基于多特征提取和Stacking集成學習的金線蓮品系分類
2020-09-21 14:06:10謝文涌柴琴琴甘勇輝陳舒迪
農(nóng)業(yè)工程學報 2020年14期
謝文涌,柴琴琴,甘勇輝,陳舒迪,張 勛,王 武
基于多特征提取和Stacking集成學習的金線蓮品系分類
謝文涌1,2,柴琴琴1,2※,甘勇輝3,陳舒迪1,2,張勛4,王武1,2
(1. 福州大學電氣工程與自動化學院,福州 350108;2. 福建省醫(yī)療器械和醫(yī)藥技術(shù)重點實驗室,福州 350108;3.漳州職業(yè)技術(shù)學院食品工程學院,漳州 363000;4. 福建中醫(yī)藥大學藥學院,福州 350122)
針對傳統(tǒng)中藥鑒定、分子鑒定、生物技術(shù)鑒定及光譜檢測技術(shù)的主觀性強、耗時、操作復雜等不足,以及金線蓮整個葉片形態(tài)區(qū)分度小、單一分類器鑒別精度不高的問題,該研究提出了基于機器視覺的葉片子區(qū)間多特征提取方法和基于多模型融合的Stacking集成學習算法實現(xiàn)金線蓮的品系分類。試驗采集6個品系的金線蓮葉片圖像數(shù)據(jù),進行圖像預處理后提取葉片子區(qū)間內(nèi)紋理、顏色共114個特征,基于這些特征,構(gòu)建堆疊式兩階段集成學習框架,以邏輯回歸、K最近鄰、隨機森林和梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)作為基分類器,GBDT作為元分類器進行學習。試驗結(jié)果表明,Stacking集成學習模型的整體識別綜合評價指標值達93.91%,分類正確率達94.49%,分別比邏輯回歸、K最近鄰、隨機森林和GBDT這4個單一分類模型高出4.40、11.87、11.01、12.94個百分點和5.36、11.34、6.93、12.13個百分點。因此,該研究能夠有效識別金線蓮品系,為形狀大小相似、形狀特征難以利用的植物葉片識別提供參考。
機器視覺;模型;金線蓮;子區(qū)間分割;特征提取;Stacking集成學習;植物葉片
0 引 言
金線蓮,又名金絲線、金耳環(huán)、烏人參、金錢草等,是中國的二級保護植物[1],被譽為“藥中之王”,能夠用于預防和治療高血壓,糖尿病,高脂血癥,肝炎和腫瘤等疾病[2-3]。由于野生金線蓮的自然繁殖率低、生長條件受限制等原因?qū)е聰?shù)量有限,市面上出售的金線蓮大多為人工培育品種。目前,金線蓮品系繁多,不同品系的金線蓮外觀相似但藥效差異大,市場上以次充好的現(xiàn)象層出不窮,因此,如何準確有效識別金線蓮的品系對保障藥方藥效、維護消費者利益具有重要意義。
金線蓮的品質(zhì)鑒定通常依賴于化學分析方法,主要包括顯微鑒定法、高效液相色譜法、DNA分子鑒定法和近紅外光譜檢測技術(shù)等,然而這些方法需要在專業(yè)人士指導下進行,存在主觀性強,過程耗時且精度低,操作過程復雜且費用昂貴等缺陷[4-5]。為了克服以上鑒別方法的缺陷,學者們將機器視覺技術(shù)引入到中藥材的鑒別中[6-7],主要集中在通過中藥材葉片的識別來判定藥材質(zhì)量,但尚未見有關(guān)基于機器視覺技術(shù)對金線蓮進行品系分類的研究報道。在葉片的特征提取方面,通常使用形狀特征[8]、紋理特征[9]和顏色特征[10]來作為葉片的識別特征,為了更加充分表達葉片信息,進一步提高葉片識別精度,特征融合在葉片識別中得到廣泛應用[11]。然而上述研究主要是針對不同類別的植物葉片分類進行,對于同種類別不同品系的植物葉片分類研究鮮有報道。
