小的卷積核,主要是從以下兩方面進行考慮:①卷積核過大,參數量增加,從而導致計算量增加;②卷積核過大,不能很好地提取圖像的特征,從而影響最終生成圖像的清晰度。最后的池化用了最大池化,而不是平均池化,也是考慮到清晰度的問題。
1.2.3 特征融合網絡和解碼網絡
特征融合網絡是將時間子網絡和空間子網絡提取的兩個特征進行融合,并利用ResNet 網絡對得到的特征進行進一步提取。特征融合網絡的結構圖如圖4所示。
解碼網絡是以反卷積神經網絡為基礎進行構建。輸入是特征融合網絡得到的時空特征,與空間子網絡中的卷積相對應,經過一系列反池化和反卷積操作,得到預測圖像。
2 實驗及結果分析
2.1 實驗配置
本實驗所使用的硬件及軟件配置如表1所示。網絡是在Tensorflow 深度學習框架下搭建,在此基礎上進行網絡的訓練與測試。
2.2 實驗數據與步驟
實驗所用視頻由實驗室載有紅外攝像頭的無人車在夜間拍攝所得。考慮到圖像信息冗余性問題,將數據集每隔3 幀抽取一幀,得到了6500 張圖像,訓練集為6000 張紅外圖像,測試集為500 張紅外圖像。訓練過程中學習率為0.0001,迭代的次數為100 k,整個網絡的訓練時間為2.5 d,通過多次迭代學習紅外視頻序列的時空特征,保存模型參數,模型的參數通過Adam 算法優化獲得。將測試集中的圖像輸入到訓練好的模型中,得到預測結果,具體的實驗流程如圖5所示。
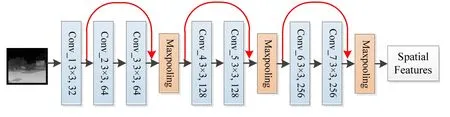
圖3 基于ResNet 的空間子網絡結構圖Fig.3 Structure diagram of spatial sub-network based on ResNet
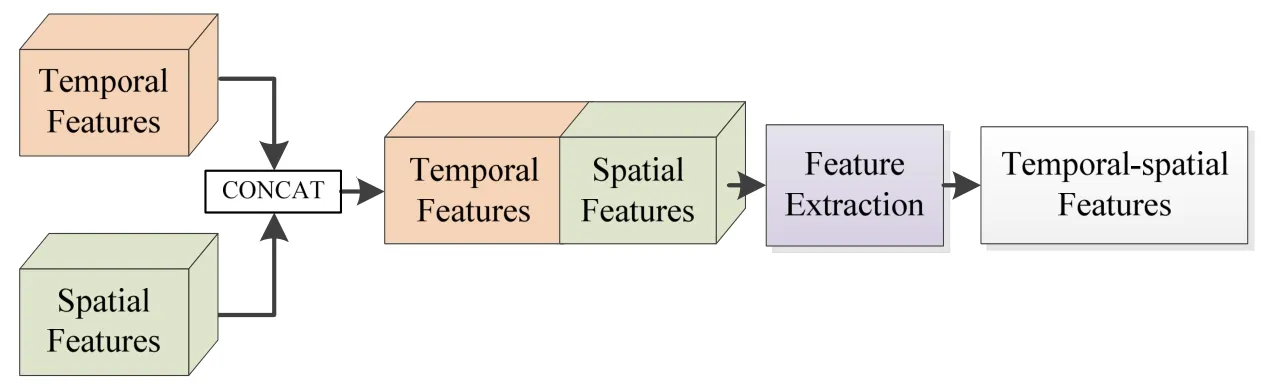
圖4 特征融合網絡Fig.4 Feature fusion network

表1 實驗配置Table 1 Experimental configuration
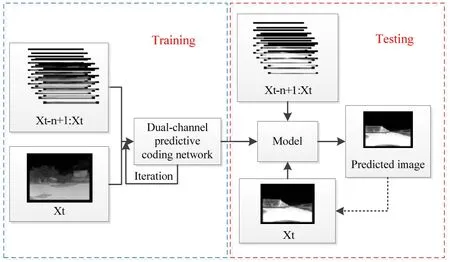
圖5 實驗流程圖Fig.5 Experimental flowchart
常見的圖像預測評估中主要有以下兩個評價指標[14]:
1)峰值信噪比(peak signal to noise ratio, PSNR)
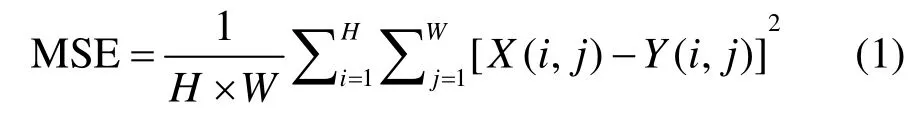
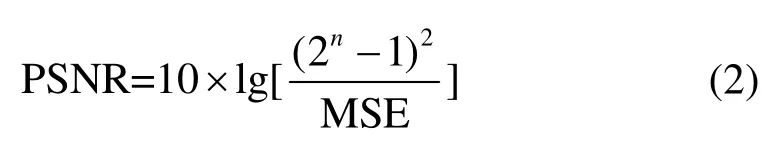
式中:MSE 表示實際圖像X和預測圖像Y的均方誤差(mean square error);H、W分別表示圖像的高度和寬度;PSNR 的單位是dB,數值越大,表示失真越小,即圖像內容越接近。
2)結構相似性(structural similarity, SSIM)

