
基于云計算技術的分布式網絡海量數據處理系統設計
2020-09-23 08:06:20盧鵬蘆立華
現代電子技術 2020年18期
關鍵詞:數據處理
盧鵬 蘆立華


摘? 要: 傳統的數據集中處理系統數據處理頻率較低,導致對海量數據的反饋效果不佳,為此基于云計算技術,設計網絡海量數據的分布式處理系統。該系統在原有系統硬件基礎上,替換其中的數據處理器,并增加該處理器的總使用數量,實現對海量數據的分布式同步處理。在軟件設計方面,通過協議使系統單元、模塊之間形成交互,改進系統的數據通信方式;計算歐氏距離,設置系統的分布式處理方式;根據云計算定義,使用分類函數確定約束條件,建立處理頻率方程,實現對海量數據的快速處理。實驗結果表明,與傳統系統相比,所設計系統對海量數據的處理頻率更快,反饋給用戶的效果更好。由此可見,該系統的應用可以增強用戶的體驗感受。
關鍵詞: 分布式網絡; 數據處理; 系統設計; 云計算技術; 處理方程建立; 對比驗證
中圖分類號: TN915?34; TP311? ? ? ? ? ? ? ? ? ?文獻標識碼: A? ? ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2020)18?0036?04
Abstract: As the traditional centralized data processing system has a low frequency of data processing, which results in poor feedback effect on mass data, a distributed processing system of mass data of network is designed based on cloud computing technology, in which the original system hardware is reserved, but the data processor is replaced and the total quantity in use of the processor is added, so that the distributed synchronous processing of mass data is realized. In terms of the software design, the interaction between system units and modules is formed by means of the protocol, which improves the data communication mode of the system. In this paper, the Euclidean distance is calculated, and the distributed processing mode of the system is set. The classification function is used to determine the constraint conditions according to the definition of cloud computing, and the processing frequency equation is established to realize the rapid processing of mass data. The experimental results show that, in comparison with the traditional system, the designed system can process mass data more quickly and give better feedback to users. Thus it can be seen that the application of the system can enhance the users′ experience.
Keywords: distributed network; data processing; system design; cloud computing technology; processing equation building; contrast validation
0? 引? 言