基于提取的特征,構(gòu)造合適的分類器是通過葉片識別解決品系鑒別問題需研究的另一個重點,常用于葉片識別領域的機器學習方法有K最近鄰(K Nearest Neighbor,KNN)[12]、支持向量機[13]、邏輯回歸(Logistic Regression,LR)[14]、極限學習機[9]等。然而這些識別方法均要求測試數(shù)據(jù)集與訓練數(shù)據(jù)集的樣本概率分布一致,要在眾多假設函數(shù)構(gòu)成的空間中確定一個與實際情況最相符合的特征分布函數(shù)作為分類器。但是由于金線蓮種植基地分布廣泛、復雜的生長環(huán)境會造成葉片形態(tài)異常,如存在如脈紋、葉形異常等情況,實際測試集數(shù)據(jù)分布存在不確定性,找到一個與實際情況最相符合的分布函數(shù)十分困難。因此,單一分類器往往會存在泛化能力不佳的問題。為克服由于樣本不確定性帶來的分布函數(shù)難以精確估計的問題,學者們提出了集成學習方法,通過將多個弱分類器集成為強分類器完成高精度的分類任務。目前,集成學習已成為機器學習的熱門研究方向之一[15],常用的集成學習方法有并行化集成Bagging[16],序列化集成的Boosting[17]和多層分類器組合的Stacking[18]。不同于Bagging和Boosting集成方式,Stacking使用高級別的元分類器來綜合低級別的基分類器的輸出特征以此來增強泛化能力,得到更高的預測精度,降低模型過擬合風險。Stacking集成學習在教育、醫(yī)學、社會科學等領域得到廣泛應用[19-21],然而在農(nóng)業(yè)方面的應用甚少[22]。
綜上所述,本文提出了基于多模型融合的Stacking集成學習算法實現(xiàn)不同品系金線蓮葉片的分類。首先針對利用整個葉片形狀難以區(qū)分不同品系的金線蓮的問題,提出了基于子區(qū)間分割的顏色、紋理等特征提取和融合方法;其次以提取的特征為基礎,在Stacking集成框架下設計LR、KNN、隨機森林(Random Forest,RF)[23]和梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)[24]作為基學習器,并以GBDT作為元學習器輸出分類結(jié)果;最后,通過算法對比驗證所提方法的有效性。
1 材料與方法
1.1 樣本圖像獲取及預處理
1.1.1 圖像獲取
金線蓮含有的多糖和黃酮成分是其藥效的有效成分,不同品系的金線蓮含量具有顯著差異,影響金線蓮的售價。目前,市場上主要售賣的金線蓮品系分為小圓葉、大圓葉、尖葉、臺灣金線蓮和雜交金線蓮。因此,本研究采集市場上廣泛流通的小圓葉、大圓葉、尖葉、臺灣金線蓮等主要品系以及雜交品系(紅霞、一株圓葉)作為研究對象,以此來驗證品系分類方法的有效性。
試驗所用全部金線蓮樣本均來源于福建葛園生物科技有限公司,并經(jīng)福建中醫(yī)藥大學教師專業(yè)認證。采集人工套袋培養(yǎng)的6個品系金線蓮葉片,分別包含臺灣金線蓮58幅、紅霞64幅、小圓葉45幅、尖葉46幅、一株圓葉60幅、大圓葉44幅,總共317個樣本。為了使采集的樣本更具有代表性,將樣本平鋪于拍攝箱中的白色紙板上,箱內(nèi)燈光均勻照射在葉片,相機鏡頭與目標樣本的距離為30 cm左右。采集設備為尼康單反數(shù)碼相機,型號為NIKON D7100,圖像分辨率為6 000×4 000像素。采集的代表樣本圖片如圖1所示。

圖1 金線蓮不同品系葉片代表圖
1.1.2 圖像預處理與子區(qū)間劃分
為了避免除了葉片本身其他因素干擾,需對拍攝的原圖進行預處理,流程如圖2所示。首先將圖像分辨率縮小至800×800像素,先使用均值濾波對彩色圖像降噪,其次將圖像灰度化,對灰度化后的圖像使用高斯濾波去除噪聲點;然后用最大類間方差法(OTSU Method)[25]進行自動閾值分割得到二值化圖像,再用數(shù)學形態(tài)學方法中的閉運算消除葉片存在的內(nèi)部孔洞,開運算去除葉柄;最后,針對不同品系的金線蓮形狀大小極其相似,葉片形狀特征難以利用的問題,提出對葉片進行子區(qū)間分割來避免葉片形狀特征的影響,在二值圖像的基礎上繪制原圖的葉片輪廓,計算葉片的質(zhì)心,選擇以質(zhì)心為中心,邊長為150個像素點的正方形區(qū)域作為葉片的子區(qū)間,從完整葉片中分割出相同部位和大小的子區(qū)間葉片。