式中:μX、μY分別表示實際圖像X和預測圖像Y的均值;σX、σY分別表示圖像X和Y的方差;σXY表示圖像X和Y的協方差;C1、C2是維持穩定的常數。SSIM數值越大,表示圖像內容越接近。
2.3 實驗結果與分析
將測試集輸入到場景預測網絡中,得到預測圖像序列。輸入10 幀圖像,可以預測未來8 幀圖像,因數據集是每隔3 幀抽取一幀,則可以預測到第32 幀圖像,即1.2 s 以后的圖像,預測的結果如圖6所示,分別給出了轉彎、行人和車輛3 種典型場景的預測場景圖像與真實場景圖像的比較。

圖6 紅外圖像場景預測結果Fig.6 Infrared image scene prediction results
從圖6預測結果可以看出,本文的場景預測圖像接近真實值,預測圖像較準確,清晰度較高。圖6共有3 組預測結果,每一組的第一行是真實場景的8 幀圖像,第二行是網絡預測的8 幀圖像。圖6(a)很好地反映了車輛行駛過程中道路轉彎的變化,道路輪廓預測準確、清晰,路面上的一些標識可以預測到第5 張(即第20 幀);圖6(b)能夠合理地預測道路中行人的位置變化,雖然預測的行人輪廓比較模糊,但移動位置準確,并且可以合理填補消失的空缺;圖6(c)可以反映前方行駛車輛的運動情況,雖然后續預測圖像中車輛不是很清楚,但依舊可以看出車輛的基本輪廓。圖6(c)倒數2 張預測的圖像中車輛比較模糊,初步考慮是車輛行駛的速度過快,相鄰幀車輛位置變化比較大導致的。
為了更好地評價預測的結果,進行了定量的分析,將復制前一幀圖像、Conv-LSTM[15]、Prednet 網絡、SAVP 網絡[16]以及本文提出的網絡在PSNR 和SSIM 上進行了對比,對比的結果是針對不同網絡分別預測出的第1 幀紅外圖像而言,具體結果如表2所示。
PSNR 和SSIM 指標數值越大代表預測圖像與真實圖像越接近,預測時間越小預測速度越快。從表2可以看出,本文提出的方法無論是在PSNR、SSIM 還是預測時間上,其效果優于其他方法,SSIM 達到0.9以上,說明預測圖像準確度較高;預測一幀圖像的時間是0.02 s,即1 s 可以預測50 幀,達到了實際中實時性要求。
圖6和表2分別從定性和定量的方面說明了本文網絡預測圖像清晰度高、預測內容較準確度且速度快,滿足實時性要求。但本文也存在一些不足,圖6(c)預測的圖像中車輛的輪廓預測不是很清楚,初步考慮是數據集中含有車輛的紅外圖像較少以及未來的不確定性導致的。
3 結論
本文針對紅外圖像清晰度低、無色彩信息等特點,提出了基于ConvLSTM 的雙通道編碼夜間無人車場景預測網絡,利用時間子網絡提取視頻序列的時序特征,空間子網絡提取圖像的空間特征,通過特征融合網絡融合后輸入到解碼網絡,得到預測圖像。本文網絡能夠較準確地預測未來場景的變化,并且可以預測未來1.2 s 后的場景,改善了之前預測圖像模糊、預測幀數少的問題,為駕駛決策提供了足夠的決策時間,滿足實時性和準確性的要求。目前公開的紅外數據集基本沒有,本文所使用的數據集是自己課題組成員采集,場景相對比較單一,主要包括校園環路或者教學區等一些道路。之后會針對更復雜的場景進行進一步的研究。
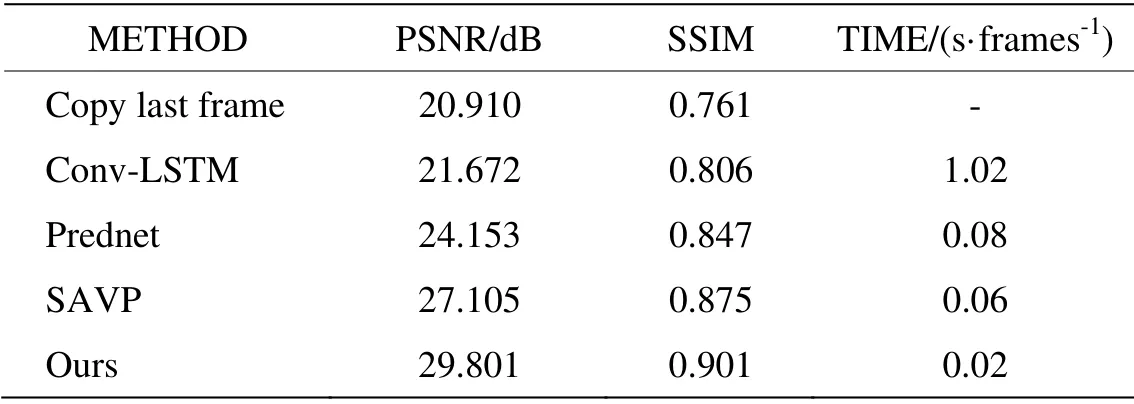
表2 場景預測不同方法對比結果Table 2 Comparison results of different methods for scene prediction
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