目前網絡技術發展迅速,越來越多的數據均可以在一個網絡平臺中體現,因此形成一個具有龐大數據體量、復雜數據類型、極高數據密度的網絡環境。為了讓用戶擁有更好的使用體驗,傳統的海量數據處理系統,將集中分析算法與模糊聚類方法相結合,形成對復雜海量數據的集中處理模式。此系統的運行,在短時間內解決了數據量過大,導致用戶體驗不佳的問題,但隨著行業的優化升級、技術水平的優化創新,大量類型不同的數據涌入網絡環境中,給數據處理系統帶來了巨大的處理壓力[1]。
為了加快系統響應速度,提升系統對海量數據的處理頻率,在傳統數據系統設計的基礎上,基于云計算技術,設計分布式的海量數據處理系統。云計算利用網絡,將其中的數據處理程序分解成無數個子程序,通過添加多個處理器,加快分析速度,并將反饋結果迅速返回給用戶。這項技術在極短的時間內完成了對數以萬計數據的分布式處理,從而實現該系統的強大處理功能。該系統的出現,緩解了海量數據對網絡環境造成的壓力,解決了現階段海量數據與處理系統之間的矛盾,為網絡及其他領域的數據處理,提供強有力的技術支持[2]。
1? 設計分布式網絡海量數據處理系統硬件
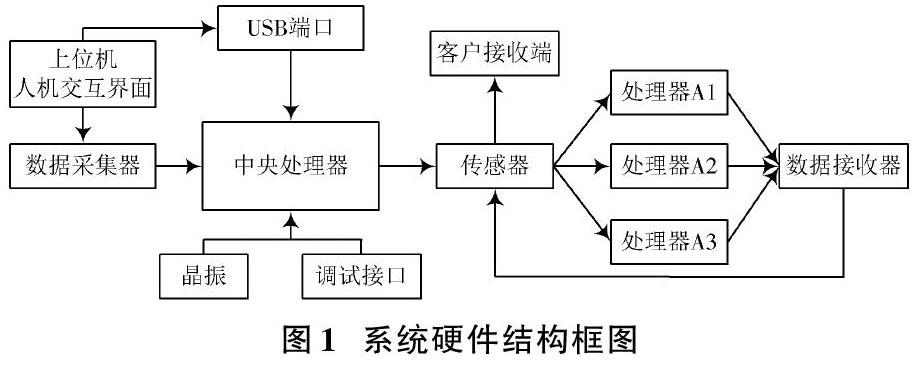
在原有系統硬件的基礎上,將原有數據處理器替換成多個功能強大的數據處理器,保證子程序協同運行,根據海量數據的類型不同,實現同步的分布式處理。該設計的硬件結構框圖如圖1所示[3]。
由系統硬件結構可知,此次設計調整原有系統的硬件集中連接形式,海量數據經傳感器迅速調配,由中央處理單元發送,將多個處理器與傳感器相連接,保證數據被實時同步接收,并協同運行處理。該處理器的型號為KR?i59400F,運行頻率在5.0 GHz以上,總線速度在8 GT/s DMI3。該處理器可以快速對海量數據進行同步分析,直接獲取數據的特征量,且耐熱性好、效率高、可長時間工作,從系統硬件上提升了系統的運行速度和處理強度[4?5]。
2? 基于云計算技術設計處理系統軟件
在系統硬件設計基礎上,對該系統軟件優化,以提升系統處理海量數據的頻率。
2.1? 改進處理系統的通信方式
為提高系統對海量數據的處理頻率,將該系統的通信方式重新設計。將主控單元的通信與子處理單元的通信重新連接,確保數據的接收以及同步處理[6]。在處理單元數據處理完成后,通過數據傳送單元,將該信息反饋給用戶,保證系統中的數據通信之間形成一個完整的通信閉環[7?8]。同時,為了保證主控通信進程與數據處理進程之間的同步性,還需要在二者之間進行協議交互,如圖2所示。
通過該協議,確保該系統在數據接收、數據處理以及數據反饋上的同步性[9]。
2.2? 基于云計算技術設置系統分布式處理方式
云計算技術將海量數據的計算處理轉換成無數個子處理程序,在相同處理時間內,加快了數據處理頻率[10]。該技術預先設置子程序之間的歐氏距離:
式中:[duv]表示任意2個相鄰子程序[u]和[v]之間的歐氏距離;[Rus],[Rvs]表示對程序[u],[v]的第[s]個變量。設置此時的距離矩陣為[K],確定最小距離元素[dmin],當子程序中的數據對應的位置為[a],[b],且其數值小于閾值[Y]時,則合并該距離矩陣實現降維。設置程序中距離最近的兩個數據類簇為[Csa],[Csb],合并后的新類簇為[Csab=Csa,Csb],因此新分類為[Cs1,Cs2,…,Csm]。該處理系統根據新的類簇設置分布式的數據處理子程序[11]。
2.3? 實現對海量數據的快速處理
在分布式處理方式設置完畢的基礎上,對海量數據線性分類,令每一處理單元中的數據同屬一個類型,或具有同一目的,或具有相似價值。隨機選則兩個樣本數據,將其分為2個大類,通過[k]維向量[x]表示相應的數據特征,[y]表示相應的分類標志,該線性分類超平面與分類函數的計算表達式為:
式中:[wT]表示針對數據類型建立的轉置矩陣;[b]表示一個固定常數;[fx]表示分類函數。當[fx>0]時,對應的分類標志[y=1];當[fx<0]時,[y=-1];當[fx=0]時,則該數據的支持向量在超平面之上[12]。根據式(2)可知,該線性分類如圖3所示。
圖中,三角形與圓圈代表隨機選取的兩類樣本向量。設置約束條件,根據云計算技術建立極速處理函數[μ],實現對海量數據的瞬時處理。
式中:[c]為數據總體量;[ω]為誤差修正系數;[fy]為處理約束條件;[ki]為處理頻率在[i]數據段的極限值;[q]為控制調和系數;[t]為瞬時反應時間;[n]為處理路徑。依據上述式(3),設置海量數據處理程序,控制子程序的處理進程。至此基于云計算技術,實現對網絡海量數據的分布式處理系統設計。
3? 仿真實驗
利用仿真實驗檢測所設計系統的可行性,并將本系統與傳統的數據集中處理系統進行對比。