圖2 圖像預處理與子區(qū)間劃分流程圖
1.2 圖像的多特征提取
1.2.1 紋理特征
本文使用基于統(tǒng)計的分析方法局部二進制模式(Local Binary Pattern,LBP)[26]和灰度共生矩陣(Gray Level Co-occurrence Matrix,GLCM)[27]來提取紋理特征。為了更充分地表示紋理特征,使用時域和頻域相結(jié)合的Gabor濾波[28]進行精細比例分析,并對紋理進行多分辨率表示,將這三類特征融合作為金線蓮葉片識別的紋理特征。
1)LBP
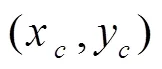
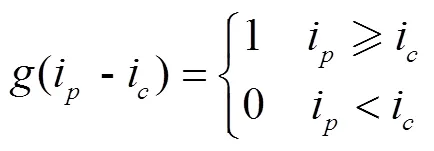
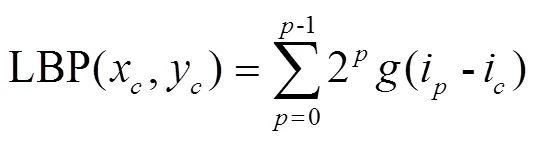
隨著采樣點數(shù)的增加,二進制模式的數(shù)量急劇增加,LBP算子計算量也隨之增大。為了解決這個問題,提高統(tǒng)計性,采用等價的LBP模式進行降維[29],這種方法既減少了二進制模式數(shù)量又不丟失信息。對于有8個領域點的LBP算子,二進制模式的數(shù)量由256種減少至59種。
2)GLCM
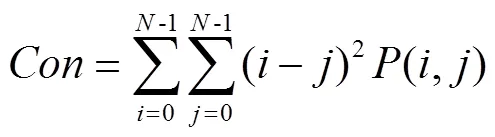
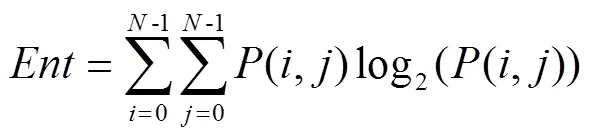
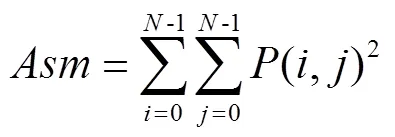
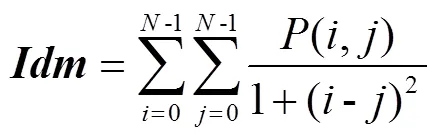
3)Gabor濾波
Gabor濾波器能捕獲到與圖像局部結(jié)構(gòu)信息相對應的不同空間頻率、空間位置和方向的特征,被廣泛應用于圖像中提取紋理特征。在空間域中,二維Gabor濾波器是由正弦平面波調(diào)制的高斯核函數(shù),具有表示正交方向的實部和虛部。Gabor濾波器的函數(shù)數(shù)學表達式如下
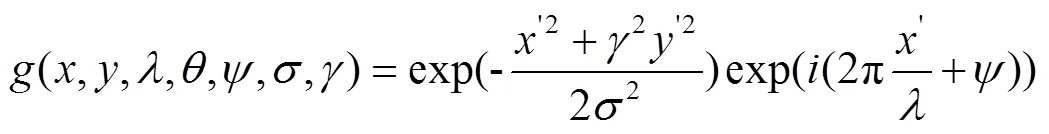
實數(shù)部分為
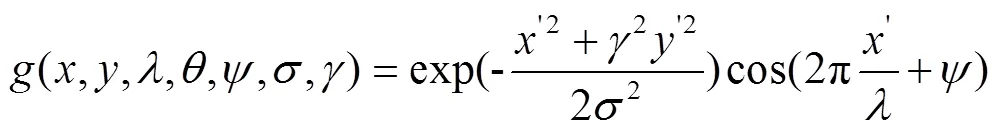
虛數(shù)部分為
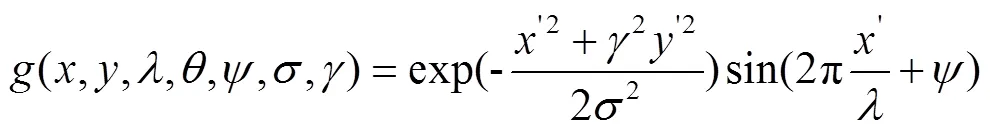
在進行特征提取之前,首先要將原圖像與Gabor函數(shù)進行卷積運算來生成與原圖像大小一致的目標圖像。本文利用4個方向,6個尺度的Gabor濾波器生成24個卷積模板。將所提取的Gabor子帶(共4×6個)的均值特征組合起來形成一個24維的特征向量。
1.2.2 顏色特征
顏色是圖像識別中最簡單直接的特征,具有良好的魯棒性。由于顏色低階矩[30]中含有豐富的顏色分布信息,一階矩通過計算顏色的均值反映圖像的明暗信息,二階矩用來描述顏色的標準差反映圖像的顏色分布范圍,三階矩重點突出顏色的偏移性反映顏色的分布對稱性。所以,本文采用低階矩來提取色彩特征。通過測量整個圖像的顏色分布,針對顏色模型HSV和RGB進行計算。然而HSV模型中分量與色彩無關(guān),所以提取顏色模型中的、、、、共5個顏色分量。最后,統(tǒng)計得到15個顏色特征。具體的計算公式如下:
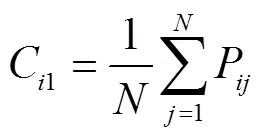
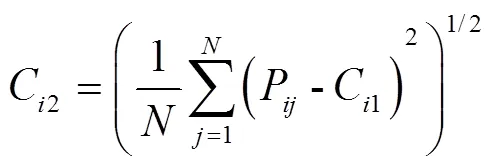
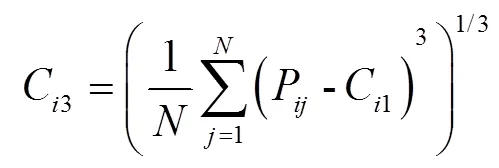
2 基于Stacking集成學習的金線蓮品系識別
2.1 Stacking集成學習基本原理
對于Stacking集成學習而言,基分類器和元分類器的設計是關(guān)鍵之處。LR、KNN因為理論成熟、簡單高效等優(yōu)點,在很多領域有著很好的應用效果[31-32]。RF、GBDT分別是基于Bagging和Boosting的思想,RF能夠高度并行化訓練,大大提高了計算效率,而GBDT通過構(gòu)造弱分類器,使每個模型輸出結(jié)果與殘差之和盡可能的與預測值接近。從偏差和方差的角度分析,RF主要降低誤差的方差項,GBDT既能降低偏差也能降低方差,這兩個算法相互組合通過不同的機制能確保結(jié)果的有效性[33-34]。所以,本文采用了經(jīng)典機器學習算法LR、KNN、RF、GBDT作為基分類器,元分類器使用泛化能力強的GBDT算法來糾正多個算法對訓練集的偏置情況。
2.2 具體案例分析
在Stacking集成學習訓練過程中如果直接用第一層模型的訓練數(shù)據(jù)當做第二層元學習器的輸入,可能會有過擬合的風險,因此需要對訓練過程進行重新設計,為此針對金線蓮品系識別提出了如圖3所示的模型訓練過程。主要步驟如下:
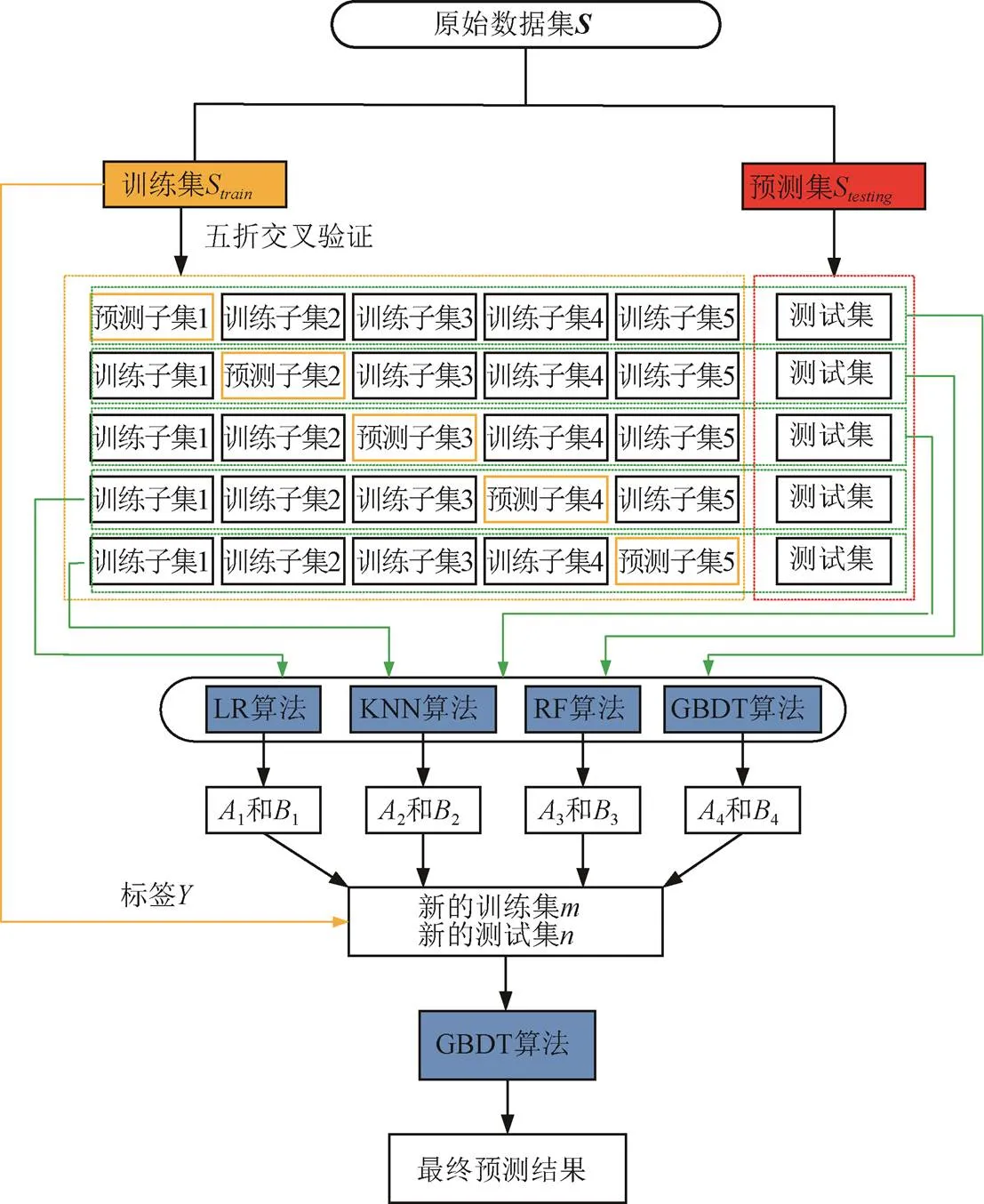
圖3 Stacking框架下的金線蓮品系識別

由于元分類器的訓練集和測試集均未參與到各個基分類器的訓練過程,所以有效防止了過擬合的發(fā)生,并且元分類器綜合了各個基分類器的輸出特征提升了分類準確率。
3 結(jié)果與討論
3.1 試驗平臺與參數(shù)設置
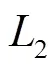
3.2 鑒別結(jié)果分析
3.2.1 Stacking集成學習模型鑒別結(jié)果分析
子區(qū)間分割之前,對葉片進行形狀特征提取以此來驗證金線蓮葉片形態(tài)區(qū)分度小這一特點。本次試驗選擇Hu不變矩特征[35]和6個幾何特征[36](狹長度、矩形度、圓形度、周長長寬比、周長直徑比、偏心率)一起作為Stacking模型的輸入特征,試驗結(jié)果表明葉片形狀特征的分類正確率僅為49.61%,故形狀特征不能作為葉片有效識別特征,從而采用子區(qū)間分割技術(shù)來提高識別率。
子區(qū)間分割后,采用混淆矩陣來評估Stacking集成學習的性能,具體結(jié)果如圖4所示。矩陣的每一行代表樣本的實際類別,每一列代表預測類別結(jié)果,矩陣對角線上的數(shù)字代表每個品系被正確識別的樣本數(shù)目。可以看出,臺灣金線蓮、紅霞、一株圓葉、大圓葉這4個不同品系全部被正確識別,然而小圓葉品系中有1個樣本被錯誤識別成尖葉,尖葉中有6個樣本被誤識別成一株圓葉,說明尖葉在紋理、顏色方面與人工自主培育品種一株圓葉有很大的相似性。
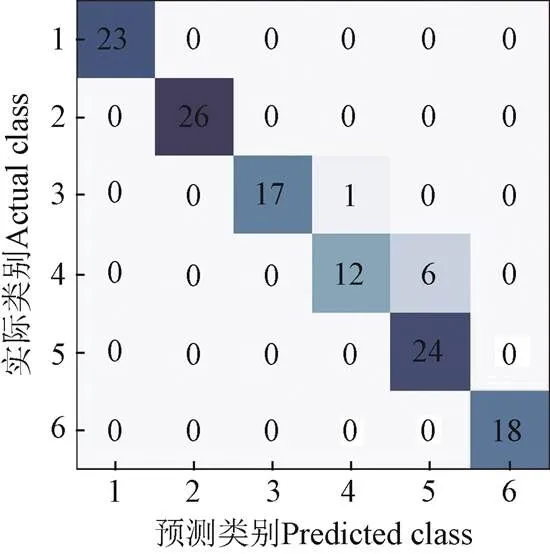
注:坐標軸數(shù)字代表1.臺灣金線蓮 2.紅霞 3.小圓葉 4.尖葉 5.一株圓葉 6.大圓葉
此外,還使用了常見分類性能度量指標來評價分類模型,這些指標包括準確率(Accuracy)、精確率(Precision)、召回率(Recall)、綜合評價指標值(F1-Score),公式如下:
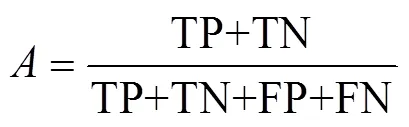
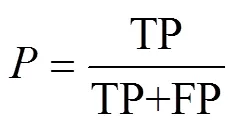
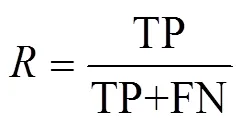
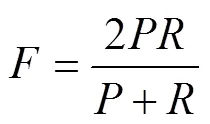