3.1? 實驗準備
實驗將系統運行分為3部分:Hadoop云處理平臺;HBase分布式海量信息數據庫;Web管理控制系統,利用上述系統搭建實驗測試環境。Web系統在開發包JDK、服務器Tomcat的支持下正常運行,配置每臺測試機器的IP地址和主機名,保證系統程序正常運行。構建Hadoop平臺的運行環境,安裝并配置HBase數據庫,并將其分發到集群中的所有階段上實施解壓程序,如圖4所示。
實驗時隨機選取某年度、某平臺的海量交易數據作為實驗對象,該平臺具體數據信息如表1所示。分別利用2種數據處理系統,處理上述表格中的數據。
3.2? 結果分析
2個系統的數據處理結果如圖5所示。
由圖5可知,當所處理的數據量為564.33 GB時,所設計系統在第0.1 s迅速做出反應,瞬間將系統處理頻率提升到7 GHz以上;而傳統系統在0.4 s時才做出處理,處理頻率在3.073 5 GHz左右,比所設計系統的處理頻率慢了50.05%。為保證實驗結果真實,利用2個系統處理11月份數據的實驗結果如圖6所示。
圖6曲線是對數據量為1 022.59 GB的11月份數據的測試結果。根據曲線走勢可以看出,面對體量更大的平臺數據,所設計系統還是在第0.1 s做出處理反應,處理頻率在7 GHz以上;而傳統系統在0.47 s做出反應,處理頻率降至3 GHz以下,比設計的處理系統慢了61.12%。綜上,基于云計算技術設計的海量數據處理系統的處理數據頻率更快,響應更迅速。
4? 結? 語
此次設計的海量數據處理系統,從數據處理頻率入手,通過云計算技術,將體量龐大的網絡海量數據分解成若干個小程序,通過多部服務器組成的系統軟件,加快了系統的分析能力和響應速度。實驗結果表明,所設計系統比傳統系統的處理頻率提高了50%以上,解決了傳統系統中受分析能力較弱、響應速度偏慢導致處理頻率偏低的問題。
參考文獻
[1] 班婭萌,趙月鵬,平金珍.基于云計算的分布式電源管理系統設計與實現[J].電源技術,2017,41(2):310?311.
[2] 竇金鳳,于文華,曹家寶,等.基于云計算平臺的工程材料詢價系統[J].計算機應用,2018,38(S1):158?161.
[3] 余昌發,程學林,楊小虎.基于Kubernetes的分布式TensorFlow平臺的設計與實現[J].計算機科學,2018,45(z2):527?531.
[4] 徐一鳳,豐大軍,張瀚文,等.基于跨平臺的實時數據處理系統的設計[J].電子技術應用,2017,43(9):98?100.
[5] 王佳玉,張振宇,褚征,等.一種基于軌跡數據密度分區的分布式并行聚類方法[J].中國科學技術大學學報,2018,48(1):47?56.
[6] 林靜懷.基于云計算的電網調度控制培訓仿真系統設計[J].電力系統自動化,2017,41(14):164?170.
[7] 覃偉榮.云計算網絡環境和大數據結合的物聯網信息化建設[J].激光雜志,2018,39(5):120?123.
[8] 王傳連,張宗朔.基于私有云的大規模交通視頻處理框架設計[J].計算機工程與應用,2017,53(21):254?257.
[9] 張海闊,陸忠華,劉芳,等.面向海量告警數據的并行處理系統設計與實現[J].計算機工程與設計,2018,39(2):407?413.
[10] 陳濤,喬佩利,孫廣路,等.實時網絡流特征提取系統設計[J].哈爾濱理工大學學報,2017,22(2):99?104.
[11] 顧東曉,李童童,梁昌勇,等.基于云計算的管理信息系統遷移模式與策略研究[J].情報科學,2018,36(12):71?76.
[12] 莫勇,張海燕.基于云計算的電力數據在線安全分析并行化[J].控制工程,2017,24(4):823?828.
猜你喜歡
中學生數理化·自主招生(2022年9期)2022-05-30 10:48:04
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
電子測試(2018年4期)2018-05-09 07:28:12
當代化工研究(2016年9期)2016-03-20 16:22:13
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
計算機工程(2015年4期)2015-07-05 08:28:04
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
聯合國青年技術培訓(2014年7期)2014-04-12 00:00:00
中國質量與標準導報(2014年7期)2014-02-28 22:24:35