根據(jù)公式(13),Stacking模型下金線蓮品系識別正確率(Accuracy)達到94.49%,而LR、KNN、RF、GBDT的正確率分別為89.13%、83.15%、87.56%、82.36%,Stacking集成學習在一定程度上提升了分類準確性。
3.2.2 不同模型分類結(jié)果對比
為了充分驗證構(gòu)建的Stacking集成學習模型的有效性,根據(jù)式(14)~(16),針對每個不同品系將集成學習模型與單一分類模型分別在精確率、召回率和綜合評價指標值方面進行對比分析,并歸納出分類器的整體識別能力。對比具體結(jié)果如表1~4所示。
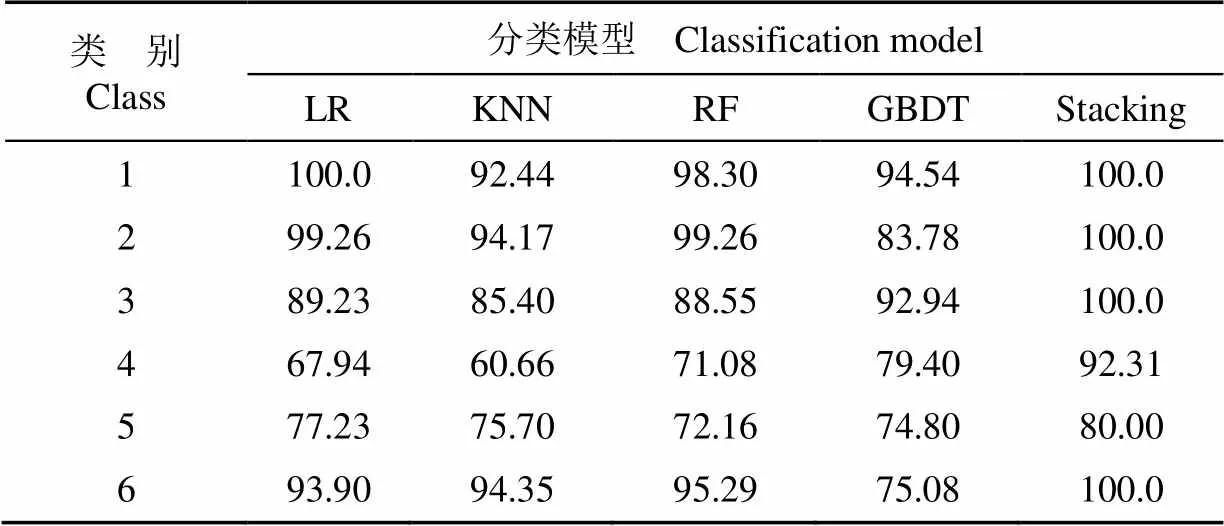
表1 不同分類模型精確率比較

表2 不同分類模型的召回率比較
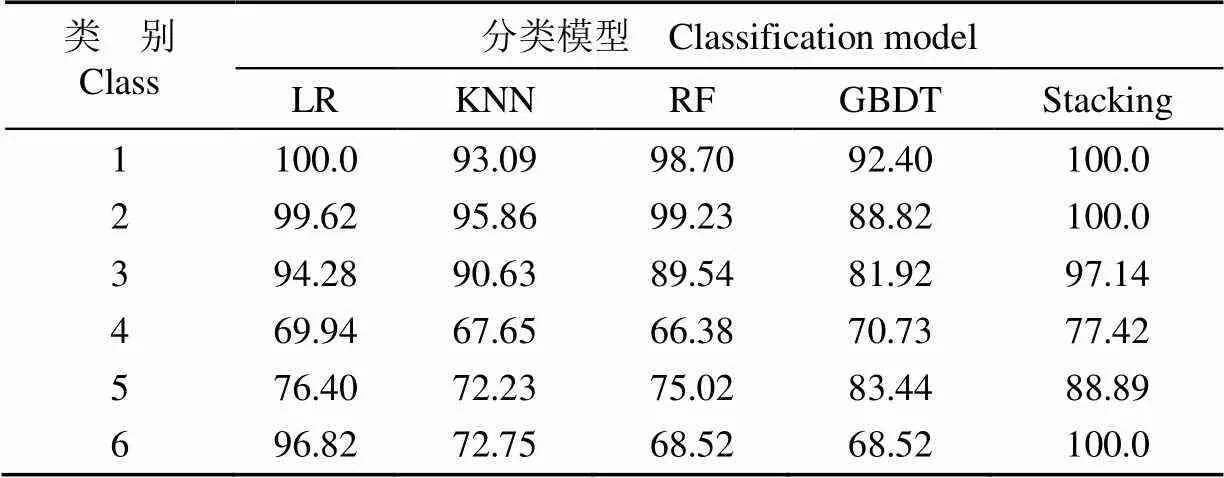
表3 不同分類模型的綜合評價指標比較
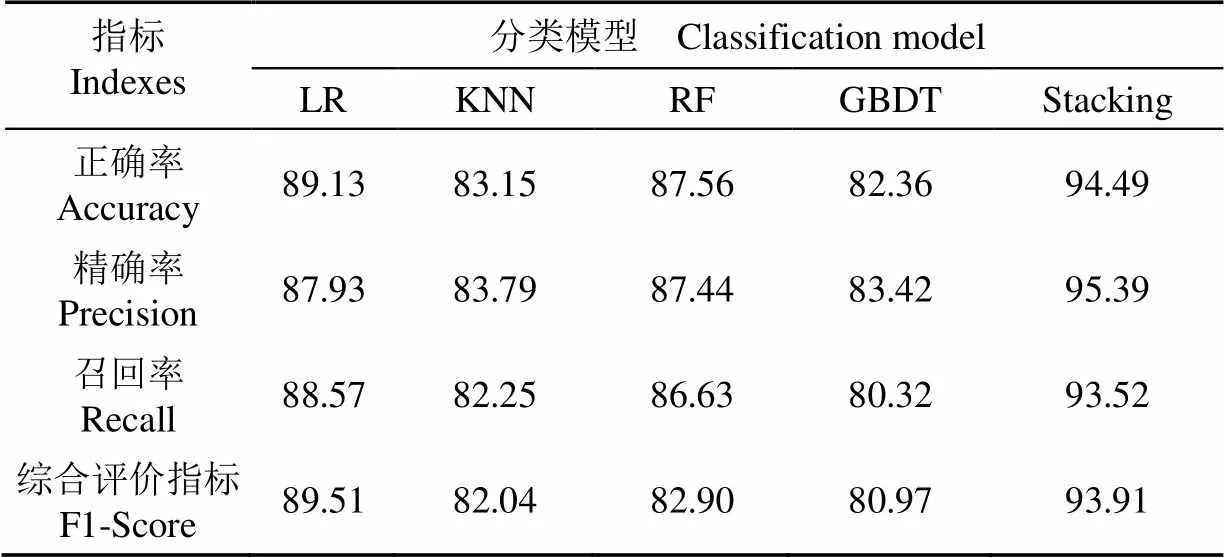
表4 不同分類模型整體平均識別能力比較
從表1~4可以看出,Stacking表現(xiàn)出良好的分類性能,在類別1、類別2、類別6品系識別中精確率、召回率、綜合評價指標值均達100%。與單一分類模型相比,Stacking集成模型在金線蓮各個品系識別中均擁有最高的精確率,整體平均精確率達95.39%,比單一分類模型中最高的LR模型高7.46個百分點。在召回率的比較中,Stacking模型在類別3的召回率為94.44%低于LR的100%和KNN的96.66%,在類別4上為66.67%低于KNN模型的76.67%,但在整體上達到93.52%優(yōu)于其中任何一個分類器。值作為綜合評價指標表示分類器的整體性能,在每個品系識別中Stacking集成模型的值均最高,且整體平均值達93.91%,分別比LR、KNN、RF、GBDT這4個單一模型高出4.40、11.87、11.01、12.94個百分點,表現(xiàn)出該模型良好的綜合性能。
以上結(jié)果表明,Stacking集成模型綜合了其他4種弱分類器分類性能,整體上擁有比單一分類器更好的表現(xiàn)性能,能夠更加有效識別不同品系的金線蓮。這是因為單一分類器在訓練過程中往往可能陷入局部最優(yōu)點,而局部最優(yōu)對應的模型泛化性能不佳,Stacking集成學習通過結(jié)合基分類器來有效減少陷入局部最優(yōu)點的風險。然而,Stacking集成學習在類別3與類別4的召回率表現(xiàn)上有所欠缺,這是因為Stacking模型受到基分類器的精度與多樣性影響的原因,其基分類器之間的相關(guān)性大,在數(shù)據(jù)空間中獲得的分類假設函數(shù)相似,無法在最大程度上體現(xiàn)不同基分類器的優(yōu)勢。
4 結(jié) 論
本文提出了多模型融合的Stacking集成學習方法,對6種不同品系的金線蓮葉片進行分類識別。首先對原始圖像進行灰度化、濾波降噪、閾值分割、形態(tài)學處理等預處理,得到葉片二值圖像,在二值圖像的基礎上提出葉片子區(qū)間分割方法,得到不同葉片相同部位的子區(qū)間目標圖像。然后使用局部二進制模式(Local Binary Pattern,LBP)、灰度共生矩陣(Gray Level Co-occurrence Matrix,GLCM)、Gabor濾波等方法提取圖像紋理特征,使用顏色低階矩提取顏色特征,這些特征相互融合作為金線蓮的識別特征。為了充分學習數(shù)據(jù)特征,構(gòu)建了以邏輯回歸(Logistic Regression,LR)、K最近鄰(K Nearest Neighbor,KNN)、隨機森林(Random Forest,RF)和梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)為基分類器的Stacking分類模型,以此來提升分類性能。通過試驗研究比較,Stacking模型在分類準確率、精確率、召回率和綜合評價指標值等指標上分別達94.49%、95.39%、93.52%和93.91%,優(yōu)于LR、KNN、RF和GBDT模型。在今后的研究中,將進一步考慮Stacking配置選擇方法,減少計算時間的情況下提高學習效率,同時將進一步擴充圖像數(shù)據(jù)集,在更加復雜的背景下實現(xiàn)不同品系的植物識別。
[1] 邵清松,葉申怡,周愛存,等. 金線蓮種苗繁育及栽培模式研究現(xiàn)狀與展望[J]. 中國中藥雜志,2016,41(2):160-166. Shao Qingsong, Ye Shenyi, Zhou Aicun, et al. Current researches and prospects of seedling propagation and cultivation modes of Jinxianlian[J]. China Journal of Chinese Materia Medica, 2016, 41(2): 160-166. (in Chinese with English abstract)
[2] Ye S, Shao Q, Zhang A. Anoectochilus roxburghii: A review of its phytochemistry, pharmacology, and clinical applications[J]. Journal of Ethnopharmacology, 2017, 209: 184-202.
[3] Tseng C C, Shang H F, Wang L F, et al. Antitumor and immunostimulating effects of Anoectochilus formosanus Hayata[J]. Phytomedicine, 2006, 13(5): 366-370.
[4] 陳瑩,任麗,嚴桂杰,等. 不同來源金線蓮的HPLC指紋圖譜[J]. 沈陽藥科大學學報,2019,36(9):794-804. Chen Ying, Ren Li, Yan Guijie, et al. Fingerprint analysis of Anoectochilus roxburghii from different sources by HPLC[J]. Journal of Shenyang Pharmaceutical University, 2019, 36(9): 794-804. (in Chinese with English abstract)
[5] Lv T, Teng R, Shao Q, et al. DNA barcodes for the identification of Anoectochilus roxburghii and its adulterants[J]. Planta, 2015, 242(5): 1167-1174.
[6] Tao O, Lin Z, Zhang X B, et al. Research on identification model of chinese herbal medicine by texture feature parameter of transverse section image[J]. World Science and Technology-Modernization of Traditional Chinese Medicine, 2014 (12): 2558-2562.
[7] 朱黎輝,李曉寧,張瑩,等. 基于形狀特征及紋理特征的中藥材檢索方法[J]. 計算機工程與設計,2014,35(11):3903-3907. Zhu Lihui, Li Xiaoning, Zhang Ying, et al. Image retrieval method for Chinese herbal medicine based on shape features and texture features[J]. Computer Engineering and Design, 2014, 35(11): 3903-3907. (in Chinese with English abstract)
[8] 宋彥,謝漢壘,寧井銘,等. 基于機器視覺形狀特征參數(shù)的祁門紅茶等級識別[J]. 農(nóng)業(yè)工程學報,2018,34(23):279-286. Song Yan, Xie Hanlei, Ning Jingming, et al. Grading Keemun black tea based on shape feature parameters of machine vision[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(23): 279-286. (in Chinese with English abstract)
[9] Turkoglu M, Hanbay D. Leaf-based plant species recognition based on improved local binary pattern and extreme learning machine[J]. Physica A: Statistical Mechanics and its Applications, 2019, 527: 121297.
[10] 張凱兵,章愛群,李春生. 基于HSV空間顏色直方圖的油菜葉片缺素診斷[J]. 農(nóng)業(yè)工程學報,2016,32(19):179-187. Zhang Kaibing, Zhang Aiqun, Li Chunsheng. Nutrient deficiency diagnosis method for rape leaves using color histogram on HSV space[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2016, 32(19): 179-187. (in Chinese with English abstract)
[11] 鄧向武,齊龍,馬旭,等. 基于多特征融合和深度置信網(wǎng)絡的稻田苗期雜草識別[J]. 農(nóng)業(yè)工程學報,2018,34(14):165-172. Deng Xiangwu, Qi Long, Ma Xu, et al. Recognition of weeds at seedling stage in paddy fields using multi-feature fusion and deep belief networks[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(14): 165-172. (in Chinese with English abstract)
[12] Sharma P, Aggarwal A, Gupta A, et al. Leaf identification using HOG, KNN, and neural networks[C]//International Conference on Innovative Computing and Communications. Springer, Singapore, 2019: 83-91.
[13] 馬娜,李艷文,徐苗. 基于改進SVM 算法的植物葉片分類研究[J]. 山西農(nóng)業(yè)大學學報:自然科學版,2018,38(11):39-44. Ma Na, Li Yanwen, Xu Miao. Plant leaf classification using improved SVM algorithm[J]. Journal of Shanxi Agricultural University: Natural Science Edition, 2018, 38(11): 39-44. (in Chinese with English abstract)
[14] 劉立波,程曉龍,戴建國,等. 基于邏輯回歸算法的復雜背景棉田冠層圖像自適應閾值分割[J]. 農(nóng)業(yè)工程學報,2017,33(12):201-208. Liu Libo, Cheng Xiaolong, Dai Jianguo, et al. Adaptive threshold segmentation for cotton canopy image in complex background based on logistic regression algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(12): 201-208. (in Chinese with English abstract)
[15] Dong X, Yu Z, Cao W, et al. A survey on ensemble learning[J]. Frontiers of Computer Science, 2020, 14(2): 241-258.
[16] Andiojaya A, Demirhan H. A bagging algorithm for the imputation of missing values in time series[J]. Expert Systems with Application, 2019, 129(9): 10-26.
[17] Wang B, Pineau J. Online bagging and boosting for imbalanced data streams[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(12): 3353-3366.
[18] Hui Y, Mei X, Jiang G, et al. Milling tool wear state recognition by vibration signal using a stacked generalization ensemble model[J]. Shock and Vibration, 2019(3): 1-16.
[19] Elayidom S, Idikkula S M, Alexander J. A hybrid stacking ensemble framwork for employment predicyion problems[J]. Advances in Computational Research, 2011, 3(1): 25-30
[20] Dinakar K, Weinstein E, Lieberman H, et al. Stacked generalization learning to analyze teenage distress[C]// 2014 8th International AAAI Conference on Weblogs and Social Media (ICWSM 2014), Ann Arbor, Michigan, USA, 2014: 81-90
[21] Haddad B M, Yang S, Karam L J, et al. Multifeature, sparse-based approach for defects detection and classification in semiconductor units[J]. IEEE Transactions on Automation Science and Engineering, 2016, 15(1): 1-15.
[22] 袁培森,楊承林,宋玉紅,等. 基于Stacking集成學習的水稻表型組學實體分類研究[J]. 農(nóng)業(yè)機械學報,2019, 50(11):144-152. Yuan Peisen, Yang Chenglin, Song Yuhong, et al. Classification of rice phenomics entities based on stacking ensemble learning[J]. Transactions of the Chinese Society for Agricultural Machinery, 2019, 50(11): 144-152. (in Chinese with English abstract)
[23] 王麗愛,周旭東,朱新開,等. 基于HJ-CCD數(shù)據(jù)和隨機森林算法的小麥葉面積指數(shù)反演[J]. 農(nóng)業(yè)工程學報,2016,32(3):149-154. Wang Liai, Zhou Xudong, Zhu Xinkai, et al. Inverting wheat leaf area index based on HJ-CCD remote sensing data and random forest algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2016, 32(3): 149-154. (in Chinese with English abstract)
[24] 張會清,牛錚. 基于線性判別分析和梯度提升決策樹的WLAN室內(nèi)定位算法[J]. 儀器儀表學報,2018,39(12):136-143. Zhang Huiqing, Niu Zheng. WLAN indoor positioning algorithm based on linear discriminant analysis and gradient boosting decision tree[J]. Chinese Journal of Scientific Instrument. 2018, 39(12): 136-143. (in Chinese with English abstract)
[25] 王見,周勤,尹愛軍. 改進Otsu算法與ELM融合的自然場景棉桃自適應分割方法[J]. 農(nóng)業(yè)工程學報,2018,34(1):173-180. Wang Jian, Zhou Qin, Yin Aijun. Self-adaptive segmentation method of cotton in natural scene by combining improved Otsu with ELM algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(1): 173-180. (in Chinese with English abstract)
[26] Naresh Y G, Nagendraswamy H S. Classification of medicinal plants: An approach using modified LBP with symbolic representation[J]. Neurocomputing, 2016, 173: 1789-1797.
[27] Wu Q, Gan Y, Lin B, et al. An active contour model based on fused texture features for image segmentation[J]. Neurocomputing, 2015, 151: 1133-1141.
[28] VijayaLakshmi B, Mohan V. Kernel-based PSO and FRVM: An automatic plant leaf type detection using texture, shape, and color features[J]. Computers and Electronics in Agriculture, 2016, 125: 99-112.
[29] Yang H, Yin J, Jiang M. Perceptual image hashing using latent low-rank representation and uniform LBP[J]. Applied Sciences, 2018, 8(2): 317.
[30] Das S, Rudrapal D. Analysis of color moment as a low level feature in improvement of content based image retrieval[C]// Proceedings of the Fourth International Conference on Signal and Image Processing 2012 (ICSIP 2012). Springer, India, 2013: 387-397.
[31] Rymarczyk T, Kozowski E, Kosowski G, et al. Logistic regression for machine learning in process tomography[J]. Sensors, 2019, 19(15): 3400.
[32] Lee T R, Wood W T, Phrampus B J. A machine learning (KNN) approach to predicting global seafloor total organic carbon[J]. Global Biogeochemical Cycles, 2019, 33(1): 37-46
[33] Gui L, Xia Y, Li H, et al. Prediction of NOX emission from coal - fired boiler based on RF - GBDT[C]// 2017 6th International Conference on Energy and Environmental Protection (ICEEP 2017). 2017: 344-350.
[34] 徐兵,劉瀟,汪子揚,等. 采用梯度提升決策樹的車輛換道融合決策模型[J]. 浙江大學學報:工學版,2019,53(6):158-168. Xu Bing, Liu Xiao, Wang Ziyang, et al. Fusion decision model for vehicle lane change with gradient boosting decision tree[J]. Journal of Zhejiang University: Engineering Science, 2019, 53(6): 158-168. (in Chinese with English abstract)
[35] Wang X F, Huang D S, Du J X, et al. Classification of plant leaf images with complicated background[J]. Applied Mathematics & Computation, 2008, 205(2): 916-926.
[36] Ahmed F, Almamun H A, Bari A S, et al. Classification of crops and weeds from digital images: A support vector machine approach[J]. Crop Protection, 2012, 40: 98-108.
Strains classification ofusing multi-feature extraction and Stacking ensemble learning
Xie Wenyong1,2, Chai Qinqin1,2※, Gan Yonghui3, Chen Shudi1,2, Zhang Xun4, Wang Wu1,2
(1.,,350108,;2.,,350108,;3.,,363000,;4.,,350122,)
(A.) is a rare medicinal herb that mainly distributed in China. It is necessary to identify strains of A.for the guidance of clinical medication, due to different strains distinctly vary in medicinal values. However, similar leaf morphology has made difficult to discern different strains directly by naked eyes. In this study, a sub-interval segmentation method was proposed to identify the different strains of A., based on leaf identification methods. Firstly, 6 strains of A.were selected, including Taiwan, Hongxia, Xiaoyuanye, Jianye, Yizhu, Dayuanye. A total of 317 images with the resolution of 800×800 pixels were taken, while two filtering methods were used to remove noise. The maximum inner variance algorithm was used for automatic threshold segmentation, in order to obtain the binary image. In the binary image, the leaf contour was drawn, and the mass center of the leaf was calculated. The square area with 150 pixels centered on the mass center was selected as the sub-interval of the leaf, to obtain the target image with the same position and size. Secondly, a combination of texture and color features was applied for the target image, in which texture features were derived by local binary patterns (LBP), gray level co-occurrence matrix (GLCM) and gabor filters, whereas, the color feature was composed of the first, second and third moments. After that, 114 merged features were obtained. Thirdly, the stacking ensemble learning was proposed to improve the accuracy of traditional single classifier. The stacking framework consisted of a base classifier, and a meta-classifier. Logistic regression (LR), K nearest neighbor (KNN), random forest (RF), and gradient boosting decision tree (GBDT) were used as the base classifiers, whereas, GBDT was used as the meta-classifier for stacking. Finally, the cross-validation method different from conventional model was used to divide the data set. The original data was normalized and randomly segmented, where 60% for training and 40% for testing. The training data set was randomly divided into 5 training subsets, and then testing subset for training each base classifier. The prediction results of base classifiers were used as the input vectors of the GBDT. The final prediction result was output by GBDT. The experiment results showed that the average recognition accuracy of the stacking reached 94.49%, while that of LR, KNN, RF and GBDT was 89.13%, 83.15%, 87.56%, 82.36%, respectively. Moreover, the Precision, Recall, and1-Score of the stacking model for the identification of Taiwan, Hongxia, and Dayuanye were all 100%. The Recall performance of stacking model was better than any of the single classifiers for identification of the Xiaoyuanye, just slightly worse than that of the LR and KNN models. The1-Score of stacking model reached the maximum in each strain identification, showing the excellent overall performance of the model. Therefore, the proposed method can significantly improve the classification performances of A.with different strains. The findings can provide a promising application method to recognize leaves of different plants using shape features. A further research is still necessary to select proper configuration, in order to improve learning efficiency of stacking model.
computer vision; models;; sub-interval segmentation; feature extraction; Stacking ensemble learning; plant leaf
謝文涌,柴琴琴,甘勇輝,等. 基于多特征提取和Stacking集成學習的金線蓮品系分類[J]. 農(nóng)業(yè)工程學報,2020,36(14):203-210.doi:10.11975/j.issn.1002-6819.2020.14.025 http://www.tcsae.org
Xie Wenyong, Chai Qinqin, Gan Yonghui, et al. Strains classification ofusing multi-feature extraction and Stacking ensemble learning[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(14): 203-210. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2020.14.025 http://www.tcsae.org
2020-04-03
2020-06-17
國家自然科學基金項目(61773124);福建省科技廳高校產(chǎn)學合作項目(No.2019Y4009);福建省食品藥品監(jiān)督管理局金線蓮質(zhì)量標準提升專項([3500]FJJF[DY]2018008)
謝文涌,主要從事圖像處理與機器學習研究。Email:1024396820@qq.com
柴琴琴,副教授,主要從事機器學習與模式識別研究。Email:qq.chai@fzu.edu.cn
10.11975/j.issn.1002-6819.2020.14.025
TP391
A
1002-6819(2020)-14-0203-08
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
